
A Method of Fusing Probability-Form Knowledge into Object Detection in Remote Sensing Images


Abstract
:1. Introduction
- We extract two kinds of knowledge in the form of probabilities, namely the correlations between classes and the correlations between the water area and classes, by analyzing the DOTA [13] and DIOR [2] training sets. Then, we transform the extracted knowledge into a knowledge factor using a novel equation improved from [14].
- We propose a method, namely the Knowledge Inference Module (KIM), of integrating knowledge into object detection in remote sensing images. Through an evaluation of two public aerial data sets, our method obtains a higher mAP than the baseline model, Oriented R-CNN [15] with fewer false and missed detections.
2. Related Work
2.1. Object Detection in Remote Sensing Images
2.2. Utilization of Existing Knowledge
2.2.1. Utilization of Knowledge Learned in Training
2.2.2. Utilization of Existing Knowledge
3. Establishment of the Knowledge Matrix
3.1. Knowledge Matrix Establishment
3.1.1. Conditional Co-Occurrence Knowledge Matrix
- We abandon the function, which means that the range of extends to the negative axis, which is suitable for situations where category l and category do not co-occur or barely co-occur;
- We regard the log part as a conditional co-occurrence factor and abandon and add as a scale factor into the equation in order to the scale knowledge factor into a proper numerical dimension and the make knowledge factor adaptive to the probability of category occurrence;
- We split our novel equation into two branches, where the upper one is for situations where l and appear together in the training set and the lower one computes the knowledge factor when l and do not co-occur;
- In the lower branch, we replace with the zero factor in Equation (4), where denotes the number of instances belonging to category l, making the equation more elegant when equals 0.
3.1.2. Water Area Knowledge Matrix
4. Methods
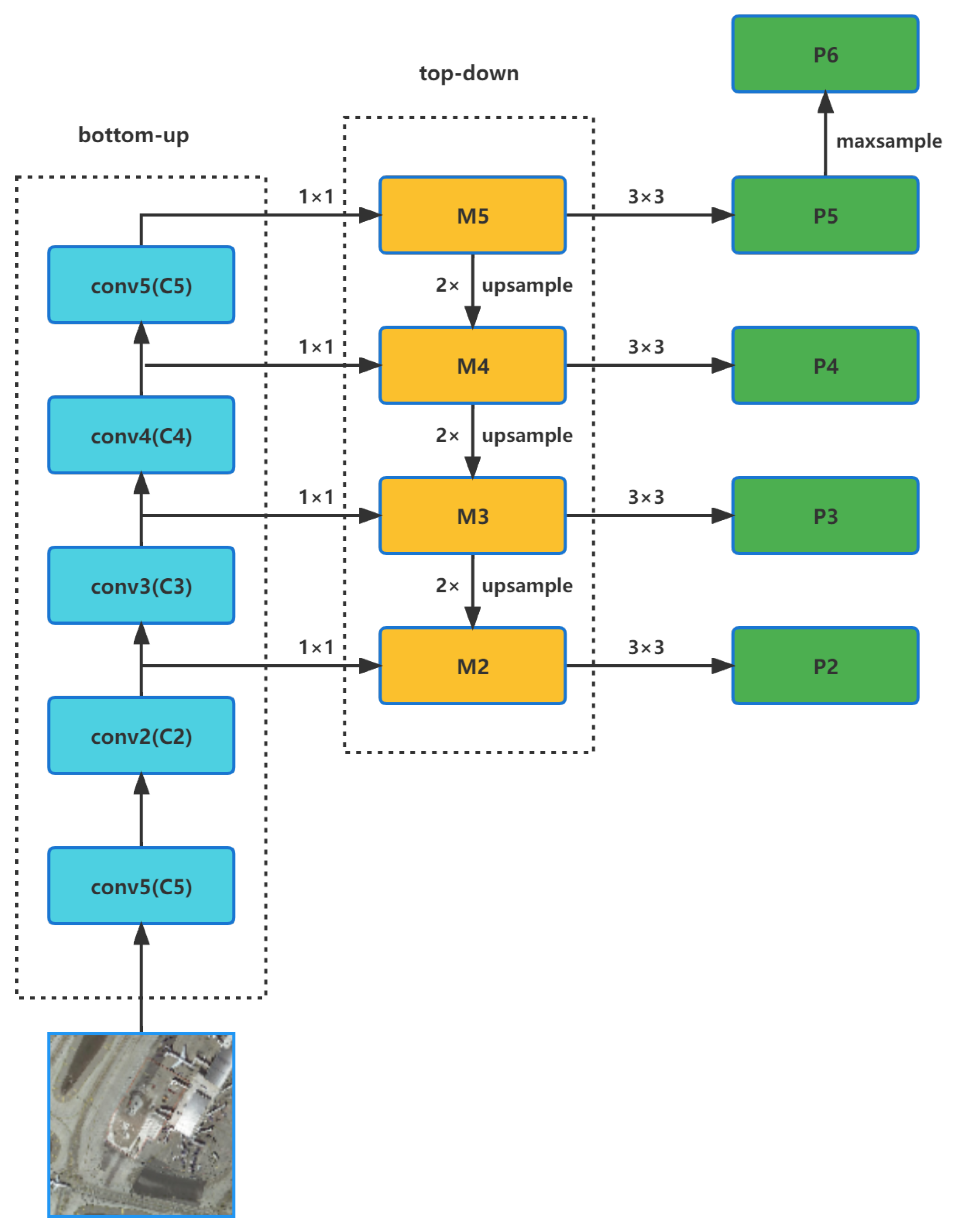
4.1. Feature Extraction
4.2. Oriented RPN
- An anchor that has an Intersection-over-Union(IoU) over 0.7 with any ground-truth box is regarded as a positive sample;
- An anchor that has an IoU over 0.3 with a ground-truth box and the IoU is the highest;
- An anchor that has an IoU lower than 0.3 is regarded as a negative sample;
- Anchors that do not belong to the above cases are discarded during the training process.
