
A Statistics and Deep Learning Hybrid Method for Multivariate Time Series Forecasting and Mortality Modeling


Abstract
:1. Introduction
1.1. Literature Review
1.2. Contribution
- We extend the current research, which focuses on ES and RNN hybrid methods for univariate forecasting, to a multivariate framework. We thus test assertions on multivariate mortality data with exogenous variables previously only tested empirically on univariate data, i.e., are hybrid methods better than pure statistical or pure deep learning methods at (i) forecasting tasks and (ii) quantifying forecast uncertainty? In particular, we present a natural extension of Smyl’s ES-RNN to higher dimensions;
- we present our forecast engine MES-LSTM, which is an efficient generalization, and as such, may be applied not only to the multivariate case but also to the univariate setting with ease; and
- whereas previous (univariate) research on forecasting hybrid methods primarily focuses on the multiplicative seasonality case, we consider both multiplicative and additive, with automatic adaptation to the case most applicable to the particular dataset.
2. Methods
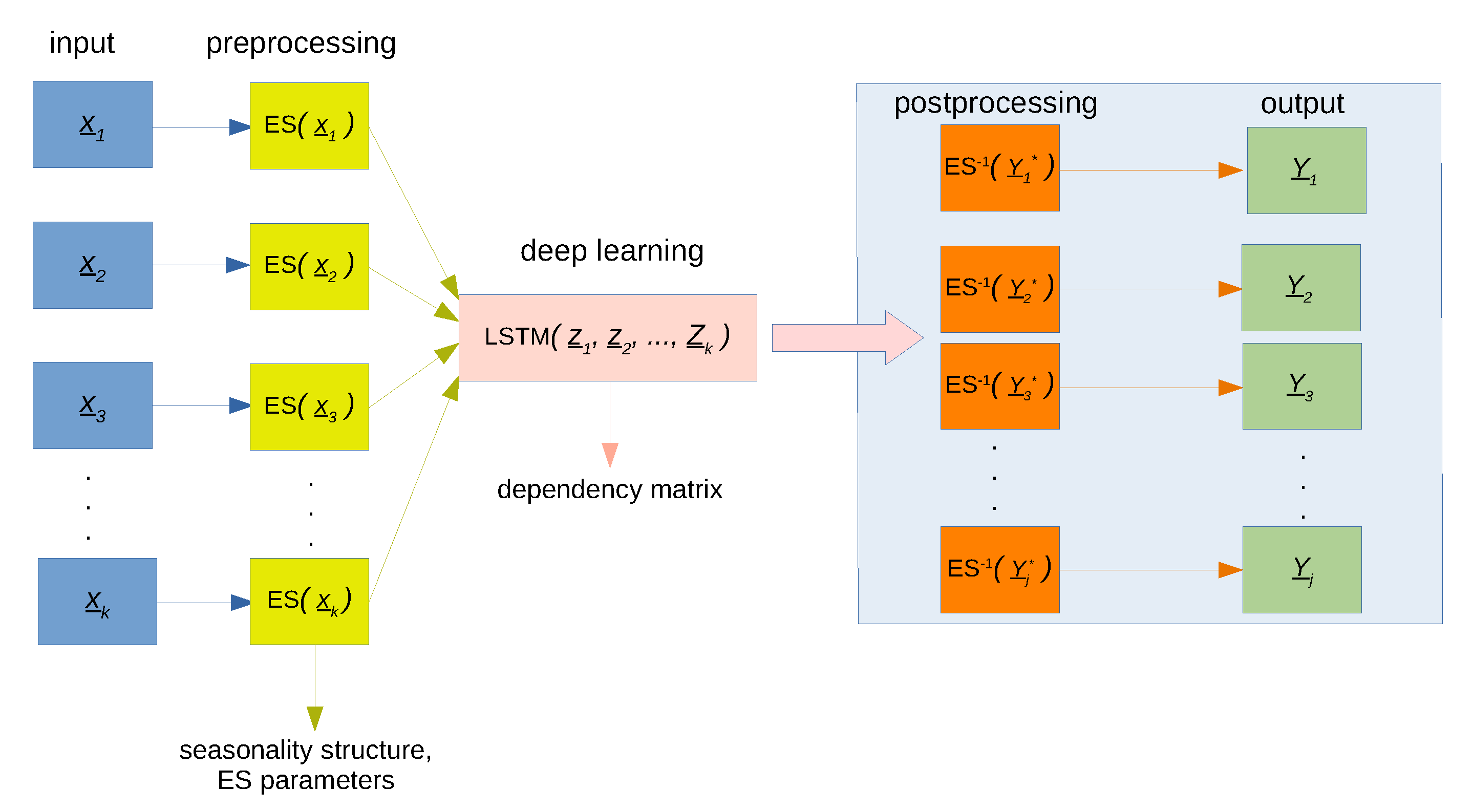
2.1. Preprocessing Layer
2.2. Deep Learning Layer
2.3. Hyperparameter Tuning
2.4. Metrics
2.5. Benchmarks
3. Datasets
4. Results and Discussion
4.1. Forecast Performance for SADC
4.2. Prediction Interval Performance for SADC
4.3. Forecast Performance for South Africa
4.4. Prediction Interval Performance for South Africa
4.5. Effects of Variability on Model Performance
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lim, B.; Arik, S.Ö.; Loeff, N.; Pfister, T. Temporal Fusion Transformers for interpretable multi-horizon time series forecasting. Int. J. Forecast. 2021, 37, 1748–1764. [Google Scholar] [CrossRef]
- Smyl, S. A hybrid method of exponential smoothing and recurrent neural networks for time series forecasting. Int. J. Forecast. 2020, 36, 75–85. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Koehler, A.B.; Snyder, R.D.; Grose, S. A state space framework for automatic forecasting using exponential smoothing methods. Int. J. Forecast. 2002, 18, 439–454. [Google Scholar] [CrossRef] [Green Version]
- Jaeger, H. The “Echo State” Approach to Analysing and Training Recurrent Neural Networks; GMD Report 148; GMD—German National Research Institute for Computer Science: Hanover, Germany, 2001. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Hochreiter, S.; Bengio, Y.; Frasconi, P. Gradient flow in recurrent nets: The difficulty of learning long-term dependencies. In A Field Guide to Dynamical Recurrent Neural Networks; Kolen, J.F., Kremer, S.C., Eds.; IEEE Press: Piscataway, NJ, USA, 2001. [Google Scholar]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. The M4 Competition: 100,000 time series and 61 forecasting methods. Int. J. Forecast. 2020, 36, 54–74. [Google Scholar] [CrossRef]
- Redd, A.; Khin, K.; Marini, A. Fast ES-RNN: A GPU Implementation of the ES-RNN Algorithm. arXiv 2019, arXiv:1907.03329. [Google Scholar]
- Beeram, S.R.; Kuchibhotla, S. Time Series Analysis on Univariate and Multivariate Variables: A Comprehensive Survey. In Communication Software and Networks; Satapathy, S.C., Bhateja, V., Ramakrishna Murty, M., Gia Nhu, N., Kotti, J., Eds.; Springer: Singapore, 2021; pp. 119–126. [Google Scholar]
- Bharathi Priya, C.; Arulanand, N. Univariate and multivariate models for Short-term wind speed forecasting. Mater. Today Proc. 2021. [Google Scholar] [CrossRef]
- Olkin, I.; Sampson, A. Multivariate Analysis: Overview. In International Encyclopedia of the Social and Behavioral Sciences; Smelser, N.J., Baltes, P.B., Eds.; Pergamon: Oxford, UK, 2001; pp. 10240–10247. [Google Scholar]
