




BigData_TP3 : Spark
- 1. Institut National des Sciences Appliquées et de Technologie Tunisie Big Data 2015-2016 TP3- SPARK Dr. Lilia SFAXI Objectifs du TP : Introduction à Apache Spark, exemples d’utilisation et performance
- 2. TP3 : Spark Page 2 I. Apache Spark1 I.1 Spark vs MapReduce2 Apache Spark a été créé au départ pour pallier les limitations de Hadoop Map/Reduce. En effet, ce dernier, qui s’avère être idéal pour implémenter des applications à base de traitements par lot (batch processing), montre certaines limites quand il s’agit d’applications à faible latence et à traitements itératifs, comme par exemple pour le machine learning ou pour les algorithmes à base de graphes. Spark permet de généraliser le modèle de traitement de Map-Reduce, tout en améliorant de manière conséquente les performances et l’utilisabilité. Il permet aux développeurs d’écrire des applications en composant facilement des opérateurs tels que des mappers, reducers, jointures, group-bys et filtres. Cette composition facilite l’expression d’un ensemble large de traitements. De plus, Spark garde la trace des données que chacun de ces opérateurs produit, et permet aux applications de stocker ces données en mémoire, améliorant ainsi considérablement la performance en permettant d’éviter les accès coûteux au disque. Hadoop Map Reduce est efficace pour les traitements à passe unique (un seul passage sur les données), mais pas pour des traitements à plusieurs passes. Pour ces traitements plus complexes, il faut enchaîner une série de jobs Map-Reduce et les exécuter séquentiellement, chacun de ces jobs présentant une latence élevée et aucun ne pouvant commencer avant que le précédent ne soit totalement terminé. Avec Spark, il est possible de développer des pipelines de traitement de données complexes, à plusieurs étapes en s’appuyant sur des graphes orientés acycliques (DAG : Directed Acyclic Graph). Spark permet de partager les données en mémoire entre les graphes, de façon à ce que plusieurs jobs puissent travailler sur le même jeu de données3 . 1 Spark: http://spark.apache.org/ 2 Inspirée du blog de Cloudera: http://blog.cloudera.com/blog/2013/11/putting-spark-to-use-fast-in-memory-2 Inspirée du blog de Cloudera: http://blog.cloudera.com/blog/2013/11/putting-spark-to-use-fast-in-memory- computing-for-your-big-data-applications/ 3 Srini Penchikala: Traitements Big Data avec Apache Spark, http://www.infoq.com/fr/articles/apache-spark-introduction
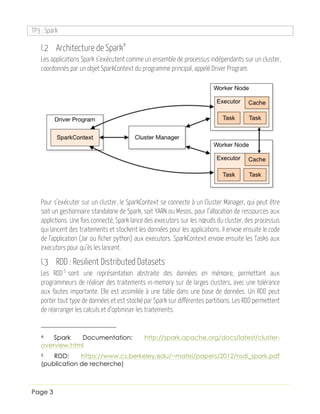
- 3. TP3 : Spark Page 3 I.2 Architecture de Spark4 Les applications Spark s’exécutent comme un ensemble de processus indépendants sur un cluster, coordonnés par un objet SparkContext du programme principal, appelé Driver Program. Pour s’exécuter sur un cluster, le SparkContext se connecte à un Cluster Manager, qui peut être soit un gestionnaire standalone de Spark, soit YARN ou Mesos, pour l’allocation de ressources aux applictions. Une fois connecté, Spark lance des executors sur les nœuds du cluster, des processus qui lancent des traitements et stockent les données pour les applications. Il envoie ensuite le code de l’application (Jar ou ficher python) aux executors. SparkContext envoie ensuite les Tasks aux executors pour qu’ils les lancent. I.3 RDD : Resilient Distributed Datasets Les RDD5 sont une représentation abstraite des données en mémoire, permettant aux programmeurs de réaliser des traitements in-memory sur de larges clusters, avec une tolérance aux fautes importante. Elle est assimilée à une table dans une base de données. Un RDD peut porter tout type de données et est stocké par Spark sur différentes partitions. Les RDD permettent de réarranger les calculs et d’optimiser les traitements. 4 Spark Documentation: http://spark.apache.org/docs/latest/cluster- overview.html 5 RDD: https://www.cs.berkeley.edu/~matei/papers/2012/nsdi_spark.pdf (publication de recherche)
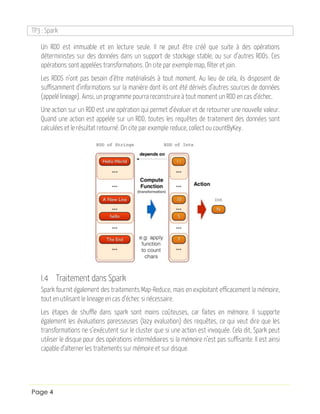
- 4. TP3 : Spark Page 4 Un RDD est immuable et en lecture seule. Il ne peut être créé que suite à des opérations déterministes sur des données dans un support de stockage stable, ou sur d’autres RDDs. Ces opérations sont appelées transformations. On cite par exemple map, filter et join. Les RDDS n’ont pas besoin d’être matérialisés à tout moment. Au lieu de cela, ils disposent de suffisamment d’informations sur la manière dont ils ont été dérivés d’autres sources de données (appelé lineage). Ainsi, un programme pourra reconstruire à tout moment un RDD en cas d’échec. Une action sur un RDD est une opération qui permet d’évaluer et de retourner une nouvelle valeur. Quand une action est appelée sur un RDD, toutes les requêtes de traitement des données sont calculées et le résultat retourné. On cite par exemple reduce, collect ou countByKey. I.4 Traitement dans Spark Spark fournit également des traitements Map-Reduce, mais en exploitant efficacement la mémoire, tout en utilisant le lineage en cas d’échec si nécessaire. Les étapes de shuffle dans spark sont moins coûteuses, car faites en mémoire. Il supporte également les évaluations paresseuses (lazy evaluation) des requêtes, ce qui veut dire que les transformations ne s’exécutent sur le cluster que si une action est invoquée. Cela dit, Spark peut utiliser le disque pour des opérations intermédiaires si la mémoire n’est pas suffisante. Il est ainsi capable d’alterner les traitements sur mémoire et sur disque.
