
Expanding the Detection of Traversable Area with RealSense for the Visually Impaired



Abstract
:1. Introduction
2. Related Work
- The 3D point cloud generated from the RealSense R200 is adjusted from the camera coordinate system to the world coordinate system with a measured sensor attitude angle, such that the sample errors are decreased to a great extent and the preliminary plane is segmented correctly.
- The seeded region, growing adequately, considers the traversable area as connected parts, and expands the preliminary segmentation result to broader and longer ranges with RGB information.
- The seeded region growing starts with preliminarily-segmented pixels other than according to the random number, thus the expansion is inherently stable between frames, which means the output will not fluctuate and confuse VIP. The seeded region growing is not reliant on a single threshold, and edges of the RGB image and depth differences are also considered to restrict growing into non-traversable area.
- The approach does not require the depth image from sensor to be accurate or dense in long-range area, thus most consumer RGB-D sensors meet the requirements of the algorithm.
- The sensor outputs efficient IR image pairs under both indoor and outdoor circumstances, ensuring practical usability of the approach.
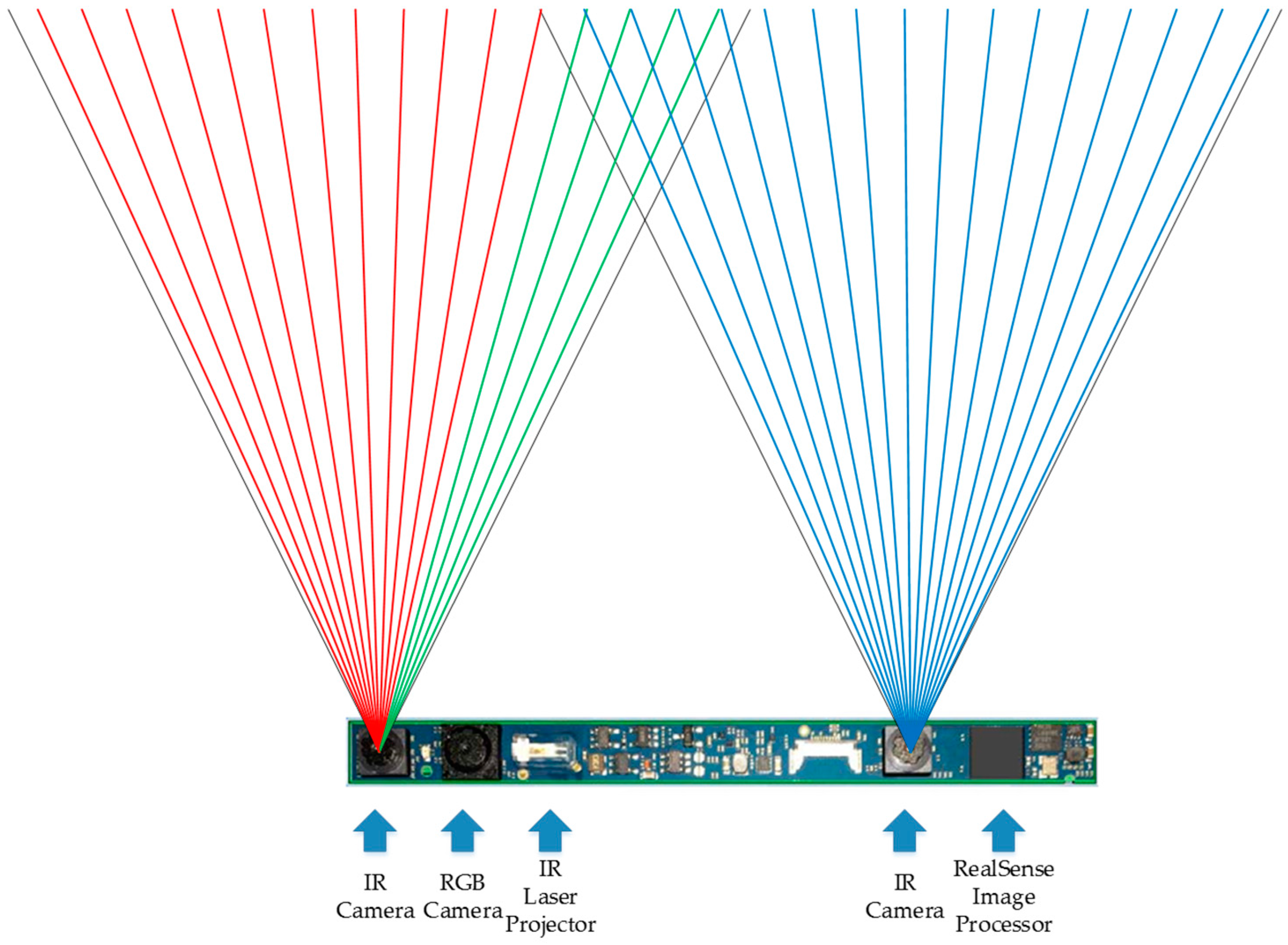
3. Approach
3.1. Depth Image Enhancement
3.2. Preliminary Ground Segmentation
- The inclination angle of the sampled plane can be calculated using Equation (7). This allows for dismissing some sample errors described in [25]. For example, if inclination angle of a sampled plane is abnormally high, the plane could not be the ground plane.
- Since the incorrect sampled planes are dismissed directly, the validation of inlier 3D points can be skipped to save much computing time.
- Given points in the world coordinate system, we obtain a subset of 3D points which only contains points whose real height is reasonable to be ground according to the position of the camera while the prototype is worn. Points which could not be ground points, such as points in the upper air are not included. As a result, the percentage of outliers is decreased, so , the number of computations, is decreased and, thereby, a great deal of processing time is saved.
3.3. Seeded Region Growing
- Gi is not located at Canny edges of color image;
- Gi has not been traversed during the expansion stage;
- Real height of Gi is reasonable to be included in traversable area; and
