





Research Projects
-

OBJect 3DIT: Language-guided 3D-aware Image Editing
The task of 3D-aware image editing involves editing an image in a way that is consistent with some transformation to its underlying 3D scene. We present a model and dataset for this task and show impressive transfer to the real-world....
-

Visual Programming: Compositional visual reasoning without training
[CVPR 2023 Best Paper] VISPROG is a neuro-symbolic system for solving complex and compositional visual tasks by generating and executing programs.
-

🏘️ ProcTHOR: Large-Scale Embodied AI Using Procedural Generation
[Neurips 2022 Outstanding Paper] ProcTHOR is a platform to procedurally generate realistic, interactive, and diverse simulated 3D environments. It dramatically scales up the amount of training data which significantly improves performance on all embodied tasks considered.
-
Moving Forward by Moving Backward: Embedding Action Impact over Action Semantics
An embodied agent may encounter settings that dramatically alter the impact of actions: a move ahead action on a wet floor may send the agent twice as far as it expects and using the same action with a broken wheel...
-
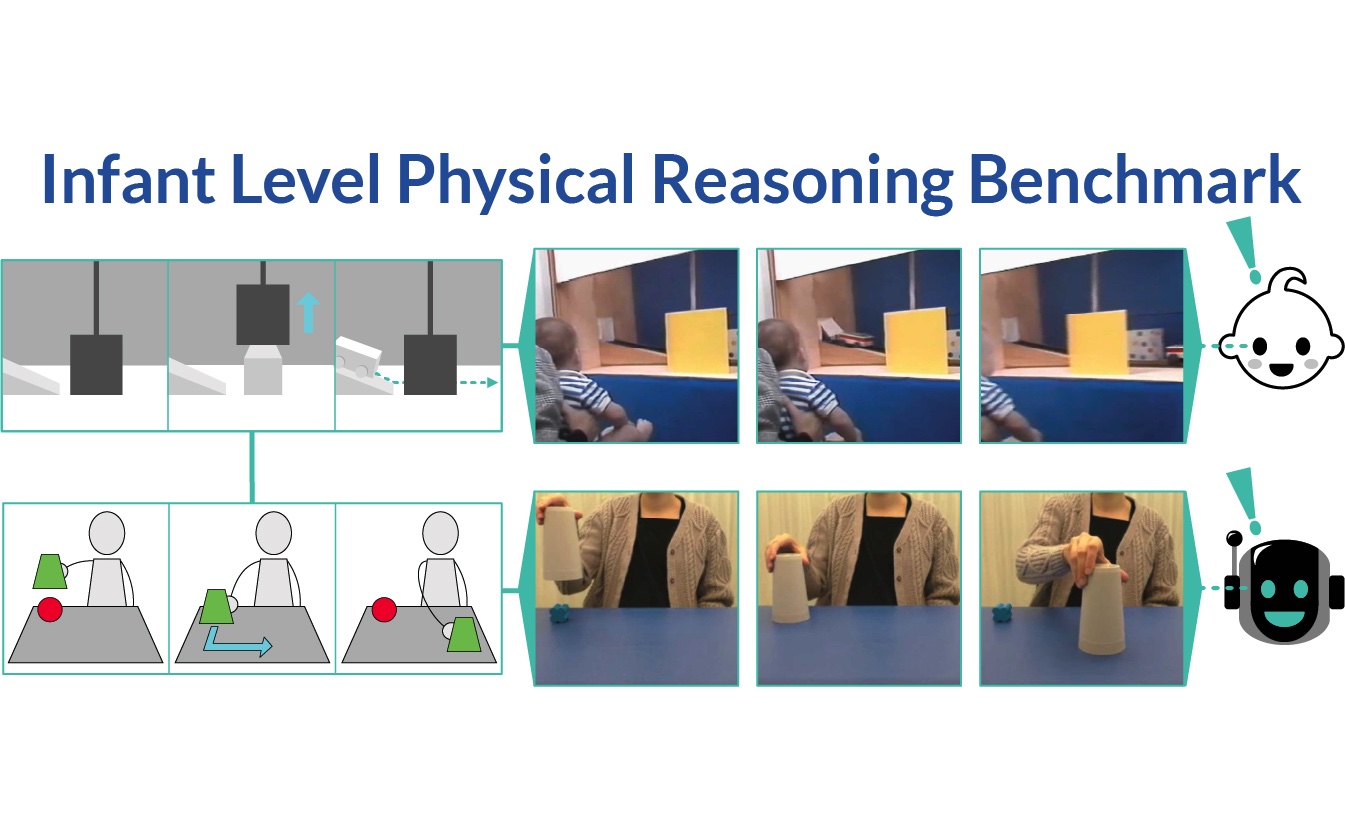
Benchmarking Progress to Infant-Level Physical Reasoning in AI
Inspired by research on infants, we introduce the Infant-Level Physical Reasoning Benchmark (InfLevel) to better understand the fundamental physical reasoning abilities of AI systems. We find that current popular systems appear to be far less proficient than infants.
-
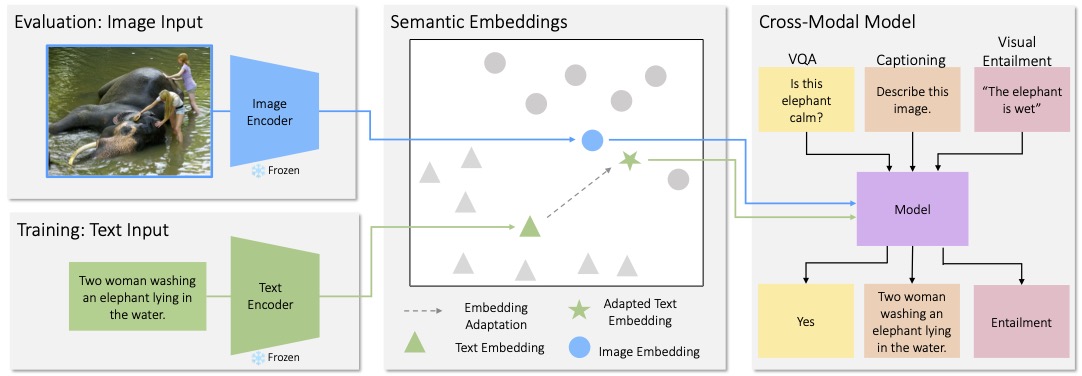
I Can't Believe There's No Images! Learning Visual Tasks Using Only Language Data
CLOSE is a cross-modal transfer model that learns skills from textual data and then use them to complete vision tasks without ever training on visual data. It works by exploiting the joint embedding space of contrastively trained vision and language...
-