- Jones, R.H. Exponential Smoothing for Multivariate Time Series. J. R. Stat. Soc. Ser. B Methodol. 1966, 28, 241–251. [Google Scholar] [CrossRef]
- Enns, P.G.; Machak, J.A.; Spivey, W.A.; Wrobleski, W.J. Forecasting Applications of an Adaptive Multiple Exponential Smoothing Model. Manag. Sci. 1982, 28, 1035–1044. [Google Scholar] [CrossRef]
- Trigg, D.W.; Leach, A.G. Exponential Smoothing with an Adaptive Response Rate. OR 1967, 18, 53–59. [Google Scholar] [CrossRef]
- Harvey, A.C. Analysis and Generalisation of a Multivariate Exponential Smoothing Model. Manag. Sci. 1986, 32, 374–380. [Google Scholar] [CrossRef]
- Pfeffermann, D.; Allon, J. Multivariate exponential smoothing: Method and practice. Int. J. Forecast. 1989, 5, 83–98. [Google Scholar] [CrossRef]
- Tan, F. Regression analysis and prediction using LSTM model and machine learning methods. J. Phys. Conf. Ser. 2021, 1982, 012013. [Google Scholar] [CrossRef]
- Hu, Y.; O’Donncha, F.; Palmes, P.; Burke, M.; Filgueira, R.; Grant, J. A spatio-temporal LSTM model to forecast across multiple temporal and spatial scales. arXiv 2021, arXiv:2108.11875. [Google Scholar]
- Kırbaş, I.; Sözen, A.; Tuncer, A.D.; Kazancioğlu, F.Ş. Comparative analysis and forecasting of COVID-19 cases in various European countries with ARIMA, NARNN and LSTM approaches. Chaos Solitons Fractals 2020, 138, 110015. [Google Scholar] [CrossRef]
- Ibrahim, M.; Jemei, S.; Wimmer, G.; Hissel, D. Nonlinear autoregressive neural network in an energy management strategy for battery/ultra-capacitor hybrid electrical vehicles. Electr. Power Syst. Res. 2016, 136, 262–269. [Google Scholar] [CrossRef]
- Chandra, R.; Jain, A.; Chauhan, D.S. Deep learning via LSTM models for COVID-19 infection forecasting in India. arXiv 2021, arXiv:2101.11881. [Google Scholar]
- Chimmula, V.K.R.; Zhang, L. Time series forecasting of COVID-19 transmission in Canada using LSTM networks. Chaos Solitons Fractals 2020, 135, 109864. [Google Scholar] [CrossRef]
- Shahid, F.; Zameer, A.; Muneeb, M. Predictions for COVID-19 with deep learning models of LSTM, GRU and Bi-LSTM. Chaos Solitons Fractals 2020, 140, 110212. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.; Gülçehre, Ç.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. In Proceedings of the NIPS 2014 Deep Learning and Representation Learning Workshop, Montreal, QC, Canada, 12 December 2014. [Google Scholar]
- Mathonsi, T.; van Zyl, T.L. Multivariate Anomaly Detection based on Prediction Intervals Constructed using Deep Learning. arXiv 2021, arXiv:2110.03393. [Google Scholar]
- Hu, M.J.C.; Root, H.E. Application of the Adaline System to Weather Forecasting; Technical Report 6775-1; Stanford Electronic Laboratories: Stanford, CA, USA, 1964. [Google Scholar]
- Mathonsi, T.; v. Zyl, T.L. Prediction Interval Construction for Multivariate Point Forecasts Using Deep Learning. In Proceedings of the 2020 7th International Conference on Soft Computing Machine Intelligence (ISCMI), Stockholm, Sweden, 14–15 November 2020; pp. 88–95. [Google Scholar]
- Oreshkin, B.N.; Carpov, D.; Chapados, N.; Bengio, Y. N-BEATS: Neural basis expansion analysis for interpretable time series forecasting. arXiv 2020, arXiv:1905.10437. [Google Scholar]
- Olivares, K.G.; Challu, C.; Marcjasz, G.; Weron, R.; Dubrawski, A. Neural basis expansion analysis with exogenous variables: Forecasting electricity prices with NBEATSx. arXiv 2021, arXiv:2104.05522. [Google Scholar]
- Makridakis, S.; Spiliotis, E. The M5 Competition and the Future of Human Expertise in Forecasting. Foresight Int. J. Appl. Forecast. 2021, 60, 33–37. [Google Scholar]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. The M5 competition: Background, organization, and implementation. Int. J. Forecast. 2021. [Google Scholar] [CrossRef]
