


Tip
🎉 [Updates in Feb 2024] Our survey paper Deep Learning for Multivariate Time Series Imputation: A Survey has been released on arXiv. The code is open source in the GitHub repo Awesome_Imputation. We comprehensively review the literature of the state-of-the-art deep-learning imputation methods for time series, provide a taxonomy for them, and discuss the challenges and future directions in this field.
🔥 [Updates in Apr 2024] We applied SAITS embedding and training strategies to Crossformer, PatchTST, DLinear, ETSformer, FEDformer,
Informer, Autoformer in PyPOTS
to enable them applicable to the time-series imputation task.
The official code repository is for the paper SAITS: Self-Attention-based Imputation for Time Series (preprint on arXiv is here), which has been accepted by the journal Expert Systems with Applications (ESWA) [2022 IF 8.665, CiteScore 12.2, JCR-Q1, CAS-Q1, CCF-C]. You may never have heard of ESWA, while it was ranked 1st in Google Scholar under the top publications of Artificial Intelligence in 2016 (info source), and is still the top 1 AI journal according to Google Scholar metrics (here is the current ranking list FYI).
SAITS is the first work applying pure self-attention without any recursive design in the algorithm for general time series imputation. Basically you can take it as a validated framework for time series imputation. More generally, you can use it for sequence imputation. Besides, the code here is open source under the MIT license. Therefore, you're welcome to modify the SAITS code for your own research purpose and domain applications. Of course, it probably needs a bit of modification in the model structure or loss functions for specific scenarios or data input. And this is an incomplete list of scientific research referencing SAITS in their papers.
🤗 Please cite SAITS in your publications if it helps with your work.
Please star🌟 this repo to help others notice SAITS if you think it is useful.
It really means a lot to our open-source research. Thank you!
BTW, you may also like
PyPOTS 
Important
📣 Attention please:
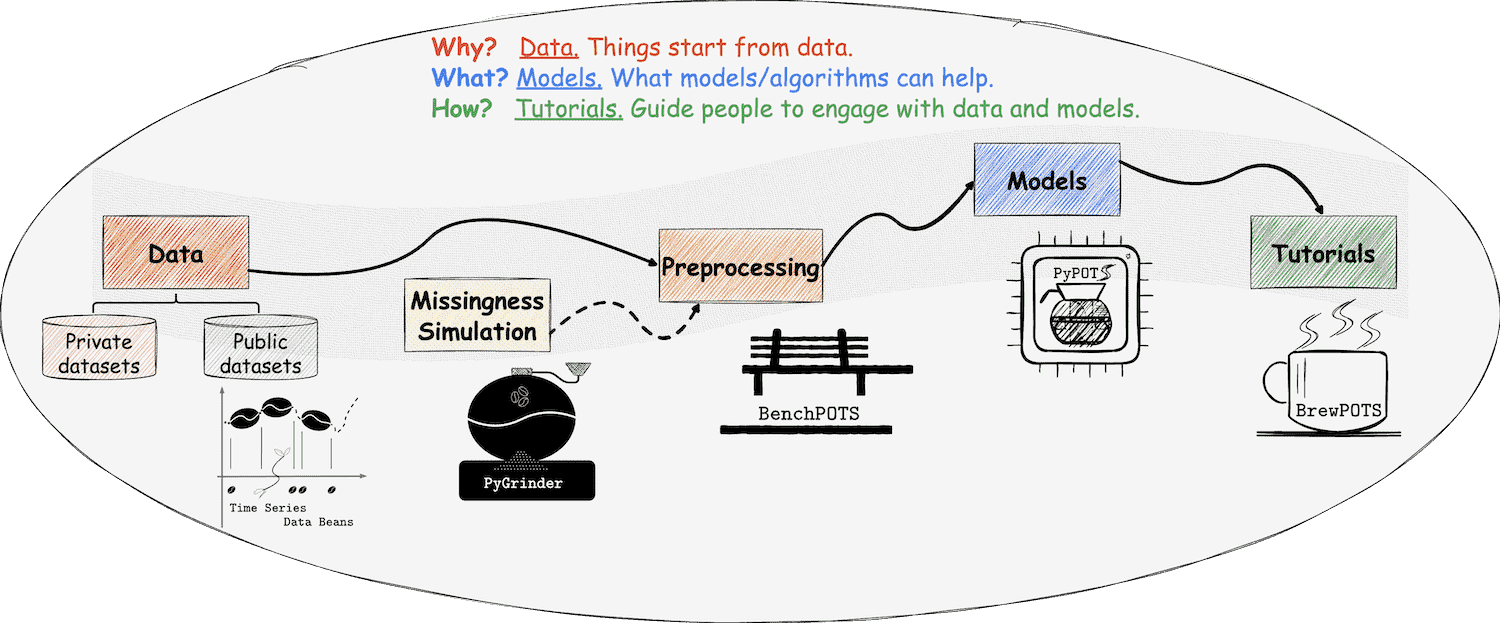
SAITS now is available in PyPOTS, a Python toolbox for data mining on POTS (Partially-Observed Time Series). An example of training SAITS for imputing dataset PhysioNet-2012 is shown below. With PyPOTS, easy peasy! 😉
👉 Click here to see the example 👀
# pip install pypots>=0.4
import numpy as np
from sklearn.preprocessing import StandardScaler
from pygrinder import mcar
from pypots.data import load_specific_dataset
from pypots.imputation import SAITS
from pypots.utils.metrics import calc_mae
# Data preprocessing. Tedious, but PyPOTS can help.
data = load_specific_dataset('physionet_2012') # PyPOTS will automatically download and extract it.
X = data['X']
num_samples = len(X['RecordID'].unique())
X = X.drop(['RecordID', 'Time'], axis = 1)
X = StandardScaler().fit_transform(X.to_numpy())
X = X.reshape(num_samples, 48, -1)
X_ori = X # keep X_ori for validation
X = mcar(X, 0.1) # randomly hold out 10% observed values as ground truth
dataset = {"X": X} # X for model input
print(X.shape) # (11988, 48, 37), 11988 samples and each sample has 48 time steps, 37 features
# Model training. This is PyPOTS showtime.
saits = SAITS(n_steps=48, n_features=37, n_layers=2, d_model=256, d_ffn=128, n_heads=4, d_k=64, d_v=64, dropout=0.1, epochs=10)
# Here I use the whole dataset as the training set because ground truth is not visible to the model, you can also split it into train/val/test sets
saits.fit(dataset)
imputation = saits.impute(dataset) # impute the originally-missing values and artificially-missing values
indicating_mask = np.isnan(X) ^ np.isnan(X_ori) # indicating mask for imputation error calculation
mae = calc_mae(imputation, np.nan_to_num(X_ori), indicating_mask) # calculate mean absolute error on the ground truth (artificially-missing values)
☕️ Welcome to the universe of PyPOTS. Enjoy it and have fun!
⦿ Motivation: SAITS is developed primarily to help overcome the drawbacks (slow speed, memory constraints, and compounding error)
of RNN-based imputation models and to obtain the state-of-the-art (SOTA) imputation accuracy on partially-observed time series.
⦿ Performance: SAITS outperforms BRITS
by 12% ∼ 38% in MAE (mean absolute error) and achieves 2.0 ∼ 2.6 times faster training speed.
Furthermore, SAITS outperforms Transformer (trained by our joint-optimization approach) by 2% ∼ 19% in MAE with a
more efficient model structure (to obtain comparable performance, SAITS needs only 15% ∼ 30% parameters of Transformer).
Compared to another SOTA self-attention imputation model NRTSI, SAITS achieves
7% ∼ 39% smaller mean squared error (above 20% in nine out of sixteen cases), meanwhile, needs much
fewer parameters and less imputation time in practice.
Please refer to our full paper for more details about SAITS' performance.
Here we only show the two main components of our method: the joint-optimization training approach and SAITS structure.
For the detailed description and explanation, please read our full paper Paper_SAITS.pdf in this repo
or on arXiv.