Towards Disturbance-Free Visual Mobile Manipulation
In this work, we take the first step towards collision/disturbance-free embodied AI agents for visual mobile manipulation, facilitating safe deployment in real robots.
-
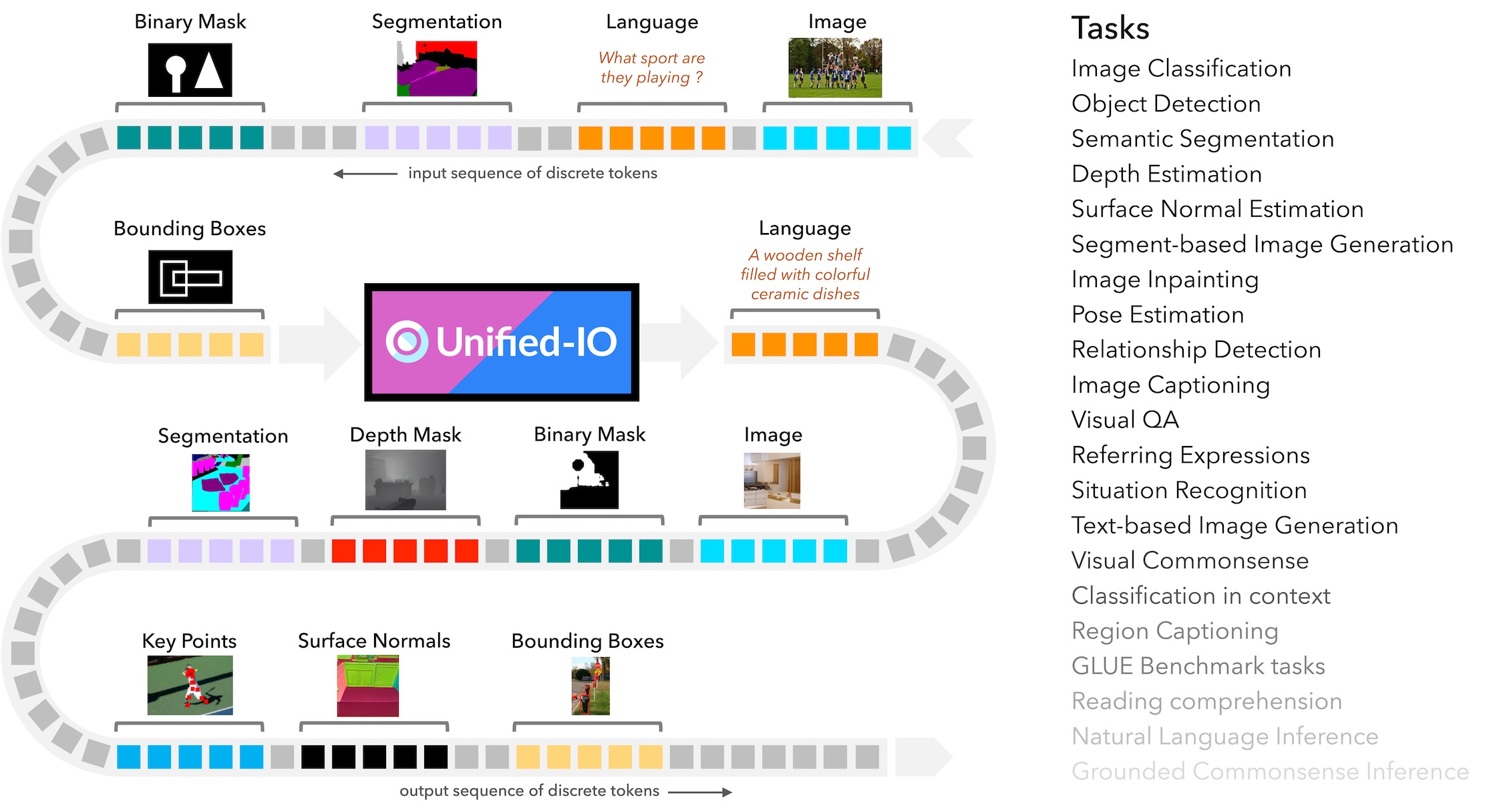
Unified-IO: A Unified Model for Vision, Language, and Multi-Modal Tasks
Unified-IO is the first neural model to perform a large and diverse set of AI tasks spanning classical computer vision, image synthesis, vision-and-language, and natural language processing.
-

Ask4help : Learning to Leverage an Expert for Embodied Tasks
We propose Ask4Help, a policy that endow off-the-shelf embodied models with the ability to request expert assistance. We show that we can improve navigation and rearrangements with limited expert help.
-

A-OKVQA: A Visual Knowledge-based Reasoning Benchmark
A-OKVQA is a new knowledge-based visual question answering benchmark. It is an Augmented successor of the OK-VQA benchmark and contains a diverse set of 25K questions requiring a broad base of commonsense and world knowledge to answer.
-
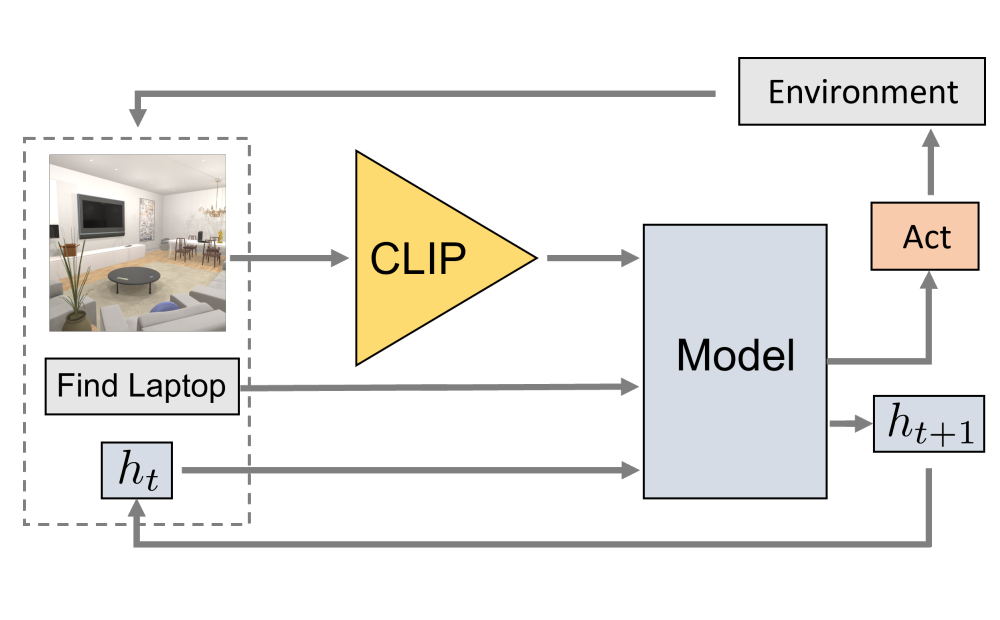
Simple but Effective: CLIP Embeddings for Embodied AI
We present competitive performance on navigation-heavy tasks in Embodied AI using frozen visual representations from CLIP.
-

GRIT: General Robust Image Task Benchmark
The General Robust Image Task (GRIT) Benchmark is an evaluation-only benchmark for evaluating the performance and robustness of vision systems across multiple image prediction tasks, concepts, and data sources.
-
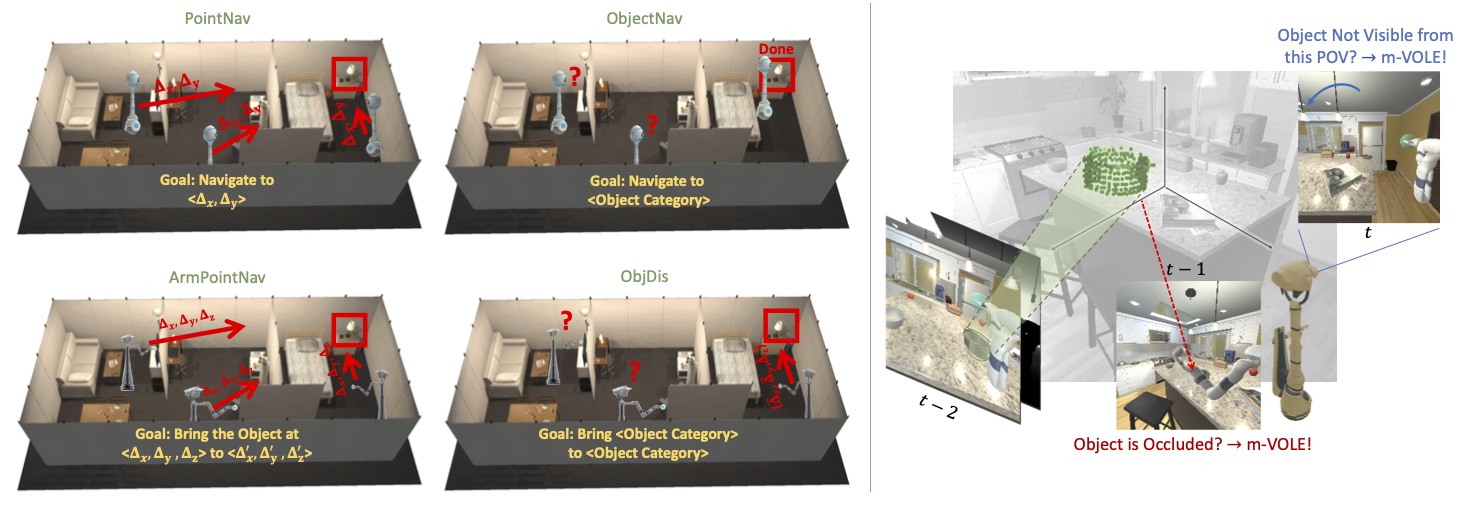
Object Manipulation via Visual Target Localization
We propose Manipulation via Visual Object Location Estimation (m-VOLE), an approach that explores the environment in search for target objects, computes their 3D coordinates once they are located, and robustly aids the task of manipulating these objects throughout the episode....
-

