




はじめに
こんにちは。検索基盤部の倉澤です。
私たちは、ZOZOTOWNの検索機能の改善に取り組んでいます。ZOZOTOWNのおすすめ順検索ではランキング学習を用いた検索機能の改善に取り組んでおり、A/Bテストにて効果を測定しています。
ランキング学習やElasticsearch Learning to Rankプラグインについては過去の記事で紹介していますので、併せてご覧ください。
techblog.zozo.com techblog.zozo.com
私たちは、機械学習モデルの開発からデプロイまでの一連の処理を実行するワークフローの構築にGoogle Cloud Platform(GCP)のVertex AI Pipelinesを利用しています。
本記事では、Vertex AI Pipelines採用前の運用とその課題点について説明し、次にVertex AI Pipelinesで構築したワークフロー概要とその運用について紹介します。
目次
Vertex AI Pipelines採用の背景
Vertex AI Pipelines採用に至った背景として、従来の運用と抱えていた課題点を紹介します。
従来の運用
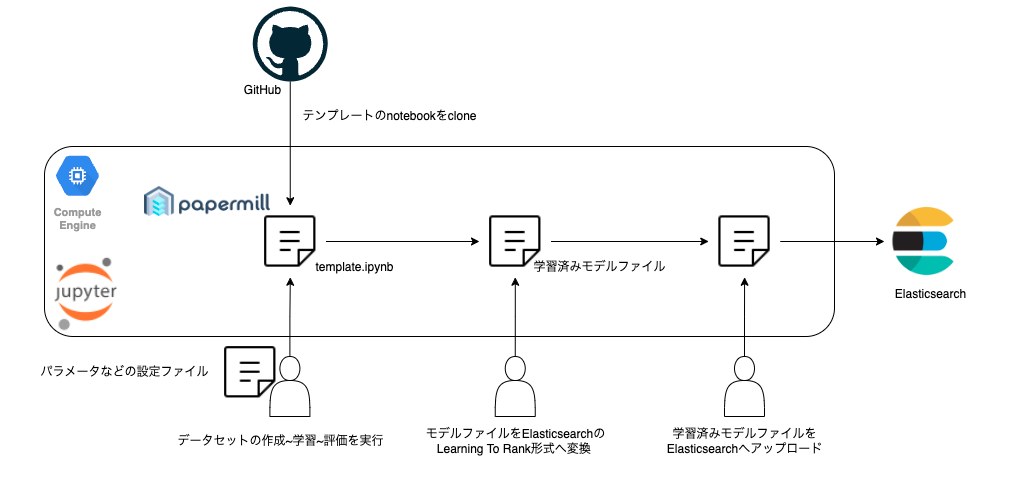
Vertex AI Pipelinesを採用する以前は、GitHubで管理されているスクリプトを、開発者が各自GCPに立てたインスタンスのJupyter Notebook上で順に実行していました。
機械学習モデルの学習期間や特徴量などのパラメータは設定ファイルで管理しており、papermillでNotebookを自動実行して機械学習モデルを生成します。そして、ElasticsearchのLearning to Rankプラグインで指定された形式にモデルを変換し、手動でデプロイを行っていました。
papermillとは
Jupyter Notebookを実行するライブラリとして記載したpapermillについて簡単に説明します。
papermillは、Jupyter Notebookに定義された各セルを実行するPythonライブラリです。 実行時にパラメータを渡すことで予めセルに定義されたデフォルトのパラメータの上書きが可能です。実行されたJupyter Notebookは別名のNotebookに保存できます。
私たちは、papermillをCLIで実行していました。
papermill input.ipynb output.ipynb -f parameter.yaml
設定ファイルは以下のようにYAMLファイルとして定義できます。
# parameter.yaml train_start_date: 20220101 train_end_date: 20220102 valid_start_date: 20220103 valid_end_date: 20220104 test_start_date: 20220105 test_end_date: 20220106 features: - feature1 - feature2 - feature3
抱えていた課題と解決策
従来の運用フローでは、モデルの数だけ同様の作業を手動で繰り返しており、以下の点を課題に感じていました。
- 各タスクの実施作業と実施完了の確認作業の工数が多い
- 実行前に設定ファイルの変更に対するレビューが無いので、誤りがあった場合は機械学習モデルを再度生成し直す必要がある
- 機械学習モデル生成の一連のタスクが途中で失敗した際に、一から再実行する必要がある
これらの課題を解決するために、各タスクを依存関係通りに実行でき、さらに再実行時にはキャッシュが利用できるワークフローエンジンの導入を検討しました。
候補となるワークフローエンジンはいくつかありましたが、弊社MLOpsブロックがVertex AI Pipelinesの実行環境の整備を進めていることもあり、より導入コストが低いVertex AI Pipelinesを選びました。
Vertex AI Pipelinesの実行環境については過去の記事で紹介していますので、併せてご覧ください。
Vertex AI Pipelinesによるワークフローの構築
私たちが構成した機械学習モデルの開発からデプロイまでのワークフローの概要を紹介します。以下の図は、実際に運用しているVertex AI Pipelinesのコンソール画面から確認できるワークフローの全体像です。

