
Financial Time Series Forecasting with the Deep Learning Ensemble Model


Abstract
:1. Introduction
2. Literature Review
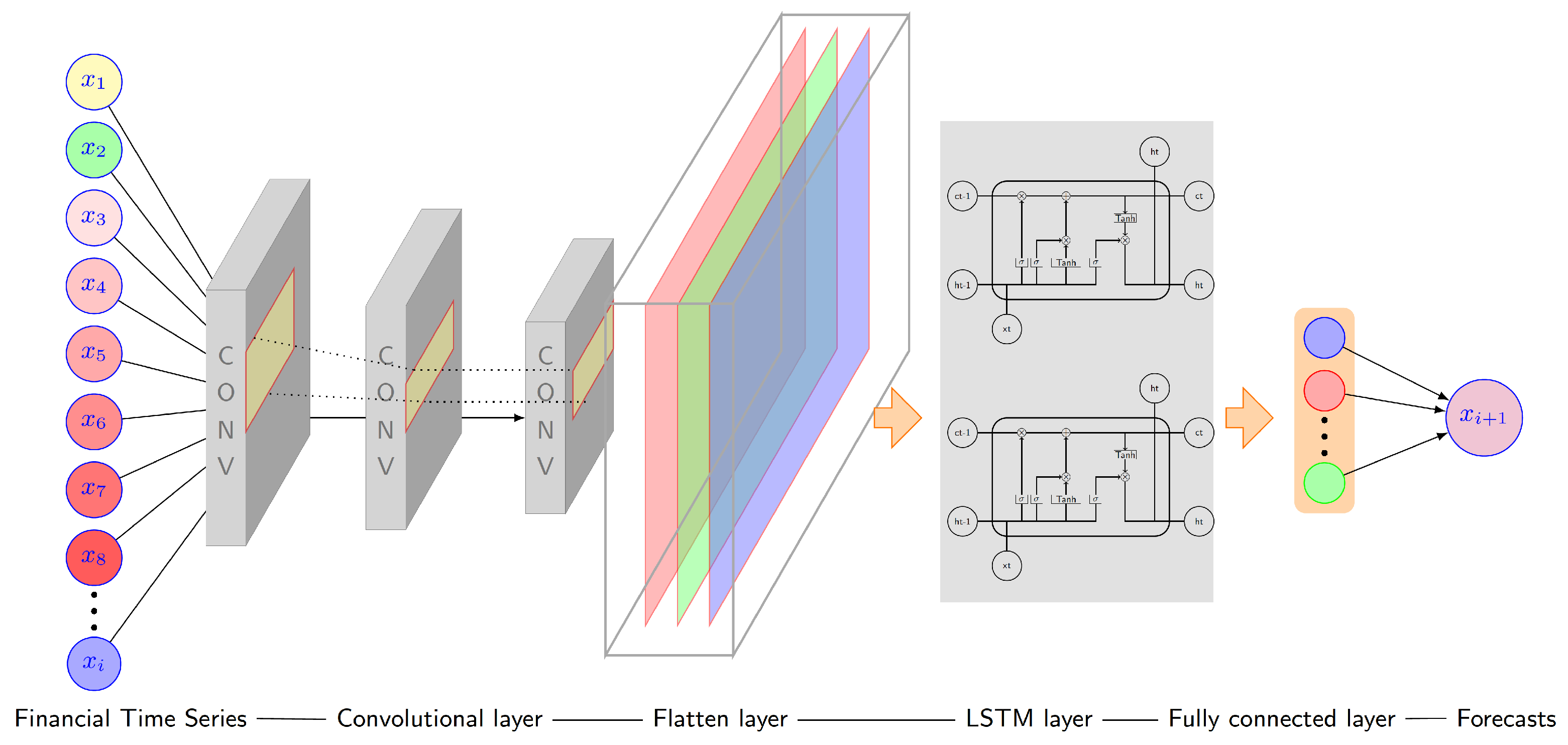
3. The ARMA-CNNLSTM Ensemble Forecasting Model
3.1. Ensemble Forecasting Model
3.2. Individual Ensemble Models
4. Empirical Studies
4.1. Data Description and Statistical Tests
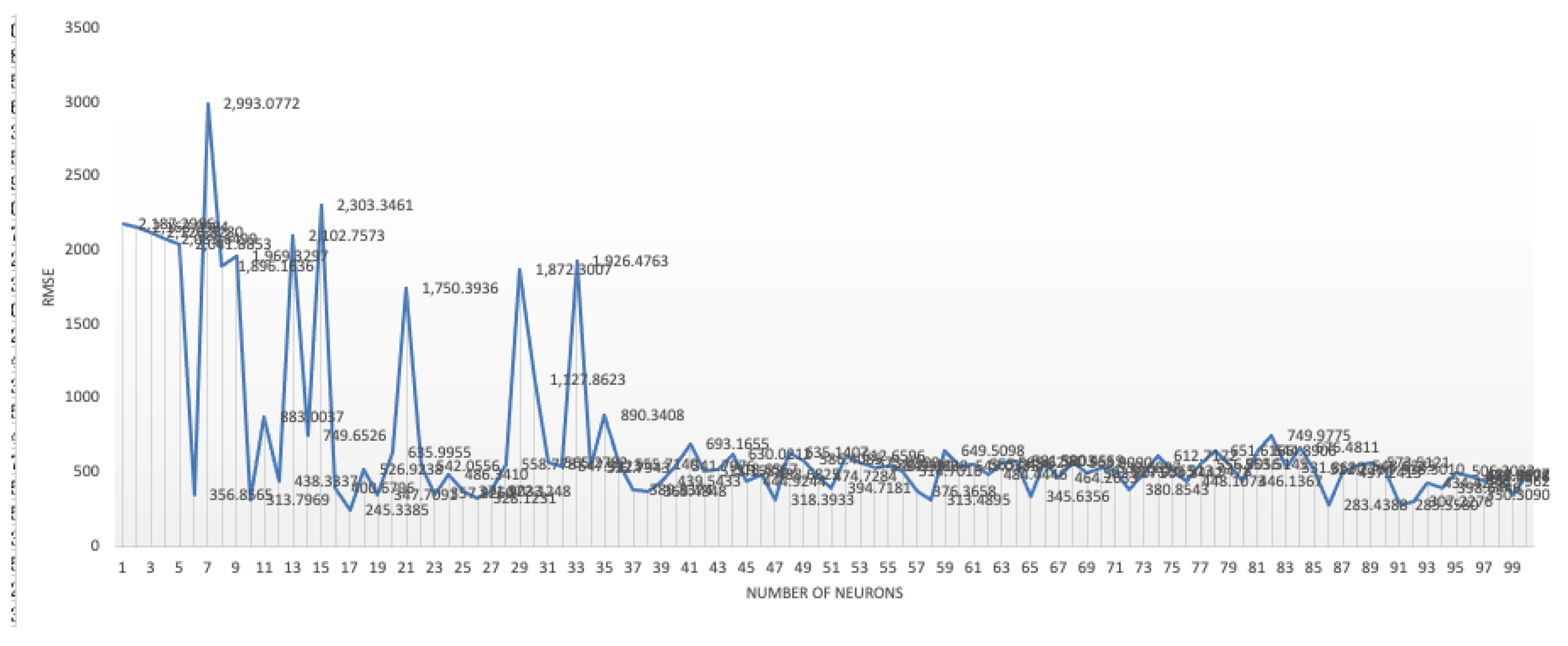
4.2. Results for In-Sample Model Fit
4.3. Results for Out-of-Sample Model Performance Evaluation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kim, H.Y.; Won, C.H. Forecasting the volatility of stock price index: A hybrid model integrating LSTM with multiple GARCH-type models. Expert Syst. Appl. 2018, 103, 25–37. [Google Scholar] [CrossRef]
- Dash, R.; Dash, P.K. A hybrid stock trading framework integrating technical analysis with machine learning techniques. J. Financ. Data Sci. 2016, 2, 42–57. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.J.; Wang, J.Z.; Zhang, Z.G.; Guo, S.P. Stock index forecasting based on a hybrid model. Omega 2012, 40, 758–766. [Google Scholar] [CrossRef]
- Chen, Z.; Li, C.; Sun, W. Bitcoin price prediction using machine learning: An approach to sample dimension engineering. J. Comput. Appl. Math. 2020, 365, 112395. [Google Scholar] [CrossRef]
- Leonardo Ranaldi, M.G.F.F. CryptoNet: Using Auto-Regressive Multi-Layer Artificial Neural Networks to Predict Financial Time Series. Information 2022, 13, 524. [Google Scholar] [CrossRef]
- Xu, H.; Wang, M.; Jiang, S.; Yang, W. Carbon price forecasting with complex network and extreme learning machine. Phys. Stat. Mech. Its Appl. 2019, 545, 122830. [Google Scholar] [CrossRef]
- Atsalakis, G.S. Using computational intelligence to forecast carbon prices. Appl. Soft Comput. J. 2016, 43, 107–116. [Google Scholar] [CrossRef]
- Daskalakis, G. On the efficiency of the European carbon market: New evidence from Phase II. Energy Policy 2013, 54, 369–375. [Google Scholar] [CrossRef]
