 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning Optimizations for Auto-regressive Decoder of Multilingual ASR systems
Jul 04, 2024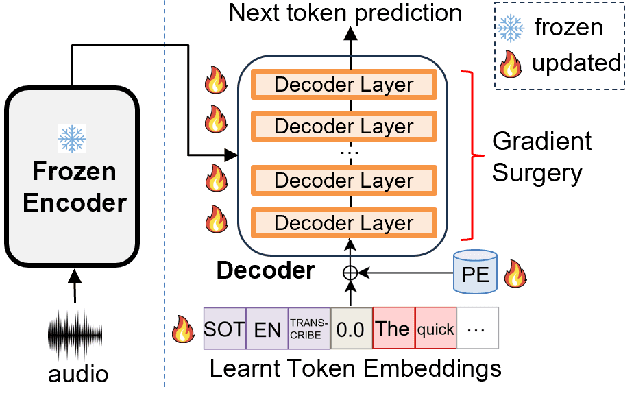
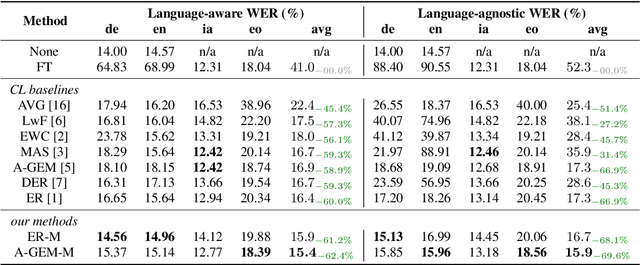
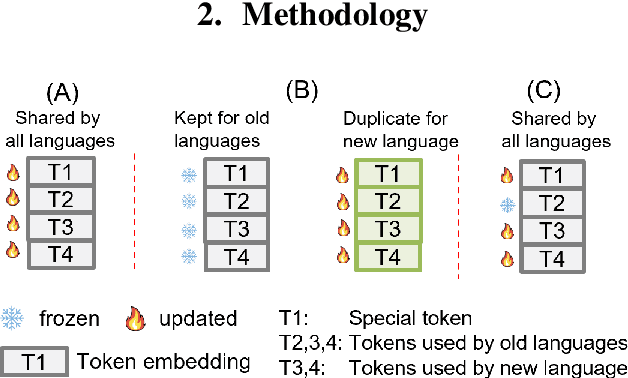
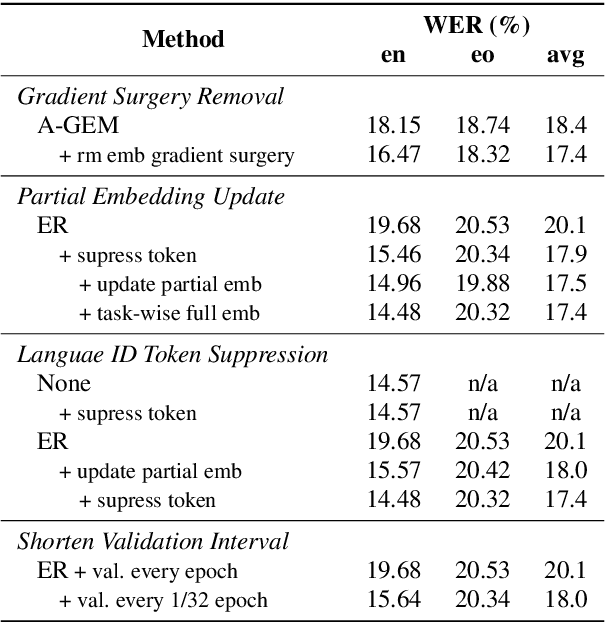
Continual Learning (CL) involves fine-tuning pre-trained models with new data while maintaining the performance on the pre-trained data. This is particularly relevant for expanding multilingual ASR (MASR) capabilities. However, existing CL methods, mainly designed for computer vision and reinforcement learning tasks, often yield sub-optimal results when directly applied to MASR. We hypothesise that this is because CL of the auto-regressive decoder in the MASR model is difficult. To verify this, we propose four optimizations on the decoder. They include decoder-layer gradient surgery, freezing unused token embeddings, suppressing output of newly added tokens, and learning rate re-scaling. Our experiments on adapting Whisper to 10 unseen languages from the Common Voice dataset demonstrate that these optimizations reduce the Average Word Error Rate (AWER) of pretrained languages from 14.2% to 12.4% compared with Experience Replay, without compromising the AWER of new languages.