- or , where is the lower hue growing threshold, and is the higher growing threshold, while the height growing threshold, limits the expansion with only the color image.
4. Experiment
5. User Study
5.1. Assisting System Overview
5.2. Non-Semantic Stereophonic Interface
- Divide the detection result into five directions, since the horizontal field view has been enlarged from 59° to 70°, so each direction corresponds to traversable area with a range of 14°.
- Each direction of traversable area is represented by a musical instrument in 3D space.
- In each direction, the longer the traversable area, the greater the sound from the instrument.
- In each direction, the wider the traversable area, the higher the pitch of the instrument.
5.3. Assisting Performance Study
6. Conclusions
Author Contributions
Conflicts of Interest
References
- World Health Organization. Available online: www.who.int/mediacentre/factsheets/fs282/en (accessed on 7 November 2016).
- PrimeSense. Available online: www.en.wikipedia.org/wiki/PrimeSense (accessed on 7 November 2016).
- Kinect. Available online: www.en.wikipedia.org/wiki/Kinect (accessed on 7 November 2016).
- Xtion Pro. Available online: www.asus.com.cn/3D-Sensor/Xtion_PRO (accessed on 7 November 2016).
- Mantis Vision. Available online: www.mv4d.com (accessed on 7 November 2016).
- Structure Sensor. Available online: structure.io (accessed on 7 November 2016).
- Zöllner, M.; Huber, S.; Jetter, H.; Reiterer, H. NAVI—A Proof-of-Concept of a Mobile Navigational Aid for Visually Impaired Based on the Microsoft Kinect. Human-Computer Interaction—INTERACT 2011; Springer: Berlin/Heidelberg, Germany, 2007; Volume 6949, pp. 584–587. [Google Scholar]
- Hicks, S.L.; Wilson, I.; Muhammed, L.; Worsfold, J.; Downes, S.M.; Kennard, C. A depth-based head-mounted visual display to aid navigation in partially sighted individuals. PLoS ONE 2013, 8, e67695. [Google Scholar] [CrossRef] [PubMed]
- Aladren, A.; Lopez-Nicolas, G.; Puig, L.; Guerrero, J.J. Navigational assistance for the visually impaired using rgb-d sensor with range expansion. IEEE Syst. J. 2014, 99, 1–11. [Google Scholar]
- Takizawa, H.; Yamaguchi, S.; Aoyagi, M.; Ezaki, N.; Mizuno, S. Kinect cane: An assistive system for the visually impaired based on three-dimensional object recognition. Pers. Ubiquitous Comput. 2012, 19, 740–745. [Google Scholar]
- Park, C.H.; Howard, A.M. Real-time haptic rendering and haptic telepresence robotic system for the visually impaired. In Proceedings of the World Haptics Conference, Daejeon, Korea, 14–18 April 2013; pp. 229–234.
