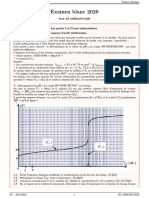
Cours5 Slides
Cours5 Slides
Télécharger au format pdf ou txt
Vous aimerez peut-être aussi
- GeoServer User ManualDocument160 pagesGeoServer User ManualMnr CamillePas encore d'évaluation
- Avis de RechercheDocument20 pagesAvis de RechercheRamseyPas encore d'évaluation
- 1 - REGRESSION LINEAIRE SIMPLE - Liaison Et Dépendance Entre Deux Variables Quantitatives 34S PDFDocument34 pages1 - REGRESSION LINEAIRE SIMPLE - Liaison Et Dépendance Entre Deux Variables Quantitatives 34S PDFbaharPas encore d'évaluation
- Presentation ABS ESPDocument22 pagesPresentation ABS ESPCydor Raveloson100% (1)
- Cours SegmentationDocument43 pagesCours Segmentationhabitav2023Pas encore d'évaluation
- Descriptives StatistiqueDocument13 pagesDescriptives StatistiqueyayacheriftraorePas encore d'évaluation
- Cours de StatistiquesDocument3 pagesCours de StatistiquesAbdessatar GouiderPas encore d'évaluation
- Apprentissage Non Supervisé 1Document129 pagesApprentissage Non Supervisé 1equipeprotobilePas encore d'évaluation
- Cours de Statistic 1 Et 2Document6 pagesCours de Statistic 1 Et 2Bilal SaghirPas encore d'évaluation
- Statistiques Descriptives À Une Ou Deux DimensionsDocument10 pagesStatistiques Descriptives À Une Ou Deux DimensionsJasmine BenhalimaPas encore d'évaluation
- Lin Analyse DonnéesDocument10 pagesLin Analyse DonnéesNicaisePas encore d'évaluation
- 2015 16.cours - StatsDocument16 pages2015 16.cours - StatsBalla KonePas encore d'évaluation
- Clustering (Tchi Drive)Document10 pagesClustering (Tchi Drive)kamel eddinePas encore d'évaluation
- Cours1 ADDDocument30 pagesCours1 ADDYassine MadaniPas encore d'évaluation
- Sopport Cours Statistiques Partie1-F InitialDocument50 pagesSopport Cours Statistiques Partie1-F Initialsabyhkeltoum19Pas encore d'évaluation
- Cours Classification OuazzaDocument40 pagesCours Classification OuazzaChaima ChichanePas encore d'évaluation
- Chapitre1: Statistique Descriptive 1: 2.1 Population Et IndividusDocument12 pagesChapitre1: Statistique Descriptive 1: 2.1 Population Et Individusmerroukiwassim2024Pas encore d'évaluation
- Formulaire ADDocument3 pagesFormulaire ADbouroualicia2022Pas encore d'évaluation
- L3 Cours KNNDocument22 pagesL3 Cours KNNMardochee ROBNDOHPas encore d'évaluation
- Diapos Proba11042023Document111 pagesDiapos Proba11042023gandonouorpheliaPas encore d'évaluation
- MID RDF 02Document53 pagesMID RDF 02bay127prem.ensmaPas encore d'évaluation
- Chapitre 02 (Présentation)Document46 pagesChapitre 02 (Présentation)Batoul DjoghPas encore d'évaluation
- Chapitre 1 ADDocument73 pagesChapitre 1 ADAref ChaariPas encore d'évaluation
- M147 - Cours (Statistique)Document69 pagesM147 - Cours (Statistique)Saloua El MarriPas encore d'évaluation
- CHAP1 - ACP Mni3i PDFDocument26 pagesCHAP1 - ACP Mni3i PDFMouhcine Zianee100% (1)
- Cours Statistiques DescriptivesDocument7 pagesCours Statistiques Descriptivestaha elatouiPas encore d'évaluation
- Chapitre 3 ClusteringDocument50 pagesChapitre 3 Clusteringhoussem yahyaoui100% (1)
- ADD Partie 2Document13 pagesADD Partie 2emed40941Pas encore d'évaluation
- Cours 1Document29 pagesCours 1SAFOPas encore d'évaluation
