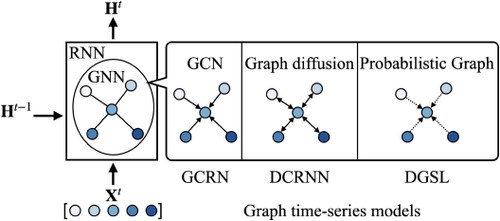
Most related datasets such as traffic data and electricity workload data provide an external graph that primarily describes the geographical connectivity of nodes, however, external graph structures are not always available, and they do not necessarily reflect the actual connections between nodes. In these situations, several models propose using self-derived graphs, i.e., the graph structure is derived either from time-series or from node embeddings. This section describes models from the perspective of graph modeling, specifically, on how different models leverage self-derived graphs to capture the inter-relations between nodes. We discuss three models in this section: FC-GAGA [
62], STFGNN [
47], and RGSL [
91], but other models such as Graph WaveNet and MTGNN, which are discussed in the previous section, also belong to this category. The graph types in different models are summarized in Table
3. At the end of this section, we compare models in terms of their graph modeling.
FC-GAGA [
62], similar to MTGNN, requires no prior knowledge of the graph structure. Note that FC-GAGA uses time-series gates instead of RNN or CNN for time-series modeling. The time-series gates can be seen as a special type of CNN, as they are used to weight time co-variate features. Let
\(\boldsymbol {\mathrm{X}}\in \mathbb {R}^{N \times T}\) denote the node time-series, and let
\(\boldsymbol {\mathrm{H}}_{emb}=f_{EMB}\left(\boldsymbol {\mathrm{X}}\right) \in \mathbb {R}^{N \times d_{emb}}\) denote the node embeddings. FC-GAGA is described by the following equations:
where the graph structure
\(\boldsymbol {\mathrm{A}}\) is learned and optimized from the node embeddings and is used together with transformed time-series data
\(\tilde{\mathbf {x}}_i\) in a gated mechanism to shut off connections of irrelevant node pairs as in Equation (
21), with
\(\epsilon\) as a selected constant hyperparameter. A hidden state
\(\boldsymbol {\mathrm{Z}}\) is constructed from a concatenation of node embedding
\(\boldsymbol {\mathrm{H}}_{emb}\), scaled time-series data
\(\boldsymbol {\mathrm{X}}/ \tilde{\mathbf {x}}\), and the gated states
\(\boldsymbol {\mathrm{G}}\). Subsequently,
\(\boldsymbol {\mathrm{Z}}\) serves as the initial input for a residual module, denoted by
\(f_{res}\), which generates the time-series prediction
\(\hat{\boldsymbol {\mathrm{X}}}\). For the purpose of conciseness, we include the details of the residual module
\(f_{res}\) in Section
B.2. FC-GAGA benefits from the freedom of automatically deriving graph structures, instead of relying on the Markov model-based or distance-based graph topological information. However, the graph construction from node embedding costs a time complexity of
\(\mathcal {O}\left(N^2\right)\), which limits the scalability of FC-GAGA.
STFGNN [
47], unlike many models that only use one graph, integrates three graphs with a fusion layer, where each graph encodes one type of information. STFGNN defines a temporal graph
\(\boldsymbol {\mathrm{A}}_{t}\) that encodes temporal similarity relationships between graph time-series with a
Dynamic Time Warping (DTW) variant (defined in Section
C.3), a spatial graph
\(\boldsymbol {\mathrm{A}}_{s}\) that is derived from the geographical distance between nodes, and a connectivity graph
\(\boldsymbol {\mathrm{A}}_{c}\) that indicates the connections of nodes between two adjacent timesteps. The three matrices are then arranged into a spatial-temporal fusion graph
\(\boldsymbol {\mathrm{A}}\in \mathbb {R}^{KN\times KN}\) with a user-selected slice size
K for hidden state learning.
