 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Benefit of Activation Sparsity in Pre-training
Oct 04, 2024Pre-trained Transformers inherently possess the characteristic of sparse activation, where only a small fraction of the neurons are activated for each token. While sparse activation has been explored through post-training methods, its potential in pre-training remains untapped. In this work, we first study how activation properties change during pre-training. Our examination reveals that Transformers exhibit sparse activation throughout the majority of the pre-training process while the activation correlation keeps evolving as training progresses. Leveraging this observation, we propose Switchable Sparse-Dense Learning (SSD). SSD adaptively switches between the Mixtures-of-Experts (MoE) based sparse training and the conventional dense training during the pre-training process, leveraging the efficiency of sparse training and avoiding the static activation correlation of sparse training. Compared to dense training, SSD achieves comparable performance with identical model size and reduces pre-training costs. Moreover, the models trained with SSD can be directly used as MoE models for sparse inference and achieve the same performance as dense models with up to $2\times$ faster inference speed. Codes are available at https://github.com/thunlp/moefication.
Configurable Foundation Models: Building LLMs from a Modular Perspective
Sep 04, 2024Advancements in LLMs have recently unveiled challenges tied to computational efficiency and continual scalability due to their requirements of huge parameters, making the applications and evolution of these models on devices with limited computation resources and scenarios requiring various abilities increasingly cumbersome. Inspired by modularity within the human brain, there is a growing tendency to decompose LLMs into numerous functional modules, allowing for inference with part of modules and dynamic assembly of modules to tackle complex tasks, such as mixture-of-experts. To highlight the inherent efficiency and composability of the modular approach, we coin the term brick to represent each functional module, designating the modularized structure as configurable foundation models. In this paper, we offer a comprehensive overview and investigation of the construction, utilization, and limitation of configurable foundation models. We first formalize modules into emergent bricks - functional neuron partitions that emerge during the pre-training phase, and customized bricks - bricks constructed via additional post-training to improve the capabilities and knowledge of LLMs. Based on diverse functional bricks, we further present four brick-oriented operations: retrieval and routing, merging, updating, and growing. These operations allow for dynamic configuration of LLMs based on instructions to handle complex tasks. To verify our perspective, we conduct an empirical analysis on widely-used LLMs. We find that the FFN layers follow modular patterns with functional specialization of neurons and functional neuron partitions. Finally, we highlight several open issues and directions for future research. Overall, this paper aims to offer a fresh modular perspective on existing LLM research and inspire the future creation of more efficient and scalable foundational models.
Turbo Sparse: Achieving LLM SOTA Performance with Minimal Activated Parameters
Jun 11, 2024Exploiting activation sparsity is a promising approach to significantly accelerating the inference process of large language models (LLMs) without compromising performance. However, activation sparsity is determined by activation functions, and commonly used ones like SwiGLU and GeGLU exhibit limited sparsity. Simply replacing these functions with ReLU fails to achieve sufficient sparsity. Moreover, inadequate training data can further increase the risk of performance degradation. To address these challenges, we propose a novel dReLU function, which is designed to improve LLM activation sparsity, along with a high-quality training data mixture ratio to facilitate effective sparsification. Additionally, we leverage sparse activation patterns within the Feed-Forward Network (FFN) experts of Mixture-of-Experts (MoE) models to further boost efficiency. By applying our neuron sparsification method to the Mistral and Mixtral models, only 2.5 billion and 4.3 billion parameters are activated per inference iteration, respectively, while achieving even more powerful model performance. Evaluation results demonstrate that this sparsity achieves a 2-5x decoding speedup. Remarkably, on mobile phones, our TurboSparse-Mixtral-47B achieves an inference speed of 11 tokens per second. Our models are available at \url{https://huggingface.co/PowerInfer}
Robust and Scalable Model Editing for Large Language Models
Mar 26, 2024Large language models (LLMs) can make predictions using parametric knowledge--knowledge encoded in the model weights--or contextual knowledge--knowledge presented in the context. In many scenarios, a desirable behavior is that LLMs give precedence to contextual knowledge when it conflicts with the parametric knowledge, and fall back to using their parametric knowledge when the context is irrelevant. This enables updating and correcting the model's knowledge by in-context editing instead of retraining. Previous works have shown that LLMs are inclined to ignore contextual knowledge and fail to reliably fall back to parametric knowledge when presented with irrelevant context. In this work, we discover that, with proper prompting methods, instruction-finetuned LLMs can be highly controllable by contextual knowledge and robust to irrelevant context. Utilizing this feature, we propose EREN (Edit models by REading Notes) to improve the scalability and robustness of LLM editing. To better evaluate the robustness of model editors, we collect a new dataset, that contains irrelevant questions that are more challenging than the ones in existing datasets. Empirical results show that our method outperforms current state-of-the-art methods by a large margin. Unlike existing techniques, it can integrate knowledge from multiple edits, and correctly respond to syntactically similar but semantically unrelated inputs (and vice versa). The source code can be found at https://github.com/thunlp/EREN.