- Wen, Y.; Vicol, P.; Ba, J.; Tran, D.; Grosse, R. Flipout: Efficient Pseudo-Independent Weight Perturbations on Mini-Batches. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Blundell, C.; Cornebise, J.; Kavukcuoglu, K.; Wierstra, D. Weight Uncertainty in Neural Networks. In Proceedings of the 32nd International Conference on International Conference on Machine Learning—Volume 37. JMLR.org, 2015, ICML’15, Lille, France, 7–9 July; 2015; pp. 1613–1622. [Google Scholar]
- Joyce, J.M. Kullback-Leibler Divergence. In International Encyclopedia of Statistical Science; Springer: Berlin/Heidelberg, Germany, 2011; pp. 720–722. [Google Scholar] [CrossRef]
- Dillon, J.V.; Langmore, I.; Tran, D.; Brevdo, E.; Vasudevan, S.; Moore, D.A.; Patton, B.; Alemi, A.A.; Hoffman, M.; Saurous, R. TensorFlow Distributions. arXiv 2017, arXiv:1711.10604. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Dropout As a Bayesian approximation: Representing Model Uncertainty in Deep Learning. In Proceedings of the 33rd International Conference on International Conference on Machine Learning. JMLR.org, ICML’16, New York, NY, USA, 19–24 June 2016; Volume 48, pp. 1050–1059. [Google Scholar]
- Davison, A.C.; Hinkley, D.V. Bootstrap Methods and Their Application; Cambridge University Press: New York, NY, USA, 2013. [Google Scholar]
- Hesterberg, T. What Teachers Should Know about the Bootstrap: Resampling in the Undergraduate Statistics Curriculum. Am. Stat. 2014, 69, 371–386. [Google Scholar] [CrossRef] [Green Version]
- Lever, J.; Krzywinski, M.; Altman, N. Points of Significance: Model selection and overfitting. Nat. Methods 2016, 13, 703–704. [Google Scholar] [CrossRef]
- Akaike, H. Information theory and an extension of the maximum likelihood principle. In Second International Symposium on Information Theory; Petrov, B.N., Csaki, F., Eds.; Akadémiai Kiado: Budapest, Hungary, 1973; pp. 267–281. [Google Scholar]
- Matthews, D.E. Multiple Linear Regression. In Encyclopedia of Biostatistics; American Cancer Society: Atlanta, GA, USA, 2005; Chapter 5; pp. 119–133. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Makridakis, S.; Hibon, M. The M3-Competition: Results, conclusions and implications. Int. J. Forecast. 2000, 16, 451–476. [Google Scholar] [CrossRef]
- Koehler, A. Commentaries on the M3-Competition. Int. J. Forecast. 2001, 17, 537–584. [Google Scholar]
- Goodwin, P.; Lawton, R. On the asymmetry of the symmetric MAPE. Int. J. Forecast. 1999, 15, 405–408. [Google Scholar] [CrossRef]
- Gneiting, T.; Raftery, A.E. Strictly Proper Scoring Rules, Prediction, and Estimation. J. Am. Stat. Assoc. 2007, 102, 359–378. [Google Scholar] [CrossRef]
- Hannan, E.J.; Deistler, M. The Statistical Theory of Linear Systems. Econom. Theory 1992, 8, 135–143. [Google Scholar]
- Arunraj, N.; Ahrens, D.; Fernandes, M. Application of SARIMAX Model to Forecast Daily Sales in Food Retail Industry. Int. J. Oper. Res. Inf. Syst. 2016, 7, 1–21. [Google Scholar] [CrossRef]
- Salinas, D.; Flunkert, V.; Gasthaus, J.; Januschowski, T. DeepAR: Probabilistic forecasting with autoregressive recurrent networks. Int. J. Forecast. 2020, 36, 1181–1191. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3146–3154. [Google Scholar]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. The M5 Accuracy Competition: Results, Findings and Conclusions. Available online: https://www.researchgate.net/publication/344487258_The_M5_Accuracy_competition_Results_findings_and_conclusions (accessed on 23 October 2021).
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V.; Chen, Z.; Gaba, A.; Tsetlin, I.; Winkler, R. The M5 Uncertainty competition: Results, findings and conclusions. Int. J. Forecast. 2021. [Google Scholar] [CrossRef]
- Mathieu, E.; Ritchie, H.; Ortiz-Ospina, E.; Roser, M.; Hasell, J.; Appel, C.; Giattino, C. A global database of COVID-19 vaccinations. Nat. Hum. Behav. 2021, 5, 947–953. [Google Scholar] [CrossRef]