In distinction to ordinary deep graph models, the graph structure is strongly related to the time-series in graph time-series models. Researchers should be aware of their constraints, some of which are listed as follows: (a) the graph density can limit the computation efficiency. Although many GNN models reduce the time complexity from
\(\mathcal {O} \left(N^2\right)\) to
\(\mathcal {O} \left(|E|\right)\), when the graph is dense (a complete graph in the worst case), the number of edges will be close to the square of the number of nodes, i.e.,
\(\mathcal {O} \left(|E|\right) = \mathcal {O} \left(N^2\right)\), which causes the model to degrade to the worst time complexity. This is a severe limitation for tasks such as time-series forecasting that require a timely response. (b) Moreover, unlike deep learning models whose modeling power generally increases as the depth of the model or the number of layers increases, this does not hold true for deep graph models by simply adding graph neural layers. By stacking many graph neural layers, distant nodes are included and cause the problem of over-smoothing, where the locality information is not well utilized due to message propagation from a large neighborhood set [
55,
56,
81,
99]. Graph time-series models, having a nested GNN within an RNN structure, are more susceptible to over-smoothing when modeling long sequences, due to the occurrence of message propagation at each RNN unfolding step. (c) Another problem is over-squashing, which is due to the excessive neighbor nodes information for each node while the learned output is a fixed-length vector, therefore, the loss of information is unavoidable [
1].
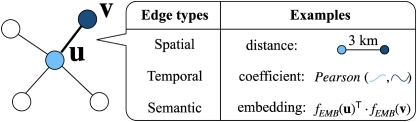
Model Comparison on Graph Components: Graph Construction methods. Many graph time-series datasets contain a pre-defined graph. For example, Wikipedia data have a graph that represents the linking relations between sites [
75]. In biological networks, a graph is provided to represent the links between bio-entities [
19]. However, for other datasets that do not explicitly provide a graph, some metrics are needed to derive one. We describe three ways to derive a graph, namely, the constructions of a spatial graph, a temporal graph, and a semantic graph, respectively. Figure
5 illustrates these graph construction approaches, each accompanied by examples. (a)
Spatial Graphs are built on distance information [
51]. Directly using distance as edge weights of graphs will cause closer nodes to have smaller edge weights, due to the shorter distance between them. However, most GNN models require a closeness graph where greater edge weights represent stronger connections. One common way to convert a distance graph to a closeness graph is through the
radial basis function (RBF) (defined in
C.2). A special case is
Connectivity Graphs, which are binary, i.e., an edge exists and has the edge weight as 1 between two nodes if and only if they are connected. Under the assumption of the first law of geography,
Everything is related to everything else, but near things are more related than distant things, spatial graphs and connectivity graphs are the intuitive choices if they are available in the datasets, as they are used in most models; (b)
Temporal Graphs are constructed based on the temporal similarity between node time-series [
57]. By formatting each node time-series as a sequence, many sequence similarity metrics can be used to derive a temporal graph, including cosine similarity, coefficient metrics, and
Dynamic Time Warping (DTW), among many others. In the aforementioned GRCNN models, for instance, STFGNN [
47] uses DTW to derive temporal graphs. Temporal graphs are useful if connections and mutual impacts between nodes are highly correlated to their time-series patterns. Besides, temporal graphs go beyond the first law of geography, as they may connect two highly correlated node time-series that may be geographically distant; (c)
Semantic Graphs are constructed based on the node embeddings to connect nodes that are semantically close to each other, that these nodes share some similar hidden features between them [
62]. In semantic graphs, spatially distant nodes may share similar features and are closely connected [
47]. The level of similarity can be measured by some embedding similarity metric, such as the correlation coefficient. Additionally, the edge embeddings can be used as parameters of distribution functions, from which the edge weights are sampled [
70]. It is also possible to integrate more than one semantic type of graph [
47,
57]. Semantic graphs have the advantage that they do not rely on external graph structures or time-series patterns. In practice, a combination of various types of graphs is widely used, through cascade processing [
62], fusion [
47], or using one graph as a mask for another graph [
79].