Continuous Scene Representations for Embodied AI
We employ a contrastive loss to embed relationships between objects as features and show how our representation can be used downstream for visual room rearrangement without any additional training.
-
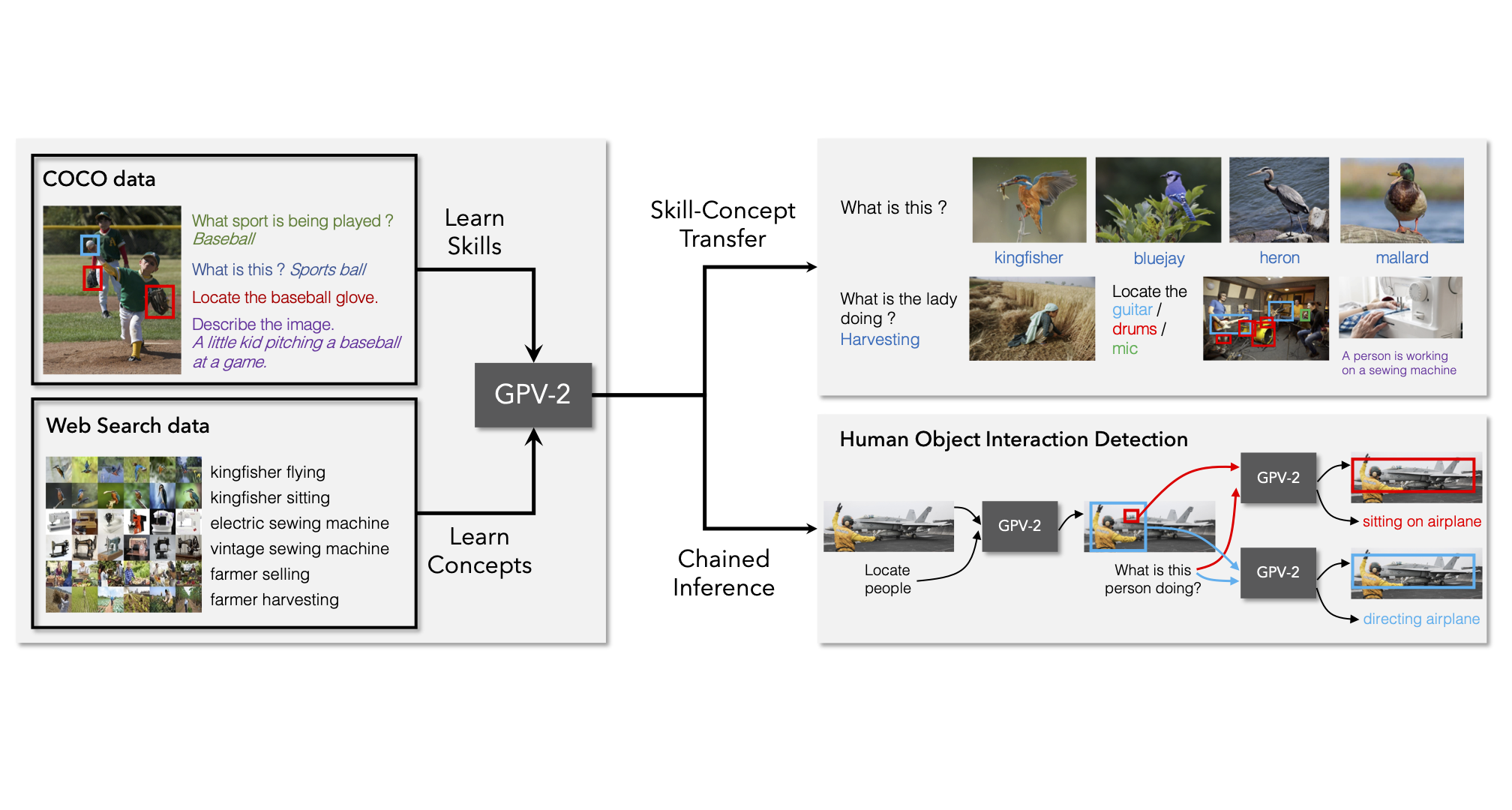
GPV-2: A Webly Supervised GPV Model
We propose expanding concept knowledge of general purpose vision systems by learning skills from supervised datasets while learning concepts from web image search data.
-

Factorizing Perception and Policy for Interactive Instruction Following
Modular Object-Centric Agent (MOCA) for interactive instruction following
-

Analysis of Contrastive Representation Learning Pipelines
Visual Representation Learning Benchmark for Self-Supervised Models
-
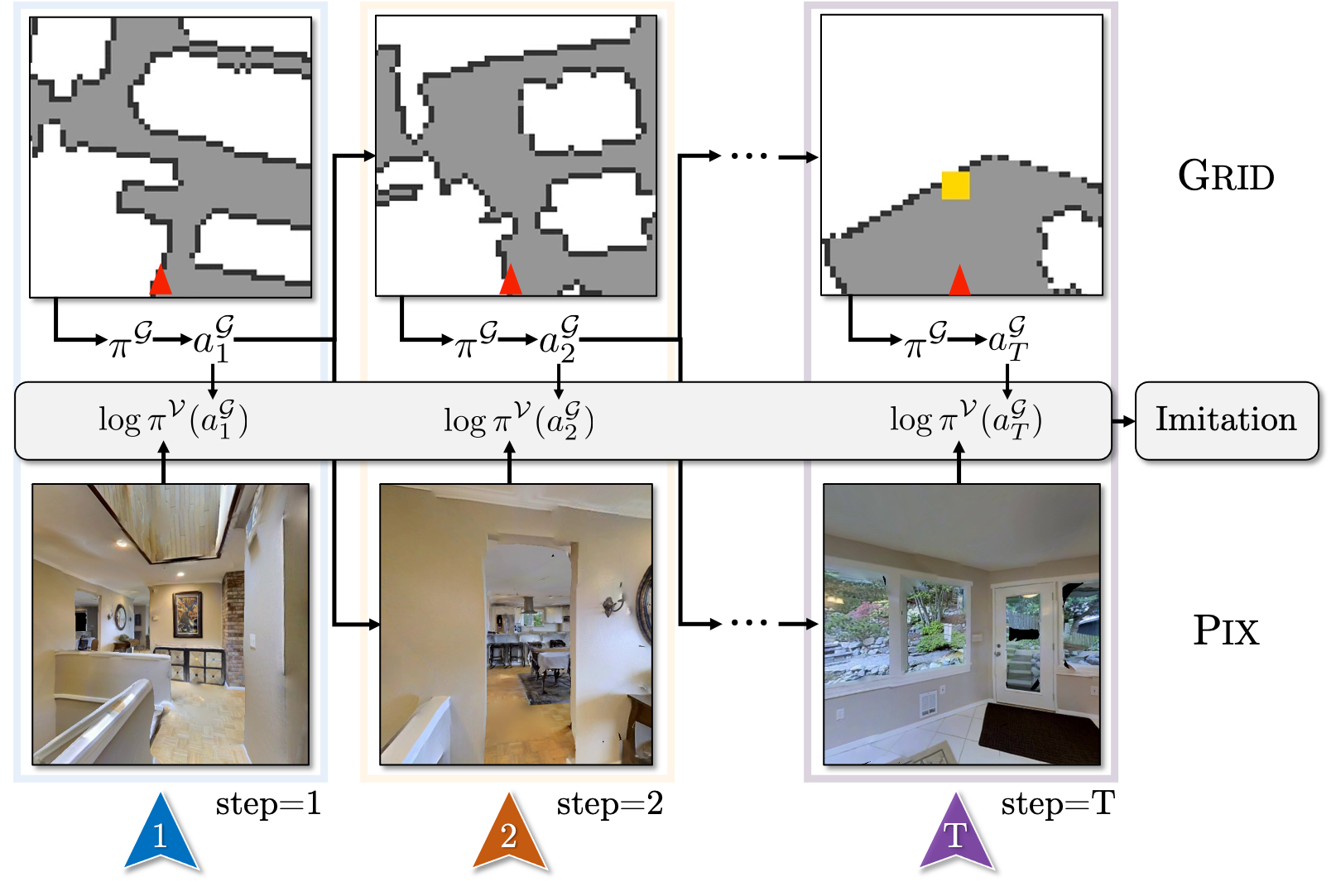
GridToPix: Training Embodied Agents with Minimal Supervision
We show that one may train embodied agents with minimal supervision by transferring knowledge learned within gridworlds.
-