- Khan, A.; Moideen, F.; Lopez, J.; Khoo, W.L.; Zhu, Z. KinDetect: Kinect Detecting Objects. In Computers Helping People with Special Needs; Springer: Berlin/Heidelberg, Germany, 2012; pp. 588–595. [Google Scholar]
- Ribeiro, F.; Florencio, D.; Chou, P.A.; Zhang, Z. Auditory augmented reality: Object sonification for the visually impaired. IEEE Int. Workshop Multimed. Signal Proc. 2012, 11, 319–324. [Google Scholar]
- Yang, K.; Wang, K.; Cheng, R.; Zhu, X. A new approach of point cloud processing and scene segmentation for guiding the visually impaired. In Proceedings of the IET International Conference on Biomedical Image and Signal Processing, Beijing, China, 19 November 2015.
- Cheng, R.; Wang, K.; Yang, K.; Zhao, X. A ground and obstacle detection algorithm for the visually impaired. In Proceedings of the IET International Conference on Biomedical Image and Signal Processing, Beijing, China, 19 November 2015.
- PMD. Available online: www.pmdtec.com (accessed on 7 November 2016).
- SoftKinetic. Available online: www.softkinetic.com (accessed on 7 November 2016).
- HEPTAGON. Available online: hptg.com/industrial (accessed on 7 November 2016).
- Zeng, L.; Prescher, D.; Webber, G. Exploration and avoidance of surrounding obstacles for the visually impaired. In Proceedings of the 14th International ACM SIGACCESS Conference on Computers and Accessibility, Boulder, CO, USA, 22–24 October 2012; pp. 111–118.
- Tamjidi, A.; Ye, C.; Hong, S. 6-DOF pose estimation of a Portable Navigation Aid for the visually impaired. In Proceedings of the IEEE International Symposium on Robotics and Sensors Environments, Washington, DC, USA, 21–23 October 2013; pp. 178–183.
- Lee, C.H.; Su, Y.C.; Chen, L.G. An intelligent depth-based obstacle detection for visually-impaired aid applications. In Proceedings of the IEEE 2012 13th International Workshop on Image Analysis for Multimedia Interactive Services (WIAMIS), Dublin, Ireland, 23–25 May 2012; pp. 1–4.
- PointGrey Bumblebee. Available online: www.ptgrey.com/bumblebee2-firewire-stereo-vision-camera-systems (accessed on 7 November 2016).
- Stereolabs. Available online: www.stereolabs.com (accessed on 7 November 2016).
- DUO. Available online: duo3d.com (accessed on 7 November 2016).
- Rodríguez, A.; Yebes, J.J.; Alcantarilla, P.F.; Bergasa, L.M.; Almazán, J.; Cele, A. Assisting the visually impaired: Obstacle detection and warning system by acoustic feedback. Sensors 2011, 12, 17476–17496. [Google Scholar] [CrossRef] [PubMed]
- Lee, Y.H.; Medioni, G. RGB-D camera based navigation for the visually impaired. In Proceedings of the RSS RGBD Advanced Reasoning with Depth Camera Workshop, Los Angeles, CA, USA, 27 June 2011.
- Martinez, J.M.S.; Ruiz, F.E. Stereo-based aerial obstacle detection for the visually impaired. In Proceedings of the Workshop on Computer Vision Applications for the Visually Impaired, Marseille, France, 18 October 2008.
