Graph Time-series Modeling in Deep Learning: A Survey
 Hoda EldardiryAuthors Info & Claims
Hoda EldardiryAuthors Info & ClaimsAbstract
1 Introduction
2 Related Survey Papers

3 Time-series and Graphs in Deep Learning: Individual Modeling
3.1 Time-series Encoding in Deep Learning
3.2 Graph Modeling in Deep Learning
3.2.1 Node Embedding.
3.2.2 Representative Graph Neural Networks.
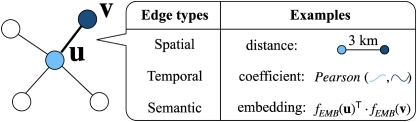
4 Preliminaries and Definitions
| Notations | Descriptions | Notations | Descriptions | Notations | Descriptions |
|---|---|---|---|---|---|
| X | a tensor | c | number of channels | \(\boldsymbol {\mathrm{D}}\) | degree matrix |
| \(\boldsymbol {\mathrm{X}}, \boldsymbol {\mathrm{W}}\) | matrices | d | number of features or variates | \(\boldsymbol {\mathrm{L}}\) | Laplacian matrix |
| \(\mathbf {\theta }, \mathbf {a}, \mathbf {b}\) | parameter vectors | \(\alpha\) | attention scores | l | number of layers |
| \(\theta , \psi\) | parameter scalar values | \(\mathcal {G}\) | a series of graphs | \(\Vert\) | concatenation operator |
| T | length of time-series | \(G=(V, E)\) | a graph, its node set and edge set | \(|\cdot |\) | cardinality operator |
| w | lookback window size | \(N =|V|\) | number of nodes | \(\odot\) | Hadamard product |
| \(\tau\) | future horizon | \(\Gamma (v)\) | neighbor node set of v | \(f_{FC}, f_{EMB}, f_{CONV}\) | neural network functions |
| \(\mathbf {h}, \boldsymbol {\mathrm{H}}\) | hidden states | \(\boldsymbol {\mathrm{A}}\) | adjacency matrix | \(f_{LSTM}, f_{GRU}, g\) | neural network modules |
4.1 Fundamental Computations in Neural Networks
4.2 Problem Definitions
5 Deep Graph Time-series Modeling
| Years | Graph Recurrent/Convolutional Neural Networks | Graph Attention Neural Networks |
|---|---|---|
| 2018 or before | GCRN [69], DCRNN [51], STGCN [90] | GaAN [92] |
| 2019 | Graph WaveNet [83], T-GCN [100], LRGCN [46] | ASTGCN [26] |
| 2020 | MTGNN [82], DGSL [70] | MTAD-GAT [98], STAG-GCN [57] |
| STGNN [79], Cola-GNN [19], ST-GRAT [66] | ||
| 2021 | FC-GAGA [62], Radflow [75] | GDN [18], StemGNN [8] |
| STFGNN [47], Z-GCNET [12], TStream [11] | ||
| 2022 | VGCRN [10], GRIN [13], RGSL [91], GANF [16] | GReLeN [95], FuSAGNet [29], THGNN [85] |
| ESG [88] |
5.1 Graph Recurrent/Convolutional Neural Networks
| Categories | Models | Time-series | Propagation | Graph Types | Evolving Graphs | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| RNN | CNN | Gates | GCN | Diffusion | Gates | Spatial | Temporal | Semantic | |||
| RNN-based Graph Time-series Modeling (Section 5.1.1) | GCRN [69] | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | |||||||
| DCRNN [51] | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | ||||||||
| T-GCN [100] | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | ||||||||
| DGSL [70] | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | ||||||||
| VGCRN [10] | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | ||||||||
| GANF [16] | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | ||||||||
| GRIN [13] | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | ||||||||
| CNN-based Graph Time-series Modeling (Section 5.1.2) | STGCN [90] | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | |||||||
| G-WaveNet [83] | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | |||||||
| MTGNN [82] | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | ||||||||
| Models with Self-derived Graphs (Section 5.1.3) | FC-GAGA [62] | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | ||||||
| STFGNN [47] | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | |||||||
| RGSL [91] | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | |||||||
| Models with Evolving Graphs (Section 5.1.4) | Radflow [75] | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | |||||||
| TStream [11] | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | |||||||
| LRGCN [46] | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | |||||||
| Z-GCNET [12] | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | |||||||
| ESG [88] | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | |||||
5.1.1 RNN-based Time-series Modeling.