- Hasell, J.; Mathieu, E.; Beltekian, D.; Macdonald, B.; Giattino, C.; Ortiz-Ospina, E.; Roser, M.; Ritchie, H. A cross-country database of COVID-19 testing. Sci. Data 2020, 7, 345–347. [Google Scholar] [CrossRef]
- Diebold, F.; Mariano, R. Comparing Predictive Accuracy. J. Bus. Econ. Stat. 1995, 13, 253–263. [Google Scholar]
- Mean Absolute Percentage Error. In Encyclopedia of Production and Manufacturing Management; Swamidass, P.M. (Ed.) Springer: Boston, MA, USA, 2000; p. 462. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Search Space |
|---|---|
| LSTM size | 50, 55, 60, …, 150 |
| epochs | 15, 20, 25, …, 75 |
| batch size | 8, 16, 24, …, 64 |
| input window | 7, 14, 21 |
| Metrics | Source | Updated | Countries |
|---|---|---|---|
| Vaccinations | Official data collated by the Our World in Data team | Daily | 217 |
| Tests & positivity | Official data collated by the Our World in Data team | Weekly | 136 |
| Hospital & ICU | Official data collated by the Our World in Data team | Weekly | 34 |
| Confirmed cases | JHU CSSE COVID-19 Data | Daily | 194 |
| Confirmed deaths | JHU CSSE COVID-19 Data | Daily | 194 |
| Reproduction rate | Arroyo-Marioli F, Bullano F, Kucinskas S, Rondón-Moreno C | Daily | 184 |
| Policy responses | Oxford COVID-19 Government Response Tracker | Daily | 186 |
| Other variables of interest | International organizations (UN, World Bank, OECD, IHME…) | Fixed | 240 |
| Variable | Description |
|---|---|
| total cases | Total confirmed cases of COVID-19 |
| new cases | New confirmed cases of COVID-19 |
| total cases per million | Total confirmed cases of COVID-19 per 1,000,000 people |
| new cases per million | New confirmed cases of COVID-19 per 1,000,000 people |
| total deaths | Total deaths attributed to COVID-19 |
| new deaths | New deaths attributed to COVID-19 |
| total deaths per million | Total deaths attributed to COVID-19 per 1,000,000 people |
| new deaths per million | New deaths attributed to COVID-19 per 1,000,000 people |
| icu patients | Number of COVID-19 patients in intensive care units (ICUs) on a given day |
| icu patients per million | Number of COVID-19 patients in ICUs on a given day per 1,000,000 people |
| hosp patients | Number of COVID-19 patients in hospital on a given day |
| weekly icu admissions | Number of COVID-19 patients newly admitted to ICUs in a given week |
| weekly icu admissions per million | Number of COVID-19 patients newly admitted to ICUs in a given week per 1,000,000 people |
| weekly hosp admissions | Number of COVID-19 patients newly admitted to hospitals in a given week |
| weekly hosp admissions per million | Number of COVID-19 patients newly admitted to hospitals in a given week per 1,000,000 people |
| stringency index | Government Response Stringency Index: composite measure based on 9 response indicators |
| reproduction rate | Real-time estimate of the effective reproduction rate (R) of COVID-19 |
| total tests | Total tests for COVID-19 |
| new tests | New tests for COVID-19 (only calculated for consecutive days) |
| positive rate | Share of COVID-19 tests that are positive, rolling 7-day average (inverse of tests per case) |
| tests per case | Tests conducted per new confirmed case of COVID-19, rolling 7-day average (inverse of positive rate) |
| total vaccinations | Total number of COVID-19 vaccination doses administered |
| people vaccinated | Total number of people who received at least one vaccine dose |
| people fully vaccinated | Total number of people who received all doses |
| new vaccinations | New COVID-19 vaccination doses administered (only calculated for consecutive days) |
| total vaccinations per hundred | Total number of COVID-19 vaccination doses administered per 100 people |