- Lin, K.W.; Lau, T.K.; Cheuk, C.M.; Liu, Y. A wearable stereo vision system for visually impaired. In Proceedings of the 2012 International Conference on Mechatronics and Automation (ICMA), Chengdu, China, 5–8 August 2012; pp. 1423–1428.
- Intel RealSense R200. Available online: software.intel.com/en-us/realsense/r200camera (accessed on 7 November 2016).
- Kytö, M.; Nuutinen, M.; Oittinen, P. Method for measuring stereo camera depth accuracy based on stereoscopic vision. Proc. SPIE Int. Soc. Opt. Eng. 2011. [Google Scholar] [CrossRef]
- Getting Started with the Depth Data Provided by Intel RealSense Technology. Available online: software.intel.com/en-us/articles/realsense-depth-data (accessed on 7 November 2016).
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Comm. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- InvenSense MPU-6050. Available online: www.invensense.com/products/motion-tracking/6-axis/mpu-6050 (accessed on 7 November 2016).
- Adams, R.; Bischof, L. Seeded Region Growing. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 641–647. [Google Scholar] [CrossRef]
- Wang, T.; Bu, L.; Huang, Z. A new method for obstacle detection based on Kinect depth image. IEEE Chin. Autom. Congr. 2015. [Google Scholar] [CrossRef]
- Perez-Yus, A.; Gutierrez-Gomez, D.; Lopez-Nicolas, G.; Guerrero, J.J. Stairs detection with odometry-aided traversal from a wearable RGB-D camera. Comput. Vis. Image Underst. 2016, in press. [Google Scholar] [CrossRef]
- Wang, Z.; Huang, S.; Dissanayake, G. Simultaneous Localization and Mapping; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Lee, Y.H.; Medioni, G. RGB-D camera based wearable navigation system for the visually impaired. Comput. Vis. Image Underst. 2016, 149, 3–20. [Google Scholar] [CrossRef]
- Sánchez, C.; Taddei, P.; Ceriani, S.; Wolfart, E.; Sequeira, V. Localization and tracking in known large environments using portable real-time 3D sensors. Comput. Vis. Image Underst. 2016, 139, 197–208. [Google Scholar] [CrossRef]
- Koester, D.; Schauerte, B.; Stiefelhagen, R. Accessible section detection for visual guidance. In Proceedings of the IEEE International Conference on Multimedia and Expo Workshops, San Jose, CA, USA, 15–19 July 2013; Volume 370, pp. 1–6.
- Bellone, M.; Messina, A.; Reina, G. A new approach for terrain analysis in mobile robot applications. In Proceedings of the IEEE International Conference on Mechatronics, Wollongong, Australia, 9–12 July 2013; Volume 307, pp. 225–230.
- Chessa, M.; Noceti, N.; Odone, F.; Solari, F.; Sosa-García, J.; Zini, L. An integrated artificial vision framework for assisting visually impaired users. Comput. Vis. Image Underst. 2015, 149, 209–228. [Google Scholar] [CrossRef]
- Hadsell, R.; Sermanet, P.; Ben, J.; Erkan, A.; Scoffier, M.; Kavukcuoglu, K. Learning long-range vision for autonomous off-road driving. J. Field Robot. 2009, 26, 120–144. [Google Scholar] [CrossRef]
- Reina, G.; Milella, A. Towards autonomous agriculture: Automatic ground detection using trinocular stereovision. Sensors 2012, 12, 12405–12423. [Google Scholar] [CrossRef]
- Milella, A.; Reina, G.; Underwood, J.; Douillard, B. Visual ground segmentation by radar supervision. Robot. Auton. Syst. 2014, 62, 696–706. [Google Scholar] [CrossRef]
- Reina, G.; Milella, A.; Rouveure, R. Traversability analysis for off-road vehicles using stereo and radar data. In Proceedings of the IEEE International Conference on Industrial Technology, Seville, Spain, 17–19 March 2015.