What Can You Learn from Your Muscles? Learning Visual Representation from Human Interactions
We use human interaction and attention cues to learn visual representations.
-
Generalizable Visual Representations via Gameplay
We study how interaction and play can be used as a new paradigm for training AI agents to understand their world.
-

Interactive Visual Navigation
We study the problem of interactive navigation where agents learn to change the environment to navigate more efficiently to their goals.
-

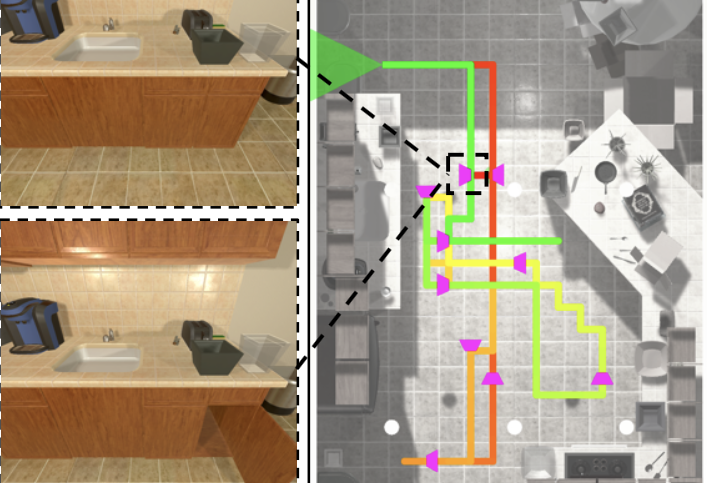
ManipulaTHOR
An interactive framework for low-level mobile object manipulation and navigation
-
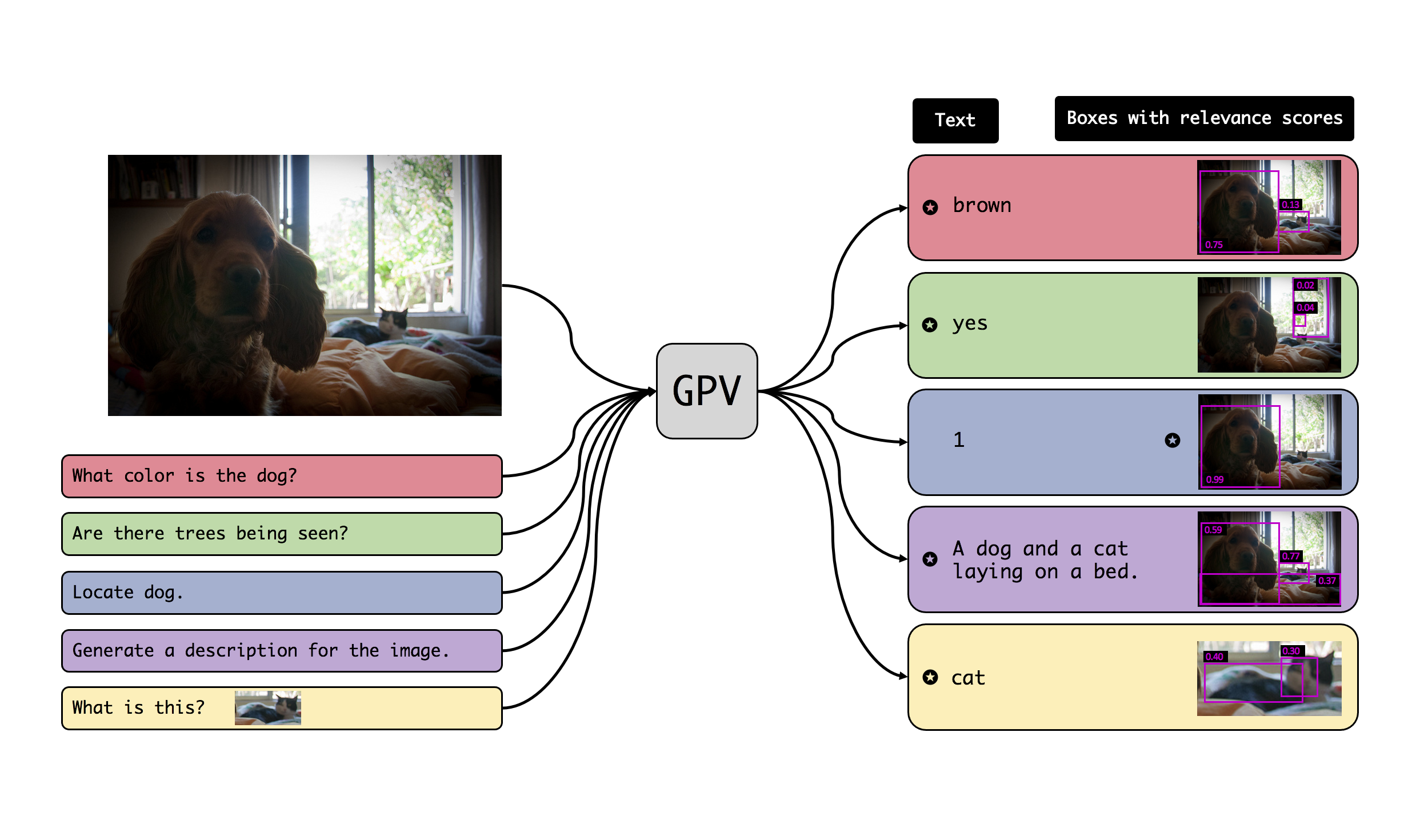
General Purpose Vision
We propose a task-agnostic vision-language system that accepts an image and a natural language task description and outputs bounding boxes, confidences, and text.
-

RobustNav
As an attempt towards assessing the robustness of embodied navigation agents, we propose RobustNav, a framework to quantify the performance of embodied navigation agents when exposed to a wide variety of visual and dynamics corruptions.
-