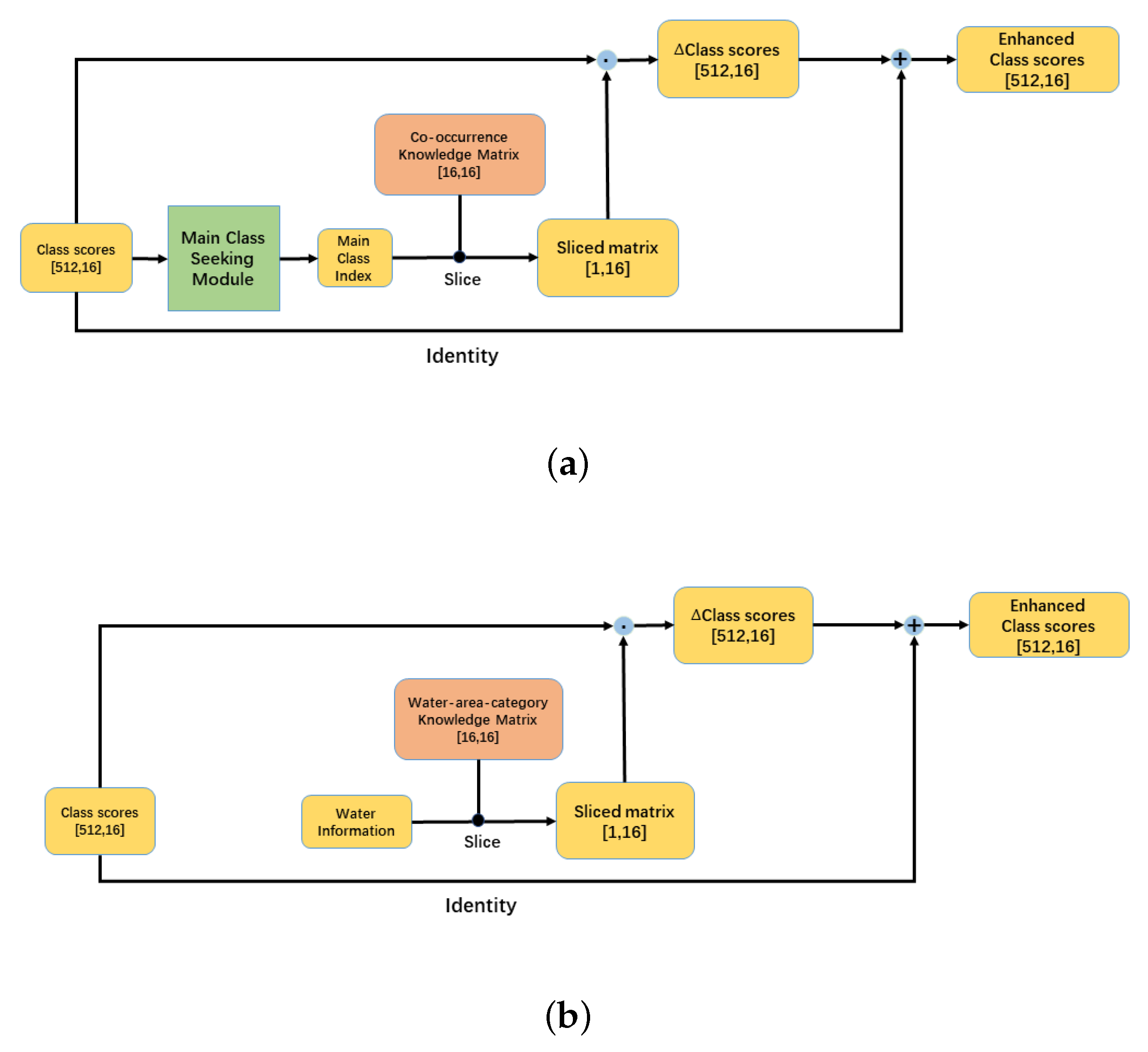
4.3. Oriented RCNN Head with the Knowledge Inference Module
4.4. Loss Function
5. Experiments
5.1. Data Sets
5.2. Evaluation Metrics
5.3. Implementation Details
6. Results
6.1. DOTA Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| METHOD | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Det [17] | 88.8 | 67.4 | 44.1 | 69.0 | 62.9 | 71.7 | 78.7 | 89.9 | 47.3 | 61.2 | 47.4 | 59.3 | 59.2 | 51.7 | 24.3 | 61.5 |
| CSL [7] | 88.1 | 72.2 | 39.8 | 63.8 | 64.3 | 71.9 | 78.5 | 89.6 | 52.4 | 61.0 | 50.5 | 66.0 | 56.6 | 50.1 | 27.5 | 62.2 |
| A-net [9] | 89.1 | 72.0 | 45.6 | 64.8 | 65.0 | 74.8 | 79.5 | 90.1 | 60.2 | 67.3 | 49.3 | 62.2 | 60.6 | 53.4 | 37.6 | 64.8 |
| FR-O [5] | 89.3 | 76.0 | 49.3 | 74.7 | 68.1 | 75.5 | 87.1 | 90.7 | 64.2 | 62.3 | 57.0 | 65.8 | 66.6 | 59.6 | 38.2 | 68.3 |
| RoI Trans [6] | 89.9 | 76.5 | 48.1 | 73.1 | 68.7 | 78.2 | 88.7 | 90.8 | 73.6 | 62.7 | 62.0 | 63.4 | 73.7 | 57.2 | 47.9 | 70.3 |
| Baseline [15] | 89.8 | 75.7 | 50.2 | 77.3 | 69.4 | 84.8 | 89.3 | 90.8 | 69.2 | 62.6 | 63.1 | 65.0 | 75.3 | 57.5 | 45.3 | 71.0 |
| Water area | 89.6 | 75.6 | 50.3 | 76.4 | 68.4 | 84.3 | 89.4 | 90.7 | 72.9 | 62.6 | 66.0 | 67.2 | 75.6 | 56.5 | 48.8 | 71.6 |
| Co-occurrence | 89.6 | 76.0 | 50.7 | 77.0 | 68.3 | 84.4 | 89.3 | 90.7 | 73.6 | 62.4 | 63.8 | 66.8 | 75.1 | 57.6 | 54.0 | 72.0 |
6.2. DIOR Results
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
| Object Categories | ||
|---|---|---|
| airplane | 344 | 0.0586 |
| airport | 326 | 0.0556 |
| baseball field | 552 | 0.0941 |
| basketball court | 336 | 0.0573 |
| bridge | 378 | 0.0644 |
| chimney | 202 | 0.0344 |
| dam | 238 | 0.0406 |
| expressway service area | 279 | 0.0475 |
| expressway toll station | 285 | 0.0486 |
| golf field | 216 | 0.0368 |
| ground track field | 537 | 0.0916 |
| harbor | 329 | 0.0561 |
| overpass | 410 | 0.0699 |
| ship | 649 | 0.1107 |
| stadium | 289 | 0.0493 |
| storage tank | 390 | 0.0665 |
| tennis court | 605 | 0.1032 |
| train station | 244 | 0.0416 |
| vehicle | 1561 | 0.2662 |
| windmill | 404 | 0.0689 |
| Object Categories | ||
|---|---|---|
| airplane | 0.0412 | 0.9588 |
| airport | 0.4482 | 0.5518 |
| baseball field | 0.0714 | 0.9286 |
| basketball court | 0.0981 | 0.9019 |
| bridge | 0.9525 | 0.0475 |
| chimney | 0.1228 | 0.8772 |
| dam | 1 | 0 |
| expressway service area | 0.2719 | 0.7281 |
| expressway toll station | 0.1335 | 0.8665 |
| golf field | 0.9114 | 0.0886 |
| ground track field | 0.1293 | 0.8707 |
