 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Planning for Robotics: A Review for Sampling-based Planners
Oct 28, 2024Recent advancements in robotics have transformed industries such as manufacturing, logistics, surgery, and planetary exploration. A key challenge is developing efficient motion planning algorithms that allow robots to navigate complex environments while avoiding collisions and optimizing metrics like path length, sweep area, execution time, and energy consumption. Among the available algorithms, sampling-based methods have gained the most traction in both research and industry due to their ability to handle complex environments, explore free space, and offer probabilistic completeness along with other formal guarantees. Despite their widespread application, significant challenges still remain. To advance future planning algorithms, it is essential to review the current state-of-the-art solutions and their limitations. In this context, this work aims to shed light on these challenges and assess the development and applicability of sampling-based methods. Furthermore, we aim to provide an in-depth analysis of the design and evaluation of ten of the most popular planners across various scenarios. Our findings highlight the strides made in sampling-based methods while underscoring persistent challenges. This work offers an overview of the important ongoing research in robotic motion planning.
Unveiling Ontological Commitment in Multi-Modal Foundation Models
Sep 25, 2024Ontological commitment, i.e., used concepts, relations, and assumptions, are a corner stone of qualitative reasoning (QR) models. The state-of-the-art for processing raw inputs, though, are deep neural networks (DNNs), nowadays often based off from multimodal foundation models. These automatically learn rich representations of concepts and respective reasoning. Unfortunately, the learned qualitative knowledge is opaque, preventing easy inspection, validation, or adaptation against available QR models. So far, it is possible to associate pre-defined concepts with latent representations of DNNs, but extractable relations are mostly limited to semantic similarity. As a next step towards QR for validation and verification of DNNs: Concretely, we propose a method that extracts the learned superclass hierarchy from a multimodal DNN for a given set of leaf concepts. Under the hood we (1) obtain leaf concept embeddings using the DNN's textual input modality; (2) apply hierarchical clustering to them, using that DNNs encode semantic similarities via vector distances; and (3) label the such-obtained parent concepts using search in available ontologies from QR. An initial evaluation study shows that meaningful ontological class hierarchies can be extracted from state-of-the-art foundation models. Furthermore, we demonstrate how to validate and verify a DNN's learned representations against given ontologies. Lastly, we discuss potential future applications in the context of QR.
Learning Task Planning from Multi-Modal Demonstration for Multi-Stage Contact-Rich Manipulation
Sep 18, 2024Large Language Models (LLMs) have gained popularity in task planning for long-horizon manipulation tasks. To enhance the validity of LLM-generated plans, visual demonstrations and online videos have been widely employed to guide the planning process. However, for manipulation tasks involving subtle movements but rich contact interactions, visual perception alone may be insufficient for the LLM to fully interpret the demonstration. Additionally, visual data provides limited information on force-related parameters and conditions, which are crucial for effective execution on real robots. In this paper, we introduce an in-context learning framework that incorporates tactile and force-torque information from human demonstrations to enhance LLMs' ability to generate plans for new task scenarios. We propose a bootstrapped reasoning pipeline that sequentially integrates each modality into a comprehensive task plan. This task plan is then used as a reference for planning in new task configurations. Real-world experiments on two different sequential manipulation tasks demonstrate the effectiveness of our framework in improving LLMs' understanding of multi-modal demonstrations and enhancing the overall planning performance.
