1. Introduction
Abundant spatial information and continuous spectral information are contained in Hyperspectral Images (HSIs), so HSI classification is widely used in mineral exploration [
1], environmental management [
2], surveillance [
3], military reconnaissance [
4] and other fields [
5,
6,
7,
8]. As satellite sensing technology continues to mature, both the spectral resolution and spatial resolution of HSI are becoming higher and higher and the feature dimension is increasing accordingly. Therefore, more resources are required for the classification task. The number of spectra in currently published hyperspectral image datasets [
9] is typically more than 100, but the actual categories of objects are generally less than 20. By observing the spectral information, it can be found that information redundancy exists to a sever degree in different bands. To reduce the information redundancy and feature dimension between spectra, some common spatial domain methods are used, such as Linear Discriminant Analysis (LDA) [
10], Independent Component Analysis [
11], Principal Component Analysis (PCA) [
12], other data preprocessing methods based on Gaussian filtering [
13] and so on.
The machine learning method [
14] has superior performance on nonlinear complex classification problems and is widely used in HSI classification, such as Multinomial Logistic Regression [
15], Relevant Vector Machine [
16], Support Vector Machine (SVM) [
17] and other methods [
18]. Kang et al. [
19] proposed a filtering method that can take pixel information into account well, aiming to optimize pixel classification maps in the local filtering framework. Although they can classify the HSI effectively to some extent, their feature learning is mainly based on spectral information, in which the correlation of pixels in the spatial domain is not used fully. To further improve the classification performance, Ma et al. [
20] proposed a spectral–spatial classification enhancement method based on active learning and iterative training sampling, which can reduce the inconsistency of classification.
With the development of deep learning in image processing and pattern recognition, remote sensing data classification has progressed tremendously in the last few years [
21]. Due to the fact that it considers local connectivity and weight sharing, CNN has a strong feature expression capability. Makantasis et al. [
22] proposed a 2D-CNN-based model to extract more high-level spectral features by encoding spatial and spectral information of pixels. Hamida et al. [
23] proposed a 3D-CNN-based method that can jointly process spectral and spatial information of HSI. Roy et al. [
24] proposed a hybrid CNN method named HybridSN, which uses 3D-CNN and 2D-CNN for spatial–spectral feature (SSF) extraction. It achieved good results and reduced computational complexity to some extent. Overall, these CNN-based methods have obtained better classification results than traditional machine learning methods. However, since there is a wide variety of ground objects in HSI and their spectral characteristics are extremely similar between some objects, the intra-class dissimilarity and inter-class similarity of HSI are high. Thus, the classification accuracies are reduced to some extent. Moreover, as the depth of the network increases, problems such as the “Hughes” phenomenon [
25] and network degradation will appear. Therefore, He et al. [
26] proposed a residual network that maps shallow features to deep features through skip connections, which can significantly solve the problem of gradient explosion and network degradation due to a deepening network without introducing additional parameters and computational complexity. Zhong et al. [
27] proposed a spatial–spectral residual network, in which spectral residual blocks and spatial residual blocks were designed to learn spectral features and spatial semantic features, respectively. The back-propagation of gradients facilitated in the SSRN model partially solved the degradation problem of other models. Chang et al. [
28] proposed a consolidated convolutional neural network by combining a 3D-CNN and a 2D-CNN, which can effectively reduce the model complexity and solve the overfitting problem. Yue et al. [
29] proposed a spectral–spatial latent reconstruction framework, which can improve the robustness of HSI classification methods. Since hyperspectral data are correlated between both spatial and spectral domains, their correlation information can not be explored fully in a global view using these CNN-based methods to some extent.