| people vaccinated per hundred | Total number of people who received at least one vaccine dose per 100 people |
| people fully vaccinated per hundred | Total number of people who received all doses prescribed by the vaccination protocol per 100 people |
| location | Geographical location |
| date | Date of observation |
| population | Population in 2020 |
| population density | Number of people divided by land area, measured in square kilometers |
| median age | Median age of the population, UN projection for 2020 |
| aged 65 older | Share of the population that is 65 years and older, most recent year available |
| aged 70 older | Share of the population that is 70 years and older in 2015 |
| gdp per capita | Gross domestic product at purchasing power parity |
| extreme poverty | Share of the population living in extreme poverty |
| cardiovasc death rate | Death rate from cardiovascular disease in 2017 |
| diabetes prevalence | Diabetes prevalence (% of population aged 20 to 79) in 2017 |
| female smokers | Share of women who smoke, most recent year available |
| male smokers | Share of men who smoke, most recent year available |
| handwashing facilities | Share of the population with basic handwashing facilities on premises |
| hospital beds per thousand | Hospital beds per 1000 people, most recent year available since 2010 |
| life expectancy | Life expectancy at birth in 2019 |
| human development index | Composite average achievement in (i) a long, healthy life (ii) knowledge (iii) standard of living |
| excess mortality | Excess mortality P-scores for all ages |
| MES-LSTM | LSTM | LGB | DeepAR | VARMAX | SARIMAX | MLR | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Country | sMAPE | RMSE | sMAPE | RMSE | sMAPE | RMSE | sMAPE | RMSE | sMAPE | RMSE | sMAPE | RMSE | sMAPE | RMSE |
| Angola | 0.7 | 563.1 | 68.9 | 28,023.4 | 5.6 | 28,524.5 | 59.0 | 23,811.6 | 76.4 | 35,442.3 | 107.1 | 59,732.6 | 77.6 | 35,830.6 |
| Botswana | 1.6 | 5817.7 | 85.5 | 94,414.1 | 5.8 | 32,635.2 | 62.9 | 72,983.0 | 99.5 | 125,387.6 | 71.0 | 123,392.6 | 114.6 | 137,334.7 |
| Comoros | 1.1 | 52.5 | 16.5 | 623.3 | 5.3 | 32,005.1 | 50.1 | 1443.4 | 6.2 | 313.8 | 23.6 | 1058.6 | 17.6 | 704.2 |
| DRC | 0.8 | 468.3 | 72.6 | 25,987.3 | 5.3 | 29,933.9 | 41.9 | 17,302.5 | 12.8 | 7047.8 | 27.6 | 15,527.6 | 83.9 | 34,102.8 |
| Eswatini | 1.3 | 617.7 | 59.1 | 18,348.9 | 5.7 | 31,572.0 | 61.2 | 17,619.4 | 63.6 | 23,417.0 | 37.9 | 16,687.6 | 110.6 | 33,055.4 |
| Lesotho | 0.7 | 167.2 | 47.2 | 7324.4 | 5.5 | 28,662.4 | 33.9 | 5484.3 | 35.2 | 6478.7 | 137.8 | 24,942.5 | 42.4 | 7603.3 |
| Madagascar | 1.3 | 636.6 | 35.1 | 12,019.8 | 5.5 | 29,387.4 | 45.6 | 13,719.5 | 11.1 | 5495.1 | 8.8 | 3889.1 | 22.3 | 9014.0 |
| Malawi | 1.3 | 817.5 | 22.0 | 11,967.0 | 5.9 | 30,163.2 | 14.1 | 8183.4 | 10.4 | 7629.0 | 9.7 | 5956.9 | 42.2 | 23,504.7 |
| Mauritius | 3.8 | 2056.8 | 99.8 | 9891.6 | 5.8 | 29,677.4 | 91.1 | 8643.8 | 179.5 | 17,135.7 | 242.9 | 32,875.6 | 171.3 | 16,742.4 |
| Mozambique | 1.1 | 1685.0 | 5.0 | 7457.6 | 5.2 | 29,234.1 | 3.0 | 4438.9 | 2.5 | 3946.2 | 90.5 | 125,768.7 | 10.3 | 15,089.2 |
| Namibia | 1.1 | 1508.8 | 5.2 | 7516.3 | 5.6 | 26,149.9 | 2.3 | 2969.0 | 12.0 | 17,579.1 | 25.3 | 32,551.7 | 7.7 | 10,010.1 |
| Seychelles | 0.9 | 266.7 | 59.9 | 8908.6 | 5.4 | 27,596.0 | 62.1 | 8596.8 | 11.4 | 2428.1 | 47.4 | 10,115.2 | 99.0 | 14,797.0 |
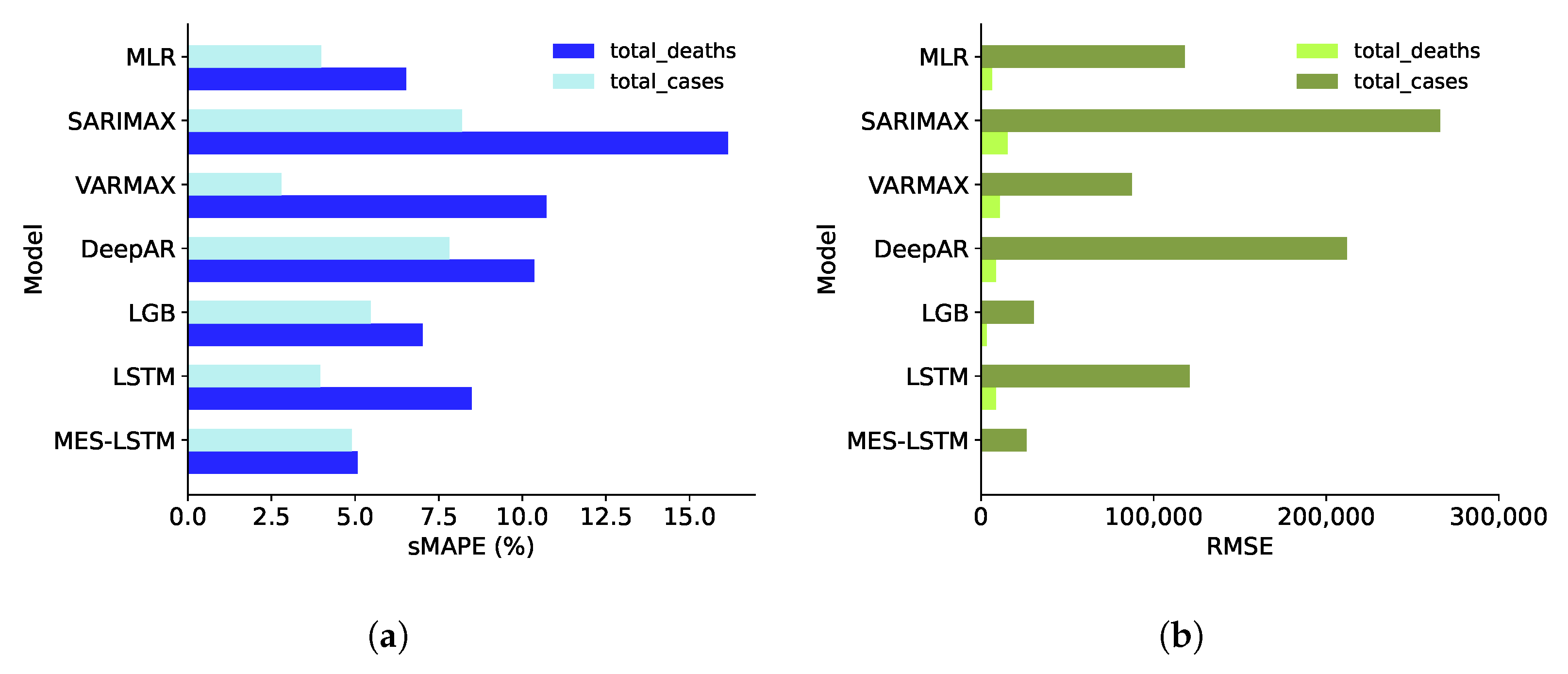
| South Africa | 5.0 | 26,979.2 | 4.8 | 150,416.4 | 5.6 | 30,420.9 | 7.8 | 212,612.0 | 2.8 | 87,376.0 | 8.2 | 265,998.0 | 4.0 | 118,139.5 |
| Tanzania | 0.3 | 134.6 | 116.3 | 15,445.1 | 6.0 | 30,900.7 | 96.5 | 12,839.8 | 184.1 | 25,060.9 | 636.9 | 87,188.8 | 194.9 | 25,818.8 |
| Zambia | 1.2 | 2499.0 | 6.4 | 15,567.7 | 5.8 | 28,686.9 | 2.0 | 4333.4 | 7.3 | 16,766.9 | 72.1 | 143,490.3 | 2.1 | 6120.9 |
