
Abstract
With the advances in scientific foundations and technological implementations, optical metrology has become versatile problem-solving backbones in manufacturing, fundamental research, and engineering applications, such as quality control, nondestructive testing, experimental mechanics, and biomedicine. In recent years, deep learning, a subfield of machine learning, is emerging as a powerful tool to address problems by learning from data, largely driven by the availability of massive datasets, enhanced computational power, fast data storage, and novel training algorithms for the deep neural network. It is currently promoting increased interests and gaining extensive attention for its utilization in the field of optical metrology. Unlike the traditional âphysics-basedâ approach, deep-learning-enabled optical metrology is a kind of âdata-drivenâ approach, which has already provided numerous alternative solutions to many challenging problems in this field with better performances. In this review, we present an overview of the current status and the latest progress of deep-learning technologies in the field of optical metrology. We first briefly introduce both traditional image-processing algorithms in optical metrology and the basic concepts of deep learning, followed by a comprehensive review of its applications in various optical metrology tasks, such as fringe denoising, phase retrieval, phase unwrapping, subset correlation, and error compensation. The open challenges faced by the current deep-learning approach in optical metrology are then discussed. Finally, the directions for future research are outlined.
Similar content being viewed by others



Introduction
Optical metrology is the science and technology of making measurements with the use of light as standards or information carriers1,2,3. Light is characterized by its fundamental properties, namely, amplitude, phase, wavelength, direction, frequency, speed, polarization, and coherence. In optical metrology, these fundamental properties of light are ingeniously utilized as information carriers of a measurand, enabling a wide range of optical metrology tools that allow the measurement of a wide range of subjects4,5,6. For example, optical interferometry takes advantage of the wavelength of light as a precise dividing marker of length. The speed of light defines the international standard of length, the meter, as the length traveled in vacuum during a time interval of 1/299,792,458 of a second7. As a result, optical metrology is being increasingly adopted in many applications where reliable data about the distance, displacement, dimensions, shape, roughness, surface properties, strain, and stress state of the object under test are required8,9,10. Optical metrology is a broad and interdisciplinary field relating to diverse disciplines such as photomechanics, optical imaging, and computer vision. There is no strict boundary between those fields, and in fact, the term âoptical metrologyâ is often interchangeably used with âoptical measurementâ, in which achieving higher precision, sensitivity, repeatability, and speed is always a priority11,12.
There are a few inventions that revolutionized optical metrology. The first is the invention of laser13,14. The advent of laser interferometry could be traced back to experiments conducted independently in 1962 by Denisyuk15 and Leith and Upatnix16 with the objective of marrying coherent light produced by lasers with Gaborâs holography method17. The use of lasers as a light source in optical metrology marked the first time that such highly controlled light became available as a physical medium to measure the physical properties of samples, opening up new possibilities for optical metrology. The second revolution was initiated with the invention of charged coupled device (CCD) cameras in 1969, which replaced the earlier photographic emulsions by virtue of recording optical intensity signals from the measurand digitally8. The use of the CCD camera as a recording device in optical metrology represented another important milestone: the compatibility of light with electricity, i.e., âlightâ can be converted into âelectrical quantity (current, voltage, etc.)â. This means that the computational storage, access, analysis, and transmission of captured data are easily attainable, leading to the âdigital transitionâ of optical metrology. Computer-based signal processing tools were introduced to automate the quantitative determination of optical metrology data, eliminating the inconvenience associated with the manual, labor-intensive, time-consuming evaluation of fringe patterns18,19,20. Methods such as digital interferometry21, digital holography22, and digital image correlation (DIC)23 have become state of the art by now.
With the digital transition, image processing plays an essential role in optical metrology for the purpose of converting the observed measurements (generally displayed in the form of deformed fringe/speckle patterns) into the desired attributes (such as geometric coordinates, displacements, strain, refractive index, and others) of an object under study. Such information-recovery process is similar to those of computer vision and computational imaging, presenting as an inverse problem that is often ill-posed with respect to the existence, uniqueness, and stability of the solution24,25,26,27. Tremendous progress has been achieved in terms of accurate mathematical modeling (statistical models of noise and the observational data)28, regularization techniques29, numerical methods, and their efficient implementations30. For the field of optical metrology, however, the situation becomes quite different due to the fact that the optical measurements are frequently carried out in a highly controlled environment. Instead of explicitly interpreting optical metrology tasks from the perspective of solving inverse problems (based on a formal optimization framework), mainstream scientists in optical metrology prefer to bypass the ill-posedness and simplify the problem by means of active strategies, such as sample manipulation, system adjustment, and multiple acquisitions31. A typical example is the phase-shifting technique32, which sacrifices the time and effort of capturing multiple fringe patterns to exchange for a deterministic and straightforward solution. Under such circumstances, the phase retrieval problem is well-posed or even over-determined (when the phase-shifting step is larger than 3), and employing more evolved algorithms, such as compressed sensing33 and nonconvex (low-rank) regularization34 seem redundant and unnecessary, especially as they fail to demonstrate clear advantages over classical ones in terms of accuracy, adaptability, speed, and, more importantly, ease-of-use. This gives us the key question and motivation of this review paper: whether machine learning will be the driving force in optical metrology not only provides superior solutions to the growing new challenges but also tolerates imperfect measurement conditions with the least efforts, such as additive noise, phase-shifting error, intensity nonlinearity, motion, and vibration.
In the past few years, we have indeed witnessed the rapid progress on high-level artificial intelligence (AI), where deep representations based on convolutional and recurrent neural network models are learned directly from the captured data to solve many tasks in computer vision, computational imaging, and computer-aided diagnosis with unprecedented performance35,36,37. The early framework for deep learning was established on artificial neural networks (ANNs) in the 1980s38, yet only recently the real impact of deep learning became significant due to the advent of fast graphics processing units (GPUs) and the availability of large datasets39. In particular, deep learning has revolutionized the computer vision community, introducing non-traditional and effective solutions to numerous challenging problems such as object detection and recognition40, object segmentation41, pedestrian detection42, image super-resolution43, as well as medical image-related applications44. Similarly, in computational imaging, deep learning has led to rapid growth in algorithms and methods for solving a variety of ill-posed inverse computational imaging problems45, such as super-resolution microscopy46, lensless phase imaging47, computational ghost imaging48, and image through scattering media49. In this context, researchers in optical metrology have also made significant explorations in this regard with very promising results within just a few short years, as evidenced by the ever-increasing and the respectable number of publications50,51,52,53,54,55. Meanwhile, those research works are scattered rather than systematic, which gives us the second motivation to provide a comprehensive review to understand their principles, implementations, advantages, applications, and challenges. It should be noted that optical metrology covers a wide range of methods and applications today. It would be beyond the scope of this review to discuss all relevant technologies and trends. We, therefore, restrict our focus to phase/correlation measurement techniques, such as interferometry, holography, fringe projection, and DIC. Although phase retrieval and wave-field sensing technologies, such as defocus variation (GerchbergâSaxtonâFienup-type methods56,57), transport of intensity equation (TIE)58,59, aperture modulation60, ptychography61,62, and wavefront sensing (e.g., ShackâHartmann63, Pyramid64, and computational shear interferometry65), has been recently introduced to optical metrology66,67,68, they may be more appropriately placed in the field of âcomputational imagingâ. The reader is referred to the earlier review by Barbastathis et al.45 for more detailed information on this topic. It is also worth mentioning that (passive) stereovision, which extracts depth information from stereo images, is an important branch of photogrammetry that has been extensively studied by the computer vision community. Although stereovision techniques do not strictly fall into the category of optical metrology, due to the fact that many ideas and algorithms in DIC and fringe projection were âborrowedâ from stereovision, they are also included in this review.
The remainder of this review is organized as follows. We start by summarizing the relevant foundations and image formation models of different optical metrology approaches, which are generally required as a priori knowledge in conventional optical metrology methods. Next, we present a general hierarchy of the image-processing algorithms that are most commonly used in conventional optical metrology in the âImage processing in optical metrologyâ section. After a brief introduction to the history and basic concept of deep learning, we recapitulate the advantages of using deep learning in optical metrology tasks by interpreting the concept as an optimization problem. We then present a recollection of the deep learning methods that have been proposed in optical metrology, suggesting the pervasive penetration of deep learning in almost all aspects of the image-processing hierarchy. The âChallengesâ section discusses both technical and implementation challenges faced by the current deep-learning approach in optical metrology. In the âFuture directionsâ section, we give our outlook for the prospects for deep learning in optical metrology. Finally, conclusions and closing remarks are given in the âConclusionsâ section.
Image formation in optical metrology
Optical metrology methods often form images (e.g., fringe/speckle patterns) for processing. Thus image formation is essential to reconstruct various quantities. In most interferometric metrological methods, the image is formed by the coherent superposition of the object and reference beams. As a result, the raw intensity across the object is modulated by a harmonic function, resulting in the bright and dark contrasts, known as fringe patterns. A typical fringe pattern can be written as18,19
where (x, y) refers to the spatial coordinates along the horizontal and vertical directions, A(x, y) is the background intensity, B(x, y) is the fringe amplitude, Ï(x, y) is the phase distribution. In most cases, phase is the primary quantity of the fringe pattern to be retrieved as it is related to the final object quantities of interest, such as surface shape, mechanical displacement, 3D coordinates, and their derivations. The related techniques include classical interferometry, photoelasticity, holographical interferometry, digital holography, etc. On a different note, the fringe patterns can also be created noninterferometrically by overlapping of two periodic gratings as in geometric moiré, or incoherent projection of structured patterns onto the object surface as in fringe projection profilometry (FPP)/deflectometry. As summarized in Fig. 1, though the final fringe patterns obtained in all forms of fringe-based techniques discussed herein are similar in form, the physics behind the image formation process and the meanings of the fringe parameters are different. In DIC, the measured intensity images are speckle patterns of the specimen surface before and after deformation,
where \(\left( {D_x(x,y),D_y(x,y)} \right)\) refers to the displacement vector-field mapping from the undeformed/reference pattern Ir(x, y) to the deformed one Id(x, y). It directly provides full-field displacements and strain distributions of the sample surface. The DIC technique can also be combined with binocular stereovision or stereophotogrammetry to recover depth and out-of-plane deformation of the surface from the displacement field (so-called disparity) by exploiting the unique textures present in two or more images of the object taken from different viewpoints. The image formation processes for typical optical metrology methods are briefly described as follows.
-
(1)
Classical interferometry: In classical interferometry, the fringe pattern is formed by superimposition of two smooth coherent wavefronts, one of which is typically a flat or spherical reference wavefront and the other a distorted wavefront formed and directed by optical components69,70 (Fig. 1a). The phase of the fringe pattern reflects the difference between the ideal reference wavefront and object wavefront. Typical examples of classical interferometry include the use of configurations such as the Michelson, Fizeau, Twyman Green, and Mach-Zehnder interferometers to characterize the surface, aberration, or roughness of optical components with high accuracy, of the order of a fraction of the wavelength.
-
(2)
Photoelasticity: Photoelasticity is a nondestructive, full-field, optical metrology technique for measuring the stress developed in transparent objects under loading71,72. Photoelasticity is based on an optomechanical property, so-called âdouble refractionâ or âbirefringenceâ observed in many transparent polymers. Combined with two circular polarizers (linear polarizer coupled with quarter waveplate) and illuminated with a conventional light source, a loaded photoelastic sample (or photoelastic coating applied to an ordinary sample) can produce fringe patterns whose phases are associated with the difference between the principal stresses in a plane perpendicular to the light propagation direction73 (Fig. 1b).
-
(3)
Geometric moiré/Moiré interferometry: In optical metrology, the moiré technique is defined as the utilization of the moiré phenomenon to measure shape, deformation, or displacements of surfaces74,75. A moiré pattern is formed by the superposition of two periodic or quasi-periodic gratings. One of these gratings is called reference grating, and the other one is object grating mounted or engraved on the surface to be studied, which is subjected to distortions induced by surface changes. For in-plane displacement and strain measurements, moiré technology has evolved from low-sensitivity geometric moiré75,76,77 to high-sensitivity moiré interferometry75,78. In moiré interferometry, two collimated coherent beams interfere to produce a virtual reference grating with high frequencies, which interacts with the object grating to create the moiré pattern with fringes representing subwavelength in-plane displacements per contour (Fig. 1c).
-
(4)
Holographic interferometry: Holography, invented by Gabor17 in the 1940âs, is a technique that records an interference pattern and uses diffraction to reproduce a wavefront, resulting in a 3D image that still has the depth, parallax, and other properties of the original scene. The principle of holography can also be utilized as an optical metrology tool. In holographic interferometry, a wavefront is first stored in the hologram and later interferometrically compared with another, producing fringe patterns that yield quantitative information about the object surface deriving these two wavefronts79,80. This comparison can be made in three different ways that constitute the basic approaches of holographic interferometry: real-time81, double-exposure82, and time-average holographic interferometry83,84 (Fig. 1d), allowing for both qualitative visualization and quantitative measurement of real-time deformation and perturbation, changes of the state between two specific time points, and vibration mode and amplitude, respectively.
-
(5)
Digital holography: Digital holography utilizes a digital camera (CMOS or CCD) to record the hologram produced by the interference between a reference wave and an object wave emanating from the sample85,86 (Fig. 1e). Unlike classical interferometry, the sample may not be precisely in-focus and can even be recorded without using any imaging lenses. The numerical propagation using Fresnel transform or angular spectrum algorithm enables digital refocusing at any depths of the sample without physically moving it. In addition, digital holography also provides an alternative and much simpler way to realize double-exposure87 and time-averaged holographic interferometry88,89, without additional benefits of quantitative evaluation of holographic interferograms and flexible phase-aberration compensation86,90.
-
(6)
Electronic speckle pattern interferometry (ESPI): In ESPI, the tested object generally has an optically rough surface. When illuminated by a coherent laser beam, it will create a speckle pattern with random phase, amplitude, and intensity91,92. If the object is displaced or deformed, the object-to-image distance will change, and the phase of the speckle pattern will change accordingly. In ESPI, two speckle patterns are acquired one each for the undeformed and deformed states, by double exposure, and the absolute difference between these two deformed patterns results in the form of fringes superimposed on the speckle pattern where each fringe contour normally represents a displacement of half a wavelength (Fig. 1f).
-
(7)
Electronic speckle shearing interferometry (shearography): Electronic speckle shearing interferometry, commonly known as shearography, is an optical measurement technique similar to ESPI. However, instead of using a separate known reference beam, shearography uses the test object itself as the reference; and the interference pattern is created by two sheared speckle fields originated from the light scattered by the surface of the object under test93,94. In shearography, the phase encoded in the fringe pattern depicts the derivatives of the surface displacements, i.e., to the strain developed on the object surface (Fig. 1g). Consequently, the anomalies or defects on the surface of the object can be revealed more prominently, rendering shearography one of the most powerful tools for nondestructive testing applications.
-
(8)
Fringe projection profilometry/deflectometry: Fringe projection is a widely used noninterferometic optical metrology technique for measuring the topography of an object at a certain angle between the observation and the projection point95,96. The sinusoidal pattern in fringe projection techniques is generally incoherently formed by a digital video projector and directly projected onto the object surface. The corresponding distorted fringe pattern is recorded by a digital camera. The average intensity and intensity modulation of the captured fringe pattern are associated with the surface reflectivity and ambient illuminations, and the phase is associated with the surface height32 (Fig. 1h). Deflectometry is another structured light technique similar to FPP, but instead of being produced by a projector, similar types of fringe patterns are displayed on a planar screen and distorted by the reflective (mirror-like) test surface97,98. The phase measured in deflectometry is directly sensitive to the surface slope (similar to shearography), so it is more effective for detecting shape defects99,100.
-
(9)
Digital image correction (DIC)/stereovision: DIC is another important noninterferometic optical metrology method that employs image correlation techniques for measuring full-field shape, displacement, and strains of an object surface23,101,102. Generally, the object surface should have a random intensity distribution (i.e., a random speckle pattern), which distorts together with the sample surface as a carrier of deformation information. Images of the object at different loadings are captured with one (2D-DIC)23, or two synchronized cameras (3D-DIC)103, and then these images are analyzed with correlation-based matching (tracking or registration) to extract full-field displacement and strain distributions (Fig. 1i). Unlike 2D-DIC that is limited to in-plane deformation measurement of nominal planar objects, 3D-DIC, also known as stereo-DIC, allows for the measurement of 3D displacements (both in-plane and out-of-plane) for both planar and curved surfaces104,105. 3D-DIC is inspired by binocular stereovision or stereophotogrammetry in the computer vision community, which recovers the 3D coordinates by finding pixel correspondence (i.e., disparity) of unique features that exist in two or more images of the object taken from different points of view106,107. Nevertheless, unlike DIC, in which the displacement vector can be along both x and y directions, in stereophotogrammetry, after epipolar rectification, disparities between the images are along the x direction only108.

a Classical interferometry. b Photoelasticity. c Geometric moiré and moiré interferometry. d Holographic interferometry. e Digital holography. f Electronic speckle shearing interferometry (ESPI). g Shearography. h Fringe projection profilometry (FPP) and deflectometry. i Digital image correlation (DIC) and stereovision
Image processing in optical metrology
The elementary task of digital image processing in optical metrology can be defined as the conversion of the captured raw intensity image(s) into the desired object quantities taking into account the physical model of the intensity distribution describing the image formation process. In most cases, image processing in optical metrology is not a one-step procedure, and a logical hierarchy of image processing steps should be accomplished. As illustrated in Fig. 2, the image-processing hierarchy typically encompasses three main steps, pre-processing, analysis, and postprocessing, each of which includes a series of mapping functions that are cascaded to form a pipeline structure. For each operation, the corresponding f is an operator that transforms the image-like input into an output of corresponding (possibly resampled) spatial dimensions. Figure 3 shows the big picture of the image-processing hierarchy with various types of algorithms distributed in different layers. Next, we will zoom in one level deeper on each of the hierarchical steps.

The pipeline of a typical optical metrology method (e.g., FPP) encompasses a sequence of distinct operations (algorithms) to process and analyze the image data, which can be further categorized into three main steps: pre-processing (e.g., denoising, image enhancement), analysis (e.g., phase demodulation, phase unwrapping), and postprocessing (e.g., phase-depth mapping)

Image processing in optical metrology is not a one-step procedure. Depending on the purpose of the evaluation, a logical hierarchy of processing steps should be implemented before the desired information can be extracted from the image. In general, the image processing architecture in optical metrology consists of three main steps: pre-processing, analysis, and post-processing.
Pre-processing
The purpose of pre-processing is to assess the quality of the image data and improve the data quality by suppressing or minimizing unwanted disturbances (noise, aliasing, geometric distortions, etc.) before being fed to the following image analysis stage. It takes place at the lowest level (so-called iconic level) of image processing âthe input and output of the corresponding mapping function(s) are both intensity images, i.e., \(f_{anal}:I \to I^\prime\). Representative image pre-processing algorithms in optical metrology includes but not limited to:
-
Denoising: In optical metrology, noise in captured raw intensity data has several sources that are related to the electronic noise of photodetectors and the coherent noise (so-called speckle). Typical numerical approaches to noise reduction include median filter109, spin filter110, anisotropic diffusion111, coherence diffusion112, Wavelet113, windowed Fourier transform (WFT)114,115, block matching 3D (BM3D)116, etc. For more detailed information and comparisons of these algorithms, the reader may refer to the reviews by Kulkarnia and Rastogi117 and Bianco et al.118.
-
Enhancement: Image enhancement is a crucial pre-processing step in intensity-based fringe analysis approaches, such as fringe tracking or skeletonizing. Referring to the intensity model, the fringe pattern may still be disturbed by locally varying background and intensity modulation after denoising. Several algorithms have been developed for fringe pattern enhancement, e.g., adaptive filter119, bidimensional empirical mode decomposition120,121, and dual-tree complex wavelet transform122.
-
Color channel separation: Because a Bayer color sensor-camera captures three monochromatic (red, green, and blue) images at once, color multiplexing techniques are often employed in optical metrology to speed up the image acquisition process123,124,125,126,127. However, the separation of three color channels is not so straightforward due to the coupling and imbalance among the three color channels. Many cross-talk-matrix-based color channel calibration and leakage correction algorithms have been proposed to minimize such side effects128,129,130.
-
Image registration and rectification: Image registration and rectification are aimed at aligning two or more images of the same object to a reference or correcting image distortion due to lens aberration. In stereophotogrammetry, epipolar (stereo) rectification determines a reprojection of each image plane so that pairs of conjugate epipolar lines in both images become collinear and parallel to one of the image axes108.
-
Interpolation: Image interpolation algorithms, such as the nearest neighbor, bilinear, bicubic109, and nonlinear regression131 are necessary when the measured intensity image is sampled at an insufficient dense grid. In DIC, to reconstruct displacements with subpixel accuracy, the correlation criterion must be evaluated at non-integer-pixel locations132,133,134. Therefore, image interpolation is also a key algorithm for DIC to infer subpixel gray values and gray-value gradients in many subpixel displacement registration algorithms, e.g., the NewtonâRaphson method133,134,135.
-
Extrapolation: Image extrapolation, especially fringe extrapolation is often employed in Fourier transform (FT) fringe analysis methods to minimize the boundary artifacts induced by spectrum leakage. Schemes for the extrapolation of the fringe pattern beyond the borders have been reported, such as soft-edged frequency filter136 and iterative FT137.
Analysis
Image analysis is the core component of the image-processing architecture to extract the key information-bearing parameter(s) reflecting the desired physical quantity being measured from the input images. In phase measurement techniques, image analysis refers to the reconstruction of phase information from the fringe-like modulated intensity distribution(s), i.e., \(f_{anal}:I \to \phi\).
-
Phase demodulation: The aim of phase demodulation, or more specifically, fringe analysis, is to obtain the wrapped phase map from the quasi-periodic fringe patterns. Various techniques for fringe analysis have been developed to meet different requirements in diverse applications, which can be broadly classified into two categories:
-
Spatial phase demodulation: Spatial phase-demodulation methods are capable of estimating the phase distribution through a single-fringe pattern. FT138,139, WFT114,115,140, and wavelet transform (WT)141 are classical methods for the spatial carrier fringe analysis. For closed-fringe patterns without the carrier, alternative methods, such as Hilbert spiral transform142,143, regularized phase tracking (RPT)144,145 and frequency-guided sequential demodulation146,147, can be applied provided that the cosinusoidal component of the fringe pattern can be extracted by pre-processing algorithms of denoising, background removal, and fringe normalization. The interested reader may refer to the book by Servin et al.148 for further details.
-
Temporal phase demodulation: Temporal phase-demodulation techniques detect the phase distribution from the temporal variation of fringe signals, as typified by heterodyne interferometry149 and phase-shifting techniques150. Many phase-shifting algorithms have originally been proposed for optical interferometry/holography and later been adapted and extended to fringe projection, for example, standard N-step phase-shifting algorithm151, Hariharan 5-step algorithm21, 2â+â1 algorithm152 etc. The interested reader may refer to the chapter âPhase shifting interferometryâ153 of the book edited by Malacara4 and the review article by Zuo et al.32 for more details about phase-shifting techniques in the contexts of optical interferometry and FPP, respectively.