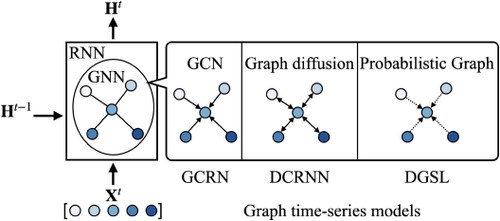
5.1.2 CNN-based Time-series Modeling.

5.1.3 Models with Self-derived Graphs.
5.1.4 Models with Evolving Graphs.
5.2 Graph Attention Neural Networks
| Categories | Models | Attention types | Tasks | ||||
|---|---|---|---|---|---|---|---|
| Spatial/Graph | Temporal | General | Classification | Regression | Anomaly Detection | ||
| Attention for Forecasting (Section 5.2.1) | GaAN [92] | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | |||
| Cola-GNN [19] | \(\checkmark\) | \(\checkmark\) | |||||
| ASTGCN [26] | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | ||||
| STAG-GCN [57] | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | |||
| STGNN [79] | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | ||||
| StemGNN [8] | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | ||||
| Radflow [75] | \(\checkmark\) | \(\checkmark\) | |||||
| ST-GRAT [66] | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | |||
| THGNN [85] | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | ||||
| Attention for Anomaly Detection (Section 5.2.2) | MTAD-GAT [98] | \(\checkmark\) | \(\checkmark\) | ||||
| GDN [18] | \(\checkmark\) | \(\checkmark\) | |||||
| GReLeN [95] | \(\checkmark\) | \(\checkmark\) | |||||
| FuSAGNet [29] | \(\checkmark\) | \(\checkmark\) | |||||
5.2.1 Attention for Forecasting.
5.2.2 Attention for Anomaly Detection.

6 Representational Components
6.1 Gated Mechanisms
6.2 Skip Connections
6.3 Model Interpretability
7 Applications and Datasets
7.1 Regression Model Performance Comparison on Traffic Forecasting
| Data | Models | 3 step ahead | 6 steps ahead | 12 steps ahead | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MAE | RMSE | MAPE | MAE | RMSE | MAPE | MAE | RMSE | MAPE | ||
| METR-LA | STGCN [90] | 2.88 | 5.74 | \(7.6\%\) | 3.47 | 7.24 | \(9.6\%\) | 4.59 | 9.40 | \(12.7\%\) |
| DCRNN [51] | 2.77 | 5.38 | \(7.3\%\) | 3.15 | 6.45 | \(8.8\%\) | 3.60 | 7.59 | \(10.5\%\) | |
| FC-GAGA [62] | 2.75 | 5.34 | \(7.3\%\) | 3.10 | 6.30 | \(8.6\%\) | 3.51 | 7.31 | \(10.1\%\) | |
| GaAN [92] | 2.71 | 5.25 | \(7.0\%\) | 3.12 | 6.36 | \(8.6\%\) | 3.64 | 7.65 | \(10.6\%\) | |
| Graph WaveNet [83] | 2.69 | 5.15 | \(6.9\%\) | 3.07 | 6.22 | \(8.4\%\) | 3.53 | 7.37 | \(10.0\%\) | |
| MTGNN [82] | 2.69 | 5.18 | \(6.9\%\) | 3.05 | 6.17 | \(8.2\%\) | 3.49 | 7.23 | \(9.9\%\) | |
| ST-GRAT [66] | 2.60 | 5.07 | \(6.6\%\) | 3.01 | 6.21 | \(8.2\%\) | 3.49 | 7.42 | \(10.0\%\) | |
| StemGNN [8] | \({2.56}\) | 5.06 | \({6.5\%}\) | 3.01 | 6.03 | \(8.2\%\) | \({3.43}\) | 7.23 | \({9.6\%}\) | |
| STGNN [79] | 2.62 | \({4.99}\) | \(6.6\%\) | \({2.98}\) | \({5.88}\) | \({7.8\%}\) | 3.49 | \({6.94}\) | \(9.7\%\) | |
| (best) DGSL [70] | \(\mathbf {2.39}\) | \(\mathbf {4.41}\) | \(\mathbf {6.0\%}\) | \(\mathbf {2.65}\) | \(\mathbf {5.06}\) | \(\mathbf {7.0\%}\) | \(\mathbf {2.99}\) | \(\mathbf {5.85}\) | \(\mathbf { 8.3\%}\) | |
| PEMS-BAY | DCRNN [51] | 1.38 | 2.95 | \(2.9\%\) | 1.74 | 3.97 | \(3.9\%\) | 2.07 | 4.74 | \(4.9\%\) |
| STGCN [90] | 1.36 | 2.96 | \(2.9\%\) | 1.81 | 4.27 | \(4.2\%\) | 2.49 | 5.69 | \(5.8\%\) | |
| FC-GAGA [62] | 1.36 | 2.86 | \(2.9\%\) | 1.68 | 3.80 | \(3.8\%\) | 1.97 | 4.52 | \(4.7\%\) | |
| MTGNN [82] | 1.32 | 2.79 | \(2.8\%\) | 1.65 | 3.74 | \(3.7\%\) | 1.94 | 4.49 | \(4.5\%\) | |
| Graph WaveNet [83] | 1.30 | 2.74 | \({2.7\%}\) | 1.63 | 3.70 | \(3.7\%\) | 1.95 | 4.52 | \(4.6\%\) | |
| ST-GRAT [66] | \({1.29}\) | 2.71 | \({2.7\%}\) | \({1.61}\) | 3.69 | \({3.6\%}\) | 1.95 | 4.54 | \(4.6\%\) | |
| DGSL [70] | 1.32 | \({2.62}\) | \(2.8\%\) | 1.64 | \({3.41}\) | \({3.6\%}\) | \({1.91}\) | \(\mathbf {3.97}\) | \({4.4\%}\) | |
| (best) STGNN [79] | \(\mathbf {1.17}\) | \(\mathbf {2.43}\) | \(\mathbf {2.3\%}\) | \(\mathbf {1.46}\) | \(\mathbf {3.27}\) | \(\mathbf {3.1\%}\) | \(\mathbf {1.83}\) | \({4.20}\) | \(\mathbf {4.2\%}\) | |
7.2 Anomaly Detection Model Performance Comparison on Water Treatment
| Data | Models | Precision | Recall | F1 |
|---|---|---|---|---|
| SWAT | MTAD-GAT [98] | 21.0 | 64.5 | 31.7 |
| GDN [18] | \(\mathbf {99.4}\) | 68.1 | 80.8 | |
| FuSAGNet [29] | \({98.8}\) | \({72.6}\) | \({83.7}\) | |
| GReLeN [95] | 95.6 | \(\mathbf {83.5}\) | \(\mathbf {89.1}\) | |
| WADI | MTAD-GAT [98] | 11.7 | 30.6 | 17.0 |
| GDN [18] | \(\mathbf {97.5}\) | 40.2 | 57.0 | |
| FuSAGNet [29] | \({83.0}\) | \({47.9}\) | \({60.7}\) | |
| GReLeN [95] | 77.3 | \(\mathbf {61.3}\) | \(\mathbf {68.2}\) |
7.3 Data Challenges
7.3.1 Irregular Time-series.
7.3.2 Irregular Graph Structures.
7.4 Other Applications and Datasets
8 Future Directions
9 Conclusion
A Neural Network Functions
B Graph Time-series Models in Detail
B.1 GCRN
B.2 FC-GAGA
B.3 Radflow
C Experimental Setup
C.1 Data Preprocessing
C.2 Distance-based Graph Construction
C.3 Time-series Similarity/Coefficient Metrics
C.4 Loss Functions and Metrics
C.5 Other Functions
D Public Resources: Code and Data