- 5. TP3 : Spark Page 5 Activité 1 : Lire la présentation6 fournie par votre enseignante, décrivant le comportement de Spark, et en particulier l’exemple simple de traitement de texte. II. Exemple : Word Count L’exemple7 que nous allons dérouler est une version modifiée du célèbre WordCount, l’exemple Map Reduce Classique. Cet exemple permet de : 1. Lire un ensemble de documents textuels 2. Compter le nombre de fois chaque mot apparaît 3. Filtrer tous les mots qui apparaissent moins qu’un certain nombre de fois 4. Pour les mots restants, compter le nombre de fois chaque lettre apparaît Si on utilisait MapReduce, on aurait besoin de deux jobs successifs, et les données seraient persistées sur HDFS entre les deux. En contre partie, dans Spark, un seul job est nécessaire, avec presque 90% moins de lignes de code. Par défaut, Spark utilise Scala (http://www.scala-lang.org/ ), un langage qui combine les paradigmes orienté-objet et fonctionnel. Il est compilé en bytecode Java. Voici le code en Scala de l’exemple (fourni par votre enseignante) : 6 Apache Spark, Fernando Rodriguez Olivera: http://fr.slideshare.net/frodriguezolivera/apache-spark-41601032 7 How-to: Run a Simple Apache Spark App in CDH 5, Cloudera: https://blog.cloudera.com/blog/2014/04/how-to-run-a-simple-apache-spark- app-in-cdh-5/
- 6. TP3 : Spark Page 6 Pour compiler ce programme, Maven est utilisé. Pour pouvoir compiler un code Scala, ajouter les dépendances nécessaires dans le fichier pom.xml. Activité 2 : Placer votre code dans le répertoire de votre choix dans la machine virtuelle CDH5 du TP précédent. Dans cette machine, Spark est installé par défaut, dans sa version 1.5.0. Pour compiler et exécuter l’exemple simplesparkapp : 1. Dans un terminal, placez-vous sous le répertoire de base du projet 2. Taper : mvn package 3. Les dépendances nécessaires seront téléchargées, le code compilé et un fichier jar sera généré sous le même répertoire, intitulé : sparkwordcount-0.0.1-SNAPSHOT.jar 4. Charger le fichier cible du traitement dans HDFS. Vous pourrez utiliser pour commencer le fichier de test fourni sous le répertoire data du projet, puis, pour un exemple plus complexe, le fichier forum_node du TP précédent, par exemple. 5. Pour exécuter le programme Spark (code en Scala), utiliser le script spark-submit : spark-submit --class com.cloudera.sparkwordcount.SparkWordCount -- master local target/sparkwordcount-0.0.1-SNAPSHOT.jar <input file> 2 6. Pour utiliser YARN, remplacer --master local par --master yarn
- 7. TP3 : Spark Page 7 Pour le fichier de données fourni dans l’exemple, le résultat devrait ressembler à ce qui suit : (e,6), (f,1), (a,4), (t,2), (u,1), (r,2), (v,1), (b,1), (c,1), (h,1), (o,2), (l,1), (n,4), (p,2), (i,1) Activité 3 : Nous désirons comparer les performances de Map-Reduce et de Spark. Pour cela : 1. Modifier le code Scala pour afficher seulement l’occurrence de chaque mot dans le fichier 2. Implémenter le même comportement avec Map-Reduce 3. Tester les deux programmes sur : a. Le fichier de données simple pour commencer, pour voir si les codes sont corrects b. Le fichier forum_nodes Quelle est votre interprétation ? III. HomeWork Implémenter dans votre réseau social une fonctionnalité nécessitant un traitement de type batch (Map Reduce ou Spark). Votre challenge dans cette partie est de déclencher ce travail à partir de l’interface de votre application, puis d’afficher le résultat sur l’interface.