-
-
Phase unwrapping: No matter which phase-demodulation technique is used, the retrieved phase distribution is mathematically wrapped to the principal value of the arctangent function ranging between âÏ and Ï. The result is what is known as a wrapped phase image, and phase unwrapping has to be performed to remove any 2Ï-phase discontinuities. Phase unwrapping algorithms can be broadly classified into three categories:
-
Spatial phase unwrapping: Spatial phase unwrapping methods use only a single wrapped phase map to retrieve the corresponding unwrapped phase distribution, and the unwrapped phase of a given pixel is derived based on the adjacent phase values. Representative methods include Goldsteinâs method154, reliability-guided method155, Flynnâs method156, minimal Lp-norm method157, and phase unwrapping max-flow/min-cut (PUMA) method158. The interested reader may refer to the book by Ghiglia et al. for more technical details. There are also many reviews on the performance comparisons of different unwrapping algorithms for specific applications159,160,161. Limited by the assumption of phase continuity, spatial phase unwrapping methods cannot fundamentally address the inherent fringe order ambiguity problem when the phase difference between neighboring pixels is greater than Ï.
-
Temporal phase unwrapping: To remove the phase ambiguity, temporal phase unwrapping methods generally generate different or synthetic wavelengths by adjusting flexible system parameters (wavelength, angular separation of light sources, spatial frequency, orientation of the projected fringe patterns) step by step, so that the object can be covered by fringes with different periods. Representative temporal phase unwrapping algorithms include gray-code methods162,163, multi-frequency (hierarchical) methods164,165,166, multi-wavelength (heterodyne) methods167,168,169, and number-theoretical methods170,171,172,173. For more detailed information about these methods, the reader can refer to the comparative review by Zuo et al.174 The advantage of temporal phase unwrapping lies in that the unwrapping is neighborhood-independent and proceeds along the time axis on the pixel itself, enabling an absolute evaluation of the mod-2Ï phase distribution.
-
Geometric phase unwrapping: Geometric phase unwrapping approaches can solve the phase ambiguity problem by exploiting the epipolar geometry of projectorâcamera systems. If the measurement volume can be predefined, depth constraints can be incorporated to preclude some phase ambiguities corresponding to the candidates falling out of the measurement range175,176,177,178,179,180,181,182,183,184,185. Alternatively, an adaptive depth-constraint strategy can provide pixel-wise depth constraint ranges according to the shape of the measured object186. By introducing more cameras, tighter geometry constraints can be enforced so as to guarantee the unique correspondence and improve the unwrapping reliability185,187.
-
In stereomatching techniques, image analysis refers to determining (tracking or matching) the displacement vector of each pixel point between a pair of acquired images, i.e., \(f_{anal}:(I_r,I_d) \to (D_x,D_y)\). In the routine implementation for DIC and stereophotogrammetry, a region of interest (ROI) or subset in the image is specified at first. The subset is further divided into an evenly spaced virtual grid. The similarity is evaluated at each point of the virtual grid in the reference image to obtain the displacement between two subsets. A full-field displacement map can be obtained by sliding the subset in the searching area of the reference image and obtaining the displacement at each location.
-
Subset correlation: In DIC, to quantitatively evaluate the similarity or difference between the selected reference subset and the target subset, several correlation criteria have been proposed, such as cross-correlation (CC), the sum of absolute difference (SAD), the sum of squared difference (SSD), zero-mean normalized cross-correlation criterion (ZNCC), zero-mean normalized sum of squared difference (ZNSSD), and the parametric sum of squared difference (PSSD)188,189,190. The subsequent matching procedure is realized by identifying the peak (or valley) position of the correlation coefficient distribution based on certain optimization algorithms. In stereophotogrammetry, nonparametric costs rely on the local ordering (i.e., Rank191, Census192, and Ordinal measures193) of intensity values, which are more frequently used due to their robustness against radiometric changes and outliers, especially near object boundaries192,193,194.
-
Subpixel refinement: The subset correlation methods mentioned above can only provide integer-pixel displacements. To further improve the measurement resolution and accuracy, many subpixel refinement methods were developed, including intensity interpolation (i.e., the coarseâfine search method)195,196, correlation coefficient curve-fitting133,197, gradient-based method198,199, NewtonâRaphson (NR) algorithm135,200,201, and inverse compositional GaussâNewton (IC-GN) algorithm202,203,204. Among these algorithms, NR and IC-GN are most commonly used for their high registration accuracy and effectiveness in handling high-order surface transformations. However, they suffer from expensive computation cost stemming from their iterative nonlinear optimization and repeated subpixel interpolation. Therefore, accurate initial guesses obtained by integer-pixel subset correlation methods are critical to ensure the rapid convergence205 and reduce the computational cost206. In stereovision, the matching algorithms can be classified as local207,208,209, semi-global210, and global methods211. Local matching methods utilize the intensity information of a local subset centered at the pixel to be matched. Global matching methods take the result obtained by local matching methods as the initial value and then optimize the disparity by minimizing a predefined global energy function. Semi-global matching methods reduce the 2D global energy minimization problem into a 1D one, enabling faster and more efficient implementations of stereomatching.
Postprocessing
In optical metrology, the main task of postprocessing is to further refine the measured phase or retrieved displacement field, and finally transform them into the desired physical quantity of the measured object, i.e., the corresponding operator \(f_{post}:\phi {{{\mathrm{/}}}}(D_x,D_y) \to q\), where q is the desired sample quantity.
-
Denoising: Instead of applying to raw fringe patterns, image denoising can also be used as a postprocessing algorithm to remove noise directly from the retrieved phase distribution. Various phase denoising algorithms have been proposed, such as least-square (LS) fitting212, anisotropic average filter213, WFT214, total variation215, and nonlocal means filter216.
-
Digital refocusing: The numerical reconstruction of propagating wavefronts by diffraction is a unique feature of digital holography. Since the hologram of the object may not be recorded in the in-focus plane. Numerical diffraction or backpropagation algorithms (e.g., Fresnel diffraction and angular spectrum methods) should be used to obtain a focused image by performing a plane-by-plane refocusing after the image acquisition217,218,219.
-
Error compensation: There are various types of phase errors associated with optical metrology systems, such as phase-shifting error, intensity nonlinearity, and motion-induced error, which can be compensated with different types of postprocessing algorithms60,220,221. In digital holographic microscopy, the microscope objective induces additional phase curvature on the measured wavefront, which needs to be compensated in order to recover the phase information induced by the sample. Typical numerical phase-aberration compensation methods include double exposure222, 2D spherical fitting223 Zernike polynomials fitting224, Fourier spectrum filtering225, and principal component analysis (PCA)226.
-
Quantity transformation: The final step of postprocessing and also the whole measurement chain is to convert the phase or displacement field into the desired sample quantity, such as height, thickness, displacement, stress, strains, and 3D coordinates, based on sample parameters (e.g., refractive index, relative stress constant) or calibrated system parameters (e.g., sensitivity vector and camera (intrinsic, extrinsic) parameters). The optical setup should be carefully designed to optimize the sensitivity with respect to the measuring quantity in order to achieve a successful and efficient measurement227,228.
Finally, it should be mentioned that since optical metrology is a rapidly expanding field in both its scientific foundations and technological developments, the image-processing hierarchy used here cannot provide full coverage of all relevant methods and technologies. For example, phase retrieval and wave-field sensing technologies have shown great promise for inexpensive, vibration-tolerant, non-interferometric, optical metrology of optical surfaces and systems66,67. These methods constitute an important aspect of computational imaging as they often involve solving ill-posed inverse problems. There are also some optical metrology methods based on solving constrained optimization problems with added penalties and relaxations (e.g., RPT phase demodulation144,145 and minimal Lp-norm phase unwrapping methods157), which may make pre- and postprocessing unnecessary. For a detailed discussion on this topic, please refer to the subsection âSolving inverse optical metrology problems: issues and challengesâ.
Brief introduction to deep learning
Deep learning is a subset of machine learning, which is defined as the use of specific algorithms that enable machines to automatically learn patterns from large amounts of historical data, and then utilize the uncovered patterns to make predictions about the future or enable decision making under uncertain intelligently229,230. The key specific algorithm used in machine learning is the ANN, which exploits input data \({{{\mathbf{x}}}} \in {{{\mathcal{X}}}} \subseteq {\Bbb R}^n\) to predict an unknown output \({{{\mathbf{y}}}} \in {{{\mathcal{Y}}}}\). The tasks accomplished by the ANN can be broadly divided as classification tasks or regression tasks, depending on whether y is a discrete label or a continuous value. The objective of machine learning is then to find a mapping function \(f:{{{\mathbf{x}}}} \to {{{\mathbf{y}}}}\). The choice of such functions is given by the neural network models with additional parameters \({{{\mathbf{\theta }}}} \in \Theta\): i.e., \({{{\hat{\mathbf y}}}} = f\left( {{{{\mathbf{x}}}},{{{\mathbf{\theta }}}}} \right) \approx {{{\mathbf{y}}}}\). The goal of this section is to provide a brief introduction to deep learning, as a preparation for the introduction of its applications in optical metrology later on.
Artificial neural network (ANN)
Inspired by the biological neural network (Fig. 4a), ANNs are composed of interconnected computational units called artificial neurons. As illustrated in Fig. 4b, the simplest neural network following the above concept is the perceptron, which consists of only one single artificial neuron231. An artificial neuron takes a bias b and weight vector \({{{\mathbf{w}}}} = \left( {w_1,w_2, \cdots ,w_n} \right)^T\) as parameters \({{{\mathbf{\theta }}}} = \left( {b,w_1,w_2, \cdots ,w_n} \right)^T\) to map the input \({{{\mathbf{x}}}} = \left( {x_1,x_2, \cdots ,x_n} \right)^T\) to the output \(f_P\left( {{{\mathbf{x}}}} \right)\) through a nonlinear activation function Ï as

a Biological neuron model458. b The single-layer perceptron: an artificial neuron calculates the weighted sum (â) of the inputs (based on weights θ1âââθn), and maps them to the output through an activation function. c CNN: convolutional neural network, consists of input layer, convolution layer, pooling layer, full connection layer and output layer. d RNN: recurrent neural network, the input of the hidden layer includes not only the output of the input layer but also the output of the hidden layer at the previous moment. e RBM: Restricted Boltzmann Machines, an undirected probability graph model with an input layer and a hidden layer. f DBM: Deep Boltzmann Machine, consists of several RBM units stacked. The connections between all layers are undirected. g DBN: Deep Belief Network, consists of several DBM units stacked. The connection between the right two layers is undirected, while other connections are directed. h Residual block: consists of two sets of convolutional layers activated by ReLU stacked one above the other
Typical choices for such activation functions are the sign function \(\sigma \left( x \right) = sgn\left( x \right)\), sigmoid function \(\sigma \left( x \right) = \frac{1}{{1\, + \,e^{ - x}}}\), hyperbolic tangent function \(\sigma \left( x \right) = \frac{{e^x\, - \,e^{ - x}}}{{e^x\, + \,e^{ - x}}}\), and rectified linear unit (ReLU) \(\sigma \left( x \right) = \max \left( {0,x} \right)\)232. A single perceptron can only model a linear function, but because of the activation functions and in combination with other neurons, the modeling capabilities will increase dramatically. Arranged in a single layer, it has already been shown that neural networks can approximate any continuous function f(x) on a compact subset of \({\Bbb R}^n\). A single-layer network, also called single-layered perceptron (SLP), is represented as a linear combination of M individual neurons:
where vi is the combination weight of the ith neuron. We can further extend the mathematical specification of SLP by stacking several single-layer networks into a multi-layered perceptron (MLP)233. As the network goes deeper (number of layers increase), the number of free parameters increases, as well as the capability of the network to represent highly nonlinear functions234. We can formalize this mathematically by stacking several single-layer networks into a deep neural network (DNN) with N layers, i.e.
where the circle ⦠is the symbol for the composition of functions. The first layer is referred to as the input layer, the last as the output layer, and the layers in between the input and output are termed as hidden layers. We refer to these using the term âdeepâ, when a neural network contains many hidden layers, hence the term âdeep learningâ.
Neural network training
Having gained basic insights into neural networks and their basic topology, we still need to discuss how to train the neural network, i.e., how its parameters θ are actually determined. In this regard, we need to select the appropriate model topology for the problem to be solved and specify the various parameters associated with the model (known as âhyper-parametersâ). In addition, we need to define a function that assesses the quality of the network parameter set θ, the so-called loss function L, which quantifies the error between the predicted value \({{{\hat{\mathbf y}}}} = f_{{{\mathbf{\theta }}}}\left( {{{\mathbf{x}}}} \right)\) and the true observation y (label)235.
Depending on the type of task accomplished by the network, the loss function can be divided into classification loss and regression loss. Commonly used classification loss functions include hinge loss (\(L_{Hinge} = \mathop {\sum}\nolimits_{i = 1}^n {\max [0,1 - {{{\mathrm{sgn}}}}(y_i)\hat y_i]}\)) and cross-entropy loss \(L_{CE} = - \mathop {\sum}\nolimits_{i = 1}^n {[y_i\log \hat y_i + (1 - y_i)\log (1 - \hat y_i)]}\))236. Since the optical metrology tasks involved in this review mainly belong to regression tasks, here we focus on the regression loss functions. The mean absolute error (MAE) loss (\(L_{MAE} = \frac{1}{n}\mathop {\sum}\nolimits_{i = 1}^n {\left| {y_i - \hat y_i} \right|}\)) and the mean squared error (MSE) loss (\(L_{MSE} = \frac{1}{n}\mathop {\sum}\nolimits_{i = 1}^n {(y_i - \hat y_i)^2}\)) are the two most commonly used loss functions, which are also known as L1 loss and L2 loss, respectively. In image-processing tasks, MSE is usually converted into a peak signal-to-noise ratio (PSNR) metric: \(L_{PSNR} = 10\,{{{\mathrm{log}}}}_{10}\frac{{MAX^2}}{{L_{MSE}}}\), where MAX is the maximum pixel intensity value within the dynamic range of the raw image237. Other variants of L1 and L2 loss include RMSE, Euclidean loss, smooth L1, etc.238. For natural images, the structural similarity (SSIM) index is a representative image fidelity measurement, which judges the structural similarity of two images based on three metrics (luminance, contrast, and structure): \(L_{SSIM} = l({{{\mathbf{y}}}},\widehat {{{\mathbf{y}}}})c({{{\mathbf{y}}}},\widehat {{{\mathbf{y}}}})s({{{\mathbf{y}}}},\widehat {{{\mathbf{y}}}})\)239, where \(l({{{\mathbf{y}}}},\widehat {{{\mathbf{y}}}})\), \(c({{{\mathbf{y}}}},\widehat {{{\mathbf{y}}}})\), and \(s({{{\mathbf{y}}}},\widehat {{{\mathbf{y}}}})\) are the similarities of the local patch luminances, contrasts, and structures, respectively. For more details about these loss functions, readers may refer to the article by Wang and Bovik240. With the defined loss function, the objective behind the training process of ANNs can be formalized as an optimization problem241
The learning schemes can be broadly classified into three categories, supervised learning, semi-supervised learning, and unsupervised learning36,242,243,244. Supervised learning dominates the majority of practical applications, in which a neural network model is optimized based on a large amount dataset of labeled data pairs (x, y), and the training process amounts to find the model parameters \(\widehat {{{\mathbf{\theta }}}}\) that best predict the data based on the loss function \(L\left( {\widehat {{{\mathbf{y}}}},{{{\mathbf{y}}}}} \right)\). In unsupervised learning, training algorithms process input data x without corresponding labels y, and the underlying structure or distribution in the data has to be modeled based on the input itself. Semi-supervised learning sits in between both supervised and unsupervised learning, where a large amount of input data x is available and only some of the data is labeled. More detailed discussions about semi-supervised and unsupervised learning can be found in the âFuture directionsâ section.
From perceptron to deep learning
As summarized in Fig. 4, despite the overall upward trend, a broader look at the history of deep learning reveals three major waves of development. Concepts of machine learning and deep learning commenced with the research into the artificial neural network, which was originated from the simplified mathematical model of biological neurons established by McCulloch and Pitts in 1943245. In 1958, Rosenblatt231 proposed the idea of perceptron, which was the first ANN that allows neurons to learn. The emergence of perceptron marked the first peak of neural network development. However, a single-layer perceptron model can only solve linear classification problems and cannot solve simple XOR and XNOR problems246. These limitations caused a major dip in their popularity and stagnated the development of neural networks for nearly two decades.
In 1986, Rumelhart et al.247 proposed the idea of a backpropagation algorithm (BP) for MLP, which constantly updates the network parameters to minimize the network loss based on a chain rule method. It effectively solves the problems of nonlinear classification and learning, leading neural networks into a second development phase of âshallow learningâ and promoting a boom of shallow learning. Inspired by the mammalian visual cortex (stimulated in the restricted visual field)248, LeCun et al.249 proposed the biologically inspired CNN model based on the BP algorithm in 1989, establishing the foundation of deep learning for modern computer vision. During this wave of development, various models like long short-term memory (LSTM) recurrent neural network (RNN), distributed representation, and processing were developed and continue to remain key components of various advanced applications of deep learning to this date. Adding more hidden layers to the network allows a deep architecture to be built, which can accomplish more complex mappings. However, training such a deep network is not trivial because once the errors are back-propagated to the first few layers, they become negligible (so-called gradient vanishing), making the learning process very slow or even fails250. Moreover, the limited computational capacity of the available hardware at that time could not support training large-scale neural networks. As a result, deep learning suffered a second major roadblock.
In 2006, Hinton et al.251,252 proposed a Deep Belief Network (DBN) (the composition of simple, unsupervised networks such as Deep Boltzmann Machines (DBMs)253 (Fig. 4f) or Restricted Boltzmann Machines (RBMs)254 (Fig. 4e)) training approach based on the brain graphical models, trying to overcome the gradient-vanishing problem. They gave the new name âdeep learningâ to multilayer neural network-related learning methods251,252. This milestone revolutionized the approaching prospects in machine learning, leading neural networks into the third upsurge along with the development of computer hardware performance, the development of GPU acceleration technology, and the availability of massive labeled datasets.
In 2012, Krizhevsky et al.255 proposed a deep CNN architecture â AlexNet, which won the 2012 ImageNet competition, making CNN249,256 become the dominant framework for deep learning after more than 20 years of silence. Meanwhile, several new deep-learning network architectures and training approaches (e.g., ReLU232 given by \(\sigma (x) = \max (0,x)\), and Dropout257 that discards a small but random portion of the neurons during each iteration of training to prevent neurons from co-adapting to the same features) were developed to further combat the gradient vanishing and ensure faster convergence. These factors have led to the explosive growth of deep learning and its applications in image analysis and computer vision-related problems. Different from CNN, RNN is another popular type of DNN inspired by the brainâs recurrent feedback system. It provides the network with additional âmemoryâ capabilities for previous data, where the inputs of the hidden layer consist of not only the current input but also the output from the previous step, making it a framework specialized in processing sequential data258,259,260 (Fig. 4d). CNNs and RNNs usually operate on Euclidean data like images, videos, texts, etc. With the diversification of data, some non-Euclidean graph-structured data, such as 3D-point clouds and biological networks, are also considered to be processed by deep learning. Graph neural networks (GNNs), where each node aggregates feature vectors of its neighbors to compute its new feature vector (a recursive neighborhood aggregation scheme), are effective graph representation learning frameworks specifically for non-Euclidean data261,262.
With the focus of more attention and efforts from both academia and industry, different types of deep neural networks have been continuously proposed in recent years with exponential growth, such as VGGNet263 (VGG means âVisual Geometry Groupâ), GoogLeNet264 (using âGoogLeâ instead of âGoogleâ is a tribute to LeNet, one of the earliest CNNs developed by LeCun256), R-CNN (regions with CNN features)265, generative adversarial network (GAN)266, etc. In 2015, the emergence of the residual block (Fig. 4h), containing two convolutional layers activated by ReLU that allow the information (from the input or those learned in earlier layers) to penetrate more into the deeper layers, significantly reduces the vanishing gradient problem as the network gets deeper, making it possible to train large-scale CNNs efficiently267. In 2016, the Google-owned AI company DeepMind shocked the world by beating Lee Se-dol with its AlphaGo AI system, alerting the world to deep learning, a new breed of machine learning that promised to be smarter and more creative than before268. For a more detailed description of the history and development of deep learning, readers can refer to the chronological review article by Schmidhuber39.
Convolutional neural network (CNN)
In the subsection âArtificial neural networkâ, we talked about the simplest DNN, so-called MLPs, which basically consist of multiple layers of neurons, each fully connected to those in the adjacent layers. Each neuron receives some inputs, which are multiplied by their weights, with nonlinearity applied via activation functions. In this subsection, we will talk about CNNs, which are considered an evolution of the MLP architecture that is developed to process data in single or multiple arrays, and thus are more appropriate to handle image-like input. Given the prevalence of CNNs in image processing and analysis tasks, here we briefly review some basic ideas and concepts widely used in CNNs. For a comprehensive introduction to CNN, we refer readers to the excellent book by Goodfellow et al.36.
CNN follows the same pattern as MLP: artificial neurons are stacked in hidden layers on top of each other; parameters are learned during network training with nonlinearity applied via activation functions; the loss \(L\left( {\widehat {{{\mathbf{y}}}},{{{\mathbf{y}}}}} \right)\) is calculated and back-propagated to update the network parameters. The major difference between them is that instead of regular fully connected layers, CNN uses specialized convolution layers to model locality and abstraction (Fig. 5b). At each layer, the input image \({{{\mathbf{x}}}}\) (lexicographically ordered) is convolved with a set of convolutional filters W (note here W represents block-Toeplitz convolution matrix) and added biases b to generate a new image, which is subjected to an elementwise nonlinear activation function Ï (normally use ReLU function \(\sigma (x) = \max (0,x)\)), and the same structure is repeated for each convolution layer k:

a The typical CNN architecture for image classification tasks consists of the input layer, convolutional layers, fully connected layers, and output prediction. b Convolution operation. c Pooling operation
The second key difference between CNNs and MLPs is the typical incorporation of pooling layers in CNNs, where pixel values of neighborhoods are aggregated by applying a permutation invariant function, such as the max or mean operation, to reduce the dimensionality of the convolutional layers and allows significant features to propagate downstream without being affected by neighboring pixels (Fig. 5c). The major advantage of such an architecture is that CNNs exploit spatial dependencies in the image and only consider a local neighborhood for each neuron, i.e., the network parameters are shared in such a way that the network performs convolution operations on images. In other words, the idea of a CNN is to take advantage of a pyramid structure to first identify features at the lowest level before passing these features to the next layer, which, in turn, create features of a higher level. Since the local statistics of images are invariant to location, the model does not need to learn weights for the same feature occurring at different positions in an image, making the network equivariant with respect to translations of the input. It makes CNNs especially suitable for processing images captured in optical metrology, e.g., a fringe pattern consisting of sinusoidal signal repeated over different image locations. In addition, it also drastically reduces the number of parameters (i.e., the number of weights no longer depends on the size of the input image) that need to be learned.