Robust Zero-Shot Text-to-Speech Synthesis with Reverse Inference Optimization
Jul 02, 2024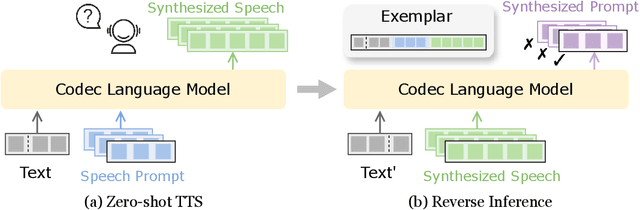
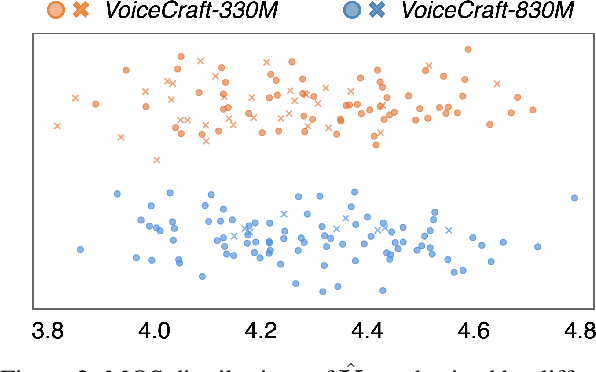
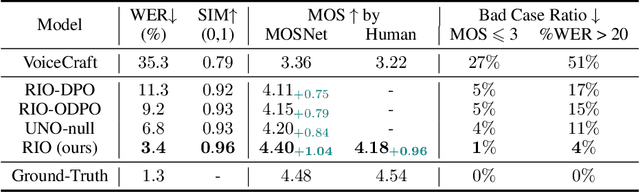
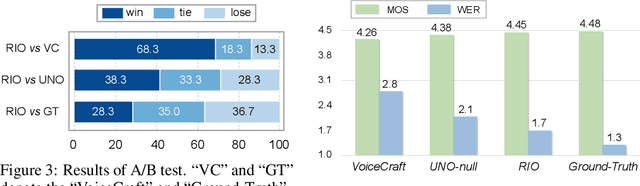
In this paper, we propose reverse inference optimization (RIO), a simple and effective method designed to enhance the robustness of autoregressive-model-based zero-shot text-to-speech (TTS) systems using reinforcement learning from human feedback (RLHF). To assess the quality of speech produced by the TTS system without human annotations, RIO introduces a novel concept termed as reverse inference based on the Bayesian principle, which suggests that a high-quality generated speech should be able to be used as a prompt for subsequent generation using the same TTS model. By leveraging reverse inference as the standard to select exemplars used in RLHF from the speech samples generated by the TTS system itself, RIO steers the subsequent optimization towards a direction of enhancing the TTS robustness. The RIO framework, comprising sampling, automatic annotating, and learning, obviates the need for a reward model or pairwise preference data, and significantly improves the stability of zero-shot TTS performance by reducing the discrepancies between training and inference conditions. Our experimental results verify that RIO can effectively improve both subjective and objective metrics, including mean opinion scores, word error rates, and speaker similarity. Remarkably, RIO can also diminish the incidence of bad outputs to nearly zero percent, rivalling the robustness when using ground-truth speech as the prompt.