References
Index Terms
- Graph Time-series Modeling in Deep Learning: A Survey
Recommendations
Evolving Super Graph Neural Networks for Large-Scale Time-Series Forecasting
Advances in Knowledge Discovery and Data MiningAbstractGraph Recurrent Neural Networks (GRNN) excel in time-series prediction by modeling complicated non-linear relationships among time-series. However, most GRNN models target small datasets that only have tens of time-series or hundreds of time-...
The Evolution of Distributed Systems for Graph Neural Networks and Their Origin in Graph Processing and Deep Learning: A Survey
Graph neural networks (GNNs) are an emerging research field. This specialized deep neural network architecture is capable of processing graph structured data and bridges the gap between graph processing and deep learning. As graphs are everywhere, GNNs ...
Generating a Graph Colouring Heuristic with Deep Q-Learning and Graph Neural Networks
Learning and Intelligent OptimizationAbstractThe graph colouring problem consists of assigning labels, or colours, to the vertices of a graph such that no two adjacent vertices share the same colour. In this work we investigate whether deep reinforcement learning can be used to discover a ...
Comments
Information & Contributors
Information
Published In

Publisher
Association for Computing Machinery
New York, NY, United States
Publication History
Check for updates
Author Tags
Qualifiers
- Tutorial
Contributors

Other Metrics
Bibliometrics & Citations
Bibliometrics
Article Metrics
- 0Total Citations
- 2,383Total Downloads
- Downloads (Last 12 months)2,383
- Downloads (Last 6 weeks)763
Other Metrics
Citations
View Options
Get Access
Login options
Check if you have access through your login credentials or your institution to get full access on this article.
Sign in