Anycost GANs for Interactive Image Synthesis and Editing
Ji Lin, Richard Zhang, Frieder Ganz, Song Han, Jun-Yan Zhu
MIT, Adobe Research, CMU
In CVPR 2021

Anycost GAN generates consistent outputs under various computational budgets.

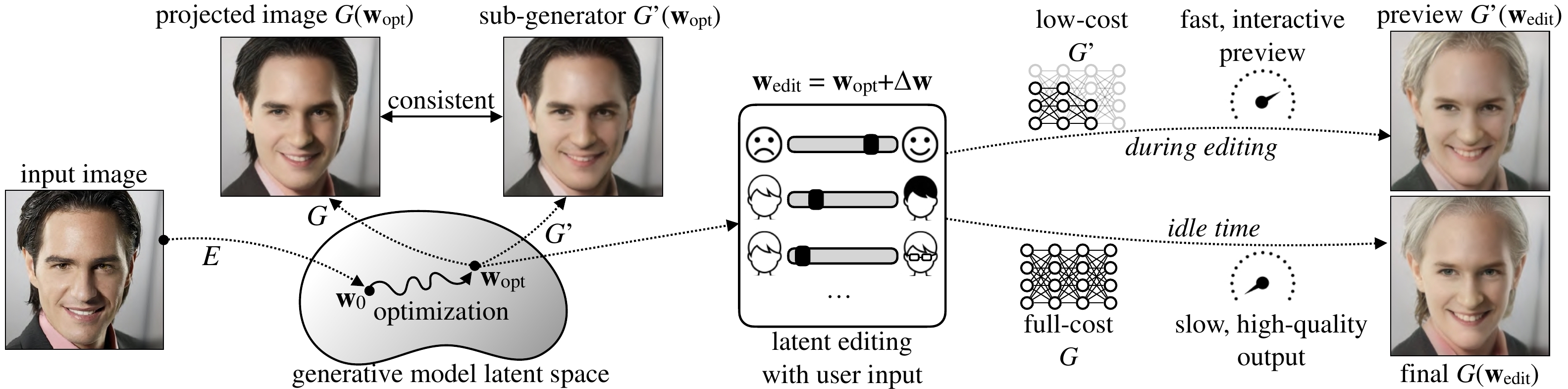
Here, we can use the Anycost generator for interactive image editing. A full generator takes ~3s to render an image, which is too slow for editing. While with Anycost generator, we can provide a visually similar preview at 5x faster speed. After adjustment, we hit the "Finalize" button to synthesize the high-quality final output. Check here for the full demo.
Anycost generators can be run at diverse computation costs by using different channel and resolution configurations. Sub-generators achieve high output consistency compared to the full generator, providing a fast preview.
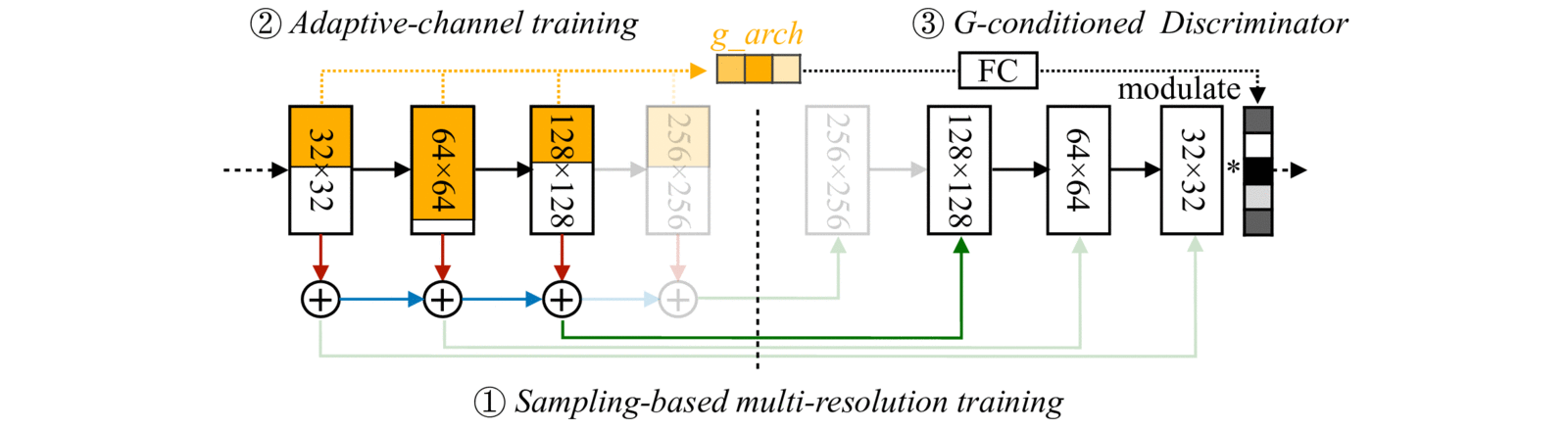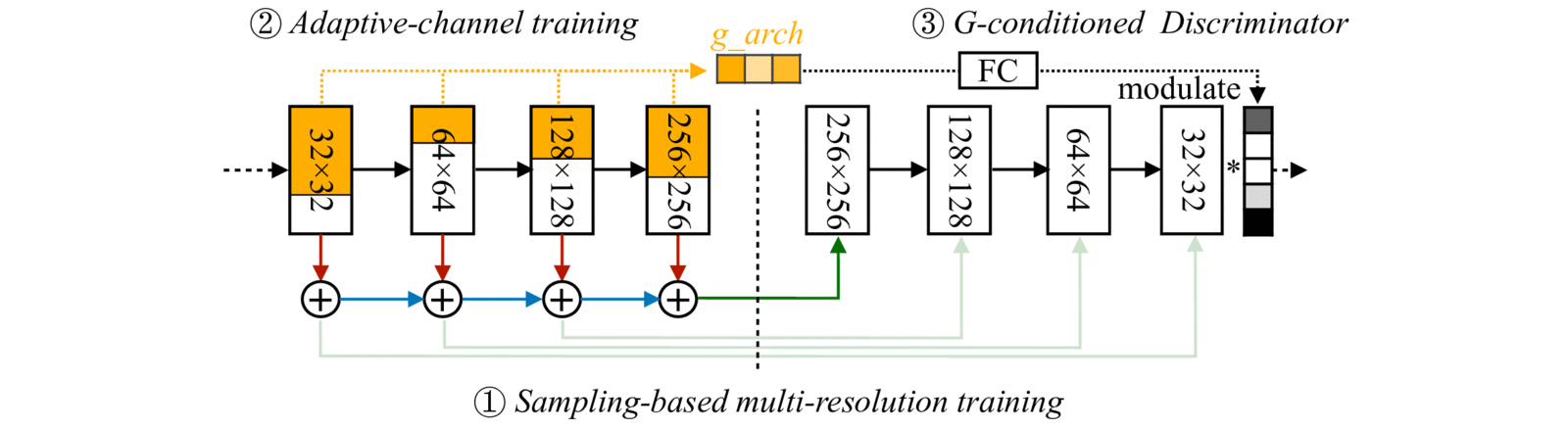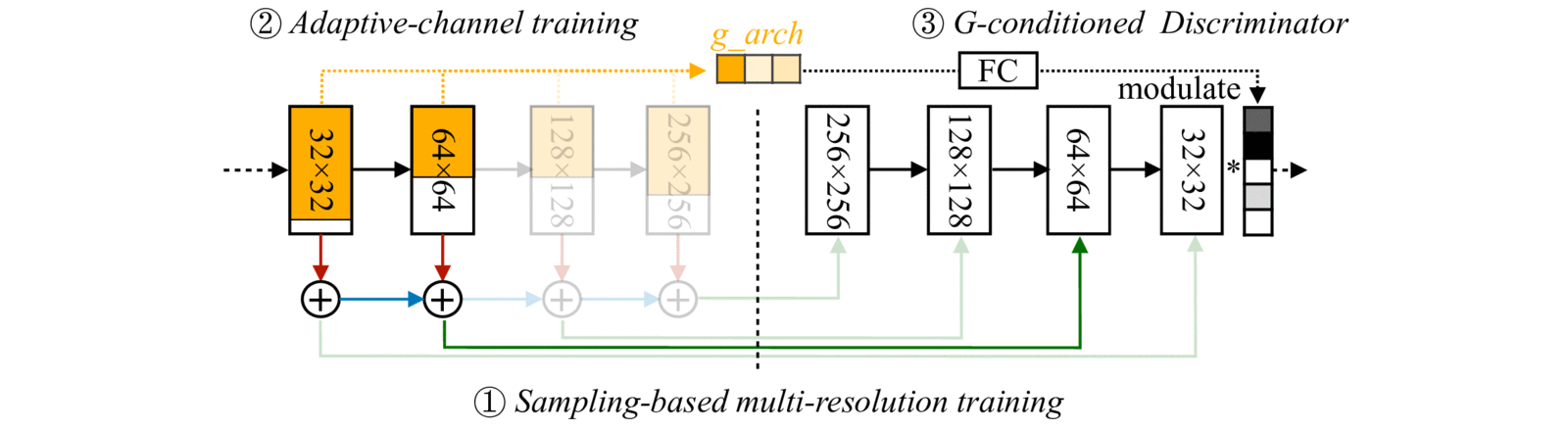
With (1) Sampling-based multi-resolution training, (2) adaptive-channel training, and (3) generator-conditioned discriminator, we achieve high image quality and consistency at different resolutions and channels.
