 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUSA: Multi-lingual Speaker Anonymization via Serial Disentanglement
Jul 16, 2024Speaker anonymization is an effective privacy protection solution designed to conceal the speaker's identity while preserving the linguistic content and para-linguistic information of the original speech. While most prior studies focus solely on a single language, an ideal speaker anonymization system should be capable of handling multiple languages. This paper proposes MUSA, a Multi-lingual Speaker Anonymization approach that employs a serial disentanglement strategy to perform a step-by-step disentanglement from a global time-invariant representation to a temporal time-variant representation. By utilizing semantic distillation and self-supervised speaker distillation, the serial disentanglement strategy can avoid strong inductive biases and exhibit superior generalization performance across different languages. Meanwhile, we propose a straightforward anonymization strategy that employs empty embedding with zero values to simulate the speaker identity concealment process, eliminating the need for conversion to a pseudo-speaker identity and thereby reducing the complexity of speaker anonymization process. Experimental results on VoicePrivacy official datasets and multi-lingual datasets demonstrate that MUSA can effectively protect speaker privacy while preserving linguistic content and para-linguistic information.
Learning Multi-view Anomaly Detection
Jul 16, 2024This study explores the recently proposed challenging multi-view Anomaly Detection (AD) task. Single-view tasks would encounter blind spots from other perspectives, resulting in inaccuracies in sample-level prediction. Therefore, we introduce the \textbf{M}ulti-\textbf{V}iew \textbf{A}nomaly \textbf{D}etection (\textbf{MVAD}) framework, which learns and integrates features from multi-views. Specifically, we proposed a \textbf{M}ulti-\textbf{V}iew \textbf{A}daptive \textbf{S}election (\textbf{MVAS}) algorithm for feature learning and fusion across multiple views. The feature maps are divided into neighbourhood attention windows to calculate a semantic correlation matrix between single-view windows and all other views, which is a conducted attention mechanism for each single-view window and the top-K most correlated multi-view windows. Adjusting the window sizes and top-K can minimise the computational complexity to linear. Extensive experiments on the Real-IAD dataset for cross-setting (multi/single-class) validate the effectiveness of our approach, achieving state-of-the-art performance among sample \textbf{4.1\%}$\uparrow$/ image \textbf{5.6\%}$\uparrow$/pixel \textbf{6.7\%}$\uparrow$ levels with a total of ten metrics with only \textbf{18M} parameters and fewer GPU memory and training time.
Whisper-SV: Adapting Whisper for Low-data-resource Speaker Verification
Jul 14, 2024Trained on 680,000 hours of massive speech data, Whisper is a multitasking, multilingual speech foundation model demonstrating superior performance in automatic speech recognition, translation, and language identification. However, its applicability in speaker verification (SV) tasks remains unexplored, particularly in low-data-resource scenarios where labeled speaker data in specific domains are limited. To fill this gap, we propose a lightweight adaptor framework to boost SV with Whisper, namely Whisper-SV. Given that Whisper is not specifically optimized for SV tasks, we introduce a representation selection module to quantify the speaker-specific characteristics contained in each layer of Whisper and select the top-k layers with prominent discriminative speaker features. To aggregate pivotal speaker-related features while diminishing non-speaker redundancies across the selected top-k distinct layers of Whisper, we design a multi-layer aggregation module in Whisper-SV to integrate multi-layer representations into a singular, compacted representation for SV. In the multi-layer aggregation module, we employ convolutional layers with shortcut connections among different layers to refine speaker characteristics derived from multi-layer representations from Whisper. In addition, an attention aggregation layer is used to reduce non-speaker interference and amplify speaker-specific cues for SV tasks. Finally, a simple classification module is used for speaker classification. Experiments on VoxCeleb1, FFSVC, and IMSV datasets demonstrate that Whisper-SV achieves EER/minDCF of 2.22%/0.307, 6.14%/0.488, and 7.50%/0.582, respectively, showing superior performance in low-data-resource SV scenarios.
AI-driven multi-omics integration for multi-scale predictive modeling of causal genotype-environment-phenotype relationships
Jul 08, 2024Despite the wealth of single-cell multi-omics data, it remains challenging to predict the consequences of novel genetic and chemical perturbations in the human body. It requires knowledge of molecular interactions at all biological levels, encompassing disease models and humans. Current machine learning methods primarily establish statistical correlations between genotypes and phenotypes but struggle to identify physiologically significant causal factors, limiting their predictive power. Key challenges in predictive modeling include scarcity of labeled data, generalization across different domains, and disentangling causation from correlation. In light of recent advances in multi-omics data integration, we propose a new artificial intelligence (AI)-powered biology-inspired multi-scale modeling framework to tackle these issues. This framework will integrate multi-omics data across biological levels, organism hierarchies, and species to predict causal genotype-environment-phenotype relationships under various conditions. AI models inspired by biology may identify novel molecular targets, biomarkers, pharmaceutical agents, and personalized medicines for presently unmet medical needs.
