3.2. Data Preprocessing
In the analysis of industrial multivariate time series, due to significant variations in numerical values across different variables, this study utilizes the Min–Max normalization method to alleviate the adverse effects stemming from large numerical differences among variables in time series data. Normalization is applied to each dimension of the time series data using the following formula:
where
and
represent the maximum and minimum values, respectively, on the
-th dimension in the training set. The symbol
denotes a small constant vector used to prevent division by zero. Since time series exhibit temporal correlations, i.e., there is temporal dependence between different time points, this study takes into account the dependency relationship between the current time point and historical time points. A fixed-length input is created using a sliding window of length
, denoted as
. For model training, instead of directly using
as the model input, the multivariate time series
is segmented into sliding windows
to serve as the model input. This approach enables the model to assess the anomaly of the time observation
by considering not only
itself but also the historical temporal dependencies associated with
.
3.3. Proposed Model
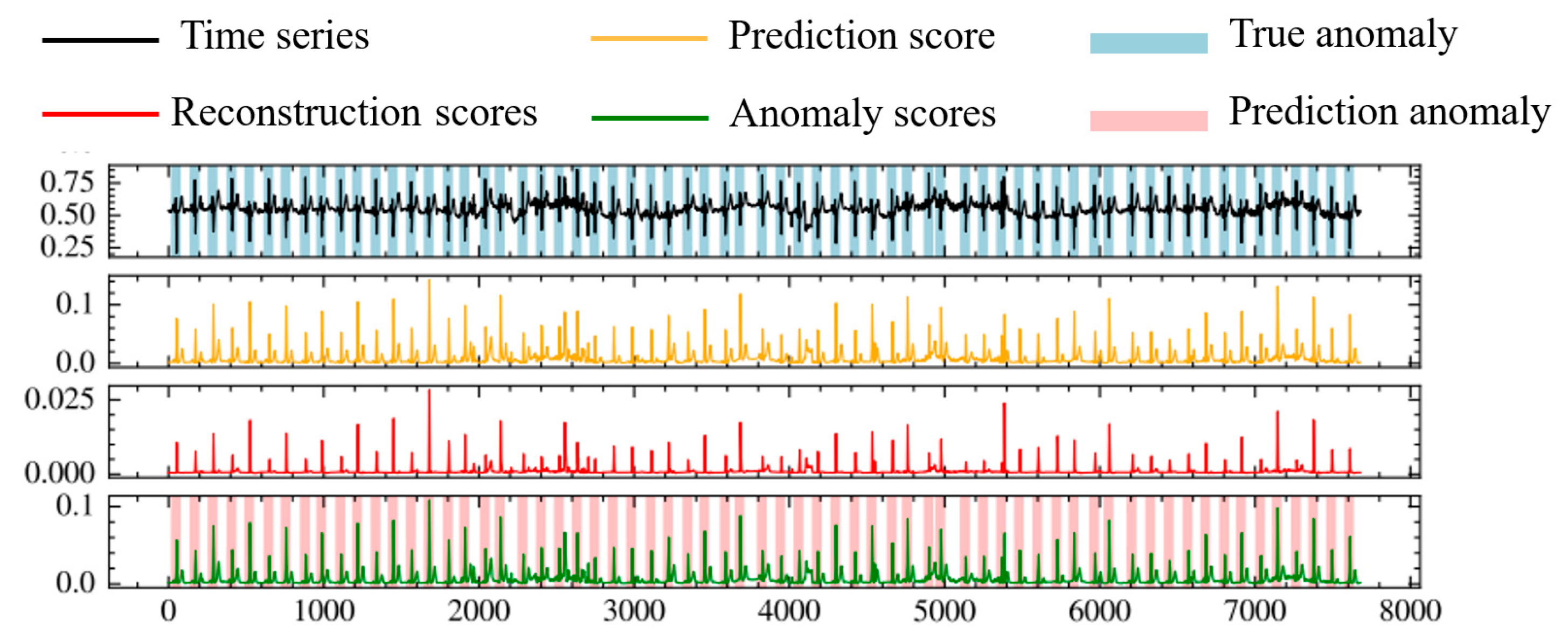
The model proposed in this paper mainly consists of two subnetworks. The first subnetwork is the characterization network, responsible for extracting low-dimensional spatial features from multivariate time-series data and calculating reconstruction errors. The second subnetwork is the prediction network, designed to capture time-dependent relationships. The characterization network encodes spatial information from multivariate time-series data into a low-dimensional representation. The incorporation of multi-head attention aims to focus on crucial information in the low-dimensional feature space. Subsequently, the characterization network calculates reconstruction errors. These reconstruction errors are then provided to the prediction network, which is based on an attention mechanism. The prediction network captures the temporal dependencies of the reconstruction errors from the characterization network and utilizes external attention to focus on important temporal information. Finally, both the characterization network and the prediction network undergo end-to-end training. For normal data, the reconstruction values generated by encoding the data are like the original input sequence, and the predicted values are like the future values of the time series. In contrast, for anomalous data, there is a significant deviation in both reconstruction and prediction values. Therefore, during the inference process, anomalies are precisely detected by calculating the anomaly score in the composite model.