Learning Curves
We propose a method to robustly estimate learning curves, abstract their parameters into error and data-reliance, and exemplify use of learning curves for classifier analysis.
-
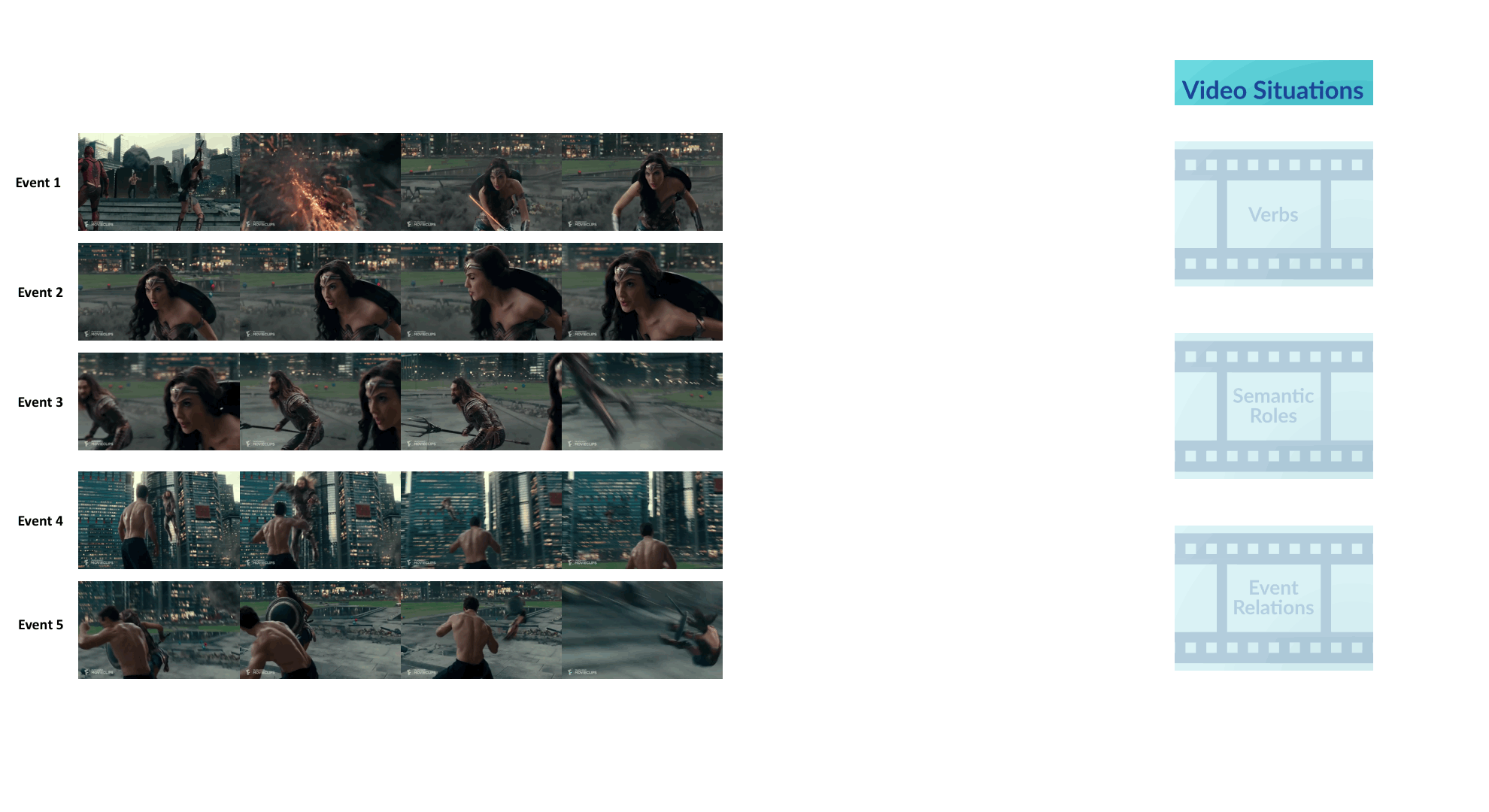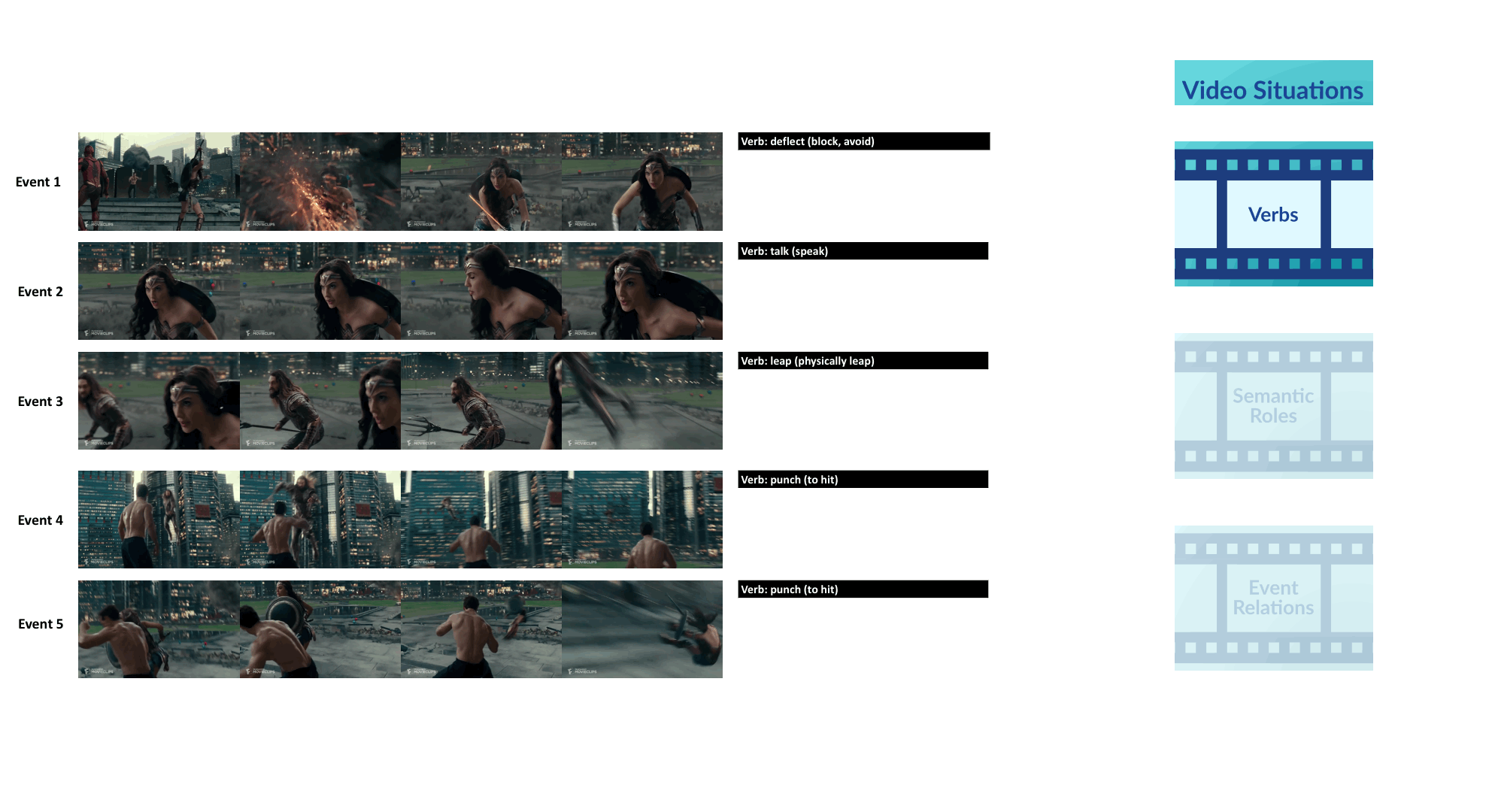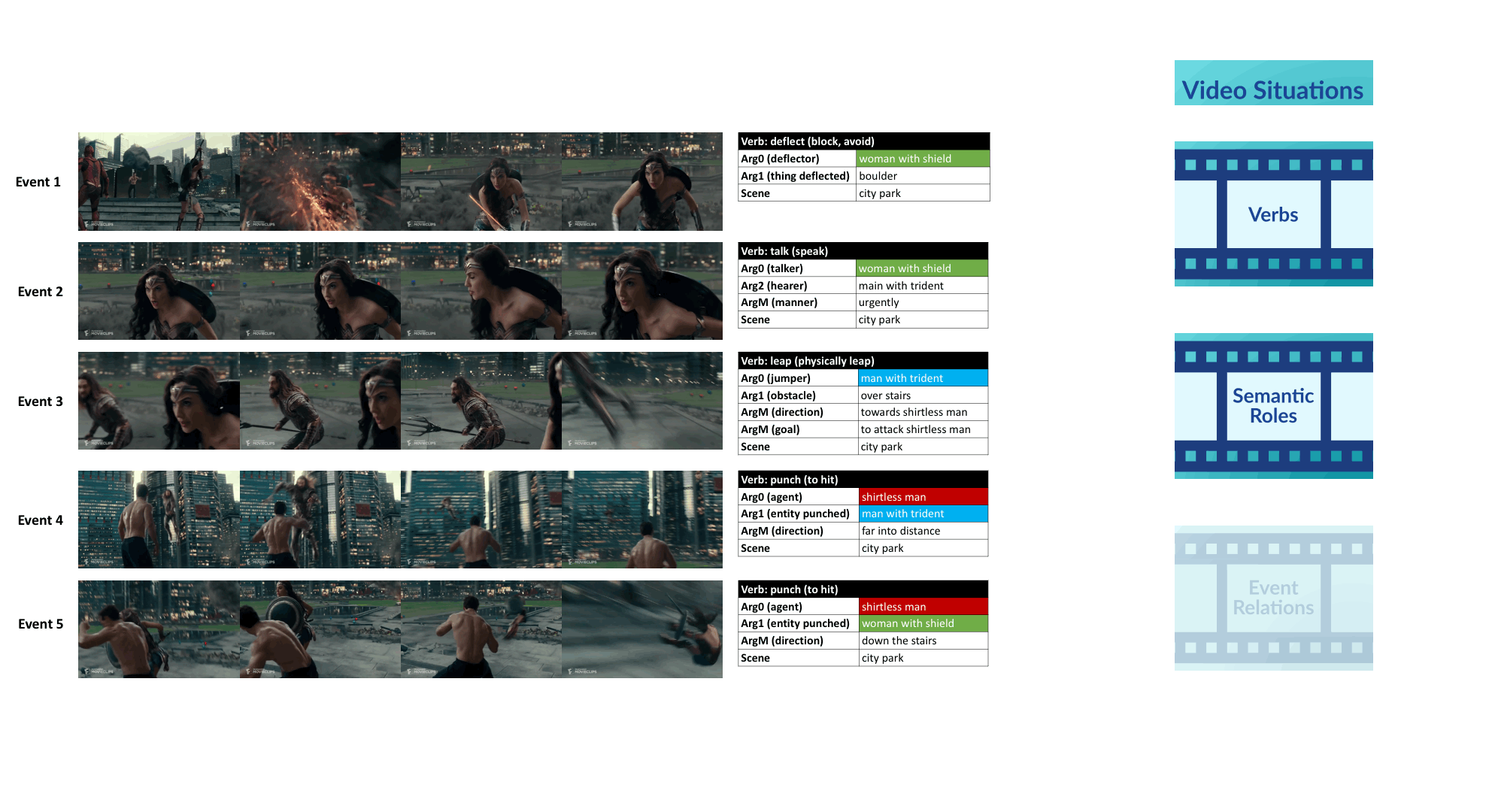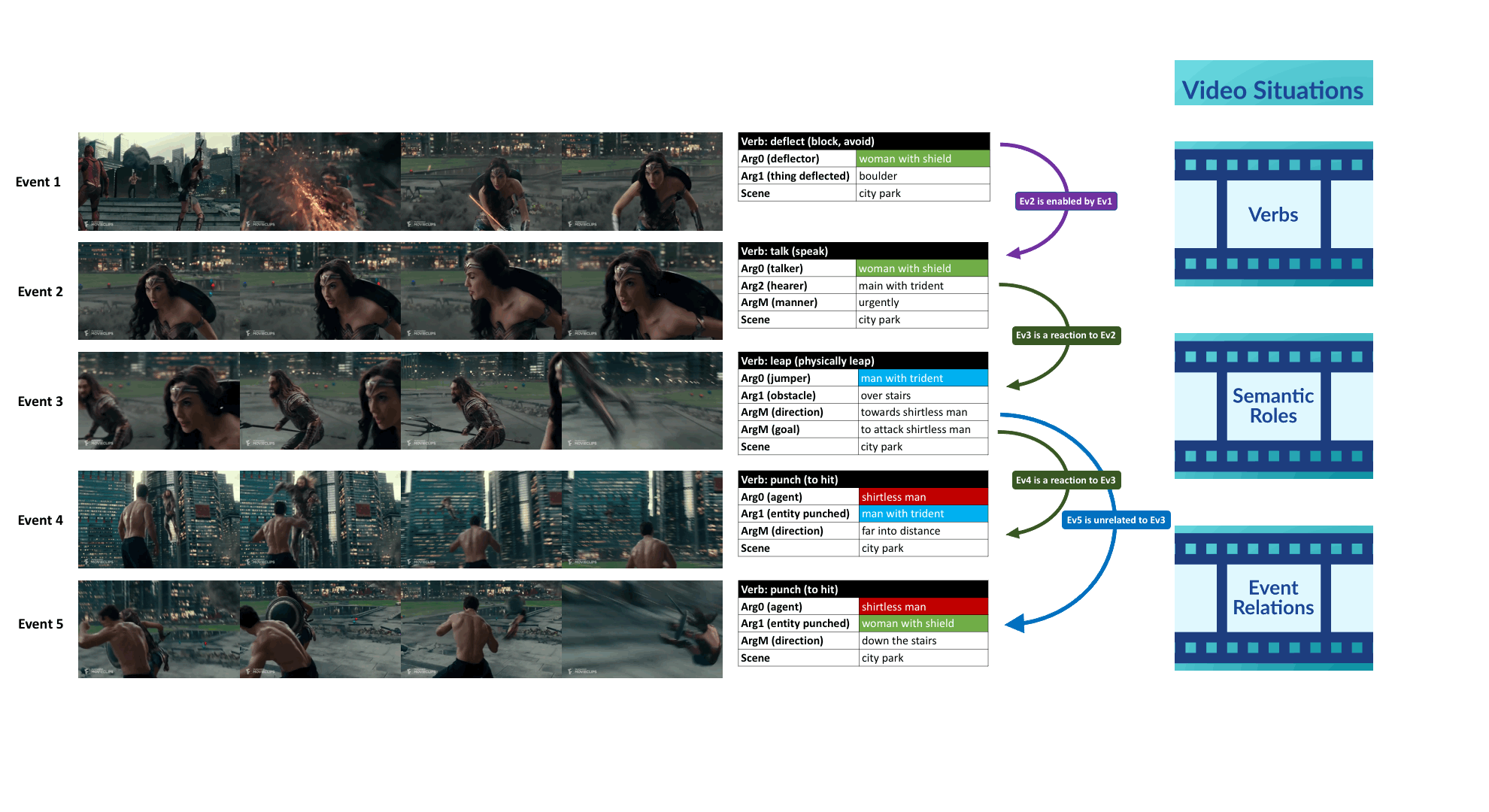
Video Situation Recognition