本ワークフローではおおよそ以下のことを行っております。
- 学習データセット生成に必要な期間のデータが揃っているかの確認
- 学習データセットの生成
- ハイパーパラメータチューニング及び最適なパラメータによる学習
- 評価及びオフライン評価結果の描画
- デプロイ判定
それぞれ順に説明します。
1. 学習データセット生成に必要な期間のデータが揃っているかの確認
学習に必要となる期間のデータが、対象のBigQueryテーブルに存在しているかの欠損チェックを行います。以下のようなAssertionクエリをコンポーネントから実行し、指定期間のデータが存在しているかを確認します。
-- check_bq_table.sql DECLARE target_dates ARRAY<DATE>; DECLARE x INT64 DEFAULT 1; SET target_dates = ( SELECT ARRAY_AGG(date ORDER BY date) FROM UNNEST(GENERATE_DATE_ARRAY('{{ start_date }}', '{{ end_date }}', INTERVAL 1 DAY) ) AS date ); WHILE x <= ARRAY_LENGTH(target_dates) DO ASSERT EXISTS( SELECT {{ period_column }} FROM `{{ full_table_id }}` WHERE DATE({{ period_column }}) = target_dates [ORDINAL(x)] ) AS 'target date does not exist in this table'; SET x = x+ 1; END WHILE;
2. 学習データセットの生成
学習・検証・テストのデータセットの生成をします。 以下のYAMLファイルはコンポーネントの入出力を定義し、学習・検証・テストのデータセットを出力しています。
# component.yaml name: Extract Dataset description: Prepare train/valid/test data inputs: - name: project_id type: String - name: job_name type: String - name: execute_date type: String outputs: - name: train_valid_data description: train/validデータセット type: Dataset - name: test_data description: testデータセット type: Dataset implementation: container: image: gcr.io/your_project_id/sample_component:gitsha-xxxx command: [ python, -m, src, --project_id, {inputValue: project_id}, --job_name, {inputValue: job_name}, --execute_date, {inputValue: execute_date}, --output_train_valid_data_path, {outputPath: train_valid_data}, --output_test_data_path, {outputPath: test_data}, ]
生成したデータセットはCloud Storage FUSEによってマウントされたGoogle Cloud Storageのバケットに格納され、そのパスを後続のコンポーネントへと渡しています。コマンドライン引数で定義されているoutput_train_valid_data_pathとoutput_test_data_pathがこれに該当します。
実行ファイルの中でデータセットの出力先となるパスをコマンドライン引数として受け取り、データセットを保存します。その後、後続のコンポーネントにてこのパスからデータセットを読み込むという流れになります。
3. ハイパーパラメータチューニング及び最適なパラメータによる学習
前段で生成された学習データセットと検証データセットを用いてモデルのハイパーパラメータチューニングを行います。その結果出力された最適なパラメータでモデルの学習をします。
4. 評価及びオフライン評価結果の描画
テストデータセットを用いて学習済みモデルの評価をします。コンポーネント内でオフライン指標として定めているnDCGを計算します。Vertex AI Pipelinesのコンソール画面はマークダウン形式での表示が可能なので、オフライン指標の計算結果を以下のように出力しています。
また、評価時にはベースラインモデルのオフライン指標も計算し、ベースラインモデルからのアップリフト値も併せて表示しています。

5. デプロイ判定
学習したモデルのオフライン指標及びベースラインモデルからのアップリフト値によって、デプロイして良いモデルなのか判定します。このデプロイ判定のコンポーネントの後にElasticsearchへモデルをアップロードするコンポーネントを用意しています。
Vertex AI Pipelines導入後の運用
A/Bテスト時には、コントロール群に適用するモデル(以下、コントロールモデル)とトリートメントモデル群に適用するモデル(以下、トリートメントモデル)をそれぞれ開発する必要があります。また、複数の実験を同時に行う場合はさらに多くのモデルが必要になります。
このA/Bテスト時のモデル開発における運用について紹介します。
A/Bテストのモデル開発時のブランチ戦略について
Vertex AI Pipelinesで利用するコンポーネントやパイプラインのソースコードなどはGitHubで管理しています。ここでは、A/Bテストで用いるコントロールモデル及びトリートメントモデル開発時のGitHubのブランチ戦略について簡単に紹介します。
コントロールモデルとトリートメントモデルのパイプラインの構成自体には基本的に大きな違いはなく、データセットを取得するSQLクエリや学習時のパラメータ値が異なります。
A/Bテストの度にトリートメントモデル用のSQLファイルや設定ファイルを新規に作成すると冗長な構造となってしまいます。そこで私たちは、ブランチごとにモデルの開発を分ける運用を採用しました。
main: コントロールモデルのデプロイ用ブランチ- コントロールモデルは定期的に学習及びデプロイされるようにスケジューリング
.*-abtest-treatment-[1-9]: トリートメントモデルの開発用及びデプロイ用ブランチ- prefixには各A/Bテストの名前がわかる任意の値を付与
- suffixにはトリートメントモデルの数に応じて番号を付与

トリートメントモデルのパイプラインは、開発ブランチからマージされた時にCIが実行するようにしています。 A/Bテストの結果、トリートメントモデルが勝った場合はそのブランチをmainブランチへマージし、負けた場合はそのままブランチを削除する運用にしています。
まとめ
Vertex AI Pipelinesを導入したことにより、冒頭に記載した以下の課題はおおよそ解決しました。
- 各タスクの実施作業と実施完了の確認作業の工数が多い
- 実行前に設定ファイルの変更に対するレビューが無いので、誤りがあった場合は機械学習モデルを再度生成し直す必要がある
- 機械学習モデル生成の一連のタスクが途中で失敗した際に、一から再実行する必要がある
コントロールモデルにおいては一通りの開発が終わり、現在はモデルの学習やデプロイの作業に工数を割くことはほとんどなくなりました。ただ、トリートメントモデルの開発やデプロイは現在も運用によりカバーしている側面もあるので、改善に向けて開発に取り組んでいます。
さいごに、ZOZOでは検索エンジニア・MLエンジニアのメンバーを募集しています。検索機能の改善に興味のある方は、以下のリンクからご応募ください。