We use the POT algorithm [
29] to automatically calculate the anomaly threshold. When the anomaly score exceeds the threshold, we identify it as an anomalous event; otherwise, we consider it as a non-anomalous event.
Figure 1 illustrates the proposed network architecture. In the figure,
represents the output of the characterization network, and
denotes the reconstruction error of the characterization network, computed as the square difference between the original input data
and
.
signifies the extracted low-dimensional key feature information
combined with the downsampled features of
.
represents the prediction error of the prediction network, calculated by subtracting
from
.
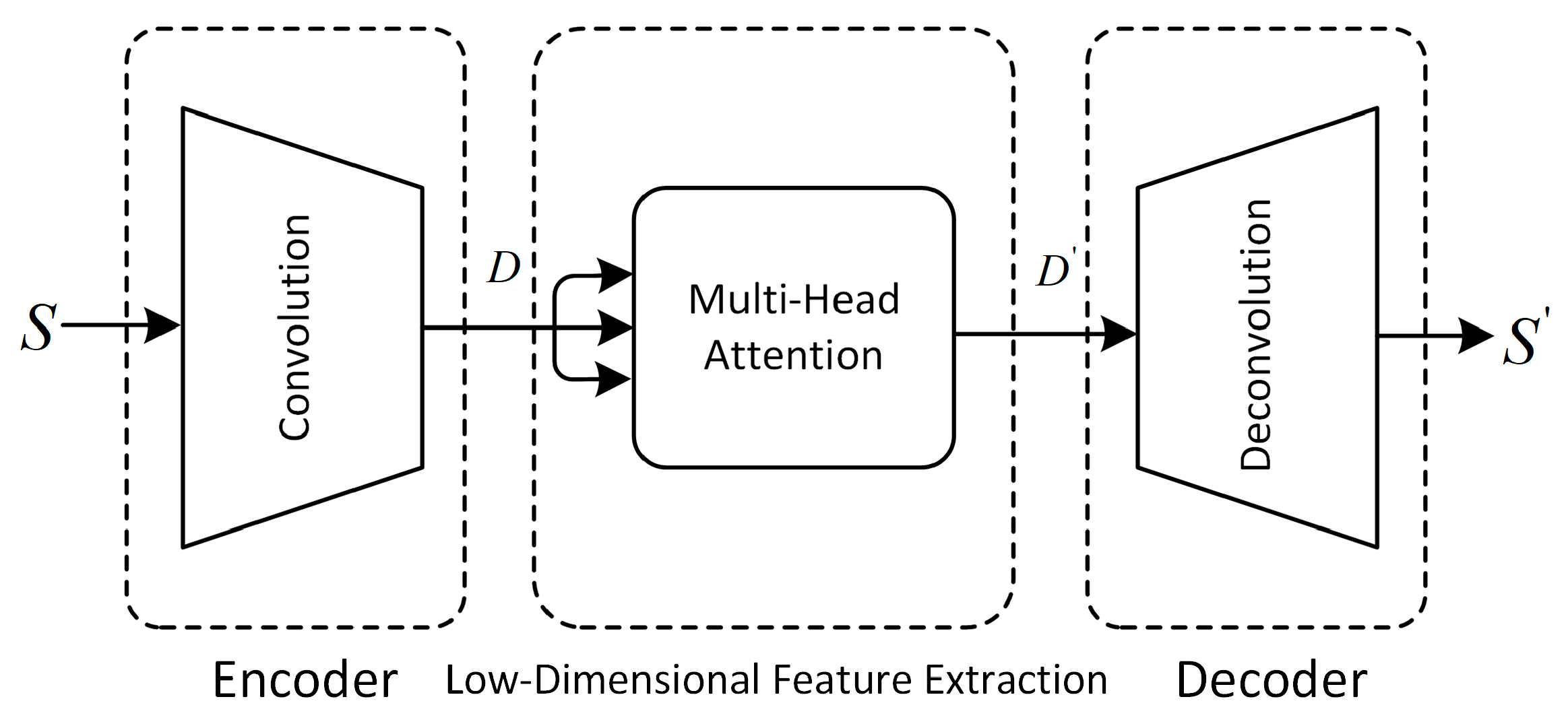
3.4. Characterization Network
To better learn the spatial features of multivariate time-series data, we adopt a convolutional autoencoder structure suitable for handling anomaly detection in multivariate time-series data [
30]. This structure integrates CNN into the AutoEncode framework, where the convolutional kernel slides in the time dimension, extracting features at different time steps. By stacking multiple convolutional layers, higher-level time-series features are gradually extracted, learning the features and patterns of multivariate time-series data. The AutoEncode structure, through backpropagation and optimization methods like gradient descent, uses the input data itself as supervision to guide the neural network in attempting to learn a mapping relationship, resulting in a reconstructed output, achieving unsupervised training. The characterization network consists of three main parts: encoder, low-dimensional feature extraction, and decoder. The structure of the characterization network is illustrated in
Figure 2.
The encoding process from the input layer to the hidden layer for the raw data
:
The process of extracting low-dimensional features:
The decoding process from the hidden layer to the output layer:
The role of the encoder is to encode the high-dimensional input into a low-dimensional latent variable , enabling the neural network to learn the most informative features. The encoder achieves this by mapping the input to the hidden representation through two one-dimensional convolutional layers and one dropout layer. The addition of the dropout layer aims to enhance the network’s robustness, contributing to improved performance on noisy or highly variable data. The stride of each convolutional layer is set to 2, reducing the dimension of features and generating smaller-sized output feature maps based on the size of the convolutional kernel.
The intermediate hidden layer features encoded by the encoder, which represent the low-dimensional spatial feature information
, play a crucial role in identifying anomalies. Methods like CAE-M and DAGMM emphasize the significance of these features. To focus on the crucial information in the low-dimensional spatial features