Streaming Decoder-Only Automatic Speech Recognition with Discrete Speech Units: A Pilot Study
Jun 27, 2024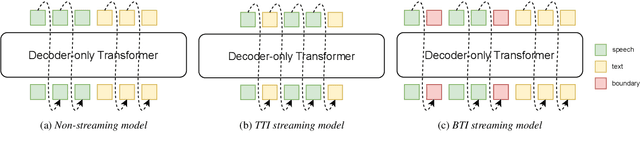
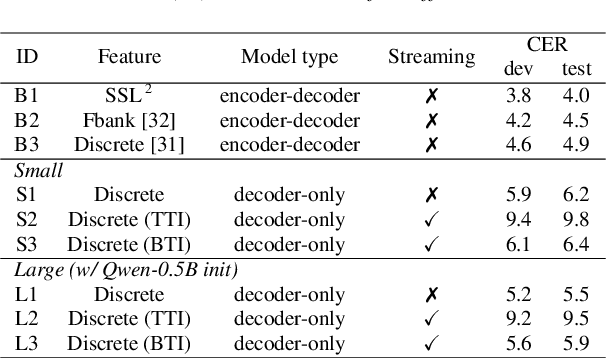
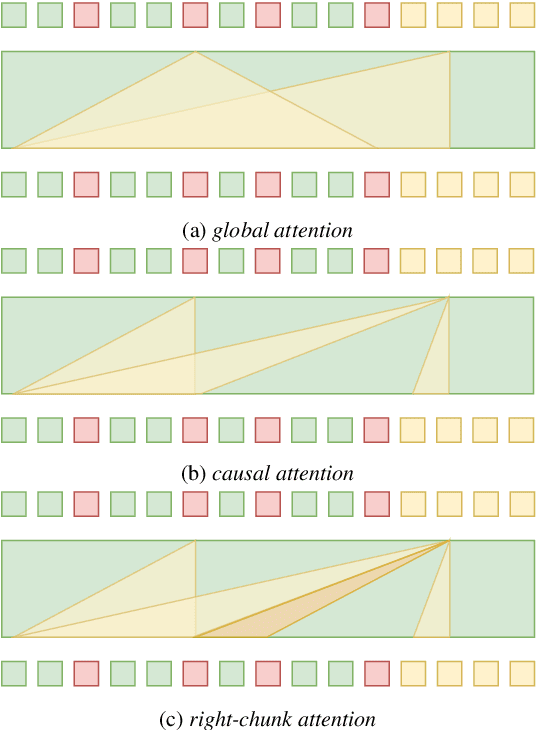

Unified speech-text models like SpeechGPT, VioLA, and AudioPaLM have shown impressive performance across various speech-related tasks, especially in Automatic Speech Recognition (ASR). These models typically adopt a unified method to model discrete speech and text tokens, followed by training a decoder-only transformer. However, they are all designed for non-streaming ASR tasks, where the entire speech utterance is needed during decoding. Hence, we introduce a decoder-only model exclusively designed for streaming recognition, incorporating a dedicated boundary token to facilitate streaming recognition and employing causal attention masking during the training phase. Furthermore, we introduce right-chunk attention and various data augmentation techniques to improve the model's contextual modeling abilities. While achieving streaming speech recognition, experiments on the AISHELL-1 and -2 datasets demonstrate the competitive performance of our streaming approach with non-streaming decoder-only counterparts.
Vec-Tok-VC+: Residual-enhanced Robust Zero-shot Voice Conversion with Progressive Constraints in a Dual-mode Training Strategy
Jun 14, 2024Zero-shot voice conversion (VC) aims to transform source speech into arbitrary unseen target voice while keeping the linguistic content unchanged. Recent VC methods have made significant progress, but semantic losses in the decoupling process as well as training-inference mismatch still hinder conversion performance. In this paper, we propose Vec-Tok-VC+, a novel prompt-based zero-shot VC model improved from Vec-Tok Codec, achieving voice conversion given only a 3s target speaker prompt. We design a residual-enhanced K-Means decoupler to enhance the semantic content extraction with a two-layer clustering process. Besides, we employ teacher-guided refinement to simulate the conversion process to eliminate the training-inference mismatch, forming a dual-mode training strategy. Furthermore, we design a multi-codebook progressive loss function to constrain the layer-wise output of the model from coarse to fine to improve speaker similarity and content accuracy. Objective and subjective evaluations demonstrate that Vec-Tok-VC+ outperforms the strong baselines in naturalness, intelligibility, and speaker similarity.
SCDNet: Self-supervised Learning Feature-based Speaker Change Detection
Jun 12, 2024Speaker Change Detection (SCD) is to identify boundaries among speakers in a conversation. Motivated by the success of fine-tuning wav2vec 2.0 models for the SCD task, a further investigation of self-supervised learning (SSL) features for SCD is conducted in this work. Specifically, an SCD model, named SCDNet, is proposed. With this model, various state-of-the-art SSL models, including Hubert, wav2vec 2.0, and WavLm are investigated. To discern the most potent layer of SSL models for SCD, a learnable weighting method is employed to analyze the effectiveness of intermediate representations. Additionally, a fine-tuning-based approach is also implemented to further compare the characteristics of SSL models in the SCD task. Furthermore, a contrastive learning method is proposed to mitigate the overfitting tendencies in the training of both the fine-tuning-based method and SCDNet. Experiments showcase the superiority of WavLm in the SCD task and also demonstrate the good design of SCDNet.