Transformer [
30] has strong long-range context modeling ability, where the attention mechanism is used to describe global dependencies in the input sequence and global order information is captured through positional encoding. Therefore, the Vision-Transformer (ViT) model proposed by Dosovitskiy et al. [
31] is applied to the field of computer vision, which can capture global information of images. Inspired by the idea, more and more people are applying it to the field of HSI classification and achieving advanced results since ViT can capture global information. From the perspective of sequences, Hong et al. [
32] proposed a Transformer-based classification architecture named SpectralFormer that can efficiently process and analyze sequential data. He et al. [
33] proposed an SST network to extract the features and alleviate the overfitting problem, which includes a well-designed 2D-CNN, an improved dense Transformer and a dynamic feature enhancement module. Zhong et al. [
34] proposed a spectral–spatial transformer network consisting of spatial attention and spectral correlation modules to overcome the limitations of the convolution kernel. Chen et al. [
35] proposed an SSFTT method to capture high-level semantic features with more discriminative. Although the above methods can obtain global information to a certain extent, they are inadequate in terms of local details.
To compensate for the deficiencies of the above methods, the spatial–spectral joint features extraction with local and global information at different scales is considered in this paper. Therefore, an end-to-end model with spatial–spectral feature enhancement from shallow to deep is designed based on CNN and Transformer. Attention mechanisms [
36,
37] are added to both shallow and deep feature extraction modules, which can make full use of local details and global information and also improve the discriminative capability of the features. First, since the PCA method can extract the most important spectral components for classification, it is applied to alleviate spectral redundancy and reduce computation costs. Next, a two-layer 3D-CNN is established as a feature extractor to extract shallow simultaneously; then, Residual Squeeze-Excitation Convolutional (Res-SEConv) block is designed to enhance the correlation between shallow spectral features. Finally, the deep features are extracted using ViT to improve the classification performance.
The main contributions are as follows:
To make full use of both spatial–spectral and global–local feature maps, an effective SDFE (Shallow-to-Deep spatial–spectral Feature Enhancement) method is proposed for HSI classification. It is constructed by cascading the Shallow Spatial–Spectral Feature Extraction (SSSFE) module, the Res-SEConv module and the VTFE module.
A Res-SEConv module based on the depth-wise convolution and channel attention mechanism is designed to further extract the spatial–spectral joint features, which can improve the robustness of the extracted features.
The remainder of this paper is structured as follows.
Section 2 contains the relevant basic theory.
Section 3 describes the proposed method.
Section 4 introduces the evaluation indicators, the datasets, the parameter settings and the experiments. A discussion is presented in
Section 5. Finally, conclusions are presented in
Section 6.
3. Proposed SDFE Method for HSI Classification
To enhance the SSFs from shallow to deep, an end-to-end HSI classification SDFE model (as in
Figure 3) is proposed. Firstly, the original hyperspectral HSIs are dimensionally reduced via PCA to retain the spectral components with important contributions. Secondly, the shallow features are extracted via the SSSFE module, which consists of two 3D-CNN layers. Thirdly, the Res-SEConv is designed to strengthen the important channel information. Finally, the VTFE module can further extract SSFs and perform classification. This shallow-to-deep feature extraction method capitalizes on spatial and spectral information at different scales. The approach proposed in this article mainly includes four parts: Band selection, SSSFE module, Res-SEConv module and VTFE module. The specific process is as follows:
3.1. Band Selection
Some bands are not sensitive to ground objects and cannot provide useful ground object information, which results in information redundancy and band noise. Therefore, dimensionality decrease is usually an important pre-processing step in HSI classification.
PCA is a widely used dimensionality reduction algorithm, which aims to find the principal components of the data and uses these principal components to characterize the original data. The raw hyperspectral data are recorded as , where M and N are the width and height of the raw data and L is the spectral band number. After the PCA method, the band number for the original data is reduced from L to B and the obtained data are denoted as . This process only reduces unimportant spectral bands and does not affect spatial information.
3.2. SSSFE Module
For small training samples, the accuracy will be decreased if the number of layers is increased continually over a certain number. Therefore, to make the most of the high-dimensional features of HSI, an SSSFE module with a two-layer 3D convolution network is designed and a ReLU and BN are performed after each convolutional layer.