TacDiffusion: Force-domain Diffusion Policy for Precise Tactile Manipulation
Sep 17, 2024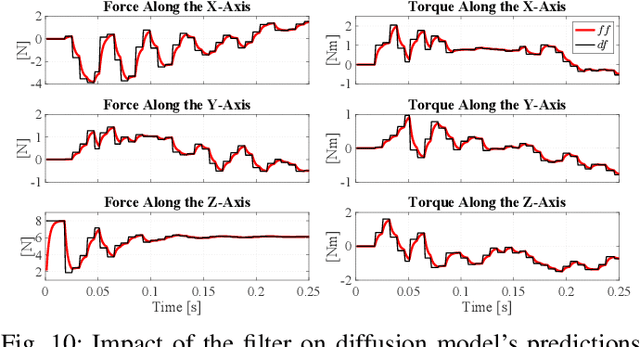
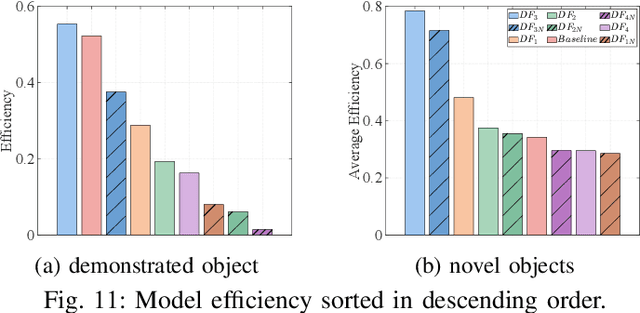
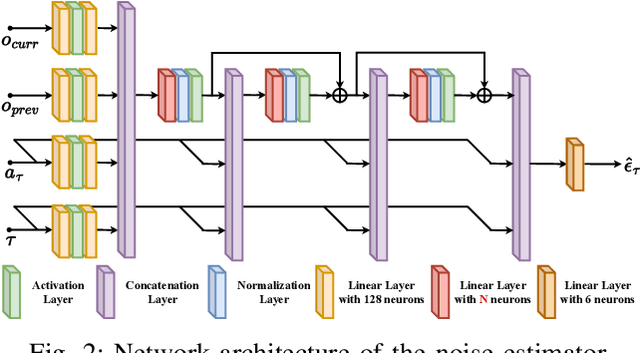

Assembly is a crucial skill for robots in both modern manufacturing and service robotics. However, mastering transferable insertion skills that can handle a variety of high-precision assembly tasks remains a significant challenge. This paper presents a novel framework that utilizes diffusion models to generate 6D wrench for high-precision tactile robotic insertion tasks. It learns from demonstrations performed on a single task and achieves a zero-shot transfer success rate of 95.7% across various novel high-precision tasks. Our method effectively inherits the self-adaptability demonstrated by our previous work. In this framework, we address the frequency misalignment between the diffusion policy and the real-time control loop with a dynamic system-based filter, significantly improving the task success rate by 9.15%. Furthermore, we provide a practical guideline regarding the trade-off between diffusion models' inference ability and speed.
How Could Generative AI Support Compliance with the EU AI Act? A Review for Safe Automated Driving Perception
Aug 30, 2024Deep Neural Networks (DNNs) have become central for the perception functions of autonomous vehicles, substantially enhancing their ability to understand and interpret the environment. However, these systems exhibit inherent limitations such as brittleness, opacity, and unpredictable behavior in out-of-distribution scenarios. The European Union (EU) Artificial Intelligence (AI) Act, as a pioneering legislative framework, aims to address these challenges by establishing stringent norms and standards for AI systems, including those used in autonomous driving (AD), which are categorized as high-risk AI. In this work, we explore how the newly available generative AI models can potentially support addressing upcoming regulatory requirements in AD perception, particularly with respect to safety. This short review paper summarizes the requirements arising from the EU AI Act regarding DNN-based perception systems and systematically categorizes existing generative AI applications in AD. While generative AI models show promise in addressing some of the EU AI Acts requirements, such as transparency and robustness, this review examines their potential benefits and discusses how developers could leverage these methods to enhance compliance with the Act. The paper also highlights areas where further research is needed to ensure reliable and safe integration of these technologies.