| Zimbabwe | 1.1 | 1518.5 | 8.6 | 10,652.2 | 5.4 | 32,284.2 | 5.7 | 7251.2 | 8.4 | 12,296.7 | 6.4 | 9733.6 | 2.6 | 4164.0 |
| MES-LSTM | LSTM | LGB | DeepAR | VARMAX | SARIMAX | MLR | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Country | sMAPE | RMSE | sMAPE | RMSE | sMAPE | RMSE | sMAPE | RMSE | sMAPE | RMSE | sMAPE | RMSE | sMAPE | RMSE |
| Angola | 0.9 | 19.8 | 74.6 | 783.5 | 6.6 | 2886.7 | 60.8 | 687.0 | 89.9 | 1055.7 | 71.6 | 1038.1 | 89.4 | 1052.1 |
| Botswana | 1.0 | 26.1 | 86.1 | 1203.9 | 6.7 | 2909.9 | 77.2 | 1128.8 | 97.6 | 1576.5 | 15.7 | 363.9 | 120.8 | 1806.0 |
| Comoros | 1.5 | 2.4 | 12.5 | 16.7 | 6.2 | 3069.4 | 72.4 | 66.8 | 15.6 | 27.3 | 13.5 | 20.6 | 10.9 | 16.0 |
| DRC | 1.0 | 12.0 | 67.2 | 470.1 | 6.1 | 3059.6 | 38.2 | 326.4 | 2.4 | 34.2 | 11.6 | 128.9 | 74.0 | 594.3 |
| Eswatini | 1.1 | 14.2 | 49.6 | 435.1 | 7.0 | 2594.2 | 58.8 | 490.0 | 46.3 | 525.6 | 35.3 | 403.1 | 95.1 | 801.0 |
| Lesotho | 0.8 | 5.4 | 47.2 | 222.9 | 6.9 | 2790.2 | 42.4 | 207.1 | 46.8 | 249.7 | 97.4 | 516.2 | 44.5 | 240.8 |
| Madagascar | 1.2 | 12.2 | 48.1 | 330.3 | 6.6 | 2820.6 | 71.5 | 431.7 | 4.2 | 44.6 | 2.0 | 20.4 | 41.7 | 335.9 |
| Malawi | 1.2 | 28.7 | 27.1 | 518.9 | 6.6 | 3072.6 | 20.4 | 416.1 | 14.5 | 349.6 | 14.2 | 314.9 | 46.2 | 958.7 |
| Mauritius | 1.7 | 39.9 | 103.0 | 109.6 | 6.9 | 3014.0 | 104.4 | 110.3 | 173.1 | 183.1 | 300.2 | 341.7 | 172.7 | 183.1 |
| Mozambique | 1.1 | 21.9 | 5.1 | 96.7 | 6.4 | 3269.7 | 4.5 | 85.6 | 4.9 | 98.7 | 9.2 | 180.1 | 15.6 | 281.4 |
| Namibia | 1.1 | 41.9 | 7.9 | 333.8 | 6.1 | 3200.6 | 4.9 | 174.9 | 19.6 | 848.9 | 17.2 | 601.2 | 29.3 | 913.9 |
| Seychelles | 1.7 | 7.0 | 71.9 | 54.0 | 7.1 | 3288.2 | 82.4 | 58.9 | 5.9 | 8.3 | 43.5 | 47.7 | 116.9 | 88.8 |
| South Africa | 4.9 | 446.2 | 7.8 | 7902.4 | 5.9 | 2773.4 | 10.4 | 8515.8 | 10.7 | 10,806.6 | 16.1 | 15,438.9 | 6.5 | 6276.2 |
| Tanzania | 0.3 | 3.8 | 114.7 | 425.6 | 6.7 | 3143.2 | 113.7 | 423.5 | 179.3 | 685.9 | 362.3 | 1379.1 | 193.0 | 712.9 |
| Zambia | 1.3 | 47.7 | 6.6 | 266.8 | 6.6 | 2806.5 | 4.3 | 174.2 | 7.5 | 301.4 | 1.9 | 87.8 | 11.7 | 420.1 |
| Zimbabwe | 1.1 | 53.4 | 6.5 | 298.2 | 6.3 | 3067.7 | 8.1 | 361.0 | 14.8 | 791.5 | 5.8 | 289.7 | 6.7 | 345.0 |
| MES-LSTM | LSTM | LGB | DeepAR | VARMAX | SARIMAX | MLR | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Country | MIS | Coverage | MIS | Coverage | MIS | Coverage | MIS | Coverage | MIS | Coverage | MIS | Coverage | MIS | Coverage |
| Angola | 1910.8 | 95.2 | 116,739.1 | 0.0 | 55,663.7 | 81.6 | 54,875.9 | 0.0 | 902,714.3 | 0.0 | 814,594.0 | 0.0 | 660,826.0 | 0.0 |
| Botswana | 11,735.6 | 85.2 | 378,936.2 | 0.0 | 164,794.4 | 77.6 | 171,350.6 | 0.0 | 4,572,270.6 | 0.0 | 1,203,716.2 | 0.0 | 4259,387.7 | 0.0 |
| Comoros | 172.9 | 97.4 | 360.0 | 87.6 | 3908.4 | 84.4 | 5064.1 | 0.0 | 3085.7 | 40.9 | 1790.1 | 59.1 | 5461.2 | 100.0 |
| DRC | 2351.8 | 97.6 | 102,410.9 | 0.0 | 45,538.0 | 65.2 | 68,391.5 | 0.0 | 143,127.3 | 0.0 | 137,288.5 | 0.0 | 413,486.5 | 0.0 |
| Eswatini | 1837.3 | 91.0 | 86,314.2 | 0.0 | 44,987.2 | 79.6 | 44,252.9 | 0.0 | 518,283.5 | 14.3 | 140,160.1 | 0.0 | 683,626.1 | 0.0 |
| Lesotho | 750.4 | 97.4 | 24,269.2 | 0.4 | 20,065.3 | 89.0 | 18,693.3 | 0.0 | 218,810.3 | 0.0 | 310,359.2 | 0.0 | 24,172.3 | 55.8 |
| Madagascar | 2310.7 | 83.6 | 25,720.5 | 16.9 | 30,953.7 | 83.1 | 19,934.0 | 56.3 | 139,138.3 | 0.0 | 5270.5 | 100.0 | 48,987.3 | 100.0 |
| Malawi | 2503.3 | 88.0 | 27,408.2 | 38.8 | 40,635.9 | 78.9 | 31,982.9 | 0.0 | 60,588.0 | 70.2 | 33,628.7 | 100.0 | 303,117.6 | 55.3 |
| Mauritius | 2460.2 | 90.1 | 44,971.4 | 0.0 | 21,957.8 | 77.6 | 43,120.5 | 0.0 | 625,931.1 | 0.0 | 441,038.4 | 0.0 | 592,480.4 | 0.0 |
| Mozambique | 5249.2 | 94.2 | 17,924.2 | 92.1 | 68,002.5 | 86.0 | 3197.7 | 46.2 | 23,040.1 | 100.0 | 1,364,340.7 | 0.0 | 83,378.3 | 22.9 |