- Nayak, S.C.; Misra, B.B.; Behera, H.S. Artificial chemical reaction optimization of neural networks for efficient prediction of stock market indices. Ain Shams Eng. J. 2017, 8, 371–390. [Google Scholar] [CrossRef] [Green Version]
- Zhu, B.; Wei, Y. Carbon price forecasting with a novel hybrid ARIMA and least squares support vector machines methodology. Omega 2013, 41, 517–524. [Google Scholar] [CrossRef]
- Rout, A.K.; Dash, P.K.; Dash, R.; Bisoi, R. Forecasting financial time series using a low complexity recurrent neural network and evolutionary learning approach. J. King Saud Univ.-Comput. Inf. Sci. 2017, 29, 536–552. [Google Scholar] [CrossRef] [Green Version]
- Rounaghi, M.M.; Nassir Zadeh, F. Investigation of market efficiency and Financial Stability between S&P 500 and London Stock Exchange: Monthly and yearly Forecasting of Time Series Stock Returns using ARMA model. Phys. A Stat. Mech. Its Appl. 2016, 456, 10–21. [Google Scholar] [CrossRef]
- Shafie-khah, M.; Moghaddam, M.P.; Sheikh-El-Eslami, M.K. Price forecasting of day-ahead electricity markets using a hybrid forecast method. Energy Convers. Manag. 2011, 52, 2165–2169. [Google Scholar] [CrossRef]
- Pai, P.F.; Lin, C.S. A hybrid ARIMA and support vector machines model in stock price forecasting. Omega 2005, 33, 497–505. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, J.; Xiong, T.; Su, C. Interval Forecasting of Carbon Futures Prices Using a Novel Hybrid Approach with Exogenous Variables. Discret. Dyn. Nat. Soc. 2017, 2017, 5730295. [Google Scholar] [CrossRef] [Green Version]
- Ibrahim, A.; Kashef, R.; Corrigan, L. Predicting market movement direction for bitcoin: A comparison of time series modeling methods. Comput. Electr. Eng. 2021, 89, 106905. [Google Scholar] [CrossRef]
- Chevallier, J. Nonparametric modeling of carbon prices. Energy Econ. 2011, 33, 1267–1282. [Google Scholar] [CrossRef]
- Zhao, X.; Han, M.; Ding, L.; Kang, W. Usefulness of economic and energy data at different frequencies for carbon price forecasting in the EU ETS. Appl. Energy 2018, 216, 132–141. [Google Scholar] [CrossRef]