Transfer Learning from Simulated to Real Scenes for Monocular 3D Object Detection
Aug 28, 2024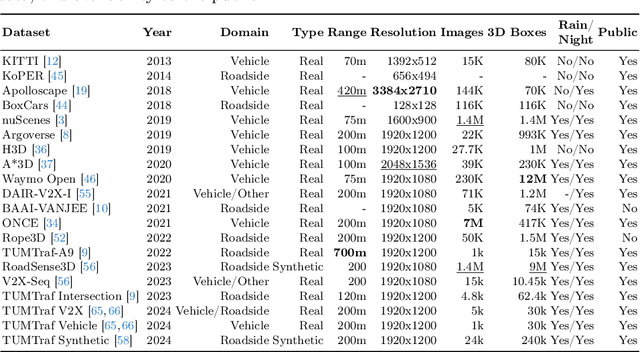


Accurately detecting 3D objects from monocular images in dynamic roadside scenarios remains a challenging problem due to varying camera perspectives and unpredictable scene conditions. This paper introduces a two-stage training strategy to address these challenges. Our approach initially trains a model on the large-scale synthetic dataset, RoadSense3D, which offers a diverse range of scenarios for robust feature learning. Subsequently, we fine-tune the model on a combination of real-world datasets to enhance its adaptability to practical conditions. Experimental results of the Cube R-CNN model on challenging public benchmarks show a remarkable improvement in detection performance, with a mean average precision rising from 0.26 to 12.76 on the TUM Traffic A9 Highway dataset and from 2.09 to 6.60 on the DAIR-V2X-I dataset when performing transfer learning. Code, data, and qualitative video results are available on the project website: https://roadsense3d.github.io.
DexGANGrasp: Dexterous Generative Adversarial Grasping Synthesis for Task-Oriented Manipulation
Jul 24, 2024We introduce DexGanGrasp, a dexterous grasping synthesis method that generates and evaluates grasps with single view in real time. DexGanGrasp comprises a Conditional Generative Adversarial Networks (cGANs)-based DexGenerator to generate dexterous grasps and a discriminator-like DexEvalautor to assess the stability of these grasps. Extensive simulation and real-world expriments showcases the effectiveness of our proposed method, outperforming the baseline FFHNet with an 18.57% higher success rate in real-world evaluation. We further extend DexGanGrasp to DexAfford-Prompt, an open-vocabulary affordance grounding pipeline for dexterous grasping leveraging Multimodal Large Language Models (MLLMs) and Vision Language Models (VLMs), to achieve task-oriented grasping with successful real-world deployments.
FFHFlow: A Flow-based Variational Approach for Multi-fingered Grasp Synthesis in Real Time
Jul 21, 2024Synthesizing diverse and accurate grasps with multi-fingered hands is an important yet challenging task in robotics. Previous efforts focusing on generative modeling have fallen short of precisely capturing the multi-modal, high-dimensional grasp distribution. To address this, we propose exploiting a special kind of Deep Generative Model (DGM) based on Normalizing Flows (NFs), an expressive model for learning complex probability distributions. Specifically, we first observed an encouraging improvement in diversity by directly applying a single conditional NFs (cNFs), dubbed FFHFlow-cnf, to learn a grasp distribution conditioned on the incomplete point cloud. However, we also recognized limited performance gains due to restricted expressivity in the latent space. This motivated us to develop a novel flow-based d Deep Latent Variable Model (DLVM), namely FFHFlow-lvm, which facilitates more reasonable latent features, leading to both diverse and accurate grasp synthesis for unseen objects. Unlike Variational Autoencoders (VAEs), the proposed DLVM counteracts typical pitfalls such as mode collapse and mis-specified priors by leveraging two cNFs for the prior and likelihood distributions, which are usually restricted to being isotropic Gaussian. Comprehensive experiments in simulation and real-robot scenarios demonstrate that our method generates more accurate and diverse grasps than the VAE baselines. Additionally, a run-time comparison is conducted to reveal its high potential for real-time applications.