| Namibia | 4487.2 | 93.1 | 18,930.5 | 93.9 | 53,947.4 | 79.7 | 1726.9 | 59.2 | 48,9847.0 | 0.0 | 28,333.2 | 38.8 | 45,068.1 | 67.3 |
| Seychelles | 728.2 | 93.1 | 32,422.8 | 0.0 | 20,364.2 | 73.7 | 17,835.9 | 14.3 | 68,568.1 | 0.0 | 103,106.7 | 0.0 | 232,264.3 | 0.0 |
| South Africa | 193,075.6 | 80.7 | 348,860.7 | 97.7 | 1,418,713.2 | 86.6 | 239,009.3 | 100.0 | 740,131.9 | 100.0 | 1,061,162.0 | 100.0 | 828,447.2 | 100.0 |
| Tanzania | 943.6 | 96.2 | 67,427.5 | 0.0 | 32,459.5 | 77.3 | 67,350.0 | 0.0 | 990,720.2 | 0.0 | 1,279,781.1 | 0.0 | 1,018,128.2 | 0.0 |
| Zambia | 8972.0 | 89.2 | 24,151.6 | 96.4 | 89,095.3 | 73.5 | 8316.6 | 16.6 | 489,501.1 | 0.0 | 1,509,742.0 | 0.0 | 36,167.6 | 95.8 |
| Zimbabwe | 4770.4 | 87.7 | 23,667.6 | 85.8 | 63,299.2 | 77.9 | 2987.9 | 100.0 | 367,165.9 | 0.0 | 14,904.8 | 95.8 | 16,359.3 | 100.0 |
| MES-LSTM | LSTM | LGB | DeepAR | VARMAX | SARIMAX | MLR | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Country | MIS | Coverage | MIS | Coverage | MIS | Coverage | MIS | Coverage | MIS | Coverage | MIS | Coverage | MIS | Coverage |
| Angola | 53.2 | 94.0 | 3206.0 | 0.0 | 3348.1 | 77.1 | 2089.5 | 0.0 | 29,346.8 | 0.0 | 24,022.4 | 0.0 | 23,844.1 | 0.0 |
| Botswana | 106.4 | 93.3 | 4803.4 | 0.0 | 4357.0 | 75.1 | 1706.3 | 10.6 | 53,087.1 | 0.0 | 1079.0 | 48.9 | 51,432.7 | 0.0 |
| Comoros | 5.9 | 95.3 | 12.5 | 86.3 | 318.6 | 78.3 | 189.9 | 0.0 | 575.5 | 0.0 | 34.5 | 100.0 | 225.3 | 100.0 |
| DRC | 46.1 | 95.7 | 1725.4 | 0.0 | 1636.2 | 84.0 | 1013.0 | 20.4 | 163.4 | 100.0 | 336.5 | 100.0 | 4297.0 | 20.4 |
| Eswatini | 49.0 | 90.7 | 2,236.0 | 0.0 | 2350.4 | 90.2 | 671.6 | 0.0 | 8795.5 | 42.9 | 7693.3 | 0.0 | 10,342.2 | 0.0 |
| Lesotho | 22.8 | 97.6 | 795.3 | 0.3 | 1302.8 | 85.2 | 677.5 | 0.0 | 8941.9 | 0.0 | 11,845.1 | 0.0 | 1408.6 | 23.3 |
| Madagascar | 46.5 | 85.4 | 733.9 | 11.8 | 1787.3 | 77.7 | 894.2 | 2.1 | 244.4 | 56.3 | 108.1 | 100.0 | 1108.4 | 100.0 |
| Malawi | 89.4 | 88.8 | 1223.5 | 29.5 | 3526.6 | 85.7 | 1202.7 | 0.0 | 3309.8 | 61.7 | 1153.1 | 100.0 | 15,170.2 | 31.9 |
| Mauritius | 75.8 | 74.0 | 468.6 | 0.0 | 484.5 | 79.9 | 454.8 | 0.0 | 6978.1 | 0.0 | 8379.1 | 0.0 | 6861.6 | 0.0 |
| Mozambique | 66.8 | 94.2 | 244.7 | 91.2 | 1928.7 | 75.0 | 70.9 | 42.1 | 341.8 | 100.0 | 602.0 | 22.9 | 2707.0 | 22.9 |
| Namibia | 134.0 | 91.3 | 587.2 | 90.8 | 3411.9 | 81.7 | 101.4 | 89.7 | 21,239.2 | 0.0 | 23,742.4 | 0.0 | 10,490.6 | 0.0 |
| Seychelles | 5.8 | 91.0 | 188.7 | 0.0 | 258.6 | 76.1 | 143.5 | 0.0 | 33.4 | 77.6 | 694.2 | 0.0 | 1984.9 | 0.0 |
| South Africa | 5785.9 | 79.8 | 10,713.1 | 97.4 | 97,311.6 | 84.7 | 9589.2 | 17.6 | 63,626.1 | 48.1 | 33,910.2 | 100.0 | 26,489.6 | 100.0 |
| Tanzania | 28.4 | 94.7 | 1853.4 | 0.0 | 1911.1 | 85.9 | 1844.1 | 0.0 | 27,048.4 | 0.0 | 35,267.8 | 0.0 | 28,062.0 | 0.0 |
| Zambia | 150.0 | 89.7 | 429.3 | 94.9 | 3701.5 | 77.6 | 429.3 | 19.1 | 6940.6 | 6.3 | 458.3 | 100.0 | 1731.8 | 77.1 |
| Zimbabwe | 169.9 | 87.3 | 810.4 | 85.8 | 5004.7 | 84.6 | 119.7 | 100.0 | 26,898.9 | 0.0 | 746.0 | 95.8 | 4778.9 | 20.8 |
| MES-LSTM | LSTM | LGB | DeepAR | VARMAX | SARIMAX | MLR | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| sMAPE | RMSE | sMAPE | RMSE | sMAPE | RMSE | sMAPE | RMSE | sMAPE | RMSE | sMAPE | RMSE | sMAPE | RMSE | |
| mean | 5.0 | 26,979.2 | 4.8 | 150,416.4 | 5.6 | 30,420.9 | 7.8 | 212,612.0 | 2.8 | 87,376.0 | 8.2 | 265,998.0 | 4.0 | 118,139.5 |
| std | 1.1 | 5641.0 | 3.8 | 121,306.0 | 1.3 | 12,885.4 | 0.1 | 1192.2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| MES-LSTM | LSTM | LGB | DeepAR | VARMAX | SARIMAX | MLR | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| sMAPE | RMSE | sMAPE | RMSE | sMAPE | RMSE | sMAPE | RMSE | sMAPE | RMSE | sMAPE | RMSE | sMAPE | RMSE | |
| mean | 4.9 | 446.2 | 7.8 | 7902.4 | 5.9 | 2773.4 | 10.4 | 8515.8 | 10.7 | 10,806.6 | 16.1 | 15,438.9 | 6.5 | 6276.2 |