| harbor | 1 | 0 |
| overpass | 0.1179 | 0.8821 |
| ship | 0.9998 | 0.0002 |
| stadium | 0.1126 | 0.8874 |
| storage tank | 0.3126 | 0.6874 |
| tennis court | 0.1366 | 0.8634 |
| train station | 0.2398 | 0.7602 |
| vehicle | 0.2140 | 0.7860 |
| windmill | 0.0489 | 0.9511 |
References
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef] [Green Version]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Wu, X.; Li, W.; Hong, D.; Tao, R.; Du, Q. Deep learning for unmanned aerial vehicle-based object detection and tracking: A survey. IEEE Geosci. Remote Sens. Mag. 2021, 10, 91–124. [Google Scholar] [CrossRef]
- Fascista, A. Toward Integrated Large-Scale Environmental Monitoring Using WSN/UAV/Crowdsensing: A Review of Applications, Signal Processing, and Future Perspectives. Sensors 2022, 22, 1824. [Google Scholar] [CrossRef] [PubMed]
- Mo, N.; Yan, L. Improved faster RCNN based on feature amplification and oversampling data augmentation for oriented vehicle detection in aerial images. Remote Sens. 2020, 12, 2558. [Google Scholar] [CrossRef]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning RoI transformer for oriented object detection in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2849–2858. [Google Scholar]
- Yang, X.; Yan, J. Arbitrary-oriented object detection with circular smooth label. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 677–694. [Google Scholar]
- Guo, Z.; Liu, C.; Zhang, X.; Jiao, J.; Ji, X.; Ye, Q. Beyond bounding-box: Convex-hull feature adaptation for oriented and densely packed object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8792–8801. [Google Scholar]
- Han, J.; Ding, J.; Li, J.; Xia, G.S. Align deep features for oriented object detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–11. [Google Scholar] [CrossRef]
- Torralba, A.; Oliva, A.; Castelhano, M.S.; Henderson, J.M. Contextual guidance of eye movements and attention in real-world scenes: The role of global features in object search. Psychol. Rev. 2006, 113, 766. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Z.; Wu, Q.; Cheng, B.; Cao, L.; Yang, H. Remote sensing image scene classification based on object relationship reasoning CNN. IEEE Geosci. Remote Sens. Lett. 2020, 19, 1–5. [Google Scholar] [CrossRef]