Figure 5a shows a CNN architecture for the image-classification task. Every layer of a CNN transforms the input volume to an output volume of neuron activation, eventually leading to the final fully connected layers, resulting in a mapping of the input data to a 1D feature vector. A typical CNN configuration consists of a sequence of convolution and pooling layers. After passing through a few pairs of convolutional and pooling layers, all the features of the image have been extracted and arranged into a long tube. At the end of the convolutional stream of the network, several fully connected layers (i.e., regular neural network architecture, MLP, that discussed in the previous subsection) are usually added to fatten the features into a vector, with which tasks, such as classifications, can be performed. Starting with LeNet256, developed in 1998 for recognizing handwritten characters with two convolutional layers, CNN architectures have evolved since then to deeper CNNs like AlexNet264 (5 convolutional Layers) and VGGNet263 (19 convolutional Layers) and beyond to more advanced and super-deep networks like GoogLeNet264 and ResNet267, respectively. These CNNs have been extremely successful in computer vision applications, such as object detection269, action recognition270, motion tracking271, and pose estimation272.
Fully convolutional network architectures for image processing
Conventionally, CNNs have been used for solving classification problems. Due to the presence of a parameter-rich fully connected layer at the end of the network, typical CNNs throw away spatial information and produce non-spatial outputs. However, for most image-processing tasks that we encountered earlier in the Section âImage processing in optical metrologyâ, the network must have a whole-resolution output with the same or even larger size compared with the input, which is commonly referred to as dense prediction (contrary to the single target category per image)273. Specifically, fully convolutional network architectures without fully connected layers should be used for this purpose, which accepts input of any size, is trained with a regression loss, and produces an output of the corresponding dimensions273,274. Here, we briefly review three representative network architectures with such features.
-
SRCNN: In conventional CNN, the downsampling effect of pooling layers results in an output with a far lower resolution than the input. Thus, a relatively naive and straightforward solution is simply stacking several convolutions layers while skipping pooling layers to preserve the input dimensions. Dong et al.275 firstly adopt this idea and propose SRCNN for the image super-resolution task. SRCNN utilizes traditional upsampling algorithms to obtain low-resolution images and then refine them by learning an end-to-end mapping from interpolated coarse images to high-resolution images of the same dimension but with more details, as illustrated in Fig. 6a. Due to its simple ideal and implementation, SRCNN has gradually become one of the most popular frameworks in image super-resolution276 and been extended to many other tasks such as radar image enhancing277, underwater image high definition display278, and computed tomography279. One major disadvantage of SRCNN is the cost of time and space to keep the whole resolution through the whole network, limiting SRCNN only practical for relatively shallow network structures.
Fig. 6: Three typical CNN structures for image-processing tasks with pixel-level image output. 
a SRCNN. b FCN. c U-Net
-
FCN: The fully convolutional network (FCN) proposed by Long et al.273 is a popular strategy and baseline for semantic-segmentation tasks. FCN is inspired by the fact that the fully connected layers in classification CNN (Fig. 5) can also be viewed as convolutions with kernels that cover their entire input regions. As illustrated in Fig. 6b, FCN uses the existing classification CNN as the encoder module of the network and replace these fully connected layers into 1âÃâ1 convolution layers (also termed as deconvolution layers) as the decoding module, enabling the CNN to upsample the input feature maps and get pixel-wise output. In FCN, skip connections combining (simply adding) information in fine layers and coarse layers enhances the localization capability of the network, allowing for the reconstruction of accurate fine details that respect global structure. FCN and its variants have achieved great success in the application of dense pixel prediction as required in many advanced computer vision understanding tasks280.
-
U-Net: Ronneberger et al.281 took the idea of FCN one step further and proposed the U-Net architecture, which replaces the one-step upsampling part with a bunch of complimentary upsampling convolutions layers, resulting in a quasi-symmetrical encoder-decoder model architecture. As illustrated in Fig. 6c, the basic structure of U-Net consists of a contractive branch and an expansive branch, which enables multiresolution analysis and general multiscale image-to-image transforms. The contractive branch (encoder) downsamples the image using conventional strided convolution, producing a compressed feature representation of the input image. The expansive branch (decoder), complimentary to the contractive branch, uses upsampling methods like transpose convolution to provide the processed result with the same size as the input. In addition, U-Net features skip connections that concatenate the matching resolution levels of the contractive branch and the expansive branch. Ronnebergerâs U-Net is a breakthrough toward automatic image segmentation and has been successfully applied in many tasks that require image-to-image transforms282.

Since the feature extraction is only performed in low-dimensional space, the computation and spatial complexity of the above encoder-decoder structured networks (FCN and U-Net) can be much reduced. Therefore, the encoder-decoder CNN structure has become the mainstream for image segmentation and reconstruction283. The encoder is usually a classic CNN (Alexnet, VGG, Resnet, etc.) in which downsampling (pooling layers) is adopted to reduce the input dimension so as to generate low-resolution feature maps. The decoder tries to mirror the encoder to upsample these feature representations and restore the original size of the image. Thus, how to perform upsampling is of great importance. Although traditional upsampling methods, e.g., nearest neighbor, bilinear, and bicubic interpolations, are easy to implement, deep-learning-based upsampling methods, e.g., unpooling284, transpose convolution273, subpixel convolution285, has gradually become a trend. All these approaches can be combined with the model mentioned above to prevent the decrease in resolution and obtain a full-resolution image output.

a Unpooling. b Transposed convolution. c Sub pixel convolution
-
Unpooling upsampling: Unpooling upsampling reverts maxpooling by remembering the location of the maxima in the maxpooling layers and in the unpooling layers copy the value to exactly this location, as shown in Fig. 7a.
-
Transposed convolution: The opposite of the convolutional layers are the transposed convolution layers (also misinterpreted as deconvolution layers280), i.e., predicting the possible input based on feature maps sized like convolution output. Specifically, it increases the image resolution by expanding the image by inserting zeros and performing convolution, as shown in Fig. 7b.
-
Sub pixel convolution: The subpixel layer performs upsampling by generating a plurality of channels by convolution and then reshaping them, as Fig. 7c shows. Within this layer, a convolution is firstly applied for producing outputs with M times channels, where M is the scaling factor. After that, the reshaping operation (a.k.a. shuffle) is performed to produce outputs with size M times larger than the original.
As discussed in the Section âImage processing in optical metrologyâ, despite their diversity, the image-processing algorithms used in optical metrology share a common characteristicâthey can be regarded as a mapping operator that transforms the content of arbitrary-sized inputs into pixel-level outputs, which fits exactly with DNNs with a fully convolutional architecture. In principle, any fully convolutional network architectures presented here can be used for a similar purpose. By applying different types of training datasets, they can be trained for accomplishing different types of image-processing tasks that we encountered in optical metrology. This provides an alternative approach to process images such that the produced results resemble or even outperform conventional image-processing operators or their combinations. There are also many other potential desirable factors for such a substitution, e.g., accuracy, speed, generality, and simplicity. All these factors were crucial to enable the fast rise of deep learning in the field of optical metrology.
Invoking deep learning in optical metrology: principles and advantages
Let us return to optical metrology. It is essential that the image formation is properly understood in order to reconstruct the required geometrical or mechanical quantities of the sample, as we discussed in Section âImage formation in optical metrologyâ. In general, the relation between the observed images \({{{\mathbf{I}}}} \in {\Bbb R}^m\) (frame-stacked lexicographically ordered with mâÃâ1 in dimension) and the desired sample parameter (or information-bearing parameter that clearly reflects the desired sample quantity, e.g., phase or displacement field) \({{{\mathbf{P}}}} \in {\Bbb R}^m\) (or \({\Bbb C}^n\)) can be described as
where \({{{\mathcal{A}}}}\) is the (possibly nonlinear) forward measurement operator mapping from the parameter space to the image space, which is given by the physics laws governing the formation of data; \({{{\mathcal{N}}}}\) represents the effect of noise (not necessarily additive). This model seems general enough to cover almost all image formation processes in optical metrology. However, this does not mean that p can be directly obtained from I. More specifically, we have to conclude in general from the effect (i.e., the intensity at the pixel) to its cause (i.e., shape, displacement, deformation, or stress of the surface), suggesting that an inverse problem has to be solved.
Solving inverse optical metrology problems: issues and challenges
Given the forward model represented by Eq. (8), our task is to find the parameters by an approximate inverse of \({{{\mathcal{A}}}}\) (denoted as \(\tilde {{{\mathcal{A}}}}^{ - 1}\)) such that \(\widehat {{{\mathbf{p}}}} = \widehat {{{\mathcal{R}}}}\left( {{{\mathbf{I}}}} \right) = \tilde {{{\mathcal{A}}}}^{ - 1}\left( {{{\mathbf{I}}}} \right) \approx {{{\mathbf{p}}}}\). However, in real practice, there are many problems involved in this process:
-
Unknown or mismatched forward model. The success of conventional optical metrology approaches relies heavily on the precise pre-knowledge about the forward model \({{{\mathcal{A}}}}\), so they are often regarded as model-driven or knowledge-driven approaches. In practical applications, the forward model \({{{\mathcal{A}}}}\) used is always an approximate description of reality, and extending it might be challenging due to a limited understanding of experimental perturbations (noise, aberrations, vibration, motion, nonlinearity, saturation, and temperature variations) and non-cooperative surfaces (shiny, translucent, coated, shielded, highly absorbent, and strong scattering). These problems are either difficult to model or result in a too complicated (even intractable) model with a large number of parameters.
-
Error accumulation and suboptimal solution. As described in the section âImage processing in optical metrologyâ, âdivide-and-conquerâ is a common practice for solving complex problems with a sequence of cascaded image-processing algorithms to obtain the desired object parameter. For example, in FPP, the entire image-processing pipeline is generally divided into several sub-steps, i.e., image pre-processing, phase demodulation, phase unwrapping, and phase-to-height conversion. Although each sub-problem or sub-step becomes simpler and easier to handle, the disadvantages are also apparent: error accumulation and suboptimal solution, i.e., the aggregation of optimum solutions to subproblems may not be equivalent to the global optimum solution.
-
Ill-posedness of the inverse problem. In many computer vision and computational imaging tasks, such as image deblurring24, sparse computed tomography25, and imaging through scattering media27, the difficulty in retrieving the desired information p from the observation I arises from the fact that the operator \({{{\mathcal{A}}}}\) is usually poorly conditioned, and the resulting inverse problem is ill-posed, as illustrated in Fig. 8a. Due to the similar indirect measurement principle, there are also many important inverse problems in optical metrology that are ill-posed, among which the phase demodulation from a single-fringe pattern and phase unwrapping from single wrapped phase distributions are the best known for specialists in optical metrology (Fig. 8b). The simplified model for the intensity distribution of fringe patterns (Eq. (1)) suggests that the observed intensity I results from the integration of several unknown components: the average intensity A(x, y), the intensity modulation B(x, y), and the desired phase function Ï(x, y). Simply put, we do not have enough information to solve the corresponding inverse problem uniquely and stably.

a In computer vision, such as image deblurring, the resulting inverse problem is ill-posed since the forward measurement operator \({{{\mathcal{A}}}}\) mapping from the parameter space to the image space is usually poorly conditioned. The classical approach is to impose certain prior assumptions (smoothing) about the solution p that helps in regularizing its retrieval. b In optical metrology, absolute phase demodulation from a single-fringe pattern exhibits all undesired difficulties of an inverse problem: ill-posedness and ambiguity, which can also be formed as a regularized optimization problem with proper prior assumptions (phase smoothness, geometric constraints) imposed. c Optical metrology uses an âactiveâ approach to transform the ill-posed inverse problem into a well-posed estimation or regression problem: by acquiring additional phase-shifted patterns of different frequencies, absolute phase can be easily determined by multi-frequency phase-shifting and temporal phase unwrapping methods
In the fields of computer vision and computational imaging, the classical approach in solving an ill-posed inverse problem is to reformulate the ill-posed original problem into a well-posed optimization problem by imposing certain prior assumptions about the solution p that helps in regularizing its retrieval:
where || ||2 indicates the Euclidean norm, R(p) is a regularization penalty function that incorporates the prior information about p, such as smoothness286, sparsity in some basis287 or dictionary288. γ is a real positive parameter (regularization parameter) that governs the weight given to the regularization against the need to fit the measurement and should be selected carefully to make an admissible compromise between the prior knowledge and data fidelity. Such an optimization problem can be solved efficiently with a variety of algorithms289,290 and provide theoretical guarantees on the recoverability and stability of the approximate solution to an inverse problem291.
Instead of regularizing the numerical solution, in optical metrology, we prefer to reformulate the original ill-posed problem into a well-posed and adequately stable one by actively controlling the image acquisition process so as to add systematically more knowledge about the object to be investigated into the evaluation process31. Due to the fact that the optical measurements are frequently carried out in a highly controlled environment, such a solution is often more practical and effective. As illustrated by Fig. 8c, by acquiring additional multi-frequency phase-shifted patterns, absolute phase retrieval becomes a well-posed estimation or regression problem, and the simple standard (unconstrainted, regularization-free) least-square methods in regression analysis provides a stable, precise, and efficient solution292,293:
The situation may become very different when we step out of the laboratory and into the complicated environment of the real world294. The active strategies mentioned above often impose stringent requirements on the measurement conditions and the object under test. For instance, high-sensitivity interferometric measurement in general needs a laboratory environment where the thermal-mechanical settings are carefully controlled to preserve beam path conditions and minimize external disturbances. Absolute 3D shape profilometry usually requires multiple fringe pattern projections, which requires that the measurement conditions remain invariant while sequential measurements are performed. However, harsh operating environments where the object or the metrology system cannot be maintained in a steady-state may make such active strategies a luxurious or even unreasonable request. Under such conditions, conventional optical metrology approaches will suffer from severe physical and technical limitations, such as a limited amount of data and uncertainties in the forward model.
To address these challenges, researchers have made great efforts to improve state-of-the-art methods from different aspects over the past few decades. For example, phase-shifting techniques were optimized from the perspective of signal processing to achieve high-precision robust phase measurement and meanwhile minimize the impact of experimental perturbations32,153. Single-shot spatial phase-demodulation methods have been explicitly formulated as a constrained optimization problem similar to Eq. (9) with an extra regularization term enforcing a priori knowledge about the recovered phase (spatially smooth, limited spectral extension, piecewise constant, etc.)140,148. Multi-frequency temporal phase unwrapping techniques have been optimized by utilizing the inherent information redundancy in the average intensity and the intensity modulation of the fringe images, allowing for absolute phase retrieval with the reduced number of patterns32,295. Geometric constraints were introduced in FPP to solve the phase ambiguity problem without additional image acquisition175,183. Despite these extensive research efforts for decades, how to extract the absolute (unambiguous) phase information, with the highest possible accuracy, from the minimum number (preferably single shot) of fringe patterns remains one of the most challenging open problems in optical metrology. Consequently, we are looking forward to innovations and breakthroughs in the principles and methods of optical metrology, which are of significant importance for its future development.
Solving inverse optical metrology problems via deep learning
As a âdata-drivenâ technology that has emerged in recent years, deep learning has received increasing attention in the field of optical metrology and made fruitful achievements in very recent years. Different from the conventional physical model and knowledge-driven approaches that the objective function (Eqs. (9) and (10)) is built based on the image formation model \({{{\mathcal{A}}}}\), in deep-learning approaches, we create a set of true object parameters p and the corresponding raw measured data I, and establish their mapping relation \({{{\mathcal{R}}}}_\theta\) based on a deep neural network with all network parameters θ learned from the dataset by solving the following optimization problem (Fig. 9):
with \(\left\| {}\, \right\|_2^2\) being the L2-norm error (loss) function once again (different types of loss functions discussed in the subsection âNeural network trainingâ can be specified depending on the type of training data) and R is a regularizer of the parameters to avoid overfitting. A key element in deep-learning approaches is to parameterize \(\widehat {{{{\mathcal{R}}}}_\theta }\) by parameters \(\theta \in \Theta\). The âlearningâ process refers to finding an âoptimalâ set of network parameters from the given training data by minimizing Eq. (11) over all possible network parameters \(\theta \in \Theta\). And the âoptimalityâ is quantified through the loss function that measures the quality of the learned \({{{\mathcal{R}}}}_\theta\). Different deep-learning approaches can be thought of as different ways to parameterize the reconstruction network \({{{\mathcal{R}}}}_\theta\). Different from conventional approaches that solving the optimization problem directly gives the final solution \(\widehat {{{{\mathcal{R}}}}_\theta }\) to the inverse problem corresponding to a current given input, in deep-learning-based approaches, the optimization problem is phrased as to find a âreconstruction algorithmâ \(\widehat {{{{\mathcal{R}}}}_\theta }\) satisfying the pseudo-inverse property \(\widehat {{{\mathbf{p}}}} = \widehat {{{{\mathcal{R}}}}_\theta }\left( {{{\mathbf{I}}}} \right) = \tilde {{{\mathcal{A}}}}^{ - 1}\left( {{{\mathbf{I}}}} \right) \approx {{{\mathbf{p}}}}\) from the prepared (previous) dataset, which is then used for the reconstruction of the future input.

a In deep-learning-based optical metrology, a set of true object parameters p and the corresponding raw measured data I are created at the training stage, and their mapping relation (learn a reconstruction algorithm) \({{{\mathcal{R}}}}_\theta\) is established by training a deep neural network with all network parameters θ (neural network weights) learned from the dataset. b The principle of obtaining the dataset by real experiments or simulations with the knowledge of the forward model \({{{\mathcal{A}}}}\) (left) and the obtained dataset (right)
Most of the deep-learning techniques currently used in optical metrology belong to supervised learning, i.e., a matched dataset of ground-truth parameters p and corresponding measurements I should be created to train the network. Ideally, the dataset should be collected by physical experiments based on the same metrology system to account for all experimental conditions (which are usually difficult to be fully described by the forward image formation model). The ground truth can be obtained by measuring various samples that one is likely to encounter by employing active strategies mentioned above, without considering the ill-posedness of the real problem. To be more precise, in deep-learning-based optical metrology approaches, active strategies frequently used in conventional optical metrology approaches are shifted from the actual measurement stage to the preparation (network training) stage. Although the situation faced during the preparation stage may be different from that in the actual measurement stage, the information obtained in the former can be transferred to the latter in many cases. What we should do during the training stage is to reproduce the sample (using representative test objects), the system (using the same measurement system), and the error sources (noise, vibration, background illumination) during the measurement stage to ensure that the captured input data is as close as possible to those in the real measurement. On the other hand, we should make the remaining environmental variables as controllable as possible so that more active strategies (sample manipulation, illumination changing, multiple acquisitions) can be involved in the training stage to derive the ground truth corresponding to these captured data. Once the network is trained, we can then strip out these ideal environment variables and make the network run in a realistic experimental condition.
For example, for an interferometric system working in a harsh environment or a FPP system designed for measuring dynamic objects, phase demodulation from a single-fringe pattern is the most desirable choice. The inherent ill-posedness of the problem makes it a very good example for deep learning in this regard. In the training stage, we reproduce all the experimental conditions except that we employ the multi-frame phase-shifting technique with large phase-shifting steps to obtain the ground truth for the training samples. Once the network is established, it can map from only one single-fringe pattern to the desired phase distribution, and thus can be used in harsh environments where the single-shot phase-demodulation technique should be applied. Note that in this example, all the training data is fully generated by experiments, so the reconstruction algorithm (inverse mapping) \(\widehat {{{{\mathcal{R}}}}_\theta }\) can be established without the knowledge of the forward model \({{{\mathcal{A}}}}\) in principle. Even though, since we have sufficient real-world training observations of the form (p, I), it can be expected that those experimental data can reflect the true \({{{\mathcal{A}}}}\) in a complete and realistic way.
It should be noted that there are also many cases that the ground truth corresponding to the experimental data is inaccessible. In such cases, the matched dataset can be obtained by a âlearning from simulationâ scheme â simulating the forward operator (with the knowledge of the forward image formation model \({{{\mathcal{A}}}}\)) on ideal sample parameters. However, due to the complexity of real experimental conditions, we typically only know an approximation of \({{{\mathcal{A}}}}\). Subsequently, the inconsistency or uncertainty in the forward operator \({{{\mathcal{A}}}}\) may lead to a compromised performance in real experiments (see the âChallengesâ section for detailed discussions). On the other hand, partial knowledge of the forward model \({{{\mathcal{A}}}}\) can be leveraged and incorporated in the deep neural network design to alleviate the âblack boxâ nature of conventional neural network architectures, which may reduce the amount of required training data and provide more accurate and reliable network reconstruction (see the âFuture directionsâ section for more details).
Advantages of invoking deep learning in optical metrology
In light of the above discussions, we summarize the potential advantages that can be gained by using a deep-learning approach in optical metrology. Figure 10 shows the advantages of deep-learning techniques compared to traditional optical metrology algorithms by taking FPP as an example. One may have noticed that FPP has appeared a few times, and in fact, it will appear more times. The reason is that FPP is currently one of the most promising and well-researched areas at the intersection of deep learning and optical metrology, offering a representative and convincing example of the use of deep learning in optical metrology.

a The basic principle of FPP relies on the physical model of optical triangulation (left). The basic reconstruction steps generally include fringe projection, phase retrieval, phase unwrapping, and phase-to-height conversion based on calibrated system parameters. b The deep-learning-based FPP technology is driven by extensive training data. A well-trained deep-learning model can directly predict the depth information from a single-fringe image
(1) From âphysics-model-drivenâ to âdata-drivenâ Deep learning subverts the conventional âphysics-model-drivenâ paradigm and opens up the âdata-drivenâ learning-based representation paradigm. The reconstruction algorithm (inverse mapping) \(\widehat {{{{\mathcal{R}}}}_\theta }\) can be learned from the experimental data without resorting to the pre-knowledge of the forward model \({{{\mathcal{A}}}}\). If the training data is collected under an environment that reproduces the real experimental conditions (including metrology system, sample types, measurement environment, etc.), and the amount (diversity) of data are sufficient, the trained model \(\widehat {{{{\mathcal{R}}}}_\theta }\) should reflect the true \({{{\mathcal{A}}}}\) more precisely and comprehensively and is expected to produce better reconstruction results than conventional physics-model-driven or knowledge-driven approaches. The âdata-drivenâ learning-based paradigm eliminates the need to design different processing flows for specific image-processing algorithm based on experience and pre-knowledge. By applying different types of training datasets, one specific class of neural network can be trained to perform various types of transformation for different tasks, significantly improving the universality and reducing the complexity of solving new problems.
(2) From âdivide-and-conquerâ to âend-to-end learningâ In contrast to the traditional optical metrology approach that solves the sequence of tasks independently, deep learning allows for an âend-to-endâ learning structure, where the neural network can learn the direct mapping relation between the raw image data and the desired sample parameters in one step, i.e., \(\widehat {{{\mathbf{p}}}} = \widehat {{{{\mathcal{R}}}}_\theta }\left( {{{\mathbf{I}}}} \right)\), as illustrated in Fig. 10b. Compared with the âdivide-and-conquerâ scheme, the âend-to-endâ learning allows to jointly solve multiple tasks, with great potential to alleviate the total computational burden. Such an approach has the advantage of synergy: it enables sharing information (features) between parts of the network that perform different tasks, which is more likely to get better overall performance compared to solving each task independently.