HGL: Hierarchical Geometry Learning for Test-time Adaptation in 3D Point Cloud Segmentation
Jul 17, 20243D point cloud segmentation has received significant interest for its growing applications. However, the generalization ability of models suffers in dynamic scenarios due to the distribution shift between test and training data. To promote robustness and adaptability across diverse scenarios, test-time adaptation (TTA) has recently been introduced. Nevertheless, most existing TTA methods are developed for images, and limited approaches applicable to point clouds ignore the inherent hierarchical geometric structures in point cloud streams, i.e., local (point-level), global (object-level), and temporal (frame-level) structures. In this paper, we delve into TTA in 3D point cloud segmentation and propose a novel Hierarchical Geometry Learning (HGL) framework. HGL comprises three complementary modules from local, global to temporal learning in a bottom-up manner.Technically, we first construct a local geometry learning module for pseudo-label generation. Next, we build prototypes from the global geometry perspective for pseudo-label fine-tuning. Furthermore, we introduce a temporal consistency regularization module to mitigate negative transfer. Extensive experiments on four datasets demonstrate the effectiveness and superiority of our HGL. Remarkably, on the SynLiDAR to SemanticKITTI task, HGL achieves an overall mIoU of 46.91\%, improving GIPSO by 3.0\% and significantly reducing the required adaptation time by 80\%. The code is available at https://github.com/tpzou/HGL.
Embracing Events and Frames with Hierarchical Feature Refinement Network for Object Detection
Jul 17, 2024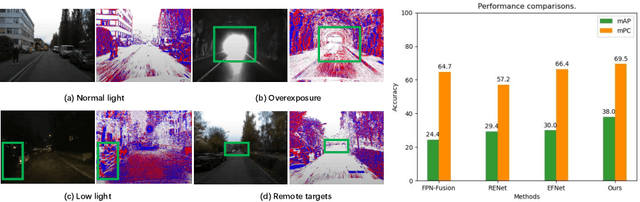


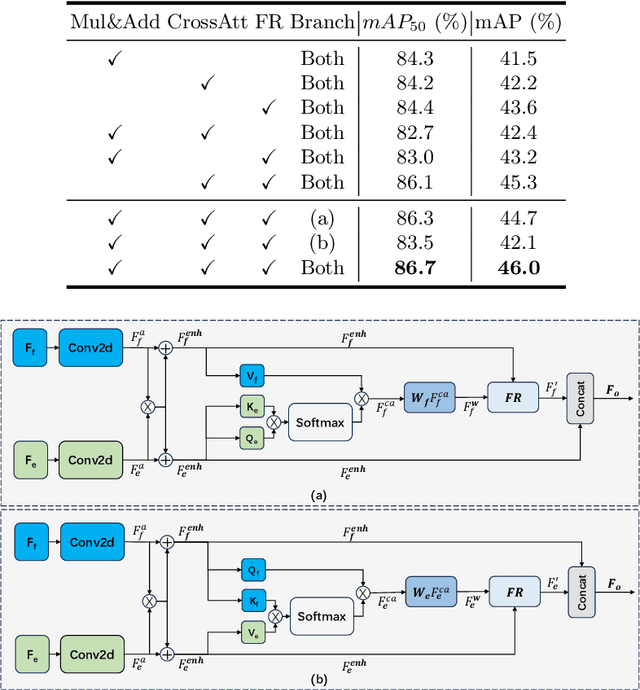
In frame-based vision, object detection faces substantial performance degradation under challenging conditions due to the limited sensing capability of conventional cameras. Event cameras output sparse and asynchronous events, providing a potential solution to solve these problems. However, effectively fusing two heterogeneous modalities remains an open issue. In this work, we propose a novel hierarchical feature refinement network for event-frame fusion. The core concept is the design of the coarse-to-fine fusion module, denoted as the cross-modality adaptive feature refinement (CAFR) module. In the initial phase, the bidirectional cross-modality interaction (BCI) part facilitates information bridging from two distinct sources. Subsequently, the features are further refined by aligning the channel-level mean and variance in the two-fold adaptive feature refinement (TAFR) part. We conducted extensive experiments on two benchmarks: the low-resolution PKU-DDD17-Car dataset and the high-resolution DSEC dataset. Experimental results show that our method surpasses the state-of-the-art by an impressive margin of $\textbf{8.0}\%$ on the DSEC dataset. Besides, our method exhibits significantly better robustness (\textbf{69.5}\% versus \textbf{38.7}\%) when introducing 15 different corruption types to the frame images. The code can be found at the link (https://github.com/HuCaoFighting/FRN).