Temporal-Channel Modeling in Multi-head Self-Attention for Synthetic Speech Detection
Jun 25, 2024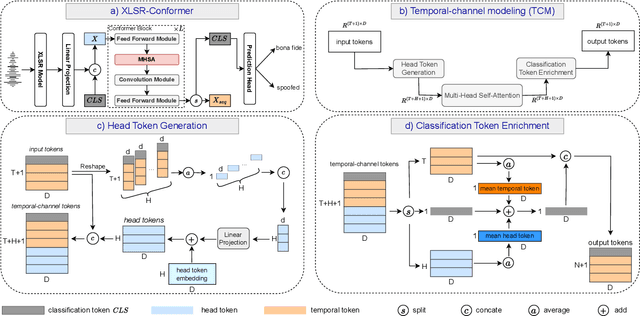
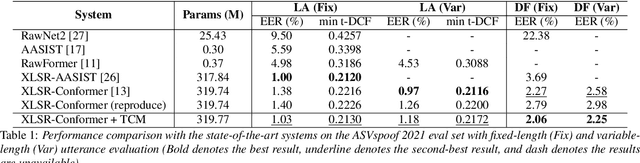
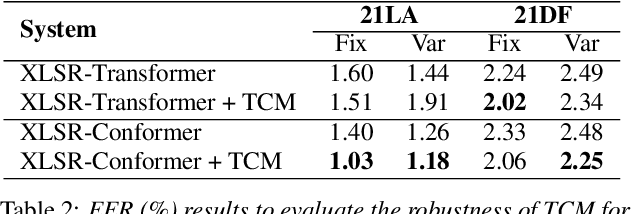

Recent synthetic speech detectors leveraging the Transformer model have superior performance compared to the convolutional neural network counterparts. This improvement could be due to the powerful modeling ability of the multi-head self-attention (MHSA) in the Transformer model, which learns the temporal relationship of each input token. However, artifacts of synthetic speech can be located in specific regions of both frequency channels and temporal segments, while MHSA neglects this temporal-channel dependency of the input sequence. In this work, we proposed a Temporal-Channel Modeling (TCM) module to enhance MHSA's capability for capturing temporal-channel dependencies. Experimental results on the ASVspoof 2021 show that with only 0.03M additional parameters, the TCM module can outperform the state-of-the-art system by 9.25% in EER. Further ablation study reveals that utilizing both temporal and channel information yields the most improvement for detecting synthetic speech.
Towards Audio Codec-based Speech Separation
Jun 18, 2024Recent improvements in neural audio codec (NAC) models have generated interest in adopting pre-trained codecs for a variety of speech processing applications to take advantage of the efficiencies gained from high compression, but these have yet been applied to the speech separation (SS) task. SS can benefit from high compression because the compute required for traditional SS models makes them impractical for many edge computing use cases. However, SS is a waveform-masking task where compression tends to introduce distortions that severely impact performance. Here we propose a novel task of Audio Codec-based SS, where SS is performed within the embedding space of a NAC, and propose a new model, Codecformer, to address this task. At inference, Codecformer achieves a 52x reduction in MAC while producing separation performance comparable to a cloud deployment of Sepformer. This method charts a new direction for performing efficient SS in practical scenarios.