(3) From âsolving ill-posed inverse problemsâ to âlearning pseudo-inverse mappingâ Deep learning utilizes complex neural network structures and nonlinear activation functions to extract high-dimensional features of the sample data, remove irrelevant information, and finally establish a nonlinear pseudo-inverse mapping model that is sufficient to describe the entire measurement process. The major reason for the success of deep learning is the abundance of training data and the explicit agnosticism from a priori knowledge of how such data are generated. Instead of hand-crafting a regularization function or specifying prior, deep learning can automatically learn it from the example data. Consequently, the learned prior R(θ) is tailored to the statistics of real experimental data and, in principle, provides stronger and more reasonable regularization to the inverse problem pertaining to a specific metrology system. Consequently, the obstacle of âsolving nonlinear ill-posed inverse problemsâ can be bypassed, and the pseudo-inverse mapping relation between the input and the desired output can be established directly.
The use of deep learning in optical metrology
Deep-learning-enabled image processing in optical metrology
Owing to the above-mentioned advantages, deep learning has been gaining increasing attention in optical metrology, demonstrating promising performance in various optical metrology tasks and in many cases exceeding that of classic techniques. In this section, we review these existing researches leveraging deep learning in optical metrology according to an architecture similar to that introduced in the section âImage processing in optical metrologyâ, as summarized in Fig. 11. The basic network types, loss functions, and data acquisition methods of some representative examples are listed in Table 1.
-
(1)
Pre-processing: Many early works applying deep learning to optical metrology focused on image pre-processing tasks, such as denoising and enhancement. This is mainly due to the fact that the successful use cases of deep learning to such pre-processing tasks can be easily found in the computer vision community. Many image pre-processing algorithms in optical metrology could receive a performance upgrade by simply reengineering these existing neural network architectures for a similar kind of problem.
-
Denoising: Yan et al.55 constructed a CNN composed of 20 convolutional layers for fringe denoising (Fig. 12a). Simulated fringe patterns with artificial Gaussian noise were generated as the training dataset, and corresponding noise-free versions were used as ground truth. Figure 12d, e shows the denoising results of WFT114 and the deep-learning-based method, showing that their method was free of the boundary artifacts in WFT and achieved comparable denoising performance in the central region. Jeon et al.296 proposed a fast speckle-noise reduction method based on U-Net, which showed robust and excellent denoising performance for digital holographic images. Hao et al.54 constructed a fast and flexible denoising convolutional neural network (FFDNet) for batch denoising of ESPI fringe images. Lin et al.297 developed a denoising CNN (DnCNN) for speckle-noise suppression of fringe patterns. Reyes-Figueroa and Rivera298 proposed a fringe pattern filtering and normalization technique based on autoencoder299. The autoencoder was able to fine-tune the U-Net network parameters and reduce residual errors, thereby improving the stability and repeatability of the neural network. Since it is difficult to access noise-free ground-truth images in real experimental conditions, the training datasets of these deep-learning-based denoising methods are all generated based on simulations.
-
Color channel separation: Our group reported a single-shot 3D shape measurement approach with deep-learning-based color fringe projection profilometry that can automatically eliminate color cross-talk and channel imbalance300. As shown in Fig. 13a, the network predicted the sine and cosine terms related to high-quality cross-talk-free phase information from the input 3-channel fringe images of different wavelengths. In order to get rid of color cross-talk and chromatic aberration, the green monochromatic fringe patterns were projected and only the green channel of the captured patterns was used to generate labels. Figure 13bâd shows 3D reconstruction results of a David plaster model measured by the traditional color-coded method301 and our method, showing that the deep-learning-based method yielded more accurate surface details. The quality of the 3D reconstruction was comparable to the ground truth (Fig. 13e) obtained by the non-composite (monochromatic) multi-frequency phase-shifting method174. The deep-learning-based method was applied for dynamic 360° 3D digital modeling, demonstrating its potential in rapid reverse engineering and related industrial applications (Fig. 13fâi).
-
Enhancement: Shi et al.51 proposed a fringe-enhancement method based on deep learning, and the flowchart of which is given in Fig. 14a. The captured fringe image and the corresponding enhanced one obtained by the subtraction of two fringe patterns with Ï relative phase shift were used to establish the mapping between the raw fringe and the desired enhanced versions. Figure 14bâd shows the 3D reconstruction results of a moving hand using the traditional FT method138 and the deep-learning method, suggesting that the deep-learning method outperformed FT in terms of detail preservation and SNR. Goy et al.302 proved that DNN could recover an image with decent quality under low-photon conditions, and successfully applied their method to phase retrieval. Yu et al.303 proposed a fringe-enhancement method in which the fringe modulation was improved by deep learning, facilitating high-dynamic 3D shape measurement without resorting to conventional multi-exposure schemes.
-
-
(2)
Analysis: Image analysis is the most critical step in the image-processing architecture of optical metrology. Consequently, most deep-learning techniques applied to optical metrology are proposed to accomplish the tasks associated with image analysis. For phase measurement techniques, deep learning is extensively explored for (both spatial and temporal) phase demodulation and (spatial, temporal, and geometric) phase unwrapping.
-
Phase demodulation:
-
Spatial phase retrieval: To address the contradiction between the measurement efficiency and accuracy of traditional phase retrieval methods, our group, for the first time, introduced deep learning to fringe pattern analysis, substantially enhancing the phase-demodulation accuracy from a single-fringe pattern50. As illustrated in Fig. 15a, the background image A was first predicted from the acquired fringe image I through CNN1. Then CNN2 was employed to realize the mapping from I and A to the numerator (sine) term M and denominator (cosine) term D. Finally, the wrapped phase information can be acquired by computing the arctangent of M/D. Figure 15b compares the phases retrieved by two representative traditional single-frame phase retrieval methods (FT138, WFT114) and the deep-learning method, revealing that our deep-learning-based single-frame phase retrieval method achieved the highest reconstruction quality, which almost visually reproduced the ground-truth information obtained by the 12-step phase-shifting method. We have incorporated the deep-learning-based phase retrieval technique into the micro-Fourier transform profilometry (μFTP) technique to eliminate the need for additional uniform patterns, doubling the measurement speed and achieving an unprecedented 3D imaging frame rate up to 20,000âHz304. Figure 15c shows the 3D measurement results of a rotating fan at different speeds (3000 and 5000 revolutions per minute (RPM)), suggesting that the 3D shape of fan blades can be intactly reconstructed without any motion-induced artifacts visible. Qiao et al.305 applied this deep-learning-based phase extraction technique for phase measuring deflectometry, and achieved single-shot high-accuracy 3D shape measurement of specular surfaces. Some other network structures, such as structured light CNN (SL-CNN)306 and deep convolutional GAN307 were also adopted for single-frame phase retrieval. In addition, deep learning can also be applied to Fourier transform profilometry for automatic spectrum extraction by identifying the carrier frequency components bearing the object information in the Fourier domain, facilitating automatical spectrum extraction, and achieving higher phase retrieval accuracy without human intervention308. Wang et al.309 proposed an automatical holographic reconstruction framework (Y-Net) consisting of two symmetrical U-Nets, allowing for simultaneous recovery of phase and intensity information from a single off-axis digital hologram. They also doubled the capability of Y-Net, extending it to the reconstruction of dual-wavelength complex amplitudes, while overcoming the spectral overlapping issue in common-path dual-wavelength digital holography310. Recently, our group used U-Net to realize aliasing-free phase retrieval from a dual-frequency composite fringe pattern311. Compared with the traditional Fourier transform profilometry, the deep-learning-enabled approach avoids the complexities associated with dual-frequency spectra separation and extraction, allowing for higher-quality single-shot absolute 3D shape reconstruction.
-
Temporal phase retrieval: Wang et al.312 introduced a deep-learning scheme to the phase-shifting technique in FPP. As shown in Fig. 16a, by introducing a fully connected DNN, the link between three low- and unit-frequency phase-shifting fringe patterns and high-quality absolute phases calculated from high-frequency fringe images were established, and thus, the 3D measurement accuracy could be significantly enhanced. The three unit-frequency phase-shifting patterns were encoded in three monochrome channels of a color image and projected by a 3LCD projector. The individual fringe patterns were then decoded and projected by the projector sequentially and rapidly313,314. Consequently, the hardware system allowed for real-time 3D surface imaging of multiple objects at a speed of 25.6âfps. Zhang et al.315 developed a deep-phase-shift network (DPS-Net) based on GAN, with which multi-step phase-shifting interferograms with accurate arbitrary phase shifts for calculating high-quality phase information were predicted from a single interferogram. Besides random intensity noise, conventional phase-shifting algorithms are also sensitive to other experimental imperfections, such as phase-shifting error, illumination fluctuations, intensity nonlinearity, lens defocusing, motion-induced artifacts, and detector saturation. Deep learning also provides a potential solution to eliminate or at least partially alleviate the impact of these error sources on phase measurement. For example, Li et al.316 proposed a deep-learning-based phase-shifting interferometric phase recovery approach. The constructed U-Net was capable of predicting the accurate wrapped phase map from two interferogram inputs with unknown phase shifts. Zhang et al.317 applied CNN to extract a high-accuracy wrapped phase map from conventional 3-step phase-shifting fringe patterns. In the training stage, low-modulation or saturated fringe patterns were used as the raw dataset, and the relation between these imperfect raw fringe and high-quality error-free unwrapped phase (obtained by 12-step phase-shifting algorithms) were established based on CNN. Consequently, the deep-learning-based approach could accommodate both dark and reflective surfaces, and the related phase errors (noise and saturation) in the conventional three-step phase-shifting method were significantly suppressed, making it a promising approach for high-dynamic-range (HDR) 3D measurement of surfaces with large reflectivity variations (Fig. 16dâg). Wu et al.318 proposed a deep-learning-based phase-shifting approach to overcome the phase errors associated with intensity nonlinearity. Through a well-trained FCN, the distortion-free high-quality phase map could be reconstructed conveniently and efficiently from the raw phase-shifting fringe patterns with a strong gamma effect. Yang et al.319 constructed a three-to-three deep-learning framework (Tree-Net) based on U-Net to compensate for the nonlinear effect in the phase-shifting images, which effectively and robustly reduced the phase errors by about 90%. Recently, our group demonstrated that the nonsinusoidal errors (e.g., residual high-order harmonics in binary defocusing projection, intensity saturation, gamma effect of projectors and cameras, and their coupling) in phase-shifting profilometry could be handled by an integrated deep-learning framework. A well-trained U-Net could effectively suppress the phase errors caused by different types of nonsinusoidal fringe with only a minimum of three fringe patterns as input320.
-
-
Phase unwrapping:
-
Spatial phase unwrapping: Wang et al.321 proposed a one-step phase unwrapping approach based on deep learning. Various ideal (noise-free) continuous phase distributions and the corresponding wrapped phase maps with different types of noises (Gaussian, salt and pepper, or multiplicative noises) were simulated and used as the training dataset for a CNN based on U-Net. Upon completion of the training, the absolute phases can be predicted directly from a noisy wrapped phase map, as illustrated in Fig. 17a. Figure 17bâf shows the comparisons of phase unwrapping results obtained by the traditional least-square (LS) method322 and deep-learning-based method, demonstrating that deep learning can directly fulfill the complicated nonlinear phase unwrapping task in one step with improved anti-noise and anti-aliasing ability. Spoorthi et al.323 developed a CNN-based phase unwrapping framework-PhaseNet. The fringe order (2Ï integer phase jumps) used for phase unwrapping can be obtained pixel by pixel through a semantic segmentation-based deep-learning framework of the encoder-decoder structure. Recently, they developed an enhanced phase unwrapping frameworkâPhaseNet 2.0, which could directly map a noisy wrapped phase to a denoised absolute one324. Zhang et al.325 transferred the task of phase unwrapping to a multi-class classification problem and generated fringe orders by feeding the wrapped phase into a convolutional segmentation network. Zhang et al.53 proposed a deep-learning-based approach for rapid 2D phase unwrapping, which demonstrated good denoising and unwrapping performance and outperformed the conventional path-dependent and path-independent methods. Kando et al.326 applied U-Net to achieve absolute phase prediction from a single interferogram, and the quality of the recovered phase was superior to that obtained by the conventional FT method, especially for closed-fringe patterns. Li et al.327 proposed a deep-learning-based phase unwrapping strategy for closed fringe patterns. They compared four different network structures for phase unwrapping and found that the improved FCN architecture performed the best in terms of accuracy and speed. However, it should be mentioned that, similar to the case of fringe denoising, true absolute phase maps corresponding to the real experimentally obtained wrapped phase maps are generally quite hard to obtain in many interferometric techniques (which requires sophisticated multi-wavelength illuminations and heterodyne operations). Therefore, the training datasets used in the above-mentioned deep-learning-based spatial phase unwrapping methods are generated based on numerical simulation instead of real experiments. Moreover, since only one single wrapped phase map is used as input, the above-mentioned deep-learning-based spatial phase unwrapping methods still suffers from the 2Ï ambiguity problem inherent in traditional phase measurement techniques.
-
Temporal phase unwrapping: Our group developed a deep-learning-based temporal phase unwrapping framework, as illustrated in Fig. 18a52. The inputs of the network are a single-period (wrap-free) phase map and a high-frequency wrapped phase map, from which the constructed CNN could directly predict the fringe orders corresponding to the high-frequency phase to be unwrapped. Figure 18bâe gives the comparison between the traditional multi-frequency temporal phase unwrapping (MF-TPU) method174 and the deep-learning-based approach for the 3D reconstructions obtained by unwrapping the wrapped phase maps using the (1â32) and (1â64) frequency combination of fringe patterns, respectively. In comparison with MF-TPU, the deep-learning-assisted method produced phase unwrapping results with higher accuracy and robustness even in the case of different types of error sources (low SNR, intensity nonlinearity, and object motion). Liu et al.328 further improved this approach by using a lightweight classification CNN to extract the fringe orders from a pair of low-high-frequency phase maps, which saved a large amount of training time and made it possible to deploy the network on mobile devices. Li et al.329 proposed a deep-learning-based dual-wavelength phase unwrapping approach in which only a single-wavelength interferogram was used to predict another interferogram recorded at a different wavelength with a conditional GAN (CGAN). Though their approach still suffered from the phase ambiguity problem when measuring discontinuous surface or isolated objects, it provided an effective and potential solution to phase unwrapping and extended the measurement range of single-wavelength interferometry and holography techniques. Yao et al. designed FCNs by incorporating residual layers to predict the fringe orders of wrapped phases from only two330 or even single331 Gray-code image(s), significantly reducing the required images compared with the conventional Gray-code technique.
-
Geometric phase unwrapping: Our group proposed a deep-learning-assisted geometric phase unwrapping approach for single-shot 3D surface measurement332. The flowchart of this approach is shown in Fig. 19a. Two CNNs (CNN1 and CNN2) were constructed for phase retrieval and phase unwrapping, respectively. Based on a stereo camera system, dual-view single-shot fringe patterns, as well as the reference plane images, were fed into CNN2 to determine the fringe orders. With the predicted wrapped phases and fringe orders, the absolute phase map can be recovered. Figure 19bâe is the comparison of 3D reconstructions obtained through different conventional geometric phase unwrapping methods175,179,186 and the deep-learning-based method, demonstrating that the deep-learning-based method can robustly unwrap the wrapped phases of dense fringe patterns within a larger measurement volume under the premise of single-frame projection. It should be mentioned that it is indeed a straightforward idea to establish the relationship between the fringe pattern to the corresponding absolute phase directly. However, since the rationality of the deep-learning-based approach is largely dependent on the input data, when the input fringe itself is ambiguous, the network can never always produce reliable phase unwrapped results. For example, in Yuâs work333, when there exist large depth discontinuities and isolated objects, even with the assistance of deep learning, one fringe image is insufficient to eliminate the 2Ï phase ambiguity.
-
Fig. 11: Deep learning in optical metrology. 
Because of the significant changes that deep learning brings to the concept of optical metrology technology, almost all elementary tasks of digital image processing in optical metrology have been reformed by deep learning
Table 1 Basic network structures, loss functions, and data acquisition methods for deep-learning methods applied to optical metrology tasks Fig. 12: Flowchart of deep-learning-based fringe pattern denoising and the denoising results of different methods. 
a The flowchart of deep-learning-based fringe pattern denoising method: taking noisy fringe patterns as input to DCNN and predicting the denoised image directly. b The noisy input pattern. c Ground truth. d The predicted result of deep learning. e The denoising result of WFT114. aâe Adapted with permission from ref. 55, Copyright (2021), with permission from Elsevier
Fig. 13: Flowchart of deep-learning-based color FPP and the 3D reconstruction results of different approaches. 
a The flowchart of deep-learning-based color FPP: CNN predicts the sine and cosine terms related to high-quality wrapped phase map from the input 3-channel fringe images of different frequencies, as well as a âcoarseâ absolute phase map. Then the outputs of CNN are used to obtain a high-accuracy absolute phase for further 3D reconstruction. b The input color fringe pattern of a David plaster model. c The 3D reconstruction result of the color-coded approach proposed by Zhang et al.301. d The 3D reconstruction result of our deep-learning-based method. e Ground truth. f One frame of the color fringe patterns of a 360° rotated workpiece. g 3D result of (f). h, f Registration results viewed from two different perspectives. aâi Adapted with permission from ref. 300, Optica Publishing
Fig. 14: Flowchart of the deep-learning-based fringe-enhancement method and the 3D reconstruction results of different approaches. 
a The flowchart of the deep-learning-based fringe enhancement: the captured raw fringe images and the quality-enhanced versions are used to learn the mapping between the input fringe image and the output enhanced fringe part of the constructed DnCNN. b Input raw fringe pattern of a moving hand. c 3D reconstruction result obtained by traditional FT138. d 3D reconstruction result obtained by the deep-learning method. aâd Adapted with permission from ref. 51, Optica Publishing
Fig. 15: Flowchart of the single-frame phase retrieval approach using deep learning and the 3D reconstruction results of different approaches. 
a The principle of deep-learning-based phase retrieval method: the background image A is first predicted from the single-frame fringe image I through CNN1; then CNN2 is employed to realize the mapping between the fringe pattern I and the predicted background map A to the numerator term M and the denominator term D of the arctangent function; finally, the high-accuracy wrapped phase map can be obtained by the arctangent function. b Comparison of the 3D reconstructions of different fringe analysis approaches (FT138, WFT114, the deep-learning-based method, and 12-step phase-shifting profilometry). c The measurement results of a desk fan rotating at different speeds using our deep-learning method. a, b Adapted from ref. 50. Distributed under Creative Commons (CC BY 4.0) license https://creativecommons.org/licenses/by/4.0/legalcode. c Adapted with permission from ref. 304, Copyright (2021), with permission from Elsevier
Fig. 16: Temporal phase retrieval based on deep learning. 
a Schematic of using deep learning for temporal phase retrieval using three phase-shifted sinusoidal fringe images. b, c The reconstruction results of a complex scene based on the deep-learning method illustrated in (a). d One raw image containing both low-modulation and saturated fringes. eâg The 3D reconstruction results using the traditional phase-shifting method. hâj The 3D reconstruction results using the deep-learning-based HDR method. aâc Adapted with permission from ref. 312, Optica Publishing. dâj Adapted with permission from ref. 317, Copyright (2021), with permission from Elsevier
Fig. 17: Flowchart of the one-step deep-learning-based phase unwrapping approach and the unwrapping results of different methods. 
a The flowchart of the one-step deep-learning-based phase unwrapping approach: the absolute phase can be predicted directly from a noisy wrapped phase based on the trained CNN. b The wrapped phase map of living mouse osteoblast. c Unwrapped phase of (b) obtained by deep learning. d Phase errors of (c). e Unwrapped phase of (b) obtained by the conventional LS method322. f Phase errors of (e). aâf Adapted with permission from ref. 321, Optica publishing
Fig. 18: Flowchart of deep-learning-assisted temporal phase unwrapping method and the 3D reconstructions of different phase unwrapping approaches. 
a The flowchart of deep-learning-based temporal phase unwrapping. b The 3D reconstruction obtained from phase unwrapping of (1â+â32)-frequency combination by MF-TPU164. c The 3D reconstruction obtained from phase unwrapping of (1â+â32)-frequency combination by the deep-learning-based method. d The 3D reconstruction obtained from phase unwrapping of (1â+â64)-frequency combination by MF-TPU. e The 3D reconstruction after phase unwrapping of (1â+â64)-frequency combination by deep-learning-based TPU. aâe Adapted by permission from Springer Nature: Scientific Reports52, Copyright (2021)
Fig. 19: Flowchart of deep-learning-assisted geometric constraints and phase unwrapping and the 3D reconstruction results of different methods. 
a The flowchart of deep-learning-assisted geometric constraints and phase unwrapping: Fengâs method50 is applied to extract the wrapped phases from two perspectives through CNN1. Then the single-frame dual-view fringe patterns, as well as the reference information are fed into CNN2 to output the fringe orders. Through the predicted wrapped phase data and fringe orders, the absolute phase in the left perspective can be recovered, followed by 3D reconstruction. b The result obtained by combining phase-shifting, triple-camera geometric phase unwrapping, and adaptive depth-constraint methods186. c The result obtained by combining phase-shifting and dual-camera geometric phase unwrapping methods. d The result obtained by Anâs depth-constraint method179. e The result obtained by the deep-learning-enabled geometric constraint method. aâe Adapted from ref. 332, with the permission of AIP Publishing
Fig. 20: Flowchart of the deep-learning-based method for extracting depth information and the estimated disparity images using different methods. 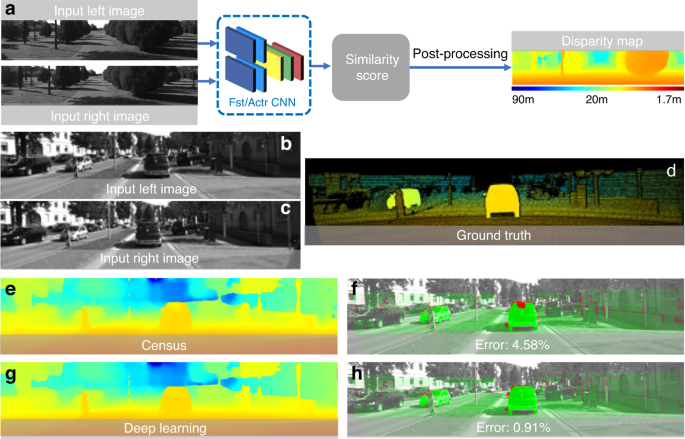
a The flowchart of deep-learning-based method for extracting depth information: two network architectures (one tuned for speed, the other for accuracy) are trained to learn the matching cost computation. The output of CNN is applied to initialize the stereomatching cost, followed by a series of postprocessing processes. b, c The input stereo images. d Ground truth. e, g The disparity estimation results using Census335 and CNN. f, h The disparity errors of (e, g). aâh Adapted from ref. 334. © 2016 Jure Zbontar and Yann LeCun, Microtome Publishing
Fig. 21: Flowchart of the cascade CNN architecture consisting of two stages for disparity estimation and the corresponding predicted disparities. 