- Fan, X.; Li, S.; Tian, L. Chaotic characteristic identification for carbon price and an multi-layer perceptron network prediction model. Expert Syst. Appl. 2015, 42, 3945–3952. [Google Scholar] [CrossRef]
- Fenghua, W.; Jihong, X.; Zhifang, H.E.; Xu, G. Stock Price Prediction based on SSA and SVM. Procedia Comput. Sci. 2014, 31, 625–631. [Google Scholar] [CrossRef] [Green Version]
- Shen, G.; Tan, Q.; Zhang, H.; Zeng, P.; Xu, J. Deep Learning with Gated Recurrent Unit Networks for Financial Sequence Predictions. Procedia Comput. Sci. 2018, 131, 895–903. [Google Scholar] [CrossRef]
- Atsalakis, G.S.; Atsalaki, I.G.; Pasiouras, F.; Zopounidis, C. Bitcoin price forecasting with neuro-fuzzy techniques. Eur. J. Oper. Res. 2019, 276, 770–780. [Google Scholar] [CrossRef]
- Nagula, P.K.; Alexakis, C. A new hybrid machine learning model for predicting the bitcoin (BTC-USD) price. J. Behav. Exp. Financ. 2022, 36, 100741. [Google Scholar] [CrossRef]
- Sun, G.; Chen, T.; Wei, Z.; Sun, Y.; Zang, H.; Chen, S. A Carbon Price Forecasting Model Based on Variational Mode Decomposition and Spiking Neural Networks. Energies 2016, 9, 54. [Google Scholar] [CrossRef] [Green Version]
- Zhu, B.; Ye, S.; Wang, P.; He, K.; Zhang, T.; Wei, Y.M. A novel multiscale nonlinear ensemble leaning paradigm for carbon price forecasting. Energy Econ. 2018, 70, 143–157. [Google Scholar] [CrossRef]
- Zhu, B.; Han, D.; Wang, P.; Wu, Z.; Zhang, T.; Wei, Y.M. Forecasting carbon price using empirical mode decomposition and evolutionary least squares support vector regression. Appl. Energy 2017, 191, 521–530. [Google Scholar] [CrossRef] [Green Version]
- Ni, L.; Li, Y.; Wang, X.; Zhang, J.; Yu, J.; Qi, C. Forecasting of Forex Time Series Data Based on Deep Learning. Procedia Comput. Sci. 2019, 147, 647–652. [Google Scholar] [CrossRef]
- Long, W.; Lu, Z.; Cui, L. Deep learning-based feature engineering for stock price movement prediction. Knowl.-Based Syst. 2019, 164, 163–173. [Google Scholar] [CrossRef]