Dataset-Distillation Generative Model for Speech Emotion Recognition
Jun 05, 2024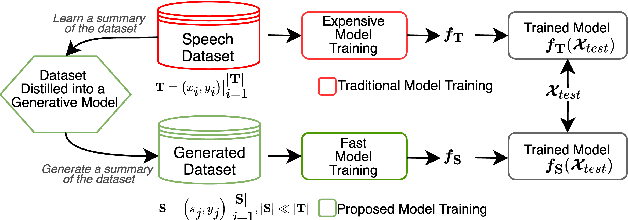

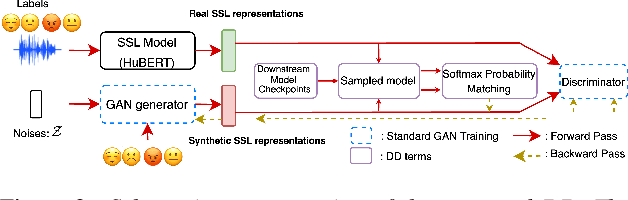
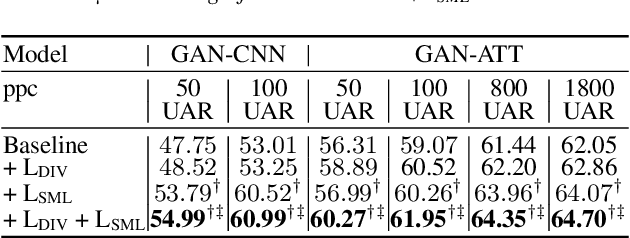
Deep learning models for speech rely on large datasets, presenting computational challenges. Yet, performance hinges on training data size. Dataset Distillation (DD) aims to learn a smaller dataset without much performance degradation when training with it. DD has been investigated in computer vision but not yet in speech. This paper presents the first approach for DD to speech targeting Speech Emotion Recognition on IEMOCAP. We employ Generative Adversarial Networks (GANs) not to mimic real data but to distil key discriminative information of IEMOCAP that is useful for downstream training. The GAN then replaces the original dataset and can sample custom synthetic dataset sizes. It performs comparably when following the original class imbalance but improves performance by 0.3% absolute UAR with balanced classes. It also reduces dataset storage and accelerates downstream training by 95% in both cases and reduces speaker information which could help for a privacy application.
Enhancing Zero-shot Text-to-Speech Synthesis with Human Feedback
Jun 02, 2024In recent years, text-to-speech (TTS) technology has witnessed impressive advancements, particularly with large-scale training datasets, showcasing human-level speech quality and impressive zero-shot capabilities on unseen speakers. However, despite human subjective evaluations, such as the mean opinion score (MOS), remaining the gold standard for assessing the quality of synthetic speech, even state-of-the-art TTS approaches have kept human feedback isolated from training that resulted in mismatched training objectives and evaluation metrics. In this work, we investigate a novel topic of integrating subjective human evaluation into the TTS training loop. Inspired by the recent success of reinforcement learning from human feedback, we propose a comprehensive sampling-annotating-learning framework tailored to TTS optimization, namely uncertainty-aware optimization (UNO). Specifically, UNO eliminates the need for a reward model or preference data by directly maximizing the utility of speech generations while considering the uncertainty that lies in the inherent variability in subjective human speech perception and evaluations. Experimental results of both subjective and objective evaluations demonstrate that UNO considerably improves the zero-shot performance of TTS models in terms of MOS, word error rate, and speaker similarity. Additionally, we present a remarkable ability of UNO that it can adapt to the desired speaking style in emotional TTS seamlessly and flexibly.