- Xu, H.; Jiang, C.; Liang, X.; Lin, L.; Li, Z. Reasoning-rcnn: Unifying adaptive global reasoning into large-scale object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6419–6428. [Google Scholar]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Fang, Y.; Kuan, K.; Lin, J.; Tan, C.; Chandrasekhar, V. Object detection meets knowledge graphs. In Proceedings of the International Joint Conferences on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017. [Google Scholar]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3520–3529. [Google Scholar]
- Ming, Q.; Miao, L.; Zhou, Z.; Dong, Y. CFC-Net: A critical feature capturing network for arbitrary-oriented object detection in remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3det: Refined single-stage detector with feature refinement for rotating object. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 3163–3171. [Google Scholar]
- Han, J.; Ding, J.; Xue, N.; Xia, G.S. Redet: A rotation-equivariant detector for aerial object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–15 June 2021; pp. 2786–2795. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chen, C.; Gong, W.; Chen, Y.; Li, W. Object detection in remote sensing images based on a scene-contextual feature pyramid network. Remote Sens. 2019, 11, 339. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, R.; Shan, S.; Chen, X. Structure inference net: Object detection using scene-level context and instance-level relationships. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6985–6994. [Google Scholar]
- Siris, A.; Jiao, J.; Tam, G.K.; Xie, X.; Lau, R.W. Scene context-aware salient object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 4156–4166. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Processing Syst. 2017, 30. [Google Scholar] [CrossRef]
- Li, K.; Cheng, G.; Bu, S.; You, X. Rotation-insensitive and context-augmented object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2017, 56, 2337–2348. [Google Scholar] [CrossRef]
- Zhang, G.; Lu, S.; Zhang, W. CAD-Net: A context-aware detection network for objects in remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 10015–10024. [Google Scholar] [CrossRef] [Green Version]
- Zhang, K.; Wu, Y.; Wang, J.; Wang, Y.; Wang, Q. Semantic context-aware network for multiscale object detection in remote sensing images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Liu, J.; Li, S.; Zhou, C.; Cao, X.; Gao, Y.; Wang, B. SRAF-Net: A Scene-Relevant Anchor-Free Object Detection Network in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Feng, X.; Han, J.; Yao, X.; Cheng, G. TCANet: Triple context-aware network for weakly supervised object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6946–6955. [Google Scholar] [CrossRef]