- Gonçalves, R.; Ribeiro, V.M.; Pereira, F.L.; Rocha, A.P. Deep learning in exchange markets. Inf. Econ. Policy 2019, 47, 38–51. [Google Scholar] [CrossRef]
- Peng, L.; Liu, S.; Liu, R.; Wang, L. Effective long short-term memory with differential evolution algorithm for electricity price prediction. Energy 2018, 162, 1301–1314. [Google Scholar] [CrossRef]
- Cen, Z.; Wang, J. Crude oil price prediction model with long short term memory deep learning based on prior knowledge data transfer. Energy 2019, 169, 160–171. [Google Scholar] [CrossRef]
- Zhang, G.P. Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing 2003, 50, 159–175. [Google Scholar] [CrossRef]
- Jeong, K.; Koo, C.; Hong, T. An estimation model for determining the annual energy cost budget in educational facilities using SARIMA (seasonal autoregressive integrated moving average) and ANN (artificial neural network). Energy 2014, 71, 71–79. [Google Scholar] [CrossRef]
- Brooks, C. Introductory Econometrics for Finance, 2nd ed.; Cambridge University Press: Cambridge, UK; New York, NY, USA, 2008. [Google Scholar]
- Li, X.; Shang, W.; Wang, S. Text-based crude oil price forecasting: A deep learning approach. Int. J. Forecast. 2019, 35, 1548–1560. [Google Scholar] [CrossRef]
- Sepp Hochreiter and Jürgen Schmidhuber. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Yang, C.; Huang, K.; Gui, W. Non-ferrous metals price forecasting based on variational mode decomposition and LSTM network. Knowl.-Based Syst. 2019, 105006. [Google Scholar] [CrossRef]
- Cao, J.; Li, Z.; Li, J. Financial time series forecasting model based on CEEMDAN and LSTM. Phys. A Stat. Mech. Appl. 2019, 519, 127–139. [Google Scholar] [CrossRef]
- Qing, X.; Niu, Y. Hourly day-ahead solar irradiance prediction using weather forecasts by LSTM. Energy 2018, 148, 461–468. [Google Scholar] [CrossRef]
- Sun, X.; Liu, M.; Sima, Z. A novel cryptocurrency price trend forecasting model based on LightGBM. Financ. Res. Lett. 2020, 32, 101084. [Google Scholar] [CrossRef]