Anycost GAN (uniform channel version) supports 4 resolutions and 4 channel ratios, producing visually consistent images with different image fidelity.

The consistency retains during image projection and editing:


- Clone this repo:
git clone https://github.com/mit-han-lab/anycost-gan.git
cd anycost-gan- Install PyTorch 1.7 and other dependeinces.
We recommend setting up the environment using Anaconda: conda env create -f environment.yml
We provide a jupyter notebook example to show how to use the anycost generator for image synthesis at diverse costs: notebooks/intro.ipynb.
We also provide a colab version of the notebook: . Be sure to select the GPU as the accelerator in runtime options.
We provide an interactive demo showing how we can use anycost GAN to enable interactive image editing. To run the demo:
python demo.pyIf your computer contains a CUDA GPU, try running with:
FORCE_NATIVE=1 python demo.pyYou can find a video recording of the demo here.
To get the pre-trained generator, encoder, and editing directions, run:
import models
pretrained_type = 'generator' # choosing from ['generator', 'encoder', 'boundary']
config_name = 'anycost-ffhq-config-f' # replace the config name for other models
models.get_pretrained(pretrained_type, config=config_name)We also provide the face attribute classifier (which is general for different generators) for computing the editing directions. You can get it by running:
models.get_pretrained('attribute-predictor')The attribute classifier takes in the face images in FFHQ format.
After loading the Anycost generator, we can run it at a wide range of computational costs. For example:
from models.dynamic_channel import set_uniform_channel_ratio, reset_generator
g = models.get_pretrained('generator', config='anycost-ffhq-config-f') # anycost uniform
set_uniform_channel_ratio(g, 0.5) # set channel
g.target_res = 512 # set resolution
out, _ = g(...) # generate image
reset_generator(g) # restore the generatorFor detailed usage and flexible-channel anycost generator, please refer to notebooks/intro.ipynb.
Currently, we provide the following pre-trained generators, encoders, and editing directions. We will add more in the future.
For Anycost generators, by default, we refer to the uniform setting.
| config name | generator | encoder | edit direction |
|---|---|---|---|
| anycost-ffhq-config-f | ✔️ | ✔️ | ✔️ |
| anycost-ffhq-config-f-flexible | ✔️ | ✔️ | ✔️ |
| anycost-car-config-f | ✔️ | ||
| stylegan2-ffhq-config-f | ✔️ | ✔️ | ✔️ |
stylegan2-ffhq-config-f refers to the official StyleGAN2 generator converted from the repo.