Fig. 1: Training approach

Fig. 2: SAITS structure
If you find SAITS is helpful to your work, please cite our paper as below, ⭐️star this repository, and recommend it to others who you think may need it. 🤗 Thank you!
@article{du2023saits,
title = {{SAITS: Self-Attention-based Imputation for Time Series}},
journal = {Expert Systems with Applications},
volume = {219},
pages = {119619},
year = {2023},
issn = {0957-4174},
doi = {10.1016/j.eswa.2023.119619},
url = {https://arxiv.org/abs/2202.08516},
author = {Wenjie Du and David Cote and Yan Liu},
}or
Wenjie Du, David Cote, and Yan Liu. SAITS: Self-Attention-based Imputation for Time Series. Expert Systems with Applications, 219:119619, 2023.
The implementation of SAITS is in dir modeling.
We give configurations of our models in dir configs, provide
the dataset links and preprocessing scripts in dir dataset_generating_scripts.
Dir NNI_tuning contains the hyper-parameter searching configurations.
All dependencies of our development environment are listed in file conda_env_dependencies.yml.
You can quickly create a usable python environment with an anaconda command conda env create -f conda_env_dependencies.yml.
For datasets downloading and generating, please check out the scripts in
dir dataset_generating_scripts.
Generate the dataset you need first. To do so, please check out the generating scripts in
dir dataset_generating_scripts.
After data generation, train and test your model, for example,
# create a dir to save logs and results
mkdir NIPS_results
# train a model
nohup python run_models.py \
--config_path configs/PhysioNet2012_SAITS_best.ini \
> NIPS_results/PhysioNet2012_SAITS_best.out &
# during training, you can run the blow command to read the training log
less NIPS_results/PhysioNet2012_SAITS_best.out
# after training, pick the best model and modify the path of the model for testing in the config file, then run the below command to test the model
python run_models.py \
--config_path configs/PhysioNet2012_SAITS_best.ini \
--test_mode❗️Note that paths of datasets and saving dirs may be different on personal computers, please check them in the configuration files.
Thanks to Ciena, Mitacs, and NSERC (Natural Sciences and Engineering Research Council of Canada) for funding support. Thanks to Ciena for providing computing resources. Thanks to all our reviewers for helping improve the quality of this paper. And thank you all for your attention to this work.
👏 Click to View Stargazers and Forkers:
If you have any additional questions or have interests in collaboration, please take a look at my GitHub profile and feel free to contact me 😃.