- Alquist, R.; Kilian, L. What Do We Learn from the Price of Crude Oil Futures? J. Appl. Econom. 2010, 25, 539–573. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Mean | Min | Max | Standard Deviation | Skewness | Kurtosis | ||
|---|---|---|---|---|---|---|---|---|
| P | 12.32 | 2.97 | 30.52 | 7.40 | 0.77 | 2.34 | 0 | 0.4685 |
| P | 2801.7 | 1950.01 | 5166.35 | 529.38 | 0.75 | 4.53 | 0 | 0.001 |
| P | 3028.11 | 4.22 | 19187 | 3847.12 | 1.15 | 3.25 | 0 | 0.5312 |
| Model | RMSE | MAPE | MAE | |
|---|---|---|---|---|
| Random walk | 1.2399 | 0.0415 | 0.9151 | 0.4651 |
| ARMA | 1.2379 | 0.0413 | 0.9122 | 0.5581 |
| MLP | 1.3771 | 0.0466 | 1.0217 | 0.5039 |
| LSTM | 3.9867 | 0.1552 | 3.3696 | 0.5504 |
| CNN | 1.7748 | 0.0621 | 1.3474 | 0.4884 |
| ARMA-CNNLSTM | 1.2195 | 0.0400 | 0.8837 | 0.6047 |
| Model | RMSE | MAPE | MAE | |
|---|---|---|---|---|
| Random walk | 1.7173 | 5.6231 | 1.271 | 0.3517 |
| ARMA | 1.2004 | 1.3853 | 0.8669 | 0.7526 |
| MLP | 1.2175 | 1.2291 | 0.8727 | 0.7321 |
| LSTM | 1.2022 | 1.0637 | 0.8655 | 0.7464 |
| CNN | 1.2061 | 1.2057 | 0.8679 | 0.7403 |
| ARMA-CNNLSTM | 1.1964 | 1.1479 | 0.861 | 0.7423 |
| Model | RMSE | MAPE | MAE | |
|---|---|---|---|---|
| Random walk | 323.8311 | 0.0257 | 199.1424 | 0.5314 |
| ARMA | 324.6788 | 0.0258 | 199.5287 | 0.4928 |
| MLP | 341.0648 | 0.028 | 217.3472 | 0.5153 |
| LSTM | 476.8439 | 0.0423 | 327.0795 | 0.5395 |
| CNN | 378.66 | 0.0315 | 243.013 | 0.5298 |
| ARMA-CNNLSTM | 323.7705 | 0.0254 | 197.04 | 0.5556 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, K.; Yang, Q.; Ji, L.; Pan, J.; Zou, Y. Financial Time Series Forecasting with the Deep Learning Ensemble Model. Mathematics 2023, 11, 1054. https://doi.org/10.3390/math11041054
He K, Yang Q, Ji L, Pan J, Zou Y. Financial Time Series Forecasting with the Deep Learning Ensemble Model. Mathematics. 2023; 11(4):1054. https://doi.org/10.3390/math11041054
Chicago/Turabian StyleHe, Kaijian, Qian Yang, Lei Ji, Jingcheng Pan, and Yingchao Zou. 2023. "Financial Time Series Forecasting with the Deep Learning Ensemble Model" Mathematics 11, no. 4: 1054. https://doi.org/10.3390/math11041054