a Flowchart of the cascade CNN architecture consisting of two stages for disparity estimation: the first stage outputs the disparity image with more details from the input stereo images through the DispFulNet, where IL and IR are the stereo pairs, d1 is the initial disparity, \(\tilde I_L\) represents the synthesized left image and eL is the error map between IL and \(\tilde I_L\). The second stage rectifies d1 and generates residual signals across multiple scales through the DispResNet, where \(d_2^{(0)}\) is the new disparity of the scale of full resolution. The final disparity map is obtained by combining the outputs of the above two stages. b Left input. c Ground truth. d, e Outputs of the first stage and the second stage. f, g Error distributions between c, d and between (c) and (e). aâg ©(2021) IEEE. Adapted, with permission, from ref. 347
Fig. 22: Flowchart of computational denoising based on deep learning for phase information and phase denoising results of different methods. 
a The flowchart of DnCNN-based phase denoising approach: the sine and cosine images of the noisy phase map is fed into a DnCNN to achieve the denoised phase information. To improve performance, 1â5 iterations are introduced in the denoising process. b The raw noisy phase. c The denoised phase processed with WFT114. d The denoised phase processed with deep learning. e The phase difference between (c) and (d). aâe Adapted with permission from ref. 362, AIP Publishing
Fig. 23: Flowchart of a holographic reconstruction network---HRNet and the hologram reconstruction results of different methods. 
a The flowchart of HRNet: Three different types of holograms (an amplitude object, a phase object, or a two-sectional object) can be used as input to obtain the corresponding reconstructions. b The input hologram image. c Ground truth. d The reconstructed images with deep learning. e The reconstructed images with the angular spectrum method.368 f The reconstructed images with the convolution method.366 aâf Adapted with permission from ref. 365. Distributed under Creative Commons (CC BY 4.0) license https://creativecommons.org/licenses/by/4.0/legalcode
Fig. 24: Flowchart of the phase-aberration compensation method combining Zernike polynomial fitting and deep learning, and the phase-aberration compensation results of different methods. 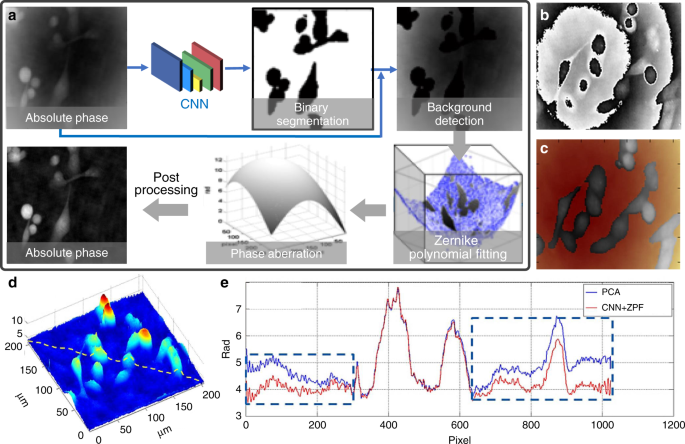
a The flowchart of CNN + (Zernike polynomial fitting) phase-aberration compensation. b The input phase-aberration map. c The unwrapped phase overlaid with CNNâs output, where the background (color denoted) is fed into Zernike polynomial fitting. d The 3D phase after compensation by CNN + Zernike polynomial fitting. e The phase profile of PCA226 and CNN + Zernike polynomial fitting along the dashed line in (d). aâe Adapted with permission from ref. 374, Optica Publishing
Fig. 25: Flowchart of the learning-based phase-height mapping approach and 3D reconstruction results of different methods. 
a Flowchart of the learning-based phase-height mapping approach: the image coordinates (Xci, Yci) and the corresponding projector lateral coordinates Xpi are fed into a 3-layer BP neural network, and the outputs are 3D coordinates (Xi, Yi, Zi). b The 3D result of a standard stair sample predicted by the learning-based method. c The plane errors of the measurement result of a stair sample by the learning-based method. d The plane errors of the measurement result of a stair sample by traditional calibration method380. e, f The input absolute phase map of a workpiece and the corresponding 3D reconstruction. aâe Adapted with permission from ref. 378, Copyright (2021), with permission from Elsevier
Fig. 26: Flowchart of the single-shot end-to-end 3D shape reconstruction based on deep learning and the 3D reconstruction results. 
a Flowchart of the single-shot end-to-end 3D shape reconstruction based on deep learning: three different deep CNNs, including FCN, AEN299, and U-Net are constructed to perform the mapping of 2D images to its corresponding 3D shape381. b, c The input and output of Nguyenâs method381. d, e The input and output of Vanâs method382. f, g The input and output of Machineniâs method384. aâc Adapted with permission from ref. 381, MDPI Publishing. d, e Adapted with permission from ref. 382, Optica Publishing. f, g Adapted with permission from ref. 384, Copyright (2021), with permission from Elsevier
Fig. 27: Flowchart of the deep-learning-based end-to-end disparity prediction method and the predicted disparity map result. 
a The Flowchart of the deep-learning-based end-to-end disparity prediction method: stereo images are fed into the constructed GC-Net to directly output disparity images of two perspectives. b The left input. c The disparity predicted by deep learning. d Ground truth. aâd ©(2021) IEEE. Adapted, with permission, from ref. 389
Fig. 28: Performance comparison between the fringe-to-phase linked deep-learning method and the deep-learning approach combining the physical model of the phase-shifting method. 
a For the end-to-end network structure, the fringe image can be fed into DNN1 to directly output the corresponding wrapped phases. b However, such an end-to-end approach makes the training process fails to converge because it is difficult to follow the 2Ï phase truncation. c Our group proposed to incorporate the physical model of the traditional phase-shifting method into deep learning and applied deep learning to predict from the fringe image the numerator and denominator of the arctangent function used to calculate the phase information50. d Such a physics-informed strategy results in a stable convergence to the minimum training and validation loss. b, d Adapted with permission from ref. 50. Distributed under Creative Commons (CC BY 4.0) license https://creativecommons.org/licenses/by/4.0/legalcode
Fig. 29: The well-trained deep-learning model for stereophase unwrapping will fail when there is depth ambiguity in a certain perspective332. 
a The left fringe image input of two flat plates (no ambiguity). b The right fringe-image input of two flat plates (no ambiguity). c Absolute phase map of (a) (ground truth). d Absolute phase map of (a) obtained by deep-learning method. e The left fringe pattern input of two flat plates, where the surface discontinuity leads to the absence of fringe orders (the fringe in the red dotted box in a) but visually presents the illusion of continuity. f The right fringe pattern input of two flat plates. The absence of a fringe order can be seen from this perspective. g Absolute phase map of (e) (ground truth). h Absolute phase map of (e) obtained by the deep-learning method. aâh Adapted with permission from ref. 332, AIP Publishing
Fig. 30: Phase retrieval uncertainty quantification based on Bayesian deep learning. 
Through BNN, the uncertainty map associated with a predicted wrapped phase map can be obtained, which gives direct information about the phase error
Fig. 31: Optimization of structured light pattern for single-shot 3D shape measurement based on deep learning. 
Deep neural network allows to determine which pattern design can yield the optimal 3D reconstruction results
Fig. 32: Comparison between deep learning and traditional algorithms should be objective. 
For several problems where traditional methods based on physics models, if implemented properly, can deliver straightforward and more than satisfying solutions, there is no need to use deep learning. However, sometimes this kind of âunnecessaryâ may not be recognized easily
In DIC and stereophotogrammetry, image analysis aims to determine the displacement vector of each pixel point between a pair of acquired images. Recently, deep learning has also been extensively applied to stereomatching in order to achieve improved performance compared with traditional subset correlation and subpixel refinement methods.
-
Subset Correlation: Zbontar and LeCun334 presented a deep-learning-based approach for estimating the disparity map from a rectified stereo image pair. A siamese-structured CNN was reconstructed to address the matching cost computation problem through learning the similarity measure from small image patches. The output of CNN was utilized for initializing the stereomatching cost, followed by some postprocessing processes, as shown in Fig. 20a. Figure 20dâh is the disparity images obtained from the traditional Census transform method335 and the deep-learning-based method, from which we can see that the deep-learning-based approach achieved a lower error rate and better prediction result. Luo et al.336 exploited a siamese CNN connected by point product layer to speed up the calculation of matching score and obtained improved matching performance. Recently, our group improved Luoâs network by introducing additional residual blocks and convolutional layers to the head of the neural network and replacing the original inner product with the fully connected layers with shared weights337. The improved network can extract a more accurate initial absolute disparity map from speckle image blocks after epipolar correction, and showed better matching capability than Luoâs network. Hartmann et al.338 constructed a CNN with five siamese branches to learn a matching function, which could directly predict a scalar similarity score from multiple image patches. It should be noted that the siamese CNN is one of the most widely used network structures in stereovision applications, which has been frequently employed and continuously improved for subset correlation tasks339,340,341,342,343. On a different note, Guo et al.344 improved the 3D-stacked hourglass network to obtain the cost volume by group-wise correlation and then realized stereomatching. Besides conventional supervised learning approaches, unsupervised learning was also introduced to subset correlation. Zhou et al.345 proposed an unsupervised deep-learning framework for learning the stereomatching cost, using a left-right consistency check to guide the training process to converge to a stable state. Kim et al.346 constructed a semi-supervised network to estimate stereo confidence. First, the matching probability was calculated according to the matching cost with residual networks. Then, the confidence measure was estimated based on a unified deep network. Finally, the confidence feature of the disparity map is extracted by synthesizing the results obtained by the two networks.
-
Subpixel refinement: Pang et al.347 proposed a cascade (two-stage) CNN architecture for subpixel stereomatching. Figure 21a shows the flowchart of their method. In the first stage, the disparity image with more details was obtained from the input stereo images through DispFulNet (âFulâ means full resolution) equipped with extra upsampling modules. Then the initialized disparity was rectified and the residual signals across multiple scales were generated through the hourglass structure DispResNet (âResâ means residual) in the second stage. According to the combination of the outputs from the two stages, the final disparity with subpixel accuracy can be obtained. Figure 21dâg shows the predicted disparity images and error distributions of the input stereo image pairs (Fig. 21b) obtained by DispFulNet and DispResNet. It can be seen from the experimental results that after the second stage of optimization, the quality of the disparity was significantly improved. Based on different considerations, a large variety of network structures were proposed for subpixel refinement, e.g., StereoNet348, LGC-Net349, DeepMVS350,351, StereoDRNet352, DeepPruner353, LAF-Net354, 3D CNN355, MADNet356, Unos357, left-right comparative recurrent model358, CNN-based disparity map optimization359, deep-learning-based fringe-image-assisted stereomatching method360, and UltraStereo361.
-
-
(3)
Postprocessing: Deep-learning techniques also play an important role in the final postprocessing stage of the image-processing architecture of optical metrology. Examples of applying deep learning for postprocessing are very diverse, including further optimization of the measurement results (e.g., phase denoising, error compensation, and refocusing) and converting the measured intermediate variable to the desired physical quantity (e.g., system calibration and phase-to-height mapping in FPP).





















-
Denoising: Montrésor et al.362 proposed to use DnCNN for phase denoising. As illustrated in Fig. 22a, the sine and cosine components of the noisy phase map were fed into a DnCNN to produce the corresponding denoised version, and the resultant phase information was calculated by the arctangent function. The phase was then fed back into and refined by DnCNN again, and this process was repeated several times to achieve a better denoising performance. In order to generate more realistic training datasets via simulation, the additive amplitude-dependent speckle noise was carefully modeled by taking its non-Gaussian statistics, non-stationary properties, and a correlation length into account. Figure 22bâe shows the comparison of the denoising results obtained by WFT114 and the deep-learning methods, suggesting that DnCNN yielded comparable standard deviation but lower peak-to-valley phase error than WFT. Yan et al.363 proposed a CNN-based wrapped phase denoising method. By filtering the original numerator and denominator of the arctangent function, phase denoising results can be achieved without tuning any parameters. They also presented a deep-learning-based phase denoising technique for digital holographic speckle pattern interferometry364. Their approach could obtain an enhanced wrapped phase map by significantly suppressing the speckle noise, and outperformed traditional phase denoising methods when processing phases with steep spatial gradients.
-
Digital refocusing: Ren et al.365 proposed the holographic reconstruction network (HRNet) to deal with the holographic reconstruction problem, which could perform automatic digital refocusing without employing any prior knowledge. Figure 23a gives the schematic of their deep-learning workflow, where a hologram input (the first block) was fed into HRNet, and then the reconstructed image (the third block) corresponding to the specific input was directly predicted. A typical lens-free Mach-Zehnder interferometer was constructed to acquire training input images, and traditional convolution method366, PCA aberration compensation226, manual artifacts removal, and phase unwrapping367 were successively employed to obtain the corresponding label images. Figure 23bâf shows the results of refocusing and hologram reconstruction with different methods, proving that the predicted images by HRNet were precisely in-focus and noise-free, whereas there are significant noises and artifacts in the reconstruction results obtained by traditional convolution and angular spectrum method368. Alternatively, the autofocusing problem in DH could be recast as a regression problem, with the focal distance being a continuous response corresponding to a digital hologram. Ren et al.369 constructed a CNN to achieve nonparametric autofocusing for digital holography, which could accurately predict the focal distance without knowing the physical parameters of the optical imaging system. Lee et al.370 constructed a CNN-based estimator combined with Discrete Fourier Transform (DFT) to realize the automatic focusing of off-axis digital holography. Their method can automatically determine the object-to-image distance rapidly and effectively, and a sharp in-focus image of the object can be reconstructed accurately. Shimobaba et al.371 used the regression-based CNN for holographic reconstruction, which could directly predict the sample depth position with millimeter accuracy from the power spectrum of the hologram. Jaferzadeh et al.372 proposed a regression-layer-toped CNN to determine the optimal focus position for numerical reconstruction of micro-sized objects, which can be extended to the study of biological samples such as cancer cells. Pitkäaho et al.373 constructed a CNN based on AlexNet and VGG16 to learn the defocus distances from a large number of holograms. The well-trained network can determine the high-accuracy in-focus position of a new hologram without resorting to conventional numerical propagation algorithms.
-
Error compensation: Nguyen et al.374 proposed a phase-aberration compensation framework combining CNN and Zernike polynomial fitting, as illustrated in Fig. 24a. The unwrapped phase aberration map of the hologram was fed into a CNN with the U-Net structure to detect the background regions, which were then sent into the Zernike polynomial fitting375 to determine the conjugated phase aberration. For training data collection/preparation, the PCA method226 was used for training data collection/preparation. Figure 24bâe gives the phase aberration compensation results of PCA and the deep-learning method, showing that the phase aberrations were completely eliminated by using the deep-learning technique, while they were still visible in the phase results obtained by the PCA method. In addition, the deep-learning-based technique was fully automatic, and the robustness and accuracy were shown to be superior to PCA. Lv et al.376 used DNN to compensate projector distortion-induced measurement errors in a FPP system. By learning the mapping between the 3D coordinates of the object and their corresponding distortion-induced error distribution, the distortion errors of the original test 3D data can be accurately predicted. Aguenounon et al.377 leveraged a DNN with a double U-Net structure to provide the single snapshot of optical properties imaging with the additional function of real-time profile correction. The real-time visualization of the resulting profile-corrected optical property (absorption and reduced scattering) map has the potential to be deployed to guide surgeons.
-
Quantity transformation: Li et al.378 proposed an accurate phase-height mapping approach for fringe projection based on a âshallowâ (3-layer) BP neural network. The flowchart of their method is shown in Fig. 25a, where the camera image coordinates (Xci, Yci) and their corresponding horizontal ones Xpi of the projector image were fed into the network to predict the desired 3D information (Xi, Yi, Zi). To obtain the training data, a standard calibration board with circle marks fixed on a high-precision displacement stage was captured at different Z-direction positions. With the captured images, the marksâ centers coordinates (Xci, Yci)with subpixel accuracy were extracted with the conventional circle center detection algorithm379, and the horizontal coordinates Xpi of the corresponding projector image for each mark center were calculated through the absolute phase value. Figure 25b shows the 3D reconstruction result of a standard stair sample predicted by the neural network. Figure 25c and d shows the error distributions of the measurement results obtained by traditional phase-height conversion method380 and neural network, showing that the learning-based method was insensitive to the fringe intensity nonlinearity and could recover the 3D shape of a workpiece with high accuracy.
End-to-end learning in optical metrology
As mentioned earlier, âdivide and conquerâ is a core idea of solving complex optical metrology problems by breaking the whole image-processing pipeline into several modules or sub-steps. On a different note, deep learning enables direct mapping between the original input and the desired output, and the whole process can be trained as a whole, in an end-to-end fashion. Although somewhat brute-force, such a straightforward treatment has been extensively used in deep learning, and gradually introduced to many subfields of optical metrology, e.g., FPP and DIC.
-
From fringe to 3D shape: In FPP, the imaging processing pipeline generally consists of pre-processing, phase demodulation, phase unwrapping, and phase-to-height conversion. Deep learning provides a viable and efficient way to reconsider the whole problem from a holistic perspective, taking human intervention out of the loop and solving the âfringe to 3D shapeâ problem in a purely data-driven manner. Based on this idea, Nguyen et al.381 proposed an end-to-end neural network to directly perform the mapping from a fringe pattern to its corresponding 3D shape, the flowchart of which is shown in Fig. 26a. Three different deep CNNs, including FCN, autoencoder299, and U-Net, were trained based on the datasets obtained by the conventional multi-frequency phase-shifting profilometry method. Figure 26b, c gives an input and its corresponding ground-truth 3D shape. Figure 26c shows the best 3D reconstruction results predicted by the three networks with the depth measurement accuracy of 2mm. Van et al.382 presented an SRCNN-based DNN to directly extract absolute height information from a single-fringe image. Through simulated fringe and depth image pairs, the trained network was able to obtain high-accuracy full-field depth information from a single-fringe pattern. Recently, they compared the effect of different loss functions (MAE, MSE, and SSIM) on a modified U-Net for mapping a fringe image to the corresponding depth, and designed a new mixed gradient loss function that yielded higher-quality 3D reconstructions than conventional ones383. Machineni et al.384 constructed a CNN with multiresolution similarity assessment to directly reconstruct the objectâs shape from the corresponding deformed fringe image. Their proposed method can achieve promising results under various challenging conditions such as low SNR, low fringe density, and high dynamic range. Zheng et al.385 utilized the calibration matrix from a real-world FPP system to construct its âdigital twinâ, which provided abundant simulation data (fringe pattern and corresponding depth map) required for the model training. The trained U-Net can then be employed to the real-world FPP system to extract the 3D geometry encoded in the fringe pattern in one step. Similarly, Wang et al.386 constructed a virtual FPP system for the training dataset generation. A modified loss function based on SSIM index was employed, providing improved performance in terms of measurement accuracy and detail preservation.
-
From stereo images to disparity: Deep learning can also be applied to DIC and stereophotogrammetry to bypass all intermediate image-processing steps in the pipeline for displacement and 3D reconstruction. Mayer et al.387 presented end-to-end networks for the estimation of disparity (DispNet) and optical flow (FlowNet). In DispNet, a 1D correlation was proposed along the disparity line corresponding to the stereo cost volume. In addition, they also offered a large synthetic dataset, Scene Flow388, for training large-scale stereomatching networks. Kendall et al.389 established an end-to-end Geometry and Context Network (GC-Net) mapping from a rectified pair of stereo images to disparity maps with subpixel accuracy (Fig. 27a). Stereo images were fed into the network to directly output disparity images of two perspectives. Figure 27bâd shows the test results on Scene Flow, where Fig. 27b is the left input, Fig. 27c is the disparity predicted by deep learning, and Fig. 27d is the ground truth. Experimental results show that the end-to-end learning method produced high-resolution disparity images and could tolerate large occlusions. Chang et al.390 developed a pyramid stereomatching network (PSMNet) to enhance the matching accuracy by using the 3D CNN-based spatial pyramid pooling and multiple hourglass networks. Zhang et al.391 proposed a cost aggregation network incorporating the local guided filter and semi-global-matching-based cost aggregation, achieving higher matching quality as well as better network generalization. Recently, our group proposed an end-to-end speckle correlation strategy for 3D shape measurement, where a multiscale residual subnetwork was utilized to obtain feature maps of stereo speckle images, and the 4D cost volume at one-fourth of the original392. Besides, a saliency detection network was integrated to generate a pixel-wise mask to exclude the shadow-noised regions. Nguyen et al.393 used three U-Net-based networks to convert a single speckle image into its corresponding 3D information. It should be mentioned that stereophotogrammetry is a representative field that deep learning has been extensively applied. Many other end-to-end deep-learning structures directly mapping stereo images to disparity have been proposed, such as hybrid CNN-CRF models394, Demon (CNN-based)395, MVSNet (CNN-based)396, CNN-based disparity estimation through feature constancy397, Segstereo398, EdgeStereo399, stereomatching with explicit cost aggregation architecture400, HyperDepth401, practical deep stereo (PDS)402, RNN-based stereomatching403,404, and unsupervised learning405,406,407,408,409. For DIC, Boukhtache et al.410 presented an enhanced FlowNet (so-called StrainNet) to predict displacement and strain fields from pairs of deformed and reference images of a flat speckled surface. Their experimental results demonstrated the feasibility of the deep-learning approach for accurate pixel-wise subpixel measurement over full displacement fields. Min et al.411 proposed a 3D CNN-based strain measurement method, which allowed simultaneous characterization in spatial and temporal domains from the surface images obtained during a tensile test of BeCu thin film. Rezaie et al.412 compared the performance of conventional DIC method and their deep-learning method based on U-Net for detecting cracks on stone masonry wall images, showing that the learning-based method could detect most visible cracks and better preserve the crack geometry.
It should be mentioned that, not just limited to phase or correlation measurement techniques, deep learning has also been widely adopted in many other fields of optical metrology. However, due to space limitations, it is not possible to describe or discuss all of them. Examples include but are not limited to the time of flight (ToF)413,414,415,416,417,418, photometric stereo419,420,421,422,423,424,425, wavefront sensing426,427,428,429, aberrations characterization430, and fiber optic imaging431,432,433,434,435, etc.
After reviewing hundreds of recent works leveraging deep learning for different optical metrology tasks, readers may still be interested to know to apply these new data-driven approaches to their own problems or projects. To help the reader, we present a step-by-step guide to applying deep learning to optical metrology in the Supplementary Information, taking phase demodulation from a single-fringe pattern as an example. We explain how to build a DNN with fully convolutional network architectures and train it with the experimentally collected training dataset. We also distribute the source code and the corresponding datasets for this example. Based on this example, we demonstrate that a well-trained DNN can accomplish the phase-demodulation task in an accurate and efficient manner, using only a single-fringe pattern as input. Thus, it is capable of combining the single-frame strength of the spatial phase demodulation methods with the high-measurement accuracy of the temporal phase-demodulation methods. The interested reader may refer to the Supplementary Information for the step-by-step tutorial.