To reduce the redundancy of HSI, two different convolution kernels with size
and
for layers 1 and 2 are set to extract. They not only can reduce the spectral dimension of the input but also effectively reduce the feature redundancy caused by augmenting the number of convolutional layers. The specific details of the SSSFE module are provided in
Figure 4.
The image cube
is divided into
3D cubes and the size of each cube is
, which is the input of the SSSFE module.
S is the height and width of the cube and
B is the band number of the cube. The ground-truth label of a cube is defined by the center pixel label. Theoretically, the number of 3D convolutional kernels for each 3D convolutional layer is
and the size of each kernal is
. When the feature block is fed into the 3D convolutional layer, the output dimension becomes
. Detailed information concerning the selection of parameters is given in
Section 4.3.
3.3. Res-SEConv Module
Compared with ordinary convolution, since a depth-wise convolution kernel can only perform a convolution operation with one channel, the operation parameters are greatly reduced. However, the process of depth-wise convolution does not contain position information and ignores the correlation between channels. Therefore, to enhance the useful spatial and spectral information further and add as few parameters as possible, a Res-SEConv module with depth-wise convolution and channel attention is designed. Its structure (Res-SEConv) is shown in
Figure 3. The channel attention adopts SENet [
41], which can adaptively obtain correlation for each feature channel. Thus, the important features are enhanced and the unimportant features are weakened according to their correlation.
The process of this module is as follows:
- (1)
After the SSSFE module, the obtained shallow feature maps are firstly rearranged to obtain feature maps with size . Then, the spatial feature is extracted using the depth-wise convolution module and the channel feature is weighted through the SE module.
- (2)
The dimension transformation of features is performed after channel attention and the dimension is transformed from to .
- (3)
Layer Normalization (LN) is first performed on the last dimension. Then, a GeLU activation operation and dimension transformation on the features are carried out. The feature dimension is transformed from to .
- (4)
The problem of gradient disappearance due to the increasing number of network layers can be solved by the identity mapping of the residual network. Therefore, the skip connection in the Res-SEConv module is designed to prevent overfitting and network degradation.
This module extracts more discriminative space–spectral joint features and only adds a small number of parameters compared to ordinary convolution. The input size of the Res-SEConv module is the same as the output, so it is a plug-and-play module and can be utilized for other computer vision tasks.
3.4. VTFE Module
Although CNN has the features of local connectivity and weight sharing, it is hard to obtain the long-distance spectral correlation. However, the core of HSI analysis is spectral analysis, so we use a ViT to enhance feature maps extracted by the Res-SEConv module. The multi-head attention mechanism of ViT captures the spectral correlation with long-range dependence and maps the global correlations, so it can better represent the spectral features of HSI. The VTFE module consists of the following three parts.
Firstly, the output of the Res-SEConv module is divided into the 2D patches along the spectral dimension and then the 2D patches are mapped to 1D vectors via linear mapping. Secondly, the Position Embedding (PE) is added to each 1D vector. PE can not only preserve the position information of the original 2D block itself before flattening, but can also preserve the relative position information between 2D blocks. Finally, the Class Token for classification is added to the vector with PE. The dimension of the Class Token is the same as that of other tokens and autocorrelation operations are performed between all tokens.
Then, the Transformer Encoder module (as in
Figure 5) is the key to the ViT model. The two sub-layers of the LN cascade Multi-head Self-Attention (MSA) and LN cascade MLP layer are alternately connected and the residual connection is used between every two sub-layers.
The attention mechanism of the Transformer can effectively capture the correlation of sequences. Its Self-Attention function essentially maps queries and key-value pairs to the output. Specifically, three learnable weight matrices are defined and the input is linearly changed with the three weight matrices to obtain the matrix of query
, key
and value
. Then, the calculation formula of the output matrix is
where
represents the dimension of the input and is also a scale factor. First, the attention score between each
and
computed in the form of an inner product is scaled by a scaling factor
. Then, a softmax operation is performed on the scale scores. Finally, the obtained score is multiplied by the weight of
and the output of the attention function is obtained.