- Cheng, B.; Li, Z.; Xu, B.; Dang, C.; Deng, J. Target detection in remote sensing image based on object-and-scene context constrained CNN. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Xu, H.; Jiang, C.; Liang, X.; Li, Z. Spatial-aware graph relation network for large-scale object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9298–9307. [Google Scholar]
- Xu, H.; Fang, L.; Liang, X.; Kang, W.; Li, Z. Universal-rcnn: Universal object detector via transferable graph r-cnn. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12492–12499. [Google Scholar]
- Shu, X.; Liu, R.; Xu, J. A Semantic Relation Graph Reasoning Network for Object Detection. In Proceedings of the 2021 IEEE 10th Data Driven Control and Learning Systems Conference (DDCLS), Suzhou, China, 14–16 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1309–1314. [Google Scholar]
- Jiang, C.; Xu, H.; Liang, X.; Lin, L. Hybrid knowledge routed modules for large-scale object detection. Adv. Neural Inf. Processing Syst. 2018, 31. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Zhou, Y.; Yang, X.; Zhang, G.; Wang, J.; Liu, Y.; Hou, L.; Jiang, X.; Liu, X.; Yan, J.; Lyu, C.; et al. MMRotate: A Rotated Object Detection Benchmark using PyTorch. arXiv 2022, arXiv:2204.13317. [Google Scholar]






















| Object Categories | ||
|---|---|---|
| Plane | 197 | 0.1396 |
| Baseball diamond | 122 | 0.0864 |
| Bridge | 210 | 0.1488 |
| Ground track field | 177 | 0.1254 |
| Small vehicle | 486 | 0.3444 |
| Large vehicle | 380 | 0.2693 |
| Ship | 326 | 0.2310 |
| Tennis court | 302 | 0.2140 |
| Basketball court | 111 | 0.0786 |
| Storage tank | 161 | 0.1141 |
| Soccer ball field | 136 | 0.0963 |
| Roundabout | 170 | 0.1204 |
| Harbor | 339 | 0.2402 |
| Swimming pool | 144 | 0.1020 |
| Helicopter | 30 | 0.0212 |
| Object Categories | ||
|---|---|---|
| plane | 0.1748 | 0.8252 |
| baseball-diamond | 0.5543 | 0.4457 |
| bridge | 0.9755 | 0.0245 |
| ground-track-field | 0.6462 | 0.3538 |
| small-vehicle | 0.2837 | 0.7163 |
| large-vehicle | 0.1584 | 0.8416 |
| ship | 0.9994 | 0.0006 |
| tennis-court | 0.2945 | 0.7055 |
| basketball-court | 0.2544 | 0.7456 |
| storage-tank | 0.9402 | 0.0598 |
| soccer-ball-field | 0.5215 | 0.4785 |
| roundabout | 0.6166 | 0.3834 |
| harbor | 1 | 0 |
| swimming-pool | 1 | 0 |
| helicopter | 0.0015 | 0.9985 |