Self-Taught Recognizer: Toward Unsupervised Adaptation for Speech Foundation Models
May 23, 2024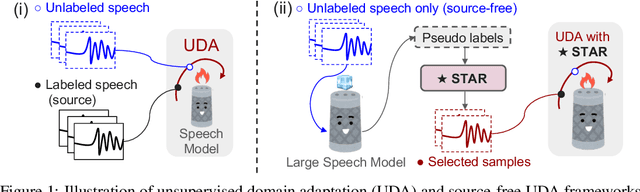
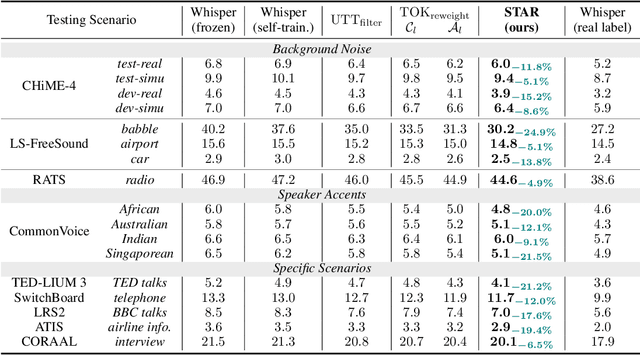
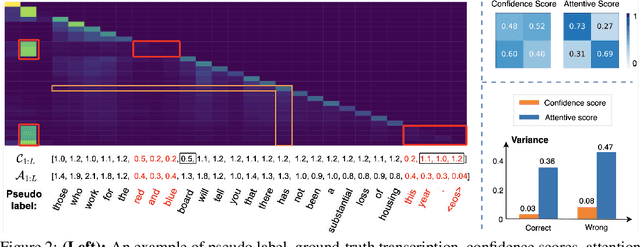
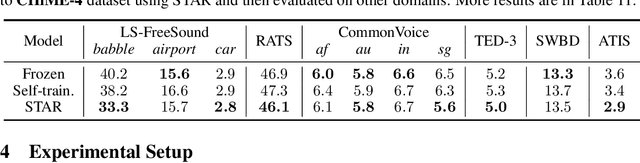
We propose an unsupervised adaptation framework, Self-TAught Recognizer (STAR), which leverages unlabeled data to enhance the robustness of automatic speech recognition (ASR) systems in diverse target domains, such as noise and accents. STAR is developed for prevalent speech foundation models based on Transformer-related architecture with auto-regressive decoding (e.g., Whisper, Canary). Specifically, we propose a novel indicator that empirically integrates step-wise information during decoding to assess the token-level quality of pseudo labels without ground truth, thereby guiding model updates for effective unsupervised adaptation. Experimental results show that STAR achieves an average of 13.5% relative reduction in word error rate across 14 target domains, and it sometimes even approaches the upper-bound performance of supervised adaptation. Surprisingly, we also observe that STAR prevents the adapted model from the common catastrophic forgetting problem without recalling source-domain data. Furthermore, STAR exhibits high data efficiency that only requires less than one-hour unlabeled data, and seamless generality to alternative large speech models and speech translation tasks. Our code aims to open source to the research communities.
Listen Again and Choose the Right Answer: A New Paradigm for Automatic Speech Recognition with Large Language Models
May 16, 2024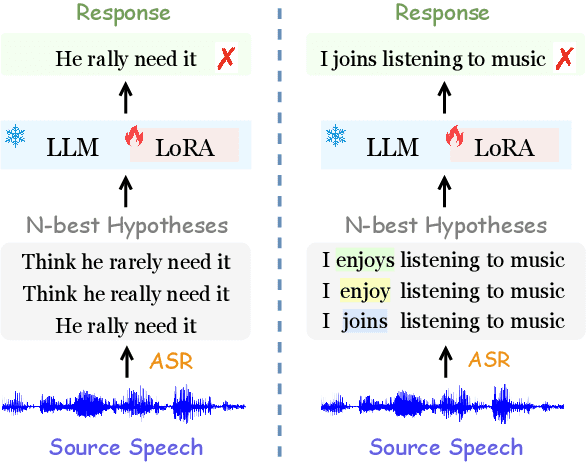
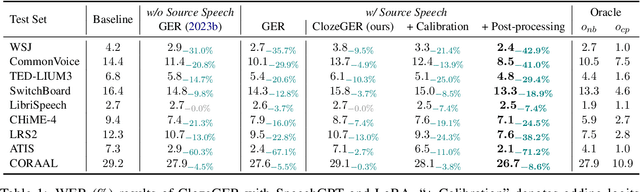
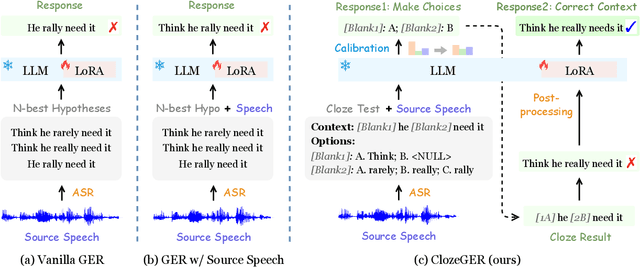
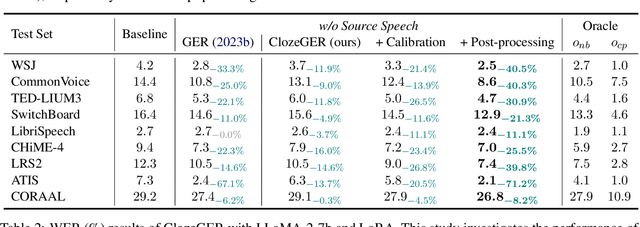