- Chap3 ClusteringDocument48 pagesChap3 Clusteringwassim.elhaniPas encore d'évaluation
- Stats BivarieesDocument12 pagesStats BivarieesjreisjoellePas encore d'évaluation
- Formulaire L1Document12 pagesFormulaire L1Abdelbast El HadiPas encore d'évaluation
- Correction TerminaleComplementaires Statistiques 2021 PDFDocument32 pagesCorrection TerminaleComplementaires Statistiques 2021 PDFبدر الذهابيPas encore d'évaluation
- Cours - Data Science Intro+ACPDocument63 pagesCours - Data Science Intro+ACPsalma tn100% (1)
- Séance 02Document18 pagesSéance 02ayoubhaouasPas encore d'évaluation
- Chapitre IDocument12 pagesChapitre IkoulliredouanePas encore d'évaluation
- TP3-24-25 (1)Document3 pagesTP3-24-25 (1)sindashm18Pas encore d'évaluation
- Cours Add MMBDSDocument25 pagesCours Add MMBDSAbdallahi SidiPas encore d'évaluation
- Aide-Mémoire Stats Nancy 2018Document31 pagesAide-Mémoire Stats Nancy 2018Zoubir DraiPas encore d'évaluation
- Chapitre 3Document21 pagesChapitre 3Nour ElhoudaPas encore d'évaluation
- Chapitre 1Document11 pagesChapitre 1Ahmed NsirPas encore d'évaluation
- Wa0003.Document16 pagesWa0003.Mame diarra bousso NdiayePas encore d'évaluation
- Cour StatestiqueDocument50 pagesCour StatestiqueYoussef LeSafioPas encore d'évaluation
- ExtraitDocument9 pagesExtraitGloirePas encore d'évaluation
- 818Document81 pages818Silviu100% (1)
- Éléments de Statistique DescriptiveDocument19 pagesÉléments de Statistique DescriptiveSidoïne Bitho GbeteyPas encore d'évaluation
- Statistiques Cours 5Document3 pagesStatistiques Cours 5MoiPas encore d'évaluation
- Résumé Trés Simple de StatistiqueDocument2 pagesRésumé Trés Simple de StatistiqueAmine NadraouiPas encore d'évaluation
- Chapitre 3Document40 pagesChapitre 3Dia Mouhamadou NabyPas encore d'évaluation
- Cours Stat Np EnsiieDocument286 pagesCours Stat Np Ensiiealoys NdziePas encore d'évaluation
- Analyse de Données PDFDocument38 pagesAnalyse de Données PDFJunior Ebong MoudoubouPas encore d'évaluation
- statist 214Document18 pagesstatist 214nacerbensaPas encore d'évaluation
- Statistique DescriptiveDocument10 pagesStatistique DescriptiveAthmane ManouPas encore d'évaluation
- Chap2 Stat L1MPIDocument14 pagesChap2 Stat L1MPIbaahmadou1339Pas encore d'évaluation
- 17 StatistiqueDocument5 pages17 StatistiquesdritessePas encore d'évaluation
- TD3 EnoncéDocument2 pagesTD3 EnoncéSaif GuesmiPas encore d'évaluation
- cours_suDocument66 pagescours_suDJAZOULI ADELPas encore d'évaluation
- ch3 ML - 221126 - 094552Document41 pagesch3 ML - 221126 - 094552aicha benslimenPas encore d'évaluation
- Chap 1 Stat 1 Et 2 DimsDocument45 pagesChap 1 Stat 1 Et 2 DimsHicham BounyanePas encore d'évaluation
- Cours1.3 2019Document35 pagesCours1.3 2019HilairePas encore d'évaluation
- 02-Modeling Process QualityDocument33 pages02-Modeling Process Qualitytsito razafinjoPas encore d'évaluation
- Scoring CorrectionsDocument32 pagesScoring CorrectionsMarie Vierge Meli JoundaPas encore d'évaluation
- Équations différentielles: Les Grands Articles d'UniversalisD'EverandÉquations différentielles: Les Grands Articles d'UniversalisPas encore d'évaluation
- Synthèse S1Document4 pagesSynthèse S1becharamehdi660Pas encore d'évaluation