ProSparse: Introducing and Enhancing Intrinsic Activation Sparsity within Large Language Models
Feb 27, 2024Activation sparsity refers to the existence of considerable weakly-contributed elements among activation outputs. As a prevalent property of the models using the ReLU activation function, it has been proven a promising paradigm to boost model inference efficiency. Nevertheless, most large language models (LLMs) adopt activation functions without intrinsic activation sparsity (e.g., GELU and Swish). Some recent efforts have explored introducing ReLU or its variants as the substitutive activation function to help LLMs achieve activation sparsity and inference acceleration, but few can simultaneously obtain high sparsity and comparable model performance. This paper introduces an effective sparsification method named "ProSparse" to push LLMs for higher activation sparsity without decreasing model performance. Specifically, after substituting the activation function of LLMs with ReLU, ProSparse adopts progressive sparsity regularization with a factor smoothly increasing along sine curves in multiple stages. This can enhance activation sparsity and alleviate performance degradation by avoiding radical shifts in activation distribution. With ProSparse, we obtain high sparsity of 89.32% and 88.80% for LLaMA2-7B and LLaMA2-13B, respectively, achieving comparable performance to their original Swish-activated versions. Our inference acceleration experiments further demonstrate the practical acceleration brought by higher activation sparsity.
InfLLM: Unveiling the Intrinsic Capacity of LLMs for Understanding Extremely Long Sequences with Training-Free Memory
Feb 07, 2024Large language models (LLMs) have emerged as a cornerstone in real-world applications with lengthy streaming inputs, such as LLM-driven agents. However, existing LLMs, pre-trained on sequences with restricted maximum length, cannot generalize to longer sequences due to the out-of-domain and distraction issues. To alleviate these issues, existing efforts employ sliding attention windows and discard distant tokens to achieve the processing of extremely long sequences. Unfortunately, these approaches inevitably fail to capture long-distance dependencies within sequences to deeply understand semantics. This paper introduces a training-free memory-based method, InfLLM, to unveil the intrinsic ability of LLMs to process streaming long sequences. Specifically, InfLLM stores distant contexts into additional memory units and employs an efficient mechanism to lookup token-relevant units for attention computation. Thereby, InfLLM allows LLMs to efficiently process long sequences while maintaining the ability to capture long-distance dependencies. Without any training, InfLLM enables LLMs pre-trained on sequences of a few thousand tokens to achieve superior performance than competitive baselines continually training these LLMs on long sequences. Even when the sequence length is scaled to $1,024$K, InfLLM still effectively captures long-distance dependencies.
ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs
Feb 06, 2024Sparse computation offers a compelling solution for the inference of Large Language Models (LLMs) in low-resource scenarios by dynamically skipping the computation of inactive neurons. While traditional approaches focus on ReLU-based LLMs, leveraging zeros in activation values, we broaden the scope of sparse LLMs beyond zero activation values. We introduce a general method that defines neuron activation through neuron output magnitudes and a tailored magnitude threshold, demonstrating that non-ReLU LLMs also exhibit sparse activation. To find the most efficient activation function for sparse computation, we propose a systematic framework to examine the sparsity of LLMs from three aspects: the trade-off between sparsity and performance, the predictivity of sparsity, and the hardware affinity. We conduct thorough experiments on LLMs utilizing different activation functions, including ReLU, SwiGLU, ReGLU, and ReLU$^2$. The results indicate that models employing ReLU$^2$ excel across all three evaluation aspects, highlighting its potential as an efficient activation function for sparse LLMs. We will release the code to facilitate future research.
Variator: Accelerating Pre-trained Models with Plug-and-Play Compression Modules
Oct 24, 2023Pre-trained language models (PLMs) have achieved remarkable results on NLP tasks but at the expense of huge parameter sizes and the consequent computational costs. In this paper, we propose Variator, a parameter-efficient acceleration method that enhances computational efficiency through plug-and-play compression plugins. Compression plugins are designed to reduce the sequence length via compressing multiple hidden vectors into one and trained with original PLMs frozen. Different from traditional model acceleration methods, which compress PLMs to smaller sizes, Variator offers two distinct advantages: (1) In real-world applications, the plug-and-play nature of our compression plugins enables dynamic selection of different compression plugins with varying acceleration ratios based on the current workload. (2) The compression plugin comprises a few compact neural network layers with minimal parameters, significantly saving storage and memory overhead, particularly in scenarios with a growing number of tasks. We validate the effectiveness of Variator on seven datasets. Experimental results show that Variator can save 53% computational costs using only 0.9% additional parameters with a performance drop of less than 2%. Moreover, when the model scales to billions of parameters, Variator matches the strong performance of uncompressed PLMs.