- Damen, D.; Leelasawassuk, T.; Mayol-Cuevas, W. You-Do, I-Learn: Egocentric unsupervised discovery of objects and their modes of interaction towards video-based guidance. Comput. Vis. Image Underst. 2016, 149, 98–112. [Google Scholar] [CrossRef]
- Geiger, A.; Roser, M.; Urtasun, R. Efficient Large-Scale Stereo Matching. Asian Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6492, pp. 25–38. [Google Scholar]
- Einecke, N.; Eggert, J. A multi-block-matching approach for stereo. In Proceedings of the 2015 IEEE Intelligent Vehicles Symposium (IV), Seoul, Korea, 28 June–1 July 2015; pp. 585–592.
- He, K.; Sun, J.; Tang, X. Guided Image Filtering. IEEE Trans. Softw. Eng. 2013, 35, 1397–1409. [Google Scholar] [CrossRef] [PubMed]
- Intel RealSense Depth Enabled Photography. Available online: software.intel.com/en-us/articles/intel-realsense-depth-enabled-photography (accessed on 7 November 2016).
- Kaiwei Wang Team. Available online: wangkaiwei.org (accessed on 7 November 2016).
- AfterShokz BLUEZ 2S. Available online: www.aftershokz.com.cn/bluez-2s (accessed on 7 November 2016).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario | Frames with Ground (G) | FRAMES Detected Ground Correctly (GD) | Detection Rate (DR) | Frames Expanded to Non-Ground Areas (ENG) | Expansion Error (EE) |
|---|---|---|---|---|---|
| An office | 1361 | 1259 | 92.5% | 44 | 3.2% |
| A corridor | 633 | 614 | 97.0% | 101 | 15.9% |
| School roads | 837 | 797 | 95.2% | 81 | 9.7% |
| A playground | 231 | 228 | 98.7% | 13 | 5.6% |
| All | 3062 | 2898 | 94.4% | 239 | 7.8% |
| Scenario | Original Depth Image (Resolution: 293,904) | Large Scale Mathced Depth Image (Resolution: 293,904) | Guided Filtered Depth Image (Resolution: 360,000) |
|---|---|---|---|
| An office | 68.6% | 89.4% | 100% |
| A corridor | 61.4% | 84.5% | 100% |
| School roads | 76.2% | 91.2% | 100% |
| A playground | 79.5% | 92.0% | 100% |
| Detection Result Transfered to VIP | Total Number of Collisions | Average Number of Collisions of Each Time | Total Time to Complete Tests | Average Time to Complete a Single Test | Total Number of Steps | Average Number of Steps to Complete a Single Test |
|---|---|---|---|---|---|---|
| Original ground deteciton | 103 | 2.58 | 733 s | 18.33 s | 1850 | 46.25 |
| Traversable area expansion | 22 | 0.55 | 517 s | 12.93 s | 1047 | 26.18 |
| User | Total Blind or Partially Sighted | Easy to Wear? | Useful? | Advice |
|---|---|---|---|---|
| User 1 | Partially sighted | Yes | Yes | |
| User 2 | Partially sighted | Yes | Yes | Add face recognition |
| User 3 | Total blind | Yes | Yes | Design the prototype in a hat |
| User 4 | Partially sighted | Yes | Yes | |
| User 5 | Partially sighted | No | Yes | Add GPS navigation |
| User 6 | Total blind | Yes | Yes | |
| User 7 | Total blind | No | Yes | |
| User 8 | Partially sighted | Yes | Yes |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, K.; Wang, K.; Hu, W.; Bai, J. Expanding the Detection of Traversable Area with RealSense for the Visually Impaired. Sensors 2016, 16, 1954. https://doi.org/10.3390/s16111954
Yang K, Wang K, Hu W, Bai J. Expanding the Detection of Traversable Area with RealSense for the Visually Impaired. Sensors. 2016; 16(11):1954. https://doi.org/10.3390/s16111954
Chicago/Turabian StyleYang, Kailun, Kaiwei Wang, Weijian Hu, and Jian Bai. 2016. "Expanding the Detection of Traversable Area with RealSense for the Visually Impaired" Sensors 16, no. 11: 1954. https://doi.org/10.3390/s16111954