We prepare the FFHQ, CelebA-HQ, and LSUN Car datasets into a directory of images, so that it can be easily used with ImageFolder from torchvision. The dataset layout looks like:
├── PATH_TO_DATASET
│ ├── images
│ │ ├── 00000.png
│ │ ├── 00001.png
│ │ ├── ...
Due to the copyright issue, you need to download the dataset from official site and process them accordingly.
We provide the code to evaluate some metrics presented in the paper. Some of the code is written with horovod to support distributed evaluation and reduce the cost of inter-GPU communication, which greatly improves the speed. Check its website for a proper installation.
Before evaluating the FIDs, you need to compute the inception features of the real images using scripts like:
python tools/calc_inception.py \
--resolution 1024 --batch_size 64 -j 16 --n_sample 50000 \
--save_name assets/inceptions/inception_ffhq_res1024_50k.pkl \
PATH_TO_FFHQor you can download the pre-computed inceptions from here and put it under assets/inceptions.
Then, you can evaluate the FIDs by running:
horovodrun -np N_GPU \
python metrics/fid.py \
--config anycost-ffhq-config-f \
--batch_size 16 --n_sample 50000 \
--inception assets/inceptions/inception_ffhq_res1024_50k.pkl
# --channel_ratio 0.5 --target_res 512 # optionally using a smaller resolution/channelSimilary, evaluting the PPL with:
horovodrun -np N_GPU \
python metrics/ppl.py \
--config anycost-ffhq-config-fEvaluating the attribute consistency by running:
horovodrun -np N_GPU \
python metrics/attribute_consistency.py \
--config anycost-ffhq-config-f \
--channel_ratio 0.5 --target_res 512 # config for the sub-generator; necessaryTo evaluate the performance of the encoder, run:
python metrics/eval_encoder.py \
--config anycost-ffhq-config-f \
--data_path PATH_TO_CELEBA_HQWe provide the scripts to train Anycost GAN on FFHQ dataset.
- Training the original StyleGAN2 on FFHQ
horovodrun -np 8 bash scripts/train_stylegan2_ffhq.sh
The training of original StyleGAN2 is time-consuming. We recommend downloading the converted checkpoints from here and place it under checkpoint/.
- Training Anycost GAN: mult-resolution
horovodrun -np 8 bash scripts/train_stylegan2_multires_ffhq.sh
Note that after each epoch, we evaluate the FIDs of two resolutions (1024&512) to better monitor the training progress. We also apply distillation to accelearte the convergence, which is not used for the ablation in the paper.
- Training Anycost GAN: adaptive-channel
horovodrun -np 8 bash scripts/train_stylegan2_multires_adach_ffhq.sh
Here we set a longer training epoch for a more stable reproduction, which might not be necessary (depending on the randomness).
Note: We trained our models on Titan RTX GPUs with 24GB memory. For GPUs with smaller memory, you may need to reduce the resolution/model size/batch size/etc. and adjust other hyper-parameters accordingly.
If you use this code for your research, please cite our paper.
@inproceedings{lin2021anycost,
author = {Lin, Ji and Zhang, Richard and Ganz, Frieder and Han, Song and Zhu, Jun-Yan},
title = {Anycost GANs for Interactive Image Synthesis and Editing},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2021},
}
GAN Compression | Once for All | iGAN | StyleGAN2
We thank Taesung Park, Zhixin Shu, Muyang Li, and Han Cai for the helpful discussion. Part of the work is supported by NSF CAREER Award #1943349, Adobe, SONY, Naver Corporation, and MIT-IBM Watson AI Lab.
The codebase is build upon a PyTorch implementation of StyleGAN2: rosinality/stylegan2-pytorch. For editing direction extraction, we refer to InterFaceGAN.