DualVC 3: Leveraging Language Model Generated Pseudo Context for End-to-end Low Latency Streaming Voice Conversion
Jun 12, 2024Streaming voice conversion has become increasingly popular for its potential in real-time applications. The recently proposed DualVC 2 has achieved robust and high-quality streaming voice conversion with a latency of about 180ms. Nonetheless, the recognition-synthesis framework hinders end-to-end optimization, and the instability of automatic speech recognition (ASR) model with short chunks makes it challenging to further reduce latency. To address these issues, we propose an end-to-end model, DualVC 3. With speaker-independent semantic tokens to guide the training of the content encoder, the dependency on ASR is removed and the model can operate under extremely small chunks, with cascading errors eliminated. A language model is trained on the content encoder output to produce pseudo context by iteratively predicting future frames, providing more contextual information for the decoder to improve conversion quality. Experimental results demonstrate that DualVC 3 achieves comparable performance to DualVC 2 in subjective and objective metrics, with a latency of only 50 ms.
Text-aware and Context-aware Expressive Audiobook Speech Synthesis
Jun 12, 2024Recent advances in text-to-speech have significantly improved the expressiveness of synthetic speech. However, a major challenge remains in generating speech that captures the diverse styles exhibited by professional narrators in audiobooks without relying on manually labeled data or reference speech. To address this problem, we propose a text-aware and context-aware(TACA) style modeling approach for expressive audiobook speech synthesis. We first establish a text-aware style space to cover diverse styles via contrastive learning with the supervision of the speech style. Meanwhile, we adopt a context encoder to incorporate cross-sentence information and the style embedding obtained from text. Finally, we introduce the context encoder to two typical TTS models, VITS-based TTS and language model-based TTS. Experimental results demonstrate that our proposed approach can effectively capture diverse styles and coherent prosody, and consequently improves naturalness and expressiveness in audiobook speech synthesis.
FreeV: Free Lunch For Vocoders Through Pseudo Inversed Mel Filter
Jun 12, 2024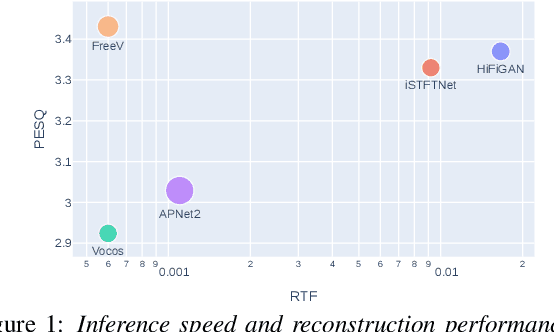
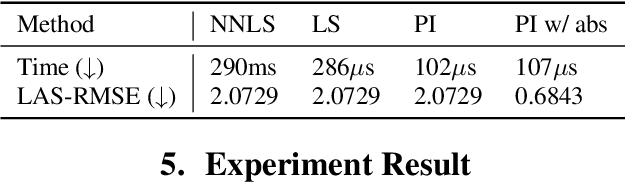
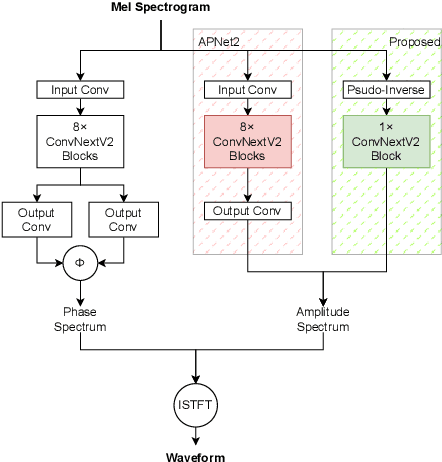
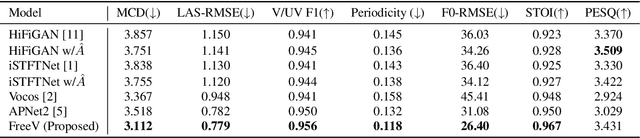
Vocoders reconstruct speech waveforms from acoustic features and play a pivotal role in modern TTS systems. Frequent-domain GAN vocoders like Vocos and APNet2 have recently seen rapid advancements, outperforming time-domain models in inference speed while achieving comparable audio quality. However, these frequency-domain vocoders suffer from large parameter sizes, thus introducing extra memory burden. Inspired by PriorGrad and SpecGrad, we employ pseudo-inverse to estimate the amplitude spectrum as the initialization roughly. This simple initialization significantly mitigates the parameter demand for vocoder. Based on APNet2 and our streamlined Amplitude prediction branch, we propose our FreeV, compared with its counterpart APNet2, our FreeV achieves 1.8 times inference speed improvement with nearly half parameters. Meanwhile, our FreeV outperforms APNet2 in resynthesis quality, marking a step forward in pursuing real-time, high-fidelity speech synthesis. Code and checkpoints is available at: https://github.com/BakerBunker/FreeV