 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamoTeacher: Dual-Rotation Consistency Learning for Semi-Supervised Camouflaged Object Detection
Aug 15, 2024Existing camouflaged object detection~(COD) methods depend heavily on large-scale pixel-level annotations.However, acquiring such annotations is laborious due to the inherent camouflage characteristics of the objects.Semi-supervised learning offers a promising solution to this challenge.Yet, its application in COD is hindered by significant pseudo-label noise, both pixel-level and instance-level.We introduce CamoTeacher, a novel semi-supervised COD framework, utilizing Dual-Rotation Consistency Learning~(DRCL) to effectively address these noise issues.Specifically, DRCL minimizes pseudo-label noise by leveraging rotation views' consistency in pixel-level and instance-level.First, it employs Pixel-wise Consistency Learning~(PCL) to deal with pixel-level noise by reweighting the different parts within the pseudo-label.Second, Instance-wise Consistency Learning~(ICL) is used to adjust weights for pseudo-labels, which handles instance-level noise.Extensive experiments on four COD benchmark datasets demonstrate that the proposed CamoTeacher not only achieves state-of-the-art compared with semi-supervised learning methods, but also rivals established fully-supervised learning methods.Our code will be available soon.
One Step Diffusion-based Super-Resolution with Time-Aware Distillation
Aug 14, 2024Diffusion-based image super-resolution (SR) methods have shown promise in reconstructing high-resolution images with fine details from low-resolution counterparts. However, these approaches typically require tens or even hundreds of iterative samplings, resulting in significant latency. Recently, techniques have been devised to enhance the sampling efficiency of diffusion-based SR models via knowledge distillation. Nonetheless, when aligning the knowledge of student and teacher models, these solutions either solely rely on pixel-level loss constraints or neglect the fact that diffusion models prioritize varying levels of information at different time steps. To accomplish effective and efficient image super-resolution, we propose a time-aware diffusion distillation method, named TAD-SR. Specifically, we introduce a novel score distillation strategy to align the data distribution between the outputs of the student and teacher models after minor noise perturbation. This distillation strategy enables the student network to concentrate more on the high-frequency details. Furthermore, to mitigate performance limitations stemming from distillation, we integrate a latent adversarial loss and devise a time-aware discriminator that leverages diffusion priors to effectively distinguish between real images and generated images. Extensive experiments conducted on synthetic and real-world datasets demonstrate that the proposed method achieves comparable or even superior performance compared to both previous state-of-the-art (SOTA) methods and the teacher model in just one sampling step. Codes are available at https://github.com/LearningHx/TAD-SR.
Deformable 3D Shape Diffusion Model
Jul 31, 2024


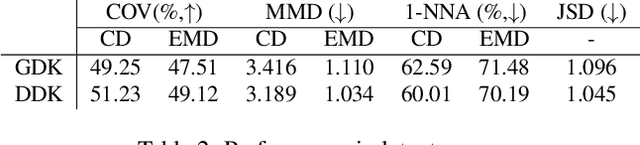
The Gaussian diffusion model, initially designed for image generation, has recently been adapted for 3D point cloud generation. However, these adaptations have not fully considered the intrinsic geometric characteristics of 3D shapes, thereby constraining the diffusion model's potential for 3D shape manipulation. To address this limitation, we introduce a novel deformable 3D shape diffusion model that facilitates comprehensive 3D shape manipulation, including point cloud generation, mesh deformation, and facial animation. Our approach innovatively incorporates a differential deformation kernel, which deconstructs the generation of geometric structures into successive non-rigid deformation stages. By leveraging a probabilistic diffusion model to simulate this step-by-step process, our method provides a versatile and efficient solution for a wide range of applications, spanning from graphics rendering to facial expression animation. Empirical evidence highlights the effectiveness of our approach, demonstrating state-of-the-art performance in point cloud generation and competitive results in mesh deformation. Additionally, extensive visual demonstrations reveal the significant potential of our approach for practical applications. Our method presents a unique pathway for advancing 3D shape manipulation and unlocking new opportunities in the realm of virtual reality.
Fine-gained Zero-shot Video Sampling
Jul 31, 2024Incorporating a temporal dimension into pretrained image diffusion models for video generation is a prevalent approach. However, this method is computationally demanding and necessitates large-scale video datasets. More critically, the heterogeneity between image and video datasets often results in catastrophic forgetting of the image expertise. Recent attempts to directly extract video snippets from image diffusion models have somewhat mitigated these problems. Nevertheless, these methods can only generate brief video clips with simple movements and fail to capture fine-grained motion or non-grid deformation. In this paper, we propose a novel Zero-Shot video Sampling algorithm, denoted as $\mathcal{ZS}^2$, capable of directly sampling high-quality video clips from existing image synthesis methods, such as Stable Diffusion, without any training or optimization. Specifically, $\mathcal{ZS}^2$ utilizes the dependency noise model and temporal momentum attention to ensure content consistency and animation coherence, respectively. This ability enables it to excel in related tasks, such as conditional and context-specialized video generation and instruction-guided video editing. Experimental results demonstrate that $\mathcal{ZS}^2$ achieves state-of-the-art performance in zero-shot video generation, occasionally outperforming recent supervised methods. Homepage: \url{https://densechen.github.io/zss/}.