Deep learning in optical metrology: challenges
Our review in the last section shows that the deep-learning solutions in optical metrology are straightforward, but have led to improved performance compared with the state-of-the-art. In this session, we will shift our attention to reveal some challenges of the use of deep learning in optical metrology, which require further attention and careful consideration:
-
High cost of collecting and labeling experimental training data: Most of the deep-learning techniques reviewed belong to supervised learning, which requires a large amount of labeled data to train the network. To account for real experimental conditions, deep-learning approaches can benefit from large amounts of experimental training data. Since these data serve as ground truth with sufficiently high accuracy, they are usually expensive to collect436. In addition, since the optical metrology system is highly customized, training data collected by one system may not be suitable for another system of the same type. This may explain why there were far fewer publicly available datasets in the field of optical metrology (especially compared with the computer vision community). Without such public benchmark datasets, it is difficult to make a fair and standardized comparison between different algorithms. Although some emerging machine learning approaches, such as transfer learning437, few-shot learning438, unsupervised learning244, and weak-supervised learning439), can decrease the reliance on the amount of data to some extent, their performance is not comparable to that of supervised learning with large data numbers so far.
-
Ground truth inaccessible for experimental data: In many areas of optical metrology, e.g., fringe or phase denoising, it is infeasible or even impossible to get the actual ground truth of the experimental data. As discussed in previous sections, generating a training dataset by simulating the forward image formation process can bypass this difficulty362,385, often at the price of compromised actual performance when the knowledge of the forward image formation model \({{{\mathcal{A}}}}\) is imprecise or simulated dataset fails to reflect the real experimental system realistically and comprehensively. An alternative approach to this issue is to create a âquasi-experimentalâ dataset by collecting experimental raw data and then using the conventional state-of-the-art solutions to get the corresponding labels308,309,310. Essentially, the network is trained to âduplicateâ the approximate inverse operator \(\tilde {{{\mathcal{A}}}}^{ - 1}\) corresponding to the conventional algorithm that is used to generate the labels. After training, the network is able to emulate the conventional reconstruction algorithm \(\widehat {{{{\mathcal{R}}}}_\theta }\left( {{{\mathbf{I}}}} \right) \approx {{{\mathrm{ }}}}\tilde {{{\mathcal{A}}}}^{ - 1}\left( {{{\mathbf{I}}}} \right)\), but the improvement in performance over conventional approaches becomes an unreasonable expectation.
-
Empiricism in network design and training: So far, there is no standard paradigm for selecting appropriate DNN architectures because it requires a comprehensive understanding of the topology, training methods, and other parameters. In practice, we usually determine our network structure by evaluating different available candidate models, or comparing similar task-specific models by training them with different hyperparameters settings (network layers, neural units, and activation functions) on a specific validation dataset440. However, the overwhelming number of deep-learning models often limits one to evaluating only a few of the most trustworthy models, which may lead to suboptimal results. Therefore, one should learn how to quickly and efficiently narrow down the range of available models to find those most likely to be best performing on a specific type of problem. In addition, training a DNN is generally laborious and time-consuming, and becomes even worse with repetitive adjustments in the network architecture or hyperparameters to prevent overfitting and convergence issues.
-
Lack of generalization ability after specific sample training: The generalization ability of deep-learning approaches is closely related to the size and diversity of training samples. Generally, deep-learning architectures used in optical metrology are highly specialized to a specific domain, and they should be implemented with extreme care and caution when solving issues that do not pertain to the same domain. Thus, we cannot ignore the risk that when a never-before-experienced input differs even slightly from what they encountered at the training stage, the mapping \(\widehat {{{{\mathcal{R}}}}_\theta }\) established by deep networks may quickly stop making sense441. This is quite different from the traditional optical metrology solutions in which the reliability of the reconstruction can be secured for diverse types of samples as long as âthe forward model \({{{\mathcal{A}}}}\) is accurateâ and âthe corresponding reconstruction algorithm \(\tilde {{{\mathcal{A}}}}^{ - 1}\) is effectiveâ.
-
âDeep learning in computer visionâ â âDeep learning in optical metrologyâ: Deep learning is essentially the process of using computers to help us find the underlying patterns within the training dataset. Since the information cannot be âborn out of nothingâ, DNNs cannot always produce a provably correct solution. Compared with many computer vision tasks, optical metrology concerns more on accuracy, reliability, repeatability, and traceability442. For example, surface defect inspection is an indispensable quality-control procedure in manufacturing processes443. When using deep learning for optical metrological inspection, one may face the risk that a defect in an industrial component is âsmoothed outâ and undetected by an overfitted DNN in the inspection stage, which will make the entire production run defective. Since the success of deep learning depends on the âcommonâ features learned and extracted from the training samples, which may lead to unsatisfactory results when facing ârare samplesâ.
-
âDeep learningâ lacks the ability of âdeep understandingâ: The âblack boxâ nature of DNNs, which is arguably one of their most well-known disadvantages, prevents us from knowing how the neural network generates expected results from specific inputs by learning a large amount of training data. For example, when we send a fringe pattern into a neural network, and it outputs a poor phase image, it is not easy to comprehend what makes it arrive at such a prediction. Interpretability is critical in optical metrology because it ensures the traceability of the mistake. Consequently, most researchers in optical metrology community use deep-learning approaches in a pragmatic fashion without the possibility to explain why it provides good results or without the ability to explain the logical bases and apply modifications in the case of underperformance.
Deep learning in optical metrology: future directions
Although the above challenges have not been adequately addressed, optical metrology is now surfing the wave of deep learning, following a trend similarly being experienced in many other fields. This field is still young, but is expected to play an increasingly prominent role in the future development of optical metrology, especially with the evolution of computer science and AI technology.
-
Hybrid, composite, and automated learning: It must be admitted that at this stage, deep-learning methods for optical metrology are still limited to some elementary techniques. There is further untapped potential as a number of latest innovations in deep learning can be directly introduced into the context of optical metrology. (1) Hybrid learning methods, such as semi-supervised242, unsupervised244, and self-supervised learning444, are capable of extracting valuable insights from unlabeled data, which is extremely attractive as the availability of ground-truth or labeled data in optical metrology is very limited. For example, GANs utilize two networks in a competitive manner, generator and discriminator, to deceive each other during the training process to generate the final prediction without specific labels266. In stereovision, the network models trained by unsupervised methods have been shown to produce better disparity prediction results in real scenes345. (2) Composite learning approaches attempt to combine different models pretrained on a similar task to produce a composite model with improved performance437 or search for the optimal network architecture in the reinforcement learning environment for a certain dataset445. They are premised on the idea that a singular model, even very large, cannot outperform a compositional model with several small models/components, each being delegated to specialize in part of the task. As optical metrology tasks are getting more and more complicated, composite learning can deconstruct one huge task into several simpler, or single-function components and make them work together, or against each other, producing a more compressive and powerful model. (3) Automated machine learning (AutoML) approaches, such as Google AutoML446 and Azure AutoML447, is developed to execute tedious modeling tasks that once performed by professional scientists440,448. It burns through an enormous number of models and the associated hyperparameters on the raw input data to decide what model is best applied to it. Consequently, AutoML is expected to permit even âcitizenâ AI scientists with their background in optical metrology to make streamlined use cases by only utilizing their domain expertise, offering practitioners a competitive advantage with minimum investments.
-
Physics-informed deep learning: Unlike traditional physics-model-based optical metrology methods for which the domain knowledge is carefully engineered into solutions, most of the current deep-learning-based optical metrology methods do not benefit so much from such prior knowledge but rather learn the solution from scratch by making use of massive training data. In contrast, if the physics laws governing the image formation (the knowledge about the forward image formation model \({{{\mathcal{A}}}}\)) are knownâeven partially, they should be naturally incorporated into the DNN model so that the training data and network parameters are not wasted on âlearning the physicsâ. For example, in fringe analysis, inspired by the conventional phase-shifting techniques, Feng et al.50 proposed to learn the sine and cosine components of the fringe pattern, based on which the wrapped phase can be calculated by the arctangent function (Fig. 28c, d). This method shows a significant gain in performance than directly using an end-to-end network structure50 (Fig. 28a, b). Goy et al.302 suggested a method for low-photon count phase retrieval where the noisy input image was converted into an approximant. As the approximant obtained by prior knowledge is much closer to the final prediction than the raw low-photon image, the phase reconstruction accuracy by using deep learning can be improved significantly. Wang et al.449 incorporated the diffraction model of numerical propagation into a DNN for phase retrieval. By minimizing the difference between the actual input image and the predicted input image, DNN learns how to reconstruct the phase that best matches the measurements without any ground-truth data.
-
Interpretable deep learning: As we have already highlighted in the previous sections, most researchers in optical metrology use deep-learning approaches intuitively without the possibility to explain why it produces such âgoodâ results. This can be very problematic in high-stakes settings such as industrial inspection, quality control, and medical diagnose where the decisions of algorithms must be explainable, or where accountability is required. Academics in deep learning are acutely aware of this interpretability problem, and there have been several developments in recent years for visualizing the features and representations they have learned by DNNs284. On the other hand, often applied to high-risk scenarios, optical metrology is among the most significant deep-learning challengesâwe are dealing with unknown, uncertain, ambiguous, incomplete, noisy, inaccurate, and missing datasets in high-dimensional spaces. The unexplainability and incomprehensibility of deep learning also imply the predictions are at risk of failure. Figure 29 illustrates one such example, where a well-trained deep-learning model for stereophase unwrapping fails when there exists depth ambiguity in a certain perspective332. Therefore, explainability will become a key strength in deep-learning techniques to interpret and explain models, which would significantly expand the usefulness of deep-learning methods in optical metrology.
-
Uncertainty quantification: Characterizing uncertainty in deep-learning solutions can help make better decisions and take precautions against erroneous predictions, which is essential for many optical metrology tasks450. However, most deep-learning methods reviewed in this work cannot provide uncertainty estimates. In recent years, Bayesian deep learning has emerged as a unified probabilistic framework that tightly integrates deep learning with Bayesian models451. By using a GAN training framework to estimate a posterior distribution of images fitting a given measurement dataset (or estimation statistics derived from the posterior), Bayesian convolutional neural networks (BNNs) can quantify the reliability of predictions through two predictive uncertainties, including model uncertainty and data uncertainty, akin to epistemic and revelation uncertainty in Bayesian analysis, respectively452. It is expected to be adopted in optical metrology applications, e.g., fringe pattern analysis, to give pixel-wise variance estimates and data uncertainty evaluation (Fig. 30)453. The latter further allows assessment of the randomness of predictions stemming from data imperfections, including noise, incompleteness of the training data, and other experimental perturbations. Incorporating similar uncertainty quantification into other deep-learning-based optical metrology methods, especially when the ground truth is unavailable, is an interesting direction for future research.
-
Guiding the metrology system design: Most of the current work using deep learning in optical metrology only considers how to reconstruct the measured data as a postprocessing algorithm while ignoring the way how the image data should be formed. However, an important feature of optical metrology methods is their active nature, especially with respect to the way of manipulating the illumination. For example, in FPP, the structure of the illumination is modulated systematically throughout the object surface to deliver high accuracy and robustness in establishing the triangulation. The design of the illumination coding strategy is curial to improving the measurement accuracy removing the ambiguity of the depth reconstruction with a minimum number of image acquisitions. However, this problem has long been tackled using heuristics like composite coding, frequency multiplexing, and color multiplexing, which does not guarantee optimality (in terms of facilitating the recovery of desired information). Deep learning provides a mechanism to optimize the system design in a more principled way. By integrating the image formation model (with trainable parameters controlling the image acquisition) into the reconstruction network, the system design and the reconstruction algorithm (i.e., both \({{{\mathcal{A}}}}\) and the corresponding \(\widehat {{{{\mathcal{R}}}}_\theta }\)) can be jointly optimized with the training data454. It allows us to determine which type of system design can yield the best results for a particular deep-learning-driven task. Such an idea has been successfully demonstrated in designing optimal illumination patterns for computational microscopes455,456,457. We hope that this âjoint optimizationâ network can effectively bridge the gap between how images should be acquired and how these images should be post-processed by deep learning, and can be widely adopted in designing the optical metrology systems, such as the fringe pattern design in FPP (Fig. 31), and the speckle pattern design in DIC, etc.
-
Both âdeepâ and âin-depthâ: Should we use deep learning or traditional optical metrology algorithms? It is a tough question to answer because it depends heavily on the problem to be solved. Considering the âno free lunch theoremâ, the selection between deep-learning and traditional algorithms should be considered rationally. For several problems where traditional methods based on physics models, if implemented properly, can deliver straightforward and more than satisfying solutions, there is no need to use deep learning. However, sometimes this kind of âunnecessaryâ may not be recognized easily. While being functionally effective, we should keep in mind that âhow best deep learning can doâ generally depends on âhow reliable the training data we can provide.â For example, though the popular âlearning from simulationâ scheme used in optical metrology eliminates the dependence on huge labeled experimental data, the inconsistency between the image formation model and actual experimental condition leads to additional challenges of âdomain adaptationâ. Therefore, our personal view is that deep learning does not (at least at the current stage) make our research easier. On the contrary, it raises the threshold for optical metrology research because it requires researchers not only need to use and understand deep learning deeply but also need to take âin-depthâ research in traditional algorithms so as to make an impartial and objective assessment between deep learning and traditional optical metrology algorithms (Fig. 32).
Conclusions
A brief summary of this review indicates that there has been significant interest in the advancement of optical metrology technologies using deep-learning architectures. The rapid development of deep-learning technology has led to a paradigm shift from physics- and knowledge-based modeling to data-driven learning for solving a wide range of optical metrology tasks. In general, deep learning is particularly advantageous for many problems in optical metrology whose physical models are complicated and acquired information is limited, e.g., in harsh environments and many challenging applications. Strong empirical and experimental evidence suggests that using problem-specific deep-learning models outperforms conventional knowledge or physical model-based approaches.
Despite the promisingâin many cases pretty impressiveâresults that have been reported in the literature, potential problems and challenges remain. For model training, we need to acquire large amounts of experimental data with labels, which, even if available, is laborious and requires professional experts. We have been looking for the theoretical groundwork that would clearly explain the mechanisms and ways to the optimal selection of network structure and training algorithm for a specific task, or to profoundly comprehend why a particular network structure or algorithm is effective in a given task or not. Furthermore, deep-learning approaches have often been regarded as âblack boxesâ, and in optical metrology, accountability is essential and can cause severe consequences. Combining Bayesian statistics with deep neuron networks to obtain quantitative uncertainty estimates allows us to assess when the network yields unreliable predictions. A synergy of the physics-based models that describe the a priori knowledge of the image formation and data-driven models that learn a regularizer from the experimental data can bring our domain expertise into deep learning to provide more physically plausible solutions to specific optical metrology problems. Leveraging these emerging technologies in the application of deep-learning methods to optical metrology could promote and accelerate the recognition and acceptance of deep learning in more application areas. These are among the most critical issues that will continue to attract the interest of deep-learning research in the optical metrology community in the years to come.
In summary, although for different optical metrology tasks, deep-learning techniques can bring substantial improvements compared to traditional methods, the field is still at the early stage of development. Many researchers are still skeptical and maintain a wait-and-see attitude towards its applications involving industrial inspection and medical care, etc. Shall we accept deep learning as the key problem-solving tool? Or should we reject such a black-box solution? These are controversial issues in the optical metrology community today. Looking on the bright side, it has promoted an exciting trend and fostered expectations of the transformative potential it may bring to the optical metrology society. However, we should not overestimate the power of deep learning by considering it as a silver bullet for every challenge encountered in the future development of optical metrology. In practice, we should assess whether the large amount of data and computational resources required to use deep learning for a particular task is worthwhile, especially when other conventional algorithms may yield comparable performance with lower complexity and higher interpretability. We envisage that deep learning will not replace the role of traditional technologies within the field of optical metrology for the years to come, but will form a cooperative and complementary relationship, which may eventually become a symbiotic relationship in the future.
Change history
27 March 2022
A Correction to this paper has been published: https://doi.org/10.1038/s41377-022-00757-0
References
GÃ¥svik, K. J. Optical Metrology, 3rd edn. (Wiley, 2002).
Yoshizawa, T. Handbook of Optical Metrology: Principles and Applications, 2nd edn. (CRC Press, 2017).
Sirohi, R. S. Introduction to Optical Metrology (CRC Press, 2016).
Malacara, D. Optical Shop Testing, 3rd edn. (John Wiley & Sons, 2007).
Harding, K. Handbook of Optical Dimensional Metrology (CRC Press, 2013).
Chen, Z. G. & Segev, M. Highlighting photonics: looking into the next decade. eLight 1, 2 (2021).
Kleppner, D. On the matter of the meter. Phys. Today 54, 11â12 (2001).
Kulkarni, R. & Rastogi, P. Optical measurement techniquesâa push for digitization. Opt. Lasers Eng. 87, 1â17 (2016).
Chen, F., Brown, G. M. & Song, M. M. Overview of 3-D shape measurement using optical methods. Optical Eng. 39, 10â22 (2000).
Blais, F. Review of 20 years of range sensor development. J. Electron. Imaging 13, 231â243 (2004).
Rastogi, P. Digital Optical Measurement Techniques and Applications (Artech House, 2015).
Osten, W. Optical metrology: the long and unstoppable way to become an outstanding measuring tool. In Proceedings of SPIE 10834, Speckle 2018: VII International Conference on Speckle Metrology. 1083402 (SPIE, Janów Podlaski, Poland, 2018).
Wyant, J. C. & Creath, K. Recent advances in interferometric optical testing. Laser Focus 21, 118â132 (1985).
Takeda, M. & Kujawinska, M. Lasers revolutionized optical metrology. https://spie.org/news/spie-professional-magazine-archive/2010-october/lasers-revolutionized-optical-metrology?SSO=1 (2010).
Denisyuk, Y. N. On the reflection of optical properties of an object in a wave field of light scattered by it. Dokl. Akad. Nauk SSSR 144, 1275â1278 (1962).
Leith, E. N. & Upatnieks, J. Reconstructed wavefronts and communication theory. J. Optical Soc. Am. 52, 1123â1130 (1962).
Gabor, D. A new microscopic principle. Nature 161, 777â778 (1948).
Reid, G. T. Automatic fringe pattern analysis: a review. Opt. Lasers Eng. 7, 37â68 (1986).
Rajshekhar, G. & Rastogi, P. Fringe analysis: premise and perspectives. Opt. Lasers Eng. 50, iiiâx (2012).
Rastogi, P. & Hack, E. Phase Estimation in Optical Interferometry (CRC Press, 2015).
Hariharan, P., Oreb, B. F. & Eiju, T. Digital phase-shifting interferometry: a simple error-compensating phase calculation algorithm. Appl. Opt. 26, 2504â2506 (1987).
Schnars, U. & Jüptner, W. Digital Holography: Digital Hologram Recording, Numerical Reconstruction, and Related Techniques (Springer Science & Business Media, 2005).
Pan, B. et al. Two-dimensional digital image correlation for in-plane displacement and strain measurement: a review. Meas. Sci. Technol. 20, 062001 (2009).
Raskar, R., Agrawal, A. & Tumblin, J. Coded exposure photography: motion deblurring using fluttered shutter. ACM Trans. Graph. 25, 795â804 (2006).
Ritschl, L. et al. Improved total variation-based CT image reconstruction applied to clinical data. Phys. Med. Biol. 56, 1545 (2011).
Edgar, M. P., Gibson, G. M. & Padgett, M. J. Principles and prospects for single-pixel imaging. Nat. Photonics 13, 13â20 (2019).
Katz, O. et al. Non-invasive single-shot imaging through scattering layers and around corners via speckle correlations. Nat. Photonics 8, 784â790 (2014).
Stuart, A. M. Inverse problems: a Bayesian perspective. Acta Numerica 19, 451â559 (2010).
Osher, S. et al. An iterative regularization method for total variation-based image restoration. Multiscale Modeling Simul. 4, 460â489 (2005).
Goldstein, T. & Osher, S. The split Bregman method for L1-regularized problems. SIAM J. Imaging Sci. 2, 323â343 (2009).
Osten, W. What optical metrology can do for experimental mechanics? Appl. Mech. Mater. 70, 1â20 (2011).
Zuo, C. et al. Phase shifting algorithms for fringe projection profilometry: a review. Opt. Lasers Eng. 109, 23â59 (2018).
Baraniuk, R. G. Compressive sensing [lecture notes]. IEEE Signal Process. Mag. 24, 118â121 (2007).
Zibulevsky, M. & Elad, M. L1-L2 optimization in signal and image processing. IEEE Signal Process. Mag. 27, 76â88 (2010).
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521, 436â444 (2015).
Goodfellow, I., Bengio, Y. & Courville, A. Deep Learning (MIT Press Cambridge, 2016).
Chang, X. Y., Bian, L. H. & Zhang, J. Large-scale phase retrieval. eLight 1, 4 (2021).
Fukushima, K. Neocognitron: a self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol. Cybern. 36, 193â202 (1980).
Schmidhuber, J. Deep learning in neural networks: an overview. Neural Netw. 61, 85â117 (2015).
Baccouche, M. et al. Sequential deep learning for human action recognition. In Proceedings of the 2nd International Workshop on Human Behavior Understanding. 29â39 (Springer, Amsterdam, 2011).
Charles, R. Q. et al. PointNet: deep learning on point sets for 3D classification and segmentation. In Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. 77â85 (IEEE, Honolulu, 2017).
Ouyang, W. L. & Wang, X. G. Joint deep learning for pedestrian detection. In Proceedings of 2013 IEEE International Conference on Computer Vision. 2056â2063 (IEEE, Sydney, NSW, 2013).
Dong, C. et al. Learning a deep convolutional network for image super-resolution. In Proceedings of 13th European Conference on Computer Vision. 184â199 (Springer, Zurich, 2014).
Litjens, G. et al. A survey on deep learning in medical image analysis. Med. Image Anal. 42, 60â88 (2017).
Barbastathis, G., Ozcan, A. & Situ, G. On the use of deep learning for computational imaging. Optica 6, 921â943 (2019).
Wang, H. D. et al. Deep learning enables cross-modality super-resolution in fluorescence microscopy. Nat. Methods 16, 103â110 (2019).
Rivenson, Y. et al. Phase recovery and holographic image reconstruction using deep learning in neural networks. Light.: Sci. Appl. 7, 17141 (2018).
Wang, F. et al. Learning from simulation: an end-to-end deep-learning approach for computational ghost imaging. Opt. Express 27, 25560â25572 (2019).
Li, S. et al. Imaging through glass diffusers using densely connected convolutional networks. Optica 5, 803â813 (2018).
Feng, S. J. et al. Fringe pattern analysis using deep learning. Adv. Photonics 1, 025001 (2019).
Shi, J. S. et al. Label enhanced and patch based deep learning for phase retrieval from single frame fringe pattern in fringe projection 3D measurement. Opt. Express 27, 28929â28943 (2019).
Yin, W. et al. Temporal phase unwrapping using deep learning. Sci. Rep. 9, 20175 (2019).
Zhang, T. et al. Rapid and robust two-dimensional phase unwrapping via deep learning. Opt. Express 27, 23173â23185 (2019).
Hao, F. G. et al. Batch denoising of ESPI fringe patterns based on convolutional neural network. Appl. Opt. 58, 3338â3346 (2019).