Recent advances in large language models (LLMs) have promoted generative error correction (GER) for automatic speech recognition (ASR), which aims to predict the ground-truth transcription from the decoded N-best hypotheses. Thanks to the strong language generation ability of LLMs and rich information in the N-best list, GER shows great effectiveness in enhancing ASR results. However, it still suffers from two limitations: 1) LLMs are unaware of the source speech during GER, which may lead to results that are grammatically correct but violate the source speech content, 2) N-best hypotheses usually only vary in a few tokens, making it redundant to send all of them for GER, which could confuse LLM about which tokens to focus on and thus lead to increased miscorrection. In this paper, we propose ClozeGER, a new paradigm for ASR generative error correction. First, we introduce a multimodal LLM (i.e., SpeechGPT) to receive source speech as extra input to improve the fidelity of correction output. Then, we reformat GER as a cloze test with logits calibration to remove the input information redundancy and simplify GER with clear instructions. Experiments show that ClozeGER achieves a new breakthrough over vanilla GER on 9 popular ASR datasets.
Aligning Speech to Languages to Enhance Code-switching Speech Recognition
Mar 09, 2024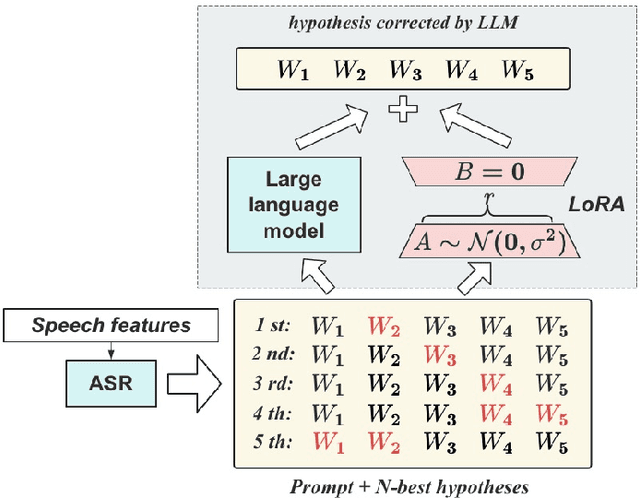
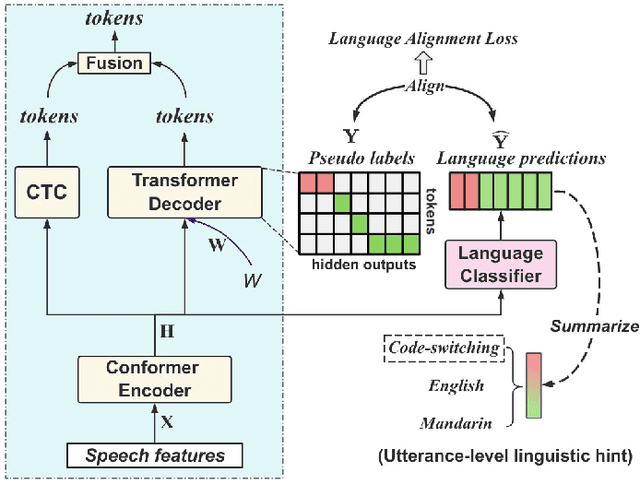
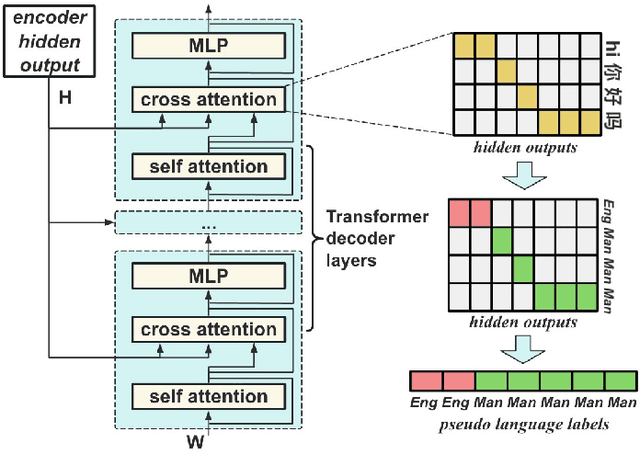
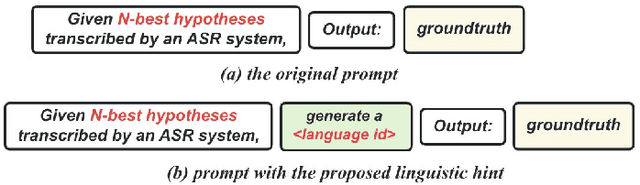
Code-switching (CS) refers to the switching of languages within a speech signal and results in language confusion for automatic speech recognition (ASR). To address language confusion, we propose the language alignment loss that performs frame-level language identification using pseudo language labels learned from the ASR decoder. This eliminates the need for frame-level language annotations. To further tackle the complex token alternatives for language modeling in bilingual scenarios, we propose to employ large language models via a generative error correction method. A linguistic hint that incorporates language information (derived from the proposed language alignment loss and decoded hypotheses) is introduced to guide the prompting of large language models. The proposed methods are evaluated on