| METHOD | FPS | mAP |
|---|---|---|
| Baseline | 11.8 | 71.0 |
| Water area | 11.7 | 71.6 |
| Conditional co-occurrence | 11.5 | 72.0 |
| METHOD | APL | APT | BF | BC | BR | CM | DA | ESA | EST | GF |
|---|---|---|---|---|---|---|---|---|---|---|
| Det [17] | 89.6 | 6.40 | 89.5 | 71.2 | 14.4 | 81.7 | 8.90 | 26.5 | 48.1 | 31.8 |
| CSL [7] | 90.9 | 2.60 | 89.4 | 71.5 | 7.10 | 81.8 | 9.30 | 31.4 | 41.5 | 58.1 |
| A-Net [9] | 90.8 | 14.0 | 89.9 | 72.7 | 17.6 | 81.7 | 9.50 | 32.9 | 50.1 | 50.9 |
| RoI Trans [6] | 90.8 | 12.1 | 90.8 | 79.8 | 22.9 | 81.8 | 8.20 | 51.3 | 54.1 | 60.7 |
| FR-O [5] | 90.9 | 13.1 | 90.7 | 79.9 | 22.0 | 81.8 | 10.4 | 49.8 | 53.1 | 58.5 |
| Baseline | 90.9 | 17.0 | 90.7 | 80.6 | 33.5 | 81.8 | 19.2 | 59.8 | 53.1 | 56.7 |
| Water area | 90.9 | 21.2 | 90.7 | 80.3 | 34.2 | 81.8 | 20.7 | 60.0 | 52.9 | 55.1 |
| Co-occurrence | 90.9 | 23.3 | 90.8 | 80.9 | 38.0 | 81.8 | 20.5 | 62.2 | 53.7 | 61.3 |
| GTF | HA | OPS | SP | STD | ST | TC | TS | VEH | WD | mAP |
| 65.6 | 8.20 | 33.4 | 69.2 | 51.9 | 72.9 | 81.1 | 21.4 | 54.2 | 44.7 | 48.5 |
| 63.2 | 17.5 | 26.6 | 69.3 | 53.8 | 72.8 | 81.6 | 18.4 | 47.2 | 46.3 | 49.0 |
| 70.9 | 16.3 | 43.6 | 80.1 | 52.5 | 75.7 | 81.7 | 23.9 | 59.0 | 45.6 | 53.0 |
| 77.2 | 30.6 | 40.5 | 89.9 | 88.2 | 79.5 | 81.8 | 20.6 | 67.9 | 55.1 | 59.2 |
| 75.4 | 35.5 | 41.6 | 89.1 | 85.4 | 79.3 | 81.8 | 32.7 | 66.4 | 55.5 | 59.6 |
| 76.9 | 26.1 | 54.5 | 89.9 | 88.8 | 79.6 | 81.8 | 30.2 | 68.3 | 55.1 | 61.7 |
| 76.7 | 26.8 | 54.6 | 89.8 | 88.3 | 79.5 | 81.8 | 35.5 | 68.7 | 55.6 | 62.2 |
| 81.3 | 32.1 | 56.6 | 90.0 | 88.3 | 79.7 | 90.1 | 44.3 | 69.2 | 56.5 | 64.6 |
| METHOD | FPS | mAP |
|---|---|---|
| Baseline | 9.3 | 61.7 |
| Water area | 9.1 | 62.2 |
| Conditional co-occurrence | 9.1 | 64.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, K.; Dong, Y.; Xu, W.; Su, Y.; Huang, P. A Method of Fusing Probability-Form Knowledge into Object Detection in Remote Sensing Images. Remote Sens. 2022, 14, 6103. https://doi.org/10.3390/rs14236103
Zheng K, Dong Y, Xu W, Su Y, Huang P. A Method of Fusing Probability-Form Knowledge into Object Detection in Remote Sensing Images. Remote Sensing. 2022; 14(23):6103. https://doi.org/10.3390/rs14236103
Chicago/Turabian StyleZheng, Kunlong, Yifan Dong, Wei Xu, Yun Su, and Pingping Huang. 2022. "A Method of Fusing Probability-Form Knowledge into Object Detection in Remote Sensing Images" Remote Sensing 14, no. 23: 6103. https://doi.org/10.3390/rs14236103