The final structure used for the classification is relatively simple, only including an LN and an FC layer. The final classification result can be obtained through the FC layer.
4. Experiments and Results
In this section, the classification performance of the SDFE method and other baselines are analyzed. All experiments in this article have the same experimental environment, in which NVIDIA GeForce RTX3090 GPU, Intel Xeon Gold 6142
[email protected] processor is used and the running memory is 60.9 GB.
The SDFE method adopts the cross-entropy loss function and Adam optimizer, the learning rate is set to 0.0001, the batch size is set to 64, the number of iterations for training on the Indian Pines (IP) dataset is 200 and the number of iterations for training on the Pavia University (PU) and Salinas (SA) datasets is 100.
4.1. Datasets
(1) Indian Pines Dataset
The IP dataset was captured by the AVIRIS imager on an Indian pine tree in the American state of Indiana, which has a spatial resolution of 20 m. There are 16 object categories, 200 bands and 145 × 145 pixels. A total of 10,776 pixels are background and 10,249 pixels are ground objects.
Figure 6a is the false-color image and (b) is the ground-truth map.
(2) Pavia University Dataset
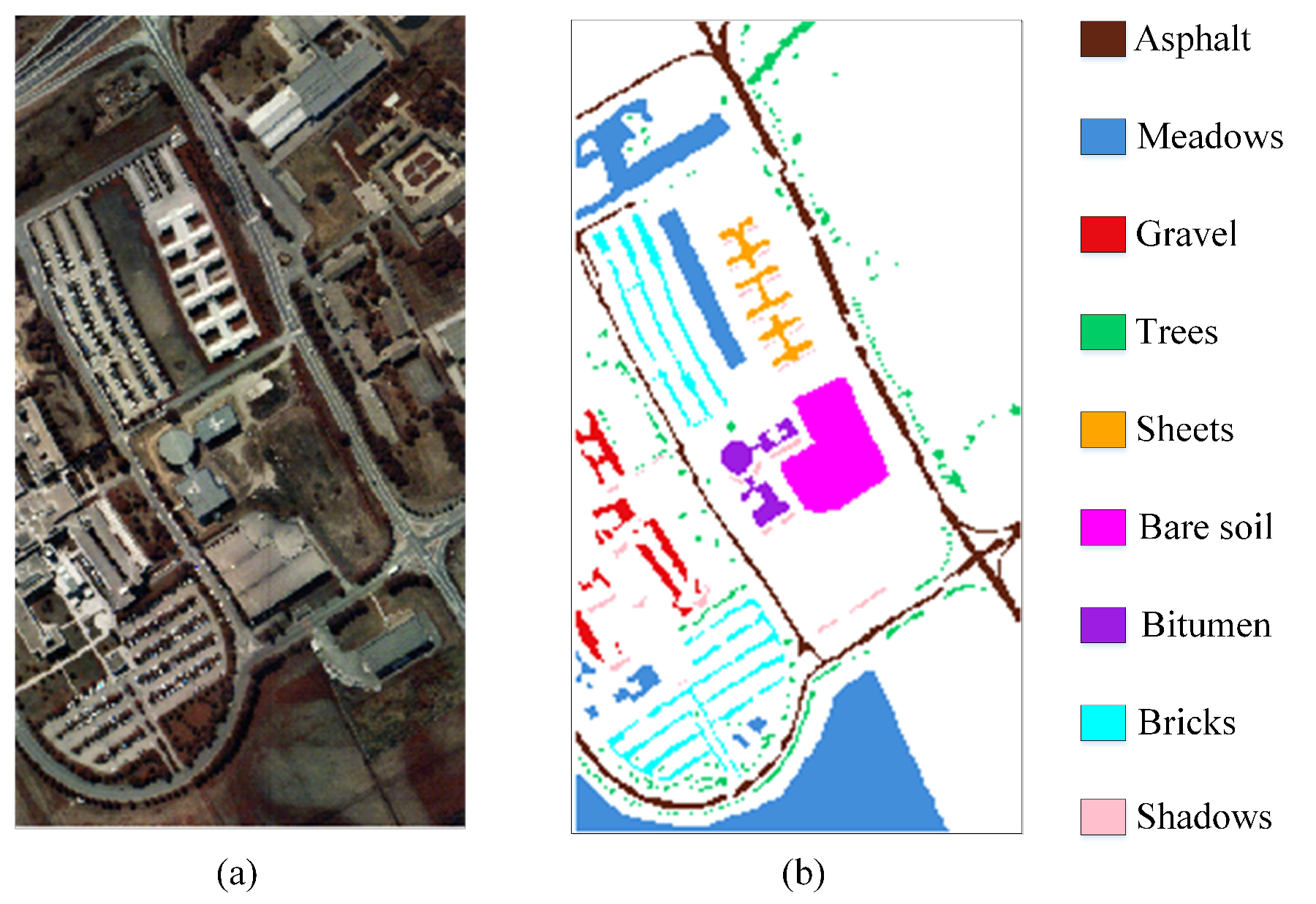
The PU dataset with a resolution of 1.3 m was captured by the ROSIS-03 sensor over the Pavia University in Northern Italy. The number of land cover categories and spectral bands is 9 and 103, respectively. It consists of 610 × 340 pixels and there are only 42,776 ground object pixels.
Figure 7a is the false-color image and (b) is the ground-truth map.
(3) Salinas Dataset
As with the IP dataset, the SA dataset was also captured by the AVIRIS imager. It has a band count of 204 and a spatial resolution of 3.7 m. The dataset contains 512 × 217 pixels and 16 object categories. Among the 111,104 pixels, 54,129 pixels represent the ground objects.
Figure 8a is the false-color image and (b) is the ground-truth map.
Table 1 lists the number of training samples, testing samples and land-cover category names for the IP, PU and SA datasets. The training sample number of the IP dataset accounts for 10% of the total and the training sample number of the PU and SA datasets accounts for 5%.
4.2. Evaluation Criterions