We introduce VidSitu, a large-scale movie dataset and the VidSRL task for representing complex situations using a semantic role labeling framework with coreferenced entities, and event-relations.
-
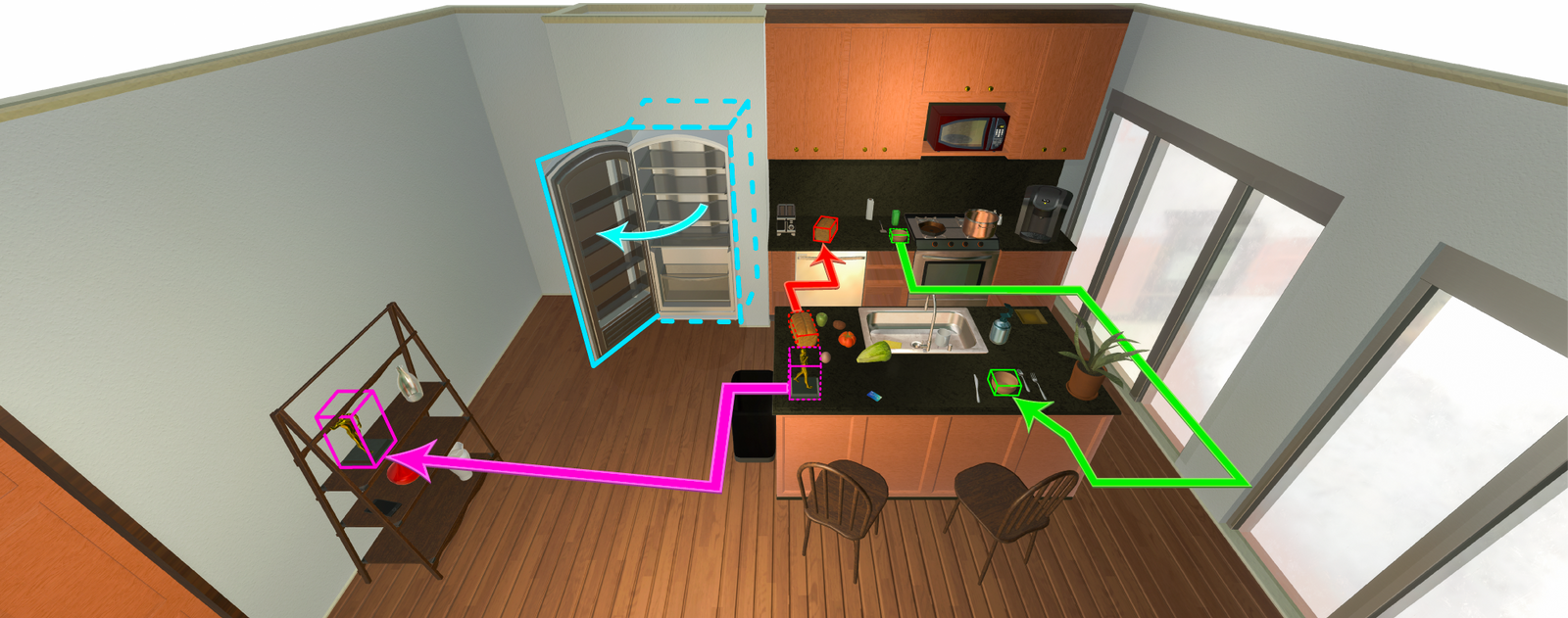
Visual Room Rearrangement
The goal of the AI2-THOR Rearrangement Challenge is to build a model/agent that move objects in a room, such that they are restored to a given initial configuration.
-