- TD Electrostatique (1) - CorDocument9 pagesTD Electrostatique (1) - CormissmaymounaPas encore d'évaluation
- GESTION PREVISIONNELLE - NPHB-Master-2024-3Document26 pagesGESTION PREVISIONNELLE - NPHB-Master-2024-3achillesia12Pas encore d'évaluation
- Mémoire MarketingDocument59 pagesMémoire Marketingtshiendachristelle19100% (1)
- Présentation Référence de La Société E.IDocument40 pagesPrésentation Référence de La Société E.IwasoldoPas encore d'évaluation
- Emploi Du Temps de Geographie Du 18 Au 23 Novembre 2024Document3 pagesEmploi Du Temps de Geographie Du 18 Au 23 Novembre 2024cs5522520Pas encore d'évaluation
- Feuillet - Approches TypologiquesDocument2 pagesFeuillet - Approches TypologiquesAmmar KulićPas encore d'évaluation
- Little Bird Johnson CraigDocument449 pagesLittle Bird Johnson CraigZouheirMoufdiPas encore d'évaluation
- Ifc So-2Document122 pagesIfc So-2bright akpah100% (1)
- HématologieDocument80 pagesHématologiesafaegreek20Pas encore d'évaluation
- Guidage en Rotation Par Roulements (BT Et KB)Document6 pagesGuidage en Rotation Par Roulements (BT Et KB)MIMFS69% (13)
- Industrie Hoteliere Francaise en 2012 PDFDocument67 pagesIndustrie Hoteliere Francaise en 2012 PDFMIMKANPas encore d'évaluation
- Corrigeě BTS Maths A PDFDocument4 pagesCorrigeě BTS Maths A PDFAbdelmajid LechhabPas encore d'évaluation
- 3 Devoir Maison Vacances de FevrierDocument2 pages3 Devoir Maison Vacances de Fevrierbounounou270Pas encore d'évaluation
- 689 875 1 PB PDFDocument22 pages689 875 1 PB PDFreluPas encore d'évaluation
- Menu Semaine Du 04.01 Au 10.01Document1 pageMenu Semaine Du 04.01 Au 10.01Lou AnnPas encore d'évaluation
- Correction Exam 2 s1Document2 pagesCorrection Exam 2 s1elhadouni114Pas encore d'évaluation
- Exem PCDocument6 pagesExem PCwfwgPas encore d'évaluation
- Série de TD4 - Suites Et Series de Fonctions & SolutionsDocument7 pagesSérie de TD4 - Suites Et Series de Fonctions & SolutionsAbdelaziz MezianPas encore d'évaluation
- Brique Tactique. Section 3. Le Combat Du TrinômeDocument20 pagesBrique Tactique. Section 3. Le Combat Du TrinômeswizzyellqcostzPas encore d'évaluation
- Exercice 1: Attaques Sur Le Cryptosystème de Cesar: Senario KPA: Ciphrtext GozihDocument3 pagesExercice 1: Attaques Sur Le Cryptosystème de Cesar: Senario KPA: Ciphrtext GozihLet's Go TlmPas encore d'évaluation
- Speech Therapy Language Rehabilitation For Children With Mental Disabilities20240219043347Document23 pagesSpeech Therapy Language Rehabilitation For Children With Mental Disabilities20240219043347vigolaforcePas encore d'évaluation
- Theoreme Central Limite Cours 02Document4 pagesTheoreme Central Limite Cours 02Noredin FaizPas encore d'évaluation
- Mode D'emploi ROSIERESDocument32 pagesMode D'emploi ROSIERESIsabelle GrandjeanPas encore d'évaluation
- (Castera) Calcul TensorielDocument269 pages(Castera) Calcul TensorielVbsa BsaPas encore d'évaluation
- Dzexams 1as Francais 698185Document5 pagesDzexams 1as Francais 698185Yassmin MimiPas encore d'évaluation
- Modélisation Et Commande MPPT D'un Système Photovoltaïque AutonomeDocument66 pagesModélisation Et Commande MPPT D'un Système Photovoltaïque AutonomeenglishzeghdarPas encore d'évaluation