The goal of the HSI classification task is to assign a category to each pixel in the image. The assigned categories are compared with the ground truth values. By studying current classification evaluation criteria, the overall accuracy (OA), average accuracy (AA) and Kappa coefficient (Kappa) are selected to evaluate the results of the SDFE method and other methods in this paper. Larger values of these indicators represent better classification effectiveness. OA represents the percentage of correctly classified samples among all test samples, which indicates the correct prediction effect. AA represents the average of the classification accuracies for each category of samples. The Kappa coefficient is a statistical metric that measures the agreement degree between the classification results and ground truth.
OA is formulated by this equation
where
is the number of samples that are actually positive and predicted to be positive,
is the number of samples that are actually negative and predicted to be negative,
is the number of samples that are actually negative but are predicted to be positive and
is the number of samples that are actually positive but are predicted to be negative.
AA is formulated by the Equation (
7):
where
is the
of class
i,
is the
of class
i and
n is the number of categories.
The formula of the Kappa coefficient is given by the following Equation (
8):
where
is equal to OA,
is formulated by the Equation (
9):
where
N is the total test sample number and it can be computed using Equation (
10).
4.3. Model Parameters Selection
In this subsection, we analyze several parameters that have an impact on the classification results, such as the selection of PCA, the input patch size, the 3D convolutional kernel number, the learning rate, batch size and the size of the depth-wise convolutional kernel.
(1) The selection of PCA
HSI contains a lot of redundant and noisy information in the spectral channel. Therefore, it is very challenging to adequately extract spectral information from the images. The comparative experiments using the PCA and LDA preprocessing methods were conducted on the IP dataset and the results are shown in
Table 2. It can be seen that the results using PCA are better than those using LDA, so PCA is selected to extract the principal spectra.