Learning from Interaction
We learn object properties from interaction in a self-supervised manner
-

X-LXMERT
Paint, Caption and Answer Questions with Multi-Modal Transformers
-

AllenAct
An open source framework for research in Embodied-AI from AI2
-

Visual Reaction
We study the problem of Visual Reaction, where the idea is to forecast the future and plan a sequence of actions accordingly.
-

ALFRED
A framework to study vision and language in the context of instruction following in an interactive environment.
-

RoboTHOR
RoboTHOR is an environment within the AI2-THOR framework, designed to develop embodied AI agents. It consists of a series of scenes in simulation with counterparts in the physical world.
-

Grounded Situation Recognition
A dataset and model to describe images with the primary action in the image as well as labels and bounding boxes for the entities involved in the action.
-

Computer Vision Explorer
Try out leading computer vision models on a variety of tasks.
-

Outside-Knowledge VQA
A dataset that includes questions that require outside knowledge to be answered.
-

ESPNets for Computer Vision
This project explores efficient CNN designs for different computer vision tasks including object classification, object detection, and semantic segmentation.
-

Discovering Neural Wirings
We propose a method for discovering neural wirings. The wiring of our network is not fixed during training, as we learn the network parameters we also learn the network structure itself.
-

Self-Adaptive Visual Navigation
We introduce a navigation agent that learns to adapt to its environment through self-supervised interaction.
-

ELASTIC: Improving CNNs with Dynamic Scaling Policies
This project explores modeling scale variations by learnable dynamic scaling policies. We observed consistent improvements on ImageNet classification, and other downstream vision tasks.
-
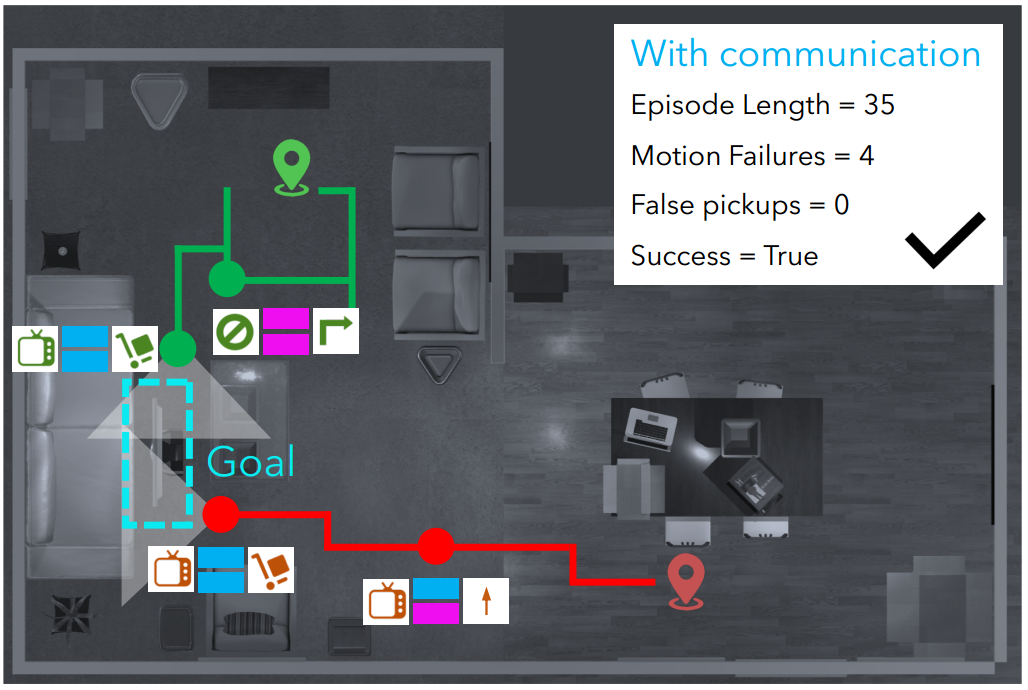
Two Body Problem: Collaborative Visual Task Completion
Learning to collaborate in visual environments and demonstrate the benefits of learned explicit and implicit communication to aid task completion. We also provide a statistical interpretation of the communication strategy learned by the agents.
-

Using Knowledge Graphs for Visual Semantic Navigation
The goal is to augment an RL-based method with a knowledge graph to better navigate in novel scenes and towards unseen objects.
-

Imagine This! Scripts to Compositions to Videos
Given a scene description, Composition, Retrieval and Fusion Network (CRAFT) predicts a layout of mentioned entities, retrieves spatio-temporal entity segments from a video database and fuses them to generate scene videos. Results are shown on a new FLINTSTONES dataset.
-

Modeling Dog Behavior From Visual Data
This project explores directly modeling a visually intelligent agent. Our model inputs visual information and predicts the agent's actions. We demonstrate our model on DECADE, a large-scale dataset of ego-centric videos from a dog's perspective.
-