Multi-Granularity Semantic Revision for Large Language Model Distillation
Jul 14, 2024
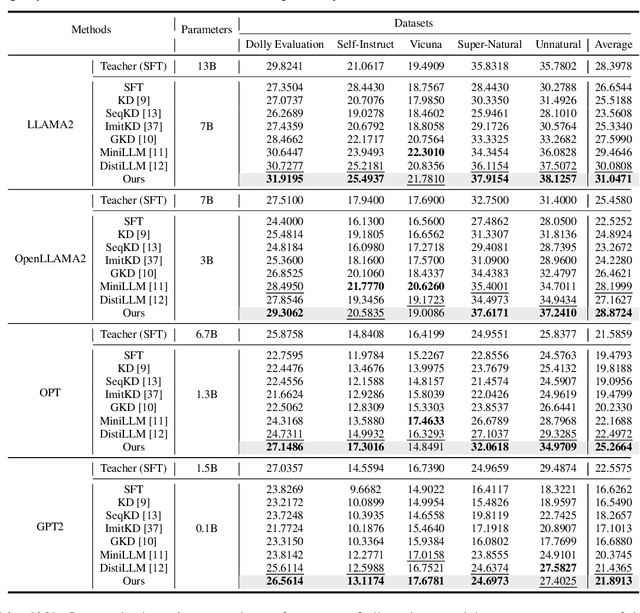


Knowledge distillation plays a key role in compressing the Large Language Models (LLMs), which boosts a small-size student model under large teacher models' guidance. However, existing LLM distillation methods overly rely on student-generated outputs, which may introduce generation errors and misguide the distillation process. Moreover, the distillation loss functions introduced in previous art struggle to align the most informative part due to the complex distribution of LLMs' outputs. To address these problems, we propose a multi-granularity semantic revision method for LLM distillation. At the sequence level, we propose a sequence correction and re-generation (SCRG) strategy. SCRG first calculates the semantic cognitive difference between the teacher and student to detect the error token, then corrects it with the teacher-generated one, and re-generates the sequence to reduce generation errors and enhance generation diversity. At the token level, we design a distribution adaptive clipping Kullback-Leibler (DAC-KL) loss as the distillation objective function. DAC-KL loss exploits a learnable sub-network to adaptively extract semantically dense areas from the teacher's output, avoiding the interference of redundant information in the distillation process. Finally, at the span level, we leverage the span priors of a sequence to compute the probability correlations within spans, and constrain the teacher and student's probability correlations to be consistent, further enhancing the transfer of semantic information. Extensive experiments across different model families with parameters ranging from 0.1B to 13B demonstrate the superiority of our method compared to existing methods.
Instruct-IPT: All-in-One Image Processing Transformer via Weight Modulation
Jun 30, 2024Due to the unaffordable size and intensive computation costs of low-level vision models, All-in-One models that are designed to address a handful of low-level vision tasks simultaneously have been popular. However, existing All-in-One models are limited in terms of the range of tasks and performance. To overcome these limitations, we propose Instruct-IPT -- an All-in-One Image Processing Transformer that could effectively address manifold image restoration tasks with large inter-task gaps, such as denoising, deblurring, deraining, dehazing, and desnowing. Rather than popular feature adaptation methods, we propose weight modulation that adapts weights to specific tasks. Firstly, we figure out task-sensitive weights via a toy experiment and introduce task-specific biases on top of them. Secondly, we conduct rank analysis for a good compression strategy and perform low-rank decomposition on the biases. Thirdly, we propose synchronous training that updates the task-general backbone model and the task-specific biases simultaneously. In this way, the model is instructed to learn general and task-specific knowledge. Via our simple yet effective method that instructs the IPT to be task experts, Instruct-IPT could better cooperate between tasks with distinct characteristics at humble costs. Further, we propose to maneuver Instruct-IPT with text instructions for better user interfaces. We have conducted experiments on Instruct-IPT to demonstrate the effectiveness of our method on manifold tasks, and we have effectively extended our method to diffusion denoisers as well. The code is available at https://github.com/huawei-noah/Pretrained-IPT.