| std | 1.2 | 106.0 | 5.3 | 5578.8 | 2.2 | 1259.7 | 0.1 | 61.2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| MES-LSTM | LSTM | LGB | DeepAR | VARMAX | SARIMAX | MLR | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MIS | Coverage | MIS | Coverage | MIS | Coverage | MIS | Coverage | MIS | Coverage | MIS | Coverage | MIS | Coverage | |
| mean | 193,075.6 | 80.7 | 348,860.7 | 97.7 | 1,418,713.2 | 86.6 | 239,009.3 | 100.0 | 740,131.9 | 100.0 | 1,061,162.0 | 100.0 | 828,447.2 | 100.0 |
| std | 13,881.3 | 11.2 | 76,242.6 | 13.7 | 0.0 | 30.2 | 1674.9 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| MES-LSTM | LSTM | LGB | DeepAR | VARMAX | SARIMAX | MLR | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MIS | Coverage | MIS | Coverage | MIS | Coverage | MIS | Coverage | MIS | Coverage | MIS | Coverage | MIS | Coverage | |
| mean | 5785.9 | 79.8 | 10,713.1 | 97.4 | 97,311.6 | 84.7 | 9589.2 | 17.6 | 63,626.1 | 48.1 | 33,910.2 | 100.0 | 26,489.6 | 100.0 |
| std | 1714.1 | 15.1 | 3448.0 | 15.6 | 0.0 | 28.5 | 723.9 | 6.5 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Total Cases | Total Deaths | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LSTM | LGB | DeepAR | VARMAX | SARIMAX | MLR | LSTM | LGB | DeepAR | VARMAX | SARIMAX | MLR | |
| statistic | −6.014 | −1.448 | −190.477 | −63.342 | −250.673 | −95.605 | −7.906 | −10.891 | −389.954 | −578.058 | −836.515 | −325.283 |
| p-value | 0.000 | 0.077 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Total Cases | Total Deaths | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LSTM | LGB | DeepAR | VARMAX | SARIMAX | MLR | LSTM | LGB | DeepAR | VARMAX | SARIMAX | MLR | |
| statistic | 0.270 | −1.883 | −15.455 | 12.180 | −17.383 | 5.616 | −3.216 | −2.422 | −27.328 | −29.110 | −56.140 | −8.166 |
| p-value | 0.606 | 0.032 | 0.000 | 1.000 | 0.000 | 1.000 | 0.001 | 0.009 | 0.000 | 0.000 | 0.000 | 0.000 |
| Total Cases | Total Deaths | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LSTM | LGB | DeepAR | VARMAX | SARIMAX | MLR | LSTM | LGB | DeepAR | VARMAX | SARIMAX | MLR | |
| statistic | −5.328 | −25.791 | −2.851 | −22.095 | −34.220 | −25.119 | −2.299 | −37.924 | −10.070 | −40.222 | −20.029 | −14.501 |
| p-value | 0.000 | 0.000 | 0.004 | 0.000 | 0.000 | 0.000 | 0.013 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Total Cases | Total Deaths | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LSTM | LGB | DeepAR | VARMAX | SARIMAX | MLR | LSTM | LGB | DeepAR | VARMAX | SARIMAX | MLR | |
| statistic | −1.8770 | 1.6106 | 0.2267 | −2.7459 | −2.7459 | −2.7459 | −2.8639 | −0.2274 | 8.3710 | 3.5521 | −3.5613 | −3.5613 |
| p-value | 0.9666 | 0.0567 | 0.4110 | 0.9952 | 0.9952 | 0.9952 | 0.9968 | 0.5895 | 0.0000 | 0.0006 | 0.9994 | 0.9994 |
| Total Cases | Total Deaths | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LSTM | LGB | DeepAR | VARMAX | SARIMAX | MLR | LSTM | LGB | DeepAR | VARMAX | SARIMAX | MLR | |
| statistic | −19.817 | −277.776 | −144.279 | −12.665 | −16.160 | −8.048 | −5.567 | −374.711 | −112.500 | −7.066 | −11.817 | −43.647 |
| p-value | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mathonsi, T.; van Zyl, T.L. A Statistics and Deep Learning Hybrid Method for Multivariate Time Series Forecasting and Mortality Modeling. Forecasting 2022, 4, 1-25. https://doi.org/10.3390/forecast4010001
Mathonsi T, van Zyl TL. A Statistics and Deep Learning Hybrid Method for Multivariate Time Series Forecasting and Mortality Modeling. Forecasting. 2022; 4(1):1-25. https://doi.org/10.3390/forecast4010001
Chicago/Turabian StyleMathonsi, Thabang, and Terence L. van Zyl. 2022. "A Statistics and Deep Learning Hybrid Method for Multivariate Time Series Forecasting and Mortality Modeling" Forecasting 4, no. 1: 1-25. https://doi.org/10.3390/forecast4010001