, we introduce multi-head attention [
30] into the low-dimensional space. Multi-head attention is capable of learning relationships between different low-dimensional features, combining various features to enhance the representation of the low-dimensional space, and capturing diverse dependencies within the low-dimensional space.
The calculation for each attention head
in multi-head attention, given query
, key
, and value
, is as follows:
,
, and
are learnable parameters.
represents the attention pooling function. The output of multi-head attention undergoes a linear transformation by concatenating multiple heads together and can be expressed as
where
is a learnable parameter. Based on this design, each head can focus on different parts of the low-dimensional features. Through this multi-head attention mechanism, the model can capture the intrinsic relationships within the low-dimensional spatial features. We have demonstrated the effectiveness of this approach through ablation experiments.
The role of the decoder is to map the crucial information from the low-dimensional spatial features through reconstruction back to the original input space. Decoding involves transforming from a narrow representation to a wide reconstruction matrix, accomplished using transpose convolutional layers to increase width and height. The working principle of these layers is almost identical to convolutional layers but in reverse. We use the Rectified Linear Unit (ReLU) as the activation function for the convolutional layers.
During model training, only normal data are provided as training data, enabling the model to learn to reconstruct normal input data as accurately as possible. The ideal scenario is that the decoder’s output
can perfectly or approximately recover the original input
. The reconstructed values
, having the same structure as
, represent the reconstruction. The square of the difference between the original input data and their reconstruction is defined as the reconstruction error
. In this context, we utilize the Mean Squared Error (MSE) to measure the proximity between the original input and its reconstruction, as described by the following equation:
3.5. Prediction Network
To simultaneously capture the temporal and spatial dependencies of multivariate time series data, our proposed model characterizes the complex spatiotemporal patterns of multivariate time series data through both reconstruction analysis and prediction analysis. We use the reconstruction error of the characterization network as the original input for the prediction network. A prediction network with a large reconstruction error will be more challenging to predict, resulting in a larger prediction error, while a prediction network with a smaller reconstruction error will be easier to predict, leading to a smaller prediction error.