The number of the principal components was selected as 20, 30, 50, 100 and 200 for the Indian Pines dataset and 20, 30 and 50 for the Pavia University dataset and Salinas dataset for the experiments. The experimental results on the three datasets are shown in
Table 3,
Table 4 and
Table 5, respectively. It can be found that both the network parameters and the running time increase as the number of the principal components increases, When the principal component number is 30, the optimum classification results can be obtained. Therefore, the principal component number is taken as 30 in this paper. That is, 30 bands of spectra are selected as the HSI spectral features.
(2) Experiments on the patch size of the input
Different input sizes can affect the classification results of the network, so the selection experiments with different input sizes are carried out.
Figure 9 demonstrates the classification metric OA on different patch sizes. We can find that the OA improves with the increase in the input patch and stops improving when the patch reaches
. Therefore, the size of the input selected in this paper is
.
(3) Experiments on the number of 3D convolutional kernels
The number of convolution kernels of the two 3D convolutional layers is denoted as
and
, respectively. To reduce the amount of data sent to ViT as much as possible,
is set to 8. The convolutional kernel number of the 1st layer 3D-CNN is set to 8, 16, 32, 64 and 128 respectively. The overall accuracies are shown in
Figure 10. When the convolutional kernel number is 64, the classification accuracies for the three datasets are all the best, so
is set to 64 in this paper.
(4) Experiments on the size of the depth-wise convolutional kernels
The depth-wise convolutional kernel size in the Res-SEConv module is set experimentally. The size of the depth-wise convolution kernel is recorded as
. For
G being 3, 5, 7, 9 and 11, respectively, the classification results are displayed in
Figure 11. We can find that the size of the depth-wise convolutional kernel in the Res-SEConv module has the greatest impact on the IP dataset and has less impact on the other two datasets. However, the classification accuracy shows an increasing trend followed by a decreasing trend with an increase in
G. The highest OAs are achieved for all three datasets when the kernel size is
. Therefore, the depth-wise convolutional kernel size is set to
.
(5) Experiments on the activation function of the Res-SEConv module
The activation in the Res-SEConv module is GeLU. Unlike ReLU, GELU weights the inputs according to their magnitude; ReLUs are gated according to the sign of the inputs. GeLU is intuitively more in line with the natural understanding and has been experimentally superior to ReLU in several computer vision tasks. The comparison experiments between ReLu and GeLU in the Res-SEConv module are conducted and the experimental results are shown in
Table 6. It can be seen that the general result of using GeLU in the Res-SEConv module is better than using ReLU.
(6) Experiments on the learning rate and batch size
The experimental results of learning rate and batch size on the IP dataset are shown in
Table 7 and
Table 8. The best classification performance is achieved when the learning rate and batch size are 0.0001 and 64.
4.4. Ablation Experiments
Five sets of ablation experiments on the SSSFE module, Res-SEConv module and VTFE module are designed (as in
Table 9) and the experimental results on the IP dataset further demonstrate the effectiveness of each module in the SDFE method.
From
Table 9, we can find that the OA, AA and Kappa are 90.10%, 92.98% and 88.69%, respectively, while using the CNN-based SSSFE module and Res-SEConv module. Compared with it, the OA and Kappa have an increase of about 1%, but AA decreases about 4.74% while only using the VTFE module, which indicates the Transformer is effective in HSI classification. When the SSSFE module is added to the VTFE module, the OA, AA and Kappa are increased by 7.04%, 10.05% and 3.03%, respectively. When the Res-SEConv module is added to the VTFE module, the OA, AA and Kappa are increased by 4.26%, 5.82% and 4.85%, respectively. Overall, the shallow feature extraction using the SSSFE module or Res-SEConv module is superior to no shallow feature extraction before the VTFE module for HSI classification. While the three modules work together, OA, AA and Kappa reach more than 99%, which are the best classification results. This not only proved the effectiveness of the SDFE method but also proved that the constructed SSSFE and Res-SEConv modules can jointly strengthen shallow further.