the SEAME dataset and data from the ASRU 2019 Mandarin-English code-switching speech recognition challenge. The incorporation of the proposed language alignment loss demonstrates a higher CS-ASR performance with only a negligible increase in the number of parameters on both datasets compared to the baseline model. This work also highlights the efficacy of language alignment loss in balancing primary-language-dominant bilingual data during training, with an 8.6% relative improvement on the ASRU dataset compared to the baseline model. Performance evaluation using large language models reveals the advantage of the linguistic hint by achieving 14.1% and 5.5% relative improvement on test sets of the ASRU and SEAME datasets, respectively.
Speaking in Wavelet Domain: A Simple and Efficient Approach to Speed up Speech Diffusion Model
Feb 16, 2024Recently, Denoising Diffusion Probabilistic Models (DDPMs) have attained leading performances across a diverse range of generative tasks. However, in the field of speech synthesis, although DDPMs exhibit impressive performance, their long training duration and substantial inference costs hinder practical deployment. Existing approaches primarily focus on enhancing inference speed, while approaches to accelerate training a key factor in the costs associated with adding or customizing voices often necessitate complex modifications to the model, compromising their universal applicability. To address the aforementioned challenges, we propose an inquiry: is it possible to enhance the training/inference speed and performance of DDPMs by modifying the speech signal itself? In this paper, we double the training and inference speed of Speech DDPMs by simply redirecting the generative target to the wavelet domain. This method not only achieves comparable or superior performance to the original model in speech synthesis tasks but also demonstrates its versatility. By investigating and utilizing different wavelet bases, our approach proves effective not just in speech synthesis, but also in speech enhancement.