Yan, K. T. et al. Fringe pattern denoising based on deep learning. Opt. Commun. 437, 148â152 (2019).
Gerchberg, R. W. & Saxton, W. O. A practical algorithm for the determination of phase from image and diffraction plane pictures. Optik 35, 237â246 (1972).
Fienup, J. R. Phase retrieval algorithms: a comparison. Appl. Opt. 21, 2758â2769 (1982).
Teague, M. R. Deterministic phase retrieval: a Greenâs function solution. J. Optical Soc. Am. 73, 1434â1441 (1983).
Zuo, C. et al. Transport of intensity equation: a tutorial. Opt. Lasers Eng. 135, 106187 (2020).
Zhang, F. C., Pedrini, G. & Osten, W. Phase retrieval of arbitrary complex-valued fields through aperture-plane modulation. Phys. Rev. A 75, 043805 (2007).
Faulkner, H. M. L. & Rodenburg, J. M. Movable aperture lensless transmission microscopy: a novel phase retrieval algorithm. Phys. Rev. Lett. 93, 023903 (2004).
Zheng, G. N. et al. Concept, implementations and applications of Fourier ptychography. Nat. Rev. Phys. 3, 207â223 (2021).
Platt, B. C. & Shack, R. History and principles of Shack-Hartmann wavefront sensing. J. Refractive Surg. 17, S573âS577 (2001).
Ragazzoni, R. Pupil plane wavefront sensing with an oscillating prism. J. Mod. Opt. 43, 289â293 (1996).
Falldorf, C., von Kopylow, C. & Bergmann, R. B. Wave field sensing by means of computational shear interferometry. J. Optical Soc. Am. A 30, 1905â1912 (2013).
Fienup, J. R. Phase retrieval for optical metrology: past, present and future. in Optical Fabrication and Testing (eds Reinhard, V.) 2017. OW2B-1 (Optical Society of America, 2017).
Claus, D. et al. Dual wavelength optical metrology using ptychography. J. Opt. 15, 035702 (2013).
Falldorf, C., Agour, M. & Bergmann, R. B. Digital holography and quantitative phase contrast imaging using computational shear interferometry. Optical Eng. 54, 024110 (2015).
Creath, K. V phase-measurement interferometry techniques. Prog. Opt. 26, 349â393 (1988).
Hariharan, P. Basics of Interferometry, 2nd edn. (Elsevier, 2007).
Aben, H. & Guillemet, C. Integrated photoelasticity. in Photoelasticity of Glass (eds Aben, H. & Guillemet, C.) 86â101 (Springer, 1993).
Asundi, A. Phase shifting in photoelasticity. Exp. Tech. 17, 19â23 (1993).
Ramesh, K. & Lewis, G. Digital photoelasticity: advanced techniques and applications. Appl. Mech. Rev. 55, B69âB71 (2002).
Sciammarella, C. A. The moiré methodâa review. Exp. Mech. 22, 418â433 (1982).
Post, D., Han, B. & Ifju, P. High Sensitivity Moiré: Experimental Analysis for Mechanics and Materials. (Springer Science & Business Media, 2012).
Durelli, A. J. & Parks, V. J. Moiré Analysis of Strain (Prentice Hall, 1970).
Chiang, F. P. Moiré methods of strain analysis. Exp. Mech. 19, 290â308 (1979).
Post, D., Han, B. & Ifju, P. Moiré interferometry. in High Sensitivity Moiré: Experimental Analysis for Mechanics and Materials (eds Post, D., Han, B. & Ifju, P.) 135â226 (Springer, 1994).
Rastogi, P. K. Holographic Interferometry: Principles and Methods (Springer-Verlag, 1994).
Kreis, T. Handbook of Holographic Interferometry: Optical and Digital Methods (John Wiley & Sons, 2004).
Hariharan, P., Oreb, B. F. & Brown, N. Real-time holographic interferometry: a microcomputer system for the measurement of vector displacements. Appl. Opt. 22, 876â880 (1983).
Heflinger, L. O., Wuerker, R. F. & Brooks, R. E. Holographic interferometry. J. Appl. Phys. 37, 642â649 (1966).
Khanna, S. M. & Tonndorf, J. Tympanic membrane vibrations in cats studied by time-averaged holography. J. Acoustical Soc. Am. 51, 1904â1920 (1972).
Tonndorf, J. & Khanna, S. M. Tympanic-membrane vibrations in human cadaver ears studied by time-averaged holography. J. Acoustical Soc. Am. 52, 1221â1233 (1972).
Schnars, U. et al. Digital holography. in Digital Holography and Wavefront Sensing: Principles, Techniques and Applications 2nd edn. (eds Schnars, U. et al.) 39â68 (Springer, 2015).
Cuche, E., Bevilacqua, F. & Depeursinge, C. Digital holography for quantitative phase-contrast imaging. Opt. Lett. 24, 291â293 (1999).
Xu, L. et al. Studies of digital microscopic holography with applications to microstructure testing. Appl. Opt. 40, 5046â5051 (2001).
Picart, P. et al. Time-averaged digital holography. Opt. Lett. 28, 1900â1902 (2003).
Singh, V. R. et al. Dynamic characterization of MEMS diaphragm using time averaged in-line digital holography. Opt. Commun. 280, 285â290 (2007).
Colomb, T. et al. Automatic procedure for aberration compensation in digital holographic microscopy and applications to specimen shape compensation. Appl. Opt. 45, 851â863 (2006).
Løkberg, O. J. Electronic speckle pattern interferometry. in Optical Metrology (ed. Soares, O. D. D.) 542â572 (Springer, 1987).
Rastogi, P. K. Digital Speckle Pattern Interferometry and Related Techniques (Wiley, 2001).
Hung, Y. Y. Shearography: a new optical method for strain measurement and nondestructive testing. Optical Eng. 21, 213391 (1982).
Hung, Y. Y. & Ho, H. P. Shearography: an optical measurement technique and applications. Mater. Sci. Eng.: R: Rep. 49, 61â87 (2005).
Gorthi, S. S. & Rastogi, P. Fringe projection techniques: whither we are? Opt. Lasers Eng. 48, 133â140 (2010).
Geng, J. Structured-light 3D surface imaging: a tutorial. Adv. Opt. Photonics 3, 128â160 (2011).
Knauer, M. C., Kaminski, J. & Hausler, G. Phase measuring deflectometry: a new approach to measure specular free-form surfaces. In Proceedings of SPIE 5457, Optical Metrology in Production Engineering. 366â376 (IEEE, Strasbourg, 2004).
Huang, L. et al. Review of phase measuring deflectometry. Opt. Lasers Eng. 107, 247â257 (2018).
Zhang, Z. H. et al. Three-dimensional shape measurements of specular objects using phase-measuring deflectometry. Sensors 17, 2835 (2017).
Xu, Y. J., Gao, F. & Jiang, X. Q. A brief review of the technological advancements of phase measuring deflectometry. PhotoniX 1, 14 (2020).
Chu, T. C., Ranson, W. F. & Sutton, M. A. Applications of digital-image-correlation techniques to experimental mechanics. Exp. Mech. 25, 232â244 (1985).
Schreier, H, Orteu, J. J & Sutton, M. A. Image Correlation for Shape, Motion and Deformation Measurements: Basic Concepts. Theory and Applications (Springer, 2009).
Verhulp, E., van Rietbergen, B. & Huiskes, R. A three-dimensional digital image correlation technique for strain measurements in microstructures. J. Biomech. 37, 1313â1320 (2004).
Sutton, M. A. et al. The effect of out-of-plane motion on 2D and 3D digital image correlation measurements. Opt. Lasers Eng. 46, 746â757 (2008).
Pan, B. Digital image correlation for surface deformation measurement: historical developments, recent advances and future goals. Meas. Sci. Technol. 29, 082001 (2018).
Marr, D. & Poggio, T. A computational theory of human stereo vision. Philos. Trans. R. Soc. B: Biol. Sci. 204, 301â328 (1979).
Luhmann, T. et al. Close-Range Photogrammetry and 3D Imaging, 2nd edn. (De Gruyter, 2014).
Fusiello, A., Trucco, E. & Verri, A. A compact algorithm for rectification of stereo pairs. Mach. Vis. Appl. 12, 16â22 (2000).
Pitas, I. Digital Image Processing Algorithms and Applications (Wiley, 2000).
Yu, Q. F. et al. Spin filtering with curve windows for interferometric fringe patterns. Appl. Opt. 41, 2650â2654 (2002).
Tang, C. et al. Second-order oriented partial-differential equations for denoising in electronic-speckle-pattern interferometry fringes. Opt. Lett. 33, 2179â2181 (2008).
Wang, H. X. et al. Fringe pattern denoising using coherence-enhancing diffusion. Opt. Lett. 34, 1141â1143 (2009).
Kaufmann, G. H. & Galizzi, G. E. Speckle noise reduction in television holography fringes using wavelet thresholding. Optical Eng. 35, 9â14 (1996).
Kemao, Q. Windowed Fourier transform for fringe pattern analysis. Appl. Opt. 43, 2695â2702 (2004).
Kemao, Q. Two-dimensional windowed Fourier transform for fringe pattern analysis: principles, applications and implementations. Opt. Lasers Eng. 45, 304â317 (2007).
Bianco, V. et al. Quasi noise-free digital holography. Light.: Sci. Appl. 5, e16142 (2016).
Kulkarni, R. & Rastogi, P. Fringe denoising algorithms: a review. Opti. Lasers Eng. https://doi.org/10.1016/j.optlaseng.2020.106190 (2020).
Bianco, V. et al. Strategies for reducing speckle noise in digital holography. Light.: Sci. Appl. 7, 48 (2018).
Zhi, H. & Johansson, R. B. Adaptive filter for enhancement of fringe patterns. Opt. Lasers Eng. 15, 241â251 (1991).
Trusiak, M., Patorski, K. & Wielgus, M. Adaptive enhancement of optical fringe patterns by selective reconstruction using FABEMD algorithm and Hilbert spiral transform. Opt. Express 20, 23463â23479 (2012).
Wang, C. X., Qian, K. M. & Da, F. P. Automatic fringe enhancement with novel bidimensional sinusoids-assisted empirical mode decomposition. Opt. Express 25, 24299â24311 (2017).
Hsung, T. C., Lun, D. P. K. & Ng, W. W. L. Efficient fringe image enhancement based on dual-tree complex wavelet transform. Appl. Opt. 50, 3973â3986 (2011).
Awatsuji, Y. et al. Single-shot phase-shifting color digital holography. In IEEE Lasers and Electro-Optics Society Annual Meeting Conference Proceedings. 84â85 (IEEE, Lake Buena Vista, FL, 2007).
Zhang, Z. H. Review of single-shot 3D shape measurement by phase calculation-based fringe projection techniques. Opt. Lasers Eng. 50, 1097â1106 (2012).
Phillips, Z. F., Chen, M. & Waller, L. Single-shot quantitative phase microscopy with color-multiplexed differential phase contrast (cDPC). PLoS ONE 12, e0171228 (2017).
Sun, J. S. et al. Single-shot quantitative phase microscopy based on color-multiplexed Fourier ptychography. Opt. Lett. 43, 3365â3368 (2018).
Fan, Y. et al. Single-shot isotropic quantitative phase microscopy based on color-multiplexed differential phase contrast. APL Photonics 4, 121301 (2019).
Zhang, Z. H., Towers, C. E. & Towers, D. P. Time efficient color fringe projection system for 3D shape and color using optimum 3-frequency selection. Opt. Express 14, 6444â6455 (2006).
Zhang, Y. B. et al. Color calibration and fusion of lens-free and mobile-phone microscopy images for high-resolution and accurate color reproduction. Sci. Rep. 6, 27811 (2016).
Lee, W. et al. Single-exposure quantitative phase imaging in color-coded LED microscopy. Opt. Express 25, 8398â8411 (2017).
Schemm, J. B. & Vest, C. M. Fringe pattern recognition and interpolation using nonlinear regression analysis. Appl. Opt. 22, 2850â2853 (1983).
Schreier, H. W., Braasch, J. R. & Sutton, M. A. Systematic errors in digital image correlation caused by intensity interpolation. Optical Eng. 39, 2915â2921 (2000).
Bing, P. et al. Performance of sub-pixel registration algorithms in digital image correlation. Meas. Sci. Technol. 17, 1615 (2006).
Pan, B. et al. Study on subset size selection in digital image correlation for speckle patterns. Opt. Express 16, 7037â7048 (2008).
Bruck, H. et al. Digital image correlation using Newton-Raphson method of partial differential correction. Exp. Mech. 29, 261â267 (1989).
Massig, J. H. & Heppner, J. Fringe-pattern analysis with high accuracy by use of the Fourier-transform method: theory and experimental tests. Appl. Opt. 40, 2081â2088 (2001).
Roddier, C. & Roddier, F. Interferogram analysis using Fourier transform techniques. Appl. Opt. 26, 1668â1673 (1987).
Takeda, M., Ina, H. & Kobayashi, S. Fourier-transform method of fringe-pattern analysis for computer-based topography and interferometry. J. Optical Soc. Am. 72, 156â160 (1982).
Su, X. Y. & Chen, W. J. Fourier transform profilometry:: a review. Opt. Lasers Eng. 35, 263â284 (2001).
Kemao, Q. Windowed Fringe Pattern Analysis (SPIE Press, 2013).
Zhong, J. G. & Weng, J. W. Spatial carrier-fringe pattern analysis by means of wavelet transform: wavelet transform profilometry. Appl. Opt. 43, 4993â4998 (2004).
Larkin, K. G., Bone, D. J. & Oldfield, M. A. Natural demodulation of two-dimensional fringe patterns. I. general background of the spiral phase quadrature transform. J. Optical Soc. Am. A 18, 1862â1870 (2001).
Trusiak, M., Wielgus, M. & Patorski, K. Advanced processing of optical fringe patterns by automated selective reconstruction and enhanced fast empirical mode decomposition. Opt. Lasers Eng. 52, 230â240 (2014).
Servin, M., Marroquin, J. L. & Cuevas, F. J. Demodulation of a single interferogram by use of a two-dimensional regularized phase-tracking technique. Appl. Opt. 36, 4540â4548 (1997).
Servin, M., Marroquin, J. L. & Quiroga, J. A. Regularized quadrature and phase tracking from a single closed-fringe interferogram. J. Optical Soc. Am. A 21, 411â419 (2004).
Kemao, Q. & Soon, S. H. Sequential demodulation of a single fringe pattern guided by local frequencies. Opt. Lett. 32, 127â129 (2007).
Wang, H. X. & Kemao, Q. Frequency guided methods for demodulation of a single fringe pattern. Opt. Express 17, 15118â15127 (2009).
Servin, M., Quiroga, J. A. & Padilla, J. M. Fringe Pattern Analysis for Optical Metrology: Theory, Algorithms, and Applications (Wiley-VCH, 2014).
Massie, N. A., Nelson, R. D. & Holly, S. High-performance real-time heterodyne interferometry. Appl. Opt. 18, 1797â1803 (1979).
Bruning, J. H. et al. Digital wavefront measuring interferometer for testing optical surfaces and lenses. Appl. Opt. 13, 2693â2703 (1974).
Srinivasan, V., Liu, H. C. & Halioua, M. Automated phase-measuring profilometry of 3-D diffuse objects. Appl. Opt. 23, 3105â3108 (1984).
Wizinowich, P. L. Phase shifting interferometry in the presence of vibration: a new algorithm and system. Appl. Opt. 29, 3271â3279 (1990).
Schreiber, H. & Bruning, J. H. Phase shifting interferometry. in Optical Shop Testing, 3rd edn. (ed. Malacara, D.) 547â666 (Wiley, 2007).
Goldstein, R. M., Zebker, H. A. & Werner, C. L. Satellite radar interferometry: two-dimensional phase unwrapping. Radio Sci. 23, 713â720 (1988).
Su, X. Y. & Chen, W. J. Reliability-guided phase unwrapping algorithm: a review. Opt. Lasers Eng. 42, 245â261 (2004).
Flynn, T. J. Two-dimensional phase unwrapping with minimum weighted discontinuity. J. Optical Soc. Am. A 14, 2692â2701 (1997).
Ghiglia, D. C. & Romero, L. A. Minimum Lp-norm two-dimensional phase unwrapping. J. Optical Soc. Am. A 13, 1999â2013 (1996).
Bioucas-Dias, J. M. & Valadao, G. Phase unwrapping via graph cuts. IEEE Trans. Image Process. 16, 698â709 (2007).
Zappa, E. & Busca, G. Comparison of eight unwrapping algorithms applied to Fourier-transform profilometry. Opt. Lasers Eng. 46, 106â116 (2008).
Zebker, H. A. & Lu, Y. P. Phase unwrapping algorithms for radar interferometry: residue-cut, least-squares, and synthesis algorithms. J. Optical Soc. Am. A 15, 586â598 (1998).
Zhao, M. et al. Quality-guided phase unwrapping technique: comparison of quality maps and guiding strategies. Appl. Opt. 50, 6214â6224 (2011).
Sansoni, G. et al. Three-dimensional imaging based on Gray-code light projection: characterization of the measuring algorithm and development of a measuring system for industrial applications. Appl. Opt. 36, 4463â4472 (1997).
Sansoni, G., Carocci, M. & Rodella, R. Three-dimensional vision based on a combination of gray-code and phase-shift light projection: analysis and compensation of the systematic errors. Appl. Opt. 38, 6565â6573 (1999).
Huntley, J. M. & Saldner, H. Temporal phase-unwrapping algorithm for automated interferogram analysis. Appl. Opt. 32, 3047â3052 (1993).
Zhao, H., Chen, W. Y. & Tan, Y. S. Phase-unwrapping algorithm for the measurement of three-dimensional object shapes. Appl. Opt. 33, 4497â4500 (1994).
Saldner, H. O. & Huntley, J. M. Temporal phase unwrapping: application to surface profiling of discontinuous objects. Appl. Opt. 36, 2770â2775 (1997).
Cheng, Y. Y. & Wyant, J. C. Two-wavelength phase shifting interferometry. Appl. Opt. 23, 4539â4543 (1984).
Creath, K., Cheng, Y. Y. & Wyant, J. C. Contouring aspheric surfaces using two-wavelength phase-shifting interferometry. Opt. Acta.: Int. J. Opt. 32, 1455â1464 (1985).
Towers, C. E., Towers, D. P. & Jones, J. D. C. Optimum frequency selection in multifrequency interferometry. Opt. Lett. 28, 887â889 (2003).
Gushov, V. I. & Solodkin, Y. N. Automatic processing of fringe patterns in integer interferometers. Opt. Lasers Eng. 14, 311â324 (1991).
Takeda, M. et al. Frequency-multiplex Fourier-transform profilometry: a single-shot three-dimensional shape measurement of objects with large height discontinuities and/or surface isolations. Appl. Opt. 36, 5347â5354 (1997).
Zhong, J. G. & Wang, M. Phase unwrapping by lookup table method: application to phase map with singular points. Optical Eng. 38, 2075â2080 (1999).
Burke, J. et al. Reverse engineering by fringe projection. In Proceedings of SPIE 4778, Interferometry XI: Applications. 312â324 (SPIE, Seattle, WA, 2002).
Zuo, C. et al. Temporal phase unwrapping algorithms for fringe projection profilometry: a comparative review. Opt. Lasers Eng. 85, 84â103 (2016).
Tao, T. Y. et al. Real-time 3-D shape measurement with composite phase-shifting fringes and multi-view system. Opt. Express 24, 20253â20269 (2016).
Liu, X. R. & Kofman, J. Background and amplitude encoded fringe patterns for 3D surface-shape measurement. Opt. Lasers Eng. 94, 63â69 (2017).
Weise, T., Leibe, B. & Van Gool, L. Fast 3D scanning with automatic motion compensation. In Proceedings of 2007 IEEE Conference on Computer Vision and Pattern Recognition. 1â8 (IEEE, Minneapolis, MN, 2007).
Zuo, C. et al. Micro Fourier transform profilometry (μFTP): 3D shape measurement at 10,000 frames per second. Opt. Lasers Eng. 102, 70â91 (2018).
An, Y. T., Hyun, J. S. & Zhang, S. Pixel-wise absolute phase unwrapping using geometric constraints of structured light system. Opt. Express 24, 18445â18459 (2016).
Li, Z. W. et al. Multiview phase shifting: a full-resolution and high-speed 3D measurement framework for arbitrary shape dynamic objects. Opt. Lett. 38, 1389â1391 (2013).
Bräuer-Burchardt, C. et al. High-speed three-dimensional measurements with a fringe projection-based optical sensor. Optical Eng. 53, 112213 (2014).
Garcia, R. R. & Zakhor, A. Consistent stereo-assisted absolute phase unwrapping methods for structured light systems. IEEE J. Sel. Top. Signal Process. 6, 411â424 (2012).
Jiang, C. F., Li, B. W. & Zhang, S. Pixel-by-pixel absolute phase retrieval using three phase-shifted fringe patterns without markers. Opt. Lasers Eng. 91, 232â241 (2017).
Liu, X. R. & Kofman, J. High-frequency background modulation fringe patterns based on a fringe-wavelength geometry-constraint model for 3D surface-shape measurement. Opt. Express 25, 16618â16628 (2017).
Tao, T. Y. et al. High-precision real-time 3D shape measurement using a bi-frequency scheme and multi-view system. Appl. Opt. 56, 3646â3653 (2017).
Tao, T. Y. et al. High-speed real-time 3D shape measurement based on adaptive depth constraint. Opt. Express 26, 22440â22456 (2018).
Cai, Z. W. et al. Light-field-based absolute phase unwrapping. Opt. Lett. 43, 5717â5720 (2018).
Pan, B., Xie, H. M. & Wang, Z. Y. Equivalence of digital image correlation criteria for pattern matching. Appl. Opt. 49, 5501â5509 (2010).
Gruen, A. W. Adaptive least squares correlation: a powerful image matching technique. J. Photogramm. Remote Sens. Cartogr. 14, 175â187 (1985).
Altunbasak, Y., Mersereau, R. M. & Patti, A. J. A fast parametric motion estimation algorithm with illumination and lens distortion correction. IEEE Trans. Image Process. 12, 395â408 (2003).
Gutman, S. On optimal guidance for homing missiles. J. Guidance Control 2, 296â300 (1979).
Zabih, R. & Woodfill, J. Non-parametric local transforms for computing visual correspondence. In Proceedings of the 3rd European Conference on Computer Vision. 151â158 (Springer, Stockholm, 1994).
Bhat, D. N. & Nayar, S. K. Ordinal measures for image correspondence. IEEE Trans. Pattern Anal. Mach. Intell. 20, 415â423 (1998).
Sara, R. & Bajcsy, R. On occluding contour artifacts in stereo vision. In Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition. 852â857 (IEEE, San Juan, PR, 1997).
Sutton, M. A. et al. Effects of subpixel image restoration on digital correlation error estimates. Optical Eng. 27, 271070 (1988).
Zhang, D., Zhang, X. & Cheng, G. Compression strain measurement by digital speckle correlation. Exp. Mech. 39, 62â65 (1999).
Hung, P. C. & Voloshin, A. In-plane strain measurement by digital image correlation. J. Braz. Soc. Mech. Sci. Eng. 25, 215â221 (2003).
Davis, C. Q. & Freeman, D. M. Statistics of subpixel registration algorithms based on spatiotemporal gradients or block matching. Optical Eng. 37, 1290â1298 (1998).
Zhou, P. & Goodson, K. E. Subpixel displacement and deformation gradient measurement using digital image/speckle correlation. Optical Eng. 40, 1613â1620 (2001).
Press, W. H. et al. Numerical Recipes in Fortran 77: Volume 1, Volume 1 of Fortran Numerical Recipes: The Art of Scientific Computing, 2nd edn. (Cambridge University Press, 1992).
Chapra, S. C., Canale, R. P. Numerical Methods for Engineers (McGraw-Hill Higher Education, 2011).
Baker, S. & Matthews, I. Equivalence and efficiency of image alignment algorithms. In Proceedings of 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. 1 (IEEE, Kauai, HI, 2001).
Baker, S. & Matthews, I. Lucas-Kanade 20 years on: a unifying framework. Int. J. Computer Vis. 56, 221â255 (2004).
Pan, B., Li, K. & Tong, W. Fast, robust and accurate digital image correlation calculation without redundant computations. Exp. Mech. 53, 1277â1289 (2013).
Pan, B. & Li, K. A fast digital image correlation method for deformation measurement. Opt. Lasers Eng. 49, 841â847 (2011).
Zhang, L. Q. et al. High accuracy digital image correlation powered by GPU-based parallel computing. Opt. Lasers Eng. 69, 7â12 (2015).
Konolige, K. Small vision systems: hardware and implementation. in Robotics Research: The Eighth International Symposium (eds Shirai, Y. & Hirose, S.) 203â212 (Springer, 1998).
Hirschmüller, H., Innocent, P. R. & Garibaldi, J. Real-time correlation-based stereo vision with reduced border errors. Int. J. Computer Vis. 47, 229â246 (2002).
Scharstein, D. & Szeliski, R. A taxonomy and evaluation of dense two-frame stereo correspondence algorithms. Int. J. Computer Vis. 47, 7â42 (2002).
Hirschmuller, H. Stereo processing by semiglobal matching and mutual information. IEEE Trans. Pattern Anal. Mach. Intell. 30, 328â341 (2008).
Boykov, Y., Veksler, O. & Zabih, R. Fast approximate energy minimization via graph cuts. IEEE Trans. Pattern Anal. Mach. Intell. 23, 1222â1239 (2001).
Hong, C. K., Ryu, H. S. & Lim, H. C. Least-squares fitting of the phase map obtained in phase-shifting electronic speckle pattern interferometry. Opt. Lett. 20, 931â933 (1995).
Aebischer, H. A. & Waldner, S. A simple and effective method for filtering speckle-interferometric phase fringe patterns. Opt. Commun. 162, 205â210 (1999).
Yatabe, K. & Oikawa, Y. Convex optimization-based windowed Fourier filtering with multiple windows for wrapped-phase denoising. Appl. Opt. 55, 4632â4641 (2016).
Huang, H. Y. H. et al. Path-independent phase unwrapping using phase gradient and total-variation (TV) denoising. Opt. Express 20, 14075â14089 (2012).
Chen, R. P. et al. Interferometric phase denoising by pyramid nonlocal means filter. IEEE Geosci. Remote Sens. Lett. 10, 826â830 (2013).
Langehanenberg, P. et al. Autofocusing in digital holographic phase contrast microscopy on pure phase objects for live cell imaging. Appl. Opt. 47, D176âD182 (2008).
Gao, P. et al. Autofocusing of digital holographic microscopy based on off-axis illuminations. Opt. Lett. 37, 3630â3632 (2012).
Dubois, F. et al. Focus plane detection criteria in digital holography microscopy by amplitude analysis. Opt. Express 14, 5895â5908 (2006).
Pan, B. et al. Phase error analysis and compensation for nonsinusoidal waveforms in phase-shifting digital fringe projection profilometry. Opt. Lett. 34, 416â418 (2009).
Feng, S. J. et al. Robust dynamic 3-D measurements with motion-compensated phase-shifting profilometry. Opt. Lasers Eng. 103, 127â138 (2018).
Ferraro, P. et al. Compensation of the inherent wave front curvature in digital holographic coherent microscopy for quantitative phase-contrast imaging. Appl. Opt. 42, 1938â1946 (2003).
Di, J. L. et al. Phase aberration compensation of digital holographic microscopy based on least squares surface fitting. Opt. Commun. 282, 3873â3877 (2009).
Miccio, L. et al. Direct full compensation of the aberrations in quantitative phase microscopy of thin objects by a single digital hologram. Appl. Phys. Lett. 90, 041104 (2007).
Colomb, T. et al. Total aberrations compensation in digital holographic microscopy with a reference conjugated hologram. Opt. Express 14, 4300â4306 (2006).
Zuo, C. et al. Phase aberration compensation in digital holographic microscopy based on principal component analysis. Opt. Lett. 38, 1724â1726 (2013).
MartÃnez, A. et al. Analysis of optical configurations for ESPI. Opt. Lasers Eng. 46, 48â54 (2008).
Wang, Y. J. & Zhang, S. Optimal fringe angle selection for digital fringe projection technique. Appl. Opt. 52, 7094â7098 (2013).
Michie, D., Spiegelhalter, D. J. & Taylor, C. C. Machine learning. Neural Stat. Classification. Neural Stat. Classif. 13, 1â298 (1994).
Zhang, X. D. Machine learning. in A Matrix Algebra Approach to Artificial Intelligence (ed. Zhang, X. D.) 223â440 (Springer, 2020).
Rosenblatt, F. The perceptron: a probabilistic model for information storage and organization in the brain. Psychol. Rev. 65, 386â408 (1958).
Nair, V. & Hinton, G. E. Rectified linear units improve restricted Boltzmann machines. In Proceedings of the 27th International Conference on International Conference on Machine Learning. 807â814 (ACM, Haifa, 2010).
Gardner, M. W. & Dorling, S. R. Artificial neural networks (the multilayer perceptron)âa review of applications in the atmospheric sciences. Atmos. Environ. 32, 2627â2636 (1998).
Sussillo, D. Random walks: training very deep nonlinear feed-forward networks with smart initialization. Preprint at https://arxiv.org/abs/1412.6558v2 (2014).
Kraus, M., Feuerriegel, S. & Oztekin, A. Deep learning in business analytics and operations research: models, applications and managerial implications. Eur. J. Operational Res. 281, 628â641 (2020).
Zhang, Z. L. & Sabuncu, M. R. Generalized cross entropy loss for training deep neural networks with noisy labels. In Proceedings of the 32nd International Conference on Neural Information Processing Systems. 8792â8802 (ACM, Montréal, 2018).
Korhonen, J. & You, J. Y. Peak signal-to-noise ratio revisited: is simple beautiful? In Proceedings of the 4th International Workshop on Quality of Multimedia Experience. 37â38 (IEEE, Melbourne, VIC, 2012).
Girshick, R. Fast R-CNN. In Proceedings of 2015 IEEE International Conference on Computer Vision. 1440â1448 (IEEE, Santiago, 2015).
Wang, Z. et al. Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 13, 600â612 (2004).
Wang, Z. & Bovik, A. C. Mean squared error: love it or leave it? A new look at signal fidelity measures. IEEE Signal Process. Mag. 26, 98â117 (2009).
Wang, J. J. et al. Deep learning for smart manufacturing: methods and applications. J. Manuf. Syst. 48, 144â156 (2018).
Kingma, D. P. et al. Semi-supervised learning with deep generative models. In Proceedings of the 27th International Conference on Neural Information Processing Systems. 3581â3589 (ACM, Montreal, 2014).
Hinton, G. E. et al. The âwake-sleepâ algorithm for unsupervised neural networks. Science 268, 1158â1161 (1995).
Bengio, Y. et al. Deep generative stochastic networks trainable by backprop. In Proceedings of the 31th International Conference on Machine Learning. 226â234 (JMLR, Beijing, 2014).
McCulloch, W. S. & Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophysics 5, 115â133 (1943).
Minsky, M. & Papert, S. A. Perceptrons: an Introduction to Computational Geometry (The MIT Press, 1969).
Rumelhart, D. E., Hinton, G. E. & Williams, R. J. Learning representations by back-propagating errors. Nature 323, 533â536 (1986).
Hubel, D. H. & Wiesel, T. N. Receptive fields, binocular interaction and functional architecture in the catâs visual cortex. J. Physiol. 160, 106â154 (1962).
LeCun, Y. et al. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1, 541â551 (1989).
Hochreiter, S. The vanishing gradient problem during learning recurrent neural nets and problem solutions. Int. J. Uncertain., Fuzziness Knowl.-Based Syst. 6, 107â116 (1998).
Hinton, G. E., Osindero, S. & Teh, Y. W. A fast learning algorithm for deep belief nets. Neural Comput. 18, 1527â1554 (2006).
Hinton, G. E. & Salakhutdinov, R. R. Reducing the dimensionality of data with neural networks. Science 313, 504â507 (2006).
Hinton, G. E. & Sejnowski, T. J. Learning and relearning in Boltzmann machines. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition: Foundations (eds Rumelhart, D. E. & McClelland, J. L.) (MIT Press, 1986) 282â317.
Smolensky, P. Information processing in dynamical systems: foundations of harmony theory. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition: Foundations (eds Rumelhart, D. E. & McClelland, J. L.) (MIT Press, 1986) 194â281.
Krizhevsky, A., Sutskever, I. & Hinton, G. E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems. 1097â1105 (ACM, Lake Tahoe, Nevada, 2012).
LeCun, Y. et al. Gradient-based learning applied to document recognition. Proc. IEEE 86, 2278â2324 (1998).
Hinton, G. E. et al. Improving neural networks by preventing co-adaptation of feature detectors. Preprint at https://arxiv.org/abs/1207.0580 (2012).
Windhorst, U. On the role of recurrent inhibitory feedback in motor control. Prog. Neurobiol. 49, 517â587 (1996).
Elman, J. L. Finding structure in time. Cogn. Sci. 14, 179â211 (1990).
Hochreiter, S. & Schmidhuber, J. Long short-term memory. Neural Comput. 9, 1735â1780 (1997).
Zhou, J. et al. Graph neural networks: a review of methods and applications. AI Open 1, 57â81 (2020).
Xu, K. et al. How powerful are graph neural networks? In Proceedings of the 7th International Conference on Learning Representations. (OpenReview, New Orleans, LA, 2018).
Simonyan, K. & Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations. (DBIP, San Diego, CA, 2014).
Szegedy, C. et al. Going deeper with convolutions. In Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. 1â9 (IEEE, Boston, MA, 2015).
Girshick, R. et al. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition. 580â587 (IEEE, Columbus, OH, 2014).
Goodfellow, I. J. et al. Generative adversarial nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems. 2672â2680 (ACM, Montreal, 2014).
He, K. M. et al. Deep residual learning for image recognition. In Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. 770â778 (IEEE, Las Vegas, NV, 2016).
Chen, J. X. The evolution of computing: AlphaGo. Comput. Sci. Eng. 18, 4â7 (2016).
Ouyang, W. L. et al. DeepID-Net: object detection with deformable part based convolutional neural networks. IEEE Trans. Pattern Anal. Mach. Intell. 39, 1320â1334 (2017).
Lin, L. et al. A deep structured model with radiusâmargin bound for 3D human activity recognition. Int. J. Computer Vis. 118, 256â273 (2016).
Doulamis, N. & Voulodimos, A. FAST-MDL: fast adaptive supervised training of multi-layered deep learning models for consistent object tracking and classification. In Proceedings of 2016 IEEE International Conference on Imaging Systems and Techniques (IST). 318â323 (IEEE, Chania, 2016).
Toshev, A. & Szegedy, C. DeepPose: human pose estimation via deep neural networks. In Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition. 1653â1660 (IEEE, Columbus, OH, 2014).
Long, J., Shelhamer, E. & Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of 2005 IEEE Conference on Computer Vision and Pattern Recognition. 3431â3440 (IEEE, Boston, MA, 2015).
Chen, Q. F., Xu, J. & Koltun, V. Fast image processing with fully-convolutional networks. In Proceedings of 2017 IEEE International Conference on Computer Vision. 2516â2525 (IEEE, Venice, 2017).
Dong, C. et al. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 38, 295â307 (2015).
Wang, Z. H., Chen, J. & Hoi, S. C. H. Deep learning for image super-resolution: a survey. IEEE Trans. Pattern Anal. Mach. Intell. 43, 3365â3387 (2021).
Dai, Y. P. et al. SRCNN-based enhanced imaging for low frequency radar. In 2018 Progress in Electromagnetics Research Symposium (PIERS-Toyama). 366â370 (IEEE, Toyama, 2018).
Li, Y. J. et al. Underwater image high definition display using the multilayer perceptron and color feature-based SRCNN. IEEE Access 7, 83721â83728 (2019).
Umehara, K., Ota, J. & Ishida, T. Application of super-resolution convolutional neural network for enhancing image resolution in chest CT. J. Digital Imaging 31, 441â450 (2018).
Noh, H., Hong, S. & Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of 2015 IEEE International Conference on Computer Vision. 1520â1528 (IEEE, Santiago, 2015).
Ronneberger, O., Fischer, P. & Brox, T. U-Net: convolutional networks for biomedical image segmentation. In Proceedings of 18th International Conference on Medical Image Computing and Computer-Assisted Intervention. 234â241 (Springer, Munich, 2015).
Falk, T. et al. U-Net: deep learning for cell counting, detection, and morphometry. Nat. Methods 16, 67â70 (2019).
Badrinarayanan, V., Kendall, A. & Cipolla, R. SegNet: a deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 39, 2481â2495 (2017).
Zeiler, M. D. & Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the 13th European Conference on Computer Vision. 818â833 (Springer, Zurich, 2014).
Shi, W. Z. et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. 1874â1883 (IEEE, Las Vegas, NV, 2016).
Bell, J. B. Solutions of Ill-posed problems. by A. N. Tikhonov, V. Y. Arsenin. Math. Comput. 32, 1320â1322 (1978).
Figueiredo, M. A. T. & Nowak, R. D. A bound optimization approach to wavelet-based image deconvolution. In IEEE International Conference on Image Processing 2005. II-782 (IEEE, Genova, Italy, 2005).
Mairal, J. et al. Online dictionary learning for sparse coding. In Proceedings of the 26th Annual International Conference on Machine Learning. 689â696 (ACM, Montreal, Quebec, 2009).
Daubechies, I., Defrise, M. & De Mol, C. An iterative thresholding algorithm for linear inverse problems with a sparsity constraint. Commun. Pure Appl. Math. 57, 1413â1457 (2004).
Boyd, S. et al. Distributed Optimization and Statistical Learning Via the Alternating Direction Method of Multipliers (Now Publishers Inc, 2011).
Candès, E. J., Romberg, J. K. & Tao, T. Stable signal recovery from incomplete and inaccurate measurements. Commun. Pure Appl. Math. 59, 1207â1223 (2006).
Greivenkamp, J. E. Generalized data reduction for heterodyne interferometry. Optical Eng. 23, 234350 (1984).
Morgan, C. J. Least-squares estimation in phase-measurement interferometry. Opt. Lett. 7, 368â370 (1982).
Osten, W. Optical metrology: from the laboratory to the real world. in Computational Optical Sensing and Imaging (ed. George, B. et al.) 2013. JW2B-4 (Optical Society of America, 2013).
Van der Jeught, S. & Dirckx, J. J. J. Real-time structured light profilometry: a review. Opt. Lasers Eng. 87, 18â31 (2016).
Jeon, W. et al. Speckle noise reduction for digital holographic images using multi-scale convolutional neural networks. Opt. Lett. 43, 4240â4243 (2018).
Lin, B. W. et al. Optical fringe patterns filtering based on multi-stage convolution neural network. Opt. Lasers Eng. 126, 105853 (2020).
Reyes-Figueroa, A., Flores, V. H. & Rivera, M. Deep neural network for fringe pattern filtering and normalization. Appl. Opt. 60, 2022â2036 (2021).
Vincent, P. et al. Stacked denoising autoencoders: learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 11, 3371â3408 (2010).
Qian, J. M. et al. Single-shot absolute 3D shape measurement with deep-learning-based color fringe projection profilometry. Opt. Lett. 45, 1842â1845 (2020).
Zhang, Z. H., Towers, D. P. & Towers, C. E. Snapshot color fringe projection for absolute three-dimensional metrology of video sequences. Appl. Opt. 49, 5947â5953 (2010).
Goy, A. et al. Low photon count phase retrieval using deep learning. Phys. Rev. Lett. 121, 243902 (2018).
Yu, H. T. et al. Deep learning-based fringe modulation-enhancing method for accurate fringe projection profilometry. Opt. Express 28, 21692â21703 (2020).
Feng, S. J. et al. Micro deep learning profilometry for high-speed 3D surface imaging. Opt. Lasers Eng. 121, 416â427 (2019).
Qiao, G. et al. A single-shot phase retrieval method for phase measuring deflectometry based on deep learning. Opt. Commun. 476, 126303 (2020).
Niu, H. B. et al. Structural light 3D reconstruction algorithm based on deep learning. In Proceedings of SPIE 11187, Optoelectronic Imaging and Multimedia Technology VI. 111871F (SPIE, Hangzhou, 2019).
Yang, T. et al. Single-shot phase extraction for fringe projection profilometry using deep convolutional generative adversarial network. Meas. Sci. Technol. 32, 015007 (2020).
Zhou, W. W. et al. Fourier transform profilometry based on convolution neural network. In Proceedings of SPIE 10819, Optical Metrology and Inspection for Industrial Applications V. 108191M (SPIE, Beijing, 2018).
Wang, K. et al. Y-Net: a one-to-two deep learning framework for digital holographic reconstruction. Opt. Lett. 44, 4765â4768 (2019).
Wang, K. Q. et al. Y4-Net: a deep learning solution to one-shot dual-wavelength digital holographic reconstruction. Opt. Lett. 45, 4220â4223 (2020).
Li, Y. X. et al. Single-shot spatial frequency multiplex fringe pattern for phase unwrapping using deep learning. In Proceedings of SPIE 11571, Optics Frontier Online 2020: Optics Imaging and Display. 1157118 (SPIE, Shanghai, 2020).
Nguyen, H. et al. Real-time 3D shape measurement using 3LCD projection and deep machine learning. Appl. Opt. 58, 7100â7109 (2019).
Zhang, S. & Huang, P. S. High-resolution, real-time three-dimensional shape measurement. Optical Eng. 45, 123601 (2006).
Zuo, C. et al. High-speed three-dimensional profilometry for multiple objects with complex shapes. Opt. Express 20, 19493â19510 (2012).
Zhang, Q. N. et al. Deep phase shifter for quantitative phase imaging. Preprint at https://arxiv.org/abs/2003.03027 (2020).
Li, Z. P., Li, X. Y. & Liang, R. G. Random two-frame interferometry based on deep learning. Opt. Express 28, 24747â24760 (2020).
Zhang, L. et al. High-speed high dynamic range 3D shape measurement based on deep learning. Opt. Lasers Eng. 134, 106245 (2020).
Wu, S. J. & Zhang, Y. Z. Gamma correction by using deep learning. In Proceedings of SPIE 11571, Optics Frontier Online 2020: Optics Imaging and Display. 115710V (SPIE, Shanghai, 2020).
Yang, Y. et al. Phase error compensation based on Tree-Net using deep learning. Opt. Lasers Eng. 143, 106628 (2021).
Feng, S. J. et al. Generalized framework for non-sinusoidal fringe analysis using deep learning. Photonics Res. 9, 1084â1098 (2021).
Wang, K. Q. et al. One-step robust deep learning phase unwrapping. Opt. Express 27, 15100â15115 (2019).
Pritt, M. D. & Shipman, J. S. Least-squares two-dimensional phase unwrapping using FFTâs. IEEE Trans. Geosci. Remote Sens. 32, 706â708 (1994).
Spoorthi, G., Gorthi, S. & Gorthi, R. K. S. S. PhaseNet: a deep convolutional neural network for two-dimensional phase unwrapping. IEEE Signal Process. Lett. 26, 54â58 (2019).
Spoorthi, G. E., Gorthi, R. K. S. S. & Gorthi, S. PhaseNet 2.0: phase unwrapping of noisy data based on deep learning approach. IEEE Trans. Image Process. 29, 4862â4872 (2020).
Zhang, J. C. et al. Phase unwrapping in optical metrology via denoised and convolutional segmentation networks. Opt. Express 27, 14903â14912 (2019).
Kando, D. et al. Phase extraction from single interferogram including closed-fringe using deep learning. Appl. Sci. 9, 3529 (2019).
Li, P. H. et al. Deep learning based method for phase analysis from a single closed fringe pattern. In Proceedings of 11523, Optical Technology and Measurement for Industrial Applications 2020. 115230E (SPIE, Yokohama, 2020).
Liu, K. & Zhang, Y. Z. Temporal phase unwrapping with a lightweight deep neural network. In Proceedings of SPIE 11571, Optics Frontier Online 2020: Optics Imaging and Display. 115710N (SPIE, Shanghai, 2020).
Li, J. S. et al. Quantitative phase imaging in dual-wavelength interferometry using a single wavelength illumination and deep learning. Opt. Express 28, 28140â28153 (2020).
Yao, P. C., Gai, S. Y. & Da, F. P. Coding-Net: a multi-purpose neural network for fringe projection profilometry. Opt. Commun. 489, 126887 (2021).
Yao, P. C. et al. A multi-code 3D measurement technique based on deep learning. Opt. Lasers Eng. 143, 106623 (2021).
Qian, J. M. et al. Deep-learning-enabled geometric constraints and phase unwrapping for single-shot absolute 3D shape measurement. APL Photonics 5, 046105 (2020).
Yu, H. T. et al. Dynamic 3-D measurement based on fringe-to-fringe transformation using deep learning. Opt. Express 28, 9405â9418 (2020).
Žbontar, J. & LeCun, Y. Stereo matching by training a convolutional neural network to compare image patches. J. Mach. Learn. Res. 17, 2287â2318 (2016).
Mei, X. et al. On building an accurate stereo matching system on graphics hardware. In Proceedings of 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops). 467â474 (IEEE, Barcelona, 2011).
Luo, W. J., Schwing, A. G. & Urtasun, R. Efficient deep learning for stereo matching. In Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. 5695â5703 (IEEE, Las Vegas, NV, 2016).
Yin, W. et al. Composite deep learning framework for absolute 3D shape measurement based on single fringe phase retrieval and speckle correlation. J. Phys.: Photonics 2, 045009 (2020).
Hartmann, W. et al. Learned multi-patch similarity. In Proceedings of 2017 IEEE International Conference on Computer Vision. 1595â1603 (IEEE, Venice, 2017).
Žbontar, J. & LeCun, Y. Computing the stereo matching cost with a convolutional neural network. In Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. 1592â1599 (IEEE, Boston, MA, 2015).
Zagoruyko, S. & Komodakis, N. Learning to compare image patches via convolutional neural networks. In Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. 4353â4361 (IEEE, Boston, MA, 2015).
Chen, Z. Y. et al. A deep visual correspondence embedding model for stereo matching costs. