The purpose of this analysis was to sample data from the LendingClub credit card credit dataset and create models to predict credit risk. We used the random oversampling, SMOTE oversampling, ClusterCentroid undersampling, and SMOTEEN combined sampling algorithms along with the ensemble algorithms Balanced Random Forest and Adaboost. We utilized these machine learning algorithms through the scikit-learn and imbalanced-learn libraries to build, fit, and evaluate our models sequentially using resampling. We evaluated performance of each model using confusion matrices and classification reports.
| Result | Random Oversampling | SMOTE Oversampling | Undersampling | SMOTEEN |
|---|---|---|---|---|
| Accuracy Score | 0.581 | 0.659 | 0.659 | 0.544 |
| Low-Risk Precision | High (1.00) | High (1.00) | High (1.00) | High (1.00) |
| High-Risk Precision | Low (0.01) | Low (0.01) | Low (0.01) | Low (0.01) |
| Low-Risk Recall | 0.58 | 0.68 | 0.40 | 0.57 |
| High-Risk Recall | 0.71 | 0.63 | 0.69 | 0.72 |
- Accuracy score: Percentage of accurate predictions
- Precision: The number of positive class predictions that are actually positive
- Recall: The number of positive class predictions of all positive class examples
| Random Oversampling | SMOTE Oversampling |
|---|---|
 |
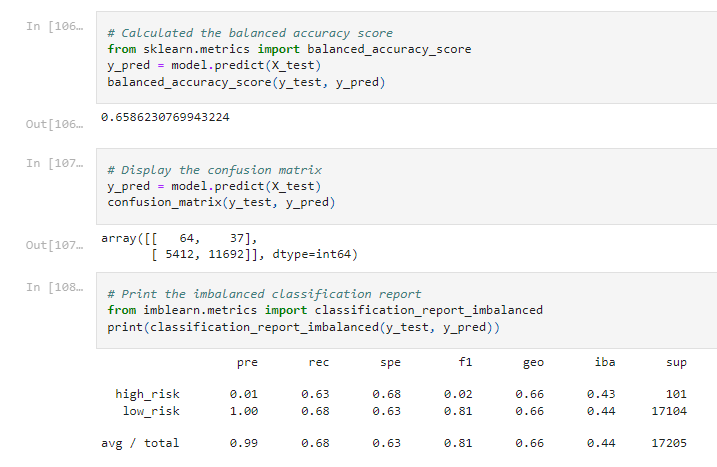 |
| Undersampling | SMOTEEN |
|---|---|
 |
 |
While we were not able to include the ensemble reports to our analysis, we were able to compare the four non-aggregate predictive algorithms. We utilized two oversampling algorithms (Random & SMOTE), Undersampling, and the combined SMOTEEN algorithm from the Scikit-learn library. One consistency throughout all four models was that there was a high precision for low-risk loans and a very low precision for high-risk loans, showing all models are very strong at predicting true positive results for low-risk loans, but very poor positive classification for high-risk loans. Of the four models, the SMOTE oversampling and undersampling algorithms had the highest percentage of accurate predictions with the same accuracy score of 0.659, while Random Oversampling performed slightly worse with a score of 0.581 and the SMOTEEN algorithm had the weakest prediction accuracy at 0.544. Out of the two models with the highest accuracy scores, SMOTE oversampling had the best and most balanced recall (0.68/0.63) compared to undersampling (0.40/0.69). From our model testing, we would suggest using the SMOTE oversampling algorithm to best predict credit loans. SMOTE showed the best overall recall for both low and high-risk loans and accuracy score, however there needs to be caution as there is a very large discrepancy in the precision for low and high risk loans.