The reconstruction error
is first fed into a one-dimensional convolutional layer with a stride of 4 and a kernel size of 1. The convolution operation downsamples the input sequence, reducing the number of time steps to one-fourth of the original. This helps reduce the computational cost of the model, improving training and inference efficiency. Using a kernel size of 1 in the convolutional layer is equivalent to performing independent linear transformations on the features of each time step. This aids the model in extracting and learning specific features for each time step without introducing a local perception field. Additionally, it allows for the reduction in the number of channels in the output of the convolutional layer while preserving input features. This helps compress the input data, making the model’s representation more compact and enhancing its ability to abstract input features. By aligning feature sizes, we merge the downsampled reconstruction loss with the low-dimensional feature information
extracted by the characterization network to obtain
. The purpose of this fusion is to introduce the low-dimensional feature representation learned by the characterization network into the features encoded after the reconstruction error. This fusion enables the network to comprehensively consider the information of the reconstruction loss and effectively handle it in the prediction network. In this way, a balance is achieved between the reconstruction error and the features learned by the characterization network to improve the overall performance and generalization ability of the entire network. Finally,
is upsampled to the original size to obtain the input
of the prediction function through a similar transpose convolution, as shown in the following equation:
Prediction functions come in various types, such as the Recurrent Neural Network (RNN), Long Short-Term Memory (LSTM), and Gated Recurrent Unit (GRU) [
31]. The original RNN struggles to learn long-term dependencies. In this work, we employ LSTM, a type of Recurrent Neural Network introduced by Hochreiter and Schmidhuber in 1997 [
32]. Unlike conventional feedforward neural networks, LSTM networks can analyze input sequences over time. LSTM proves effective in transmitting and expressing information in long-time sequences, addressing the common issue of long-term dependencies being overlooked or forgotten in general recurrent neural networks. Additionally, LSTM resolves the problem of vanishing/exploding gradients present in RNNs. It employs a specialized architecture that integrates “gates” into the structure, consisting of four main components: forget gate
, input gate
, output gate
, and a memory cell
.
represents the input at the
-th time step in
. The computation process for the hidden state
is as follows:
Here, represents the horizontal concatenation of the hidden state ; the input , and , respectively, represent the sigmoid and tanh activation functions; denotes weights; stands for the gate neuron; is the bias of the gate; and is the output of the previous LSTM cell. The LSTM forget gate, memory gate, and output gate control the information preservation and transmission in the LSTM, ultimately reflecting in the cell state and output signal . The key to LSTM is the cell state, which is like a conveyor belt running through the entire chain. The LSTM cell state allows the unit state to forget and replace values; then, it decides which values to output and sends them to the next unit. It controls the information passed to the next time step during the computation of the hidden state. It can consider global and local time information when calculating the hidden state.
To better handle time series data, we also introduce an attention mechanism, allowing the model to focus more on important information. Self-attention mechanisms [
33] are widely used in computer vision [
34], natural language processing [
35], and other tasks due to their ability to capture long-term dependencies. However, self-attention mechanisms have a significant drawback: they require a considerable amount of computation, leading to some computational redundancy. Moreover, self-attention mechanisms only utilize information within their samples, neglecting potential connections between different samples.
To extract long-term dependencies in time series data and the potential connections between samples while reducing computational costs, we employ an external attention mechanism [
36] using a small, learnable, and shared memory. External attention only uses two linear layers and normalization layers, possessing linear complexity and implicitly considering relationships between different feature maps.
External attention is achieved by introducing two external memory units, implicitly learning features of the entire dataset. It computes attention between the input and external memory units. The memory unit is represented as
, where
and
are hyperparameters. It can be expressed as
where
represents the output of the LSTM at each time step in the input sequence and
represents the similarity between the
-th element and the
-th row of
. The memory unit is a parameter independent of the input, serving as the memory for the entire training dataset.
In the output layer, the prediction error
is obtained by calculating the difference between the output
of the prediction network and the true value
. The loss function of the prediction network can be expressed as



 and
and 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