Depth-Guided Semi-Supervised Instance Segmentation
Jun 25, 2024Semi-Supervised Instance Segmentation (SSIS) aims to leverage an amount of unlabeled data during training. Previous frameworks primarily utilized the RGB information of unlabeled images to generate pseudo-labels. However, such a mechanism often introduces unstable noise, as a single instance can display multiple RGB values. To overcome this limitation, we introduce a Depth-Guided (DG) SSIS framework. This framework uses depth maps extracted from input images, which represent individual instances with closely associated distance values, offering precise contours for distinct instances. Unlike RGB data, depth maps provide a unique perspective, making their integration into the SSIS process complex. To this end, we propose Depth Feature Fusion, which integrates features extracted from depth estimation. This integration allows the model to understand depth information better and ensure its effective utilization. Additionally, to manage the variability of depth images during training, we introduce the Depth Controller. This component enables adaptive adjustments of the depth map, enhancing convergence speed and dynamically balancing the loss weights between RGB and depth maps. Extensive experiments conducted on the COCO and Cityscapes datasets validate the efficacy of our proposed method. Our approach establishes a new benchmark for SSIS, outperforming previous methods. Specifically, our DG achieves 22.29%, 31.47%, and 35.14% mAP for 1%, 5%, and 10% labeled data on the COCO dataset, respectively.
GIM: A Million-scale Benchmark for Generative Image Manipulation Detection and Localization
Jun 24, 2024The extraordinary ability of generative models emerges as a new trend in image editing and generating realistic images, posing a serious threat to the trustworthiness of multimedia data and driving the research of image manipulation detection and location(IMDL). However, the lack of a large-scale data foundation makes IMDL task unattainable. In this paper, a local manipulation pipeline is designed, incorporating the powerful SAM, ChatGPT and generative models. Upon this basis, We propose the GIM dataset, which has the following advantages: 1) Large scale, including over one million pairs of AI-manipulated images and real images. 2) Rich Image Content, encompassing a broad range of image classes 3) Diverse Generative Manipulation, manipulated images with state-of-the-art generators and various manipulation tasks. The aforementioned advantages allow for a more comprehensive evaluation of IMDL methods, extending their applicability to diverse images. We introduce two benchmark settings to evaluate the generalization capability and comprehensive performance of baseline methods. In addition, we propose a novel IMDL framework, termed GIMFormer, which consists of a ShadowTracer, Frequency-Spatial Block (FSB), and a Multi-window Anomalous Modelling (MWAM) Module. Extensive experiments on the GIM demonstrate that GIMFormer surpasses previous state-of-the-art works significantly on two different benchmarks.
Methodology and Real-World Applications of Dynamic Uncertain Causality Graph for Clinical Diagnosis with Explainability and Invariance
Jun 09, 2024AI-aided clinical diagnosis is desired in medical care. Existing deep learning models lack explainability and mainly focus on image analysis. The recently developed Dynamic Uncertain Causality Graph (DUCG) approach is causality-driven, explainable, and invariant across different application scenarios, without problems of data collection, labeling, fitting, privacy, bias, generalization, high cost and high energy consumption. Through close collaboration between clinical experts and DUCG technicians, 46 DUCG models covering 54 chief complaints were constructed. Over 1,000 diseases can be diagnosed without triage. Before being applied in real-world, the 46 DUCG models were retrospectively verified by third-party hospitals. The verified diagnostic precisions were no less than 95%, in which the diagnostic precision for every disease including uncommon ones was no less than 80%. After verifications, the 46 DUCG models were applied in the real-world in China. Over one million real diagnosis cases have been performed, with only 17 incorrect diagnoses identified. Due to DUCG's transparency, the mistakes causing the incorrect diagnoses were found and corrected. The diagnostic abilities of the clinicians who applied DUCG frequently were improved significantly. Following the introduction to the earlier presented DUCG methodology, the recommendation algorithm for potential medical checks is presented and the key idea of DUCG is extracted.
End-to-End Design of Polar Coded Integrated Data and Energy Networking
Jun 07, 2024



In order to transmit data and transfer energy to the low-power Internet of Things (IoT) devices, integrated data and energy networking (IDEN) system may be harnessed. In this context, we propose a bitwise end-to-end design for polar coded IDEN systems, where the conventional encoding/decoding, modulation/demodulation, and energy harvesting (EH) modules are replaced by the neural networks (NNs). In this way, the entire system can be treated as an AutoEncoder (AE) and trained in an end-to-end manner. Hence achieving global optimization. Additionally, we improve the common NN-based belief propagation (BP) decoder by adding an extra hypernetwork, which generates the corresponding NN weights for the main network under different number of iterations, thus the adaptability of the receiver architecture can be further enhanced. Our numerical results demonstrate that our BP-based end-to-end design is superior to conventional BP-based counterparts in terms of both the BER and power transfer, but it is inferior to the successive cancellation list (SCL)-based conventional IDEN system, which may be due to the inherent performance gap between the BP and SCL decoders.