IQA: Visual Question Answering in Interactive Environments
This project explores Interactive Question Answering (IQA), the task of answering questions such as 'Are there any apples in the fridge ?' that require an autonomous agent to interact with a dynamic visual environment.
-

One-Shot Part Labeling
This project addresses the problem of understanding diagrams in the absence of large labelled datasets, by transferring labels from smaller labeled datasets of diagrams (within-domain) as well as from labeled datasets of natural images (cross-domain).
-

MotifNet
MotifNet is a model for creating graph representations images, scene graphs. In scene graphs, every object is a node and relationships between objects are edges. MotifNet captures high-order, global repeating structures in such graphs, motifs.
-

SeGAN: Segmenting and Generating the Invisible
SeGAN is a model for generating the occluded regions of objects, where a GAN first generates the shape and then the appearance of the invisible regions.
-

Charades-Ego
Charades-Ego is a dataset that guides research into unstructured video activity recogntion and commonsense reasoning for daily human activities with paired videos of first person and third person perspective.
-

Visual Semantic Planning
A combination of Deep Reinforcement Learning and Imitation Learning to plan a sequence of actions for performing tasks.
-

Reasoning about Liquid Containers, their Volume and Content
Understanding the dynamics of liquids and their containers. The aim is to estimate the volume of containers, infer the amount of liquid, and predict pouring behavior.
-

LCNN: Lookup-based Convolutional Neural Network
The LCNN improves the efficiency of the convolutional neural networks by learning a dictionary and a small set linear weights of them and using a look up for inference.
-

YOLO
You only look once (YOLO) is a state-of-the-art, real-time object detection system.
-

imSitu
imSitu is a dataset supporting Situation Recognition, the problem of producing a concise summary of the situation an image depicts. Events (such as feeding) are described by verbs, objects and semantic roles defining how the objects are particpating.
-

Textbook Question Answering
TQA is a machine comprehension dataset that pairs middle school science questions with the supporing textbook material (including diagrams) needed to answer them.
-

Target-driven Visual Navigation
Deep Reinforcement Learning for the task of visual navigation. The goal is developing a more efficient and generalizable Reinforcement Learning approach.
-
Bidirectional Attention Flow for Machine Comprehension
Bi-directional Attention Flow (BiDAF) network is a multi-stage hierarchical process that represents context at different levels of granularity and uses a bi-directional attention flow mechanism to achieve a query-aware context representation without early summarization.
-

G-CNN: an Iterative Grid Based Object Detector
The G-CNN improves the precision of bounding box by regressing the location and scale of the bounding box iteratively.
-

XNOR-Net ImageNet Classification Using Binary Convolutional Neural Networks
This project aims at improving the efficiency of the convolutional neural networks by using the binary precision operations.
-

Charades
Charades is a dataset that guides research into unstructured video activity recogntion and commonsense reasoning for daily human activities.
-

Learning to Predict the Effect of Forces in Images
Predicting movements of objects via estimation of scene geometry and its underlying physics.
-

FigureSeer
FigureSeer is an end-to-end framework for parsing result-figures, that enables powerful search and retrieval of results in research papers.
-

Diagram Understanding
This project aims to parse diagrams and answer the corresponding questions.
-

A Task-Oriented Approach for Cost-sensitive Recognition
A task-oriented recognition approach, where the idea is to find the suitable set of features for each high-level task such that the computation cost is minimized.
-

Newtonian Image Understanding
Understanding the physics of a scene and the dynamics of objects in images.
-
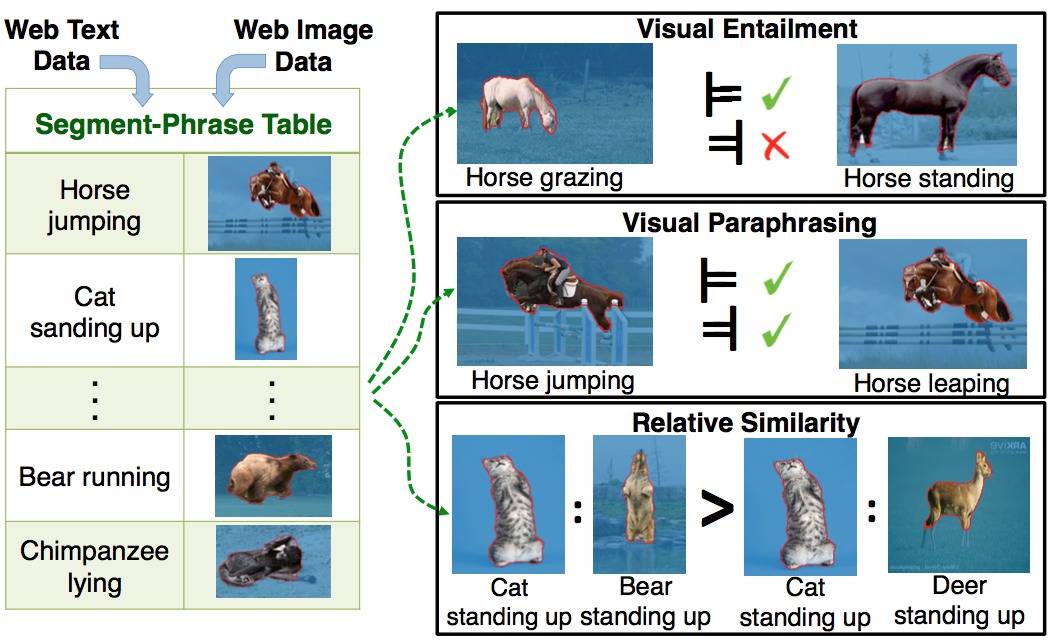
Segment-Phrase Table
Segment-phrase table is a large collection of bijective associations between textual phrases and their corresponding segmentations.
-
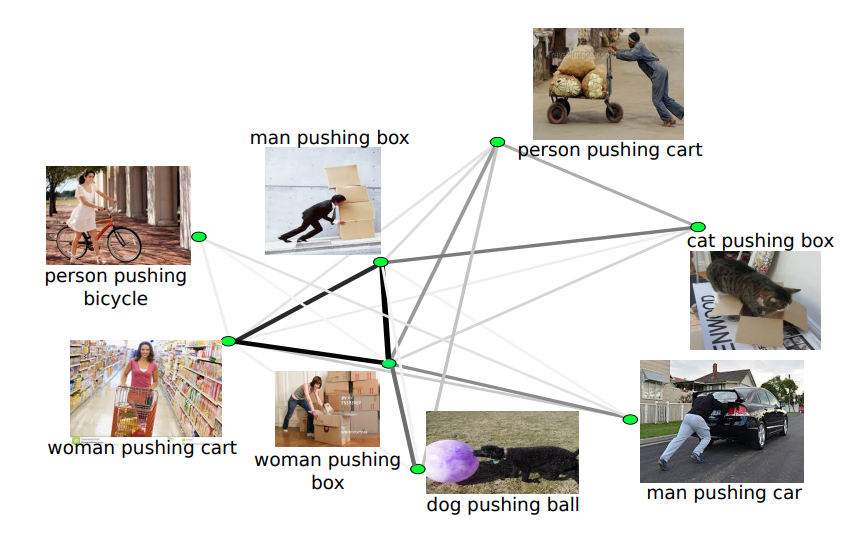
VisKE
VisKE is a VISual Knowledge Extraction and question answering system built using the idea of scalable visual verification of relation phrases.
-

LEVAN
LEVAN is a fully-automated visual concept learning program that automatically learns everything there is to know about any visual concept.
-

AI2-THOR
AI2-THOR is an open-source, interactive platform for embodied AI research. It allows artificial agents to physically interact with simulated objects and scenes. RoboTHOR extends AI2-THOR to include a series of simulated scenes with real-world counterparts.