4.5. Comparison Experiments
To compare the discrepancy between the SDFE method and other baselines, comparative experiments are conducted on the datasets of IP, PU and SA. Representative methods are selected for comparative experiments, which include traditional SVM machine learning method [
14], CNN-based methods, such as 2D-CNN [
22], 3D-CNN [
23], HybridSN [
24] and Transformer-based methods ViT [
30] and SSFTT [
35]. These comparative experiments are described as follows:
- (1)
2D-CNN: The network contains two convolutional layers of size with the numbers 30 and 90 and three FC layers. The activation function and classifier are ReLU and SoftMax, respectively.
- (2)
3D-CNN: The network contains three convolutional layers and three FC layers.
- (3)
HybridSN: This contains three 3D convolutional layers and one 2D convolutional layer, as well as three FC layers.
- (4)
ViT: The input size of the network is
. The remaining parameters are the same as those given in [
31].
- (5)
SSFTT: The specific network structure settings are the same as in [
35].
The comparisons of the classification performance between SDFE and other baselines on the three datasets are shown in
Table 10,
Table 11 and
Table 12, which proves that the SDFE method can obtain the best classification results.
The accuracies of SDFE are greatly improved compared with other methods for the IP dataset. It significantly outperforms traditional machine learning methods and CNNs and slightly outperforms Transformer-based classification models for the PU and SA datasets. This may be because CNN-based methods lose long-term information to some extent and Transformer-based methods cannot fully extract spatial neighborhood information. However, the SSFTT method and the proposed method make use of the advantages of both CNN and Transformer to some extent. In particular, the shallow spatial and spectrum features are enhanced using the constructed SSSFE module and Res-SEConv module, respectively, which greatly promote the classification effectiveness.
To observe the classification effectiveness, the classification maps using the above methods are given in
Figure 12,
Figure 13 and
Figure 14. For the sake of clear presentation, some illegible misclassification points are framed with red rectangles and are enlarged as shown in
Figure 12h,i,
Figure 13 and
Figure 14h, respectively. The first image is the ground truth and then the remaining images correspond to
Figure 12a–g in sequence from left to right for
Figure 12h,i and from top to bottom for
Figure 13h and
Figure 14h. It can be seen that the classification maps obtained by the SDFE network are most similar to the ground truth. SVM, 2D-CNN, HybridSN, 3D-CNN and ViT obviously cannot identify the type accurately and have poor performance.
Figure 12 suggests that the Grass-Pasture-mowed (light blue) marked by the red box-1 in the middle area of the IP dataset is the most difficult to distinguish, which is easily misclassified as the Grass-Pasture (light pink). In addition, the differences between the results are large when using different methods in the areas marked by the red box-2. Compared with using the SSFTT method, the soybean-mintill (dark green) and soybean-nottill (yellow) can be classified better using the SDFE method.
For the PU dataset, the results of the SDFE method for classification are the most prominent in the marked area (
Figure 13). The edge misclassification of the Bricks class (light blue) using the other methods is significantly corrected by using the proposed method.
For the SA dataset, the classification maps (
Figure 14) demonstrate that the SDFE method is more precise than baselines at the boundaries between the different categories, such as the boundary between the Fallow_rough_plow (pink) and Fallow_smooth (green) marked by a red box. In conclusion, the benefits of the SDFE method are further illustrated.
To investigate the effectiveness of SDFE with different proportions of training data, training samples are randomly selected of 5%, 10%, 15% and 20% of the IP dataset, as well as 2%, 5%, 8% and 11% of the PU and SA datasets.
Figure 15 shows the classification accuracies under different training data ratios. It can be found that the classification accuracies of all compared methods show an upward trend as the proportion of training samples increases. The advantage of SDFE is more obvious than baselines under a few training samples, which indicates that SDFE is still useful for fewer samples. However, due to a large amount of computation of the Transformer, the SDFE method has certain limitations on memory consumption and time cost and thus needs to be optimized in future research.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}