CPET: Effective Parameter-Efficient Tuning for Compressed Large Language Models
Jul 15, 2023Parameter-efficient tuning (PET) has been widely explored in recent years because it tunes much fewer parameters (PET modules) than full-parameter fine-tuning (FT) while still stimulating sufficient knowledge from large language models (LLMs) for downstream tasks. Moreover, when PET is employed to serve multiple tasks, different task-specific PET modules can be built on a frozen LLM, avoiding redundant LLM deployments. Although PET significantly reduces the cost of tuning and deploying LLMs, its inference still suffers from the computational bottleneck of LLMs. To address the above issue, we propose an effective PET framework based on compressed LLMs, named "CPET". In CPET, we evaluate the impact of mainstream LLM compression techniques on PET performance and then introduce knowledge inheritance and recovery strategies to restore the knowledge loss caused by these compression techniques. Our experimental results demonstrate that, owing to the restoring strategies of CPET, collaborating task-specific PET modules with a compressed LLM can achieve comparable performance to collaborating PET modules with the original version of the compressed LLM and outperform directly applying vanilla PET methods to the compressed LLM.
Plug-and-Play Knowledge Injection for Pre-trained Language Models
May 28, 2023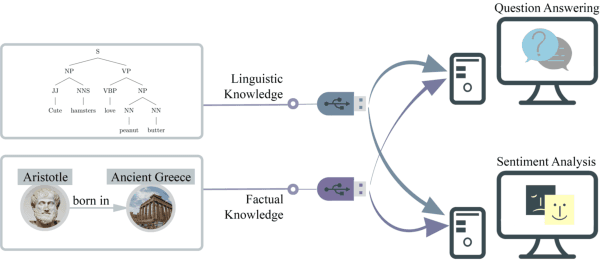
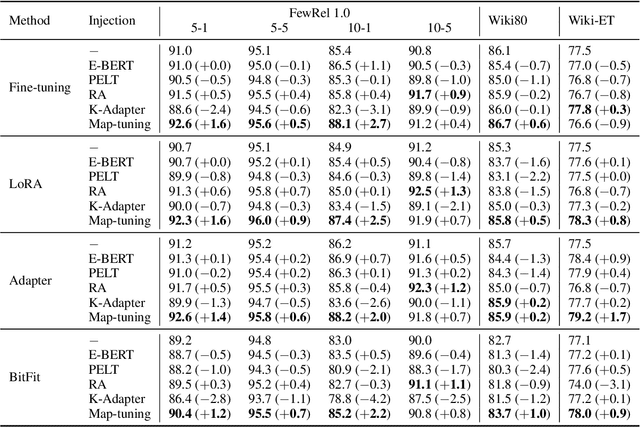
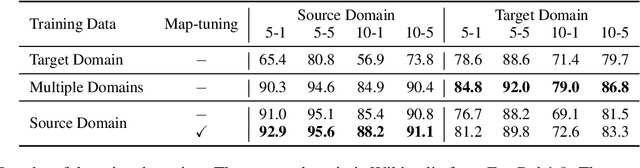
Injecting external knowledge can improve the performance of pre-trained language models (PLMs) on various downstream NLP tasks. However, massive retraining is required to deploy new knowledge injection methods or knowledge bases for downstream tasks. In this work, we are the first to study how to improve the flexibility and efficiency of knowledge injection by reusing existing downstream models. To this end, we explore a new paradigm plug-and-play knowledge injection, where knowledge bases are injected into frozen existing downstream models by a knowledge plugin. Correspondingly, we propose a plug-and-play injection method map-tuning, which trains a mapping of knowledge embeddings to enrich model inputs with mapped embeddings while keeping model parameters frozen. Experimental results on three knowledge-driven NLP tasks show that existing injection methods are not suitable for the new paradigm, while map-tuning effectively improves the performance of downstream models. Moreover, we show that a frozen downstream model can be well adapted to different domains with different mapping networks of domain knowledge. Our code and models are available at https://github.com/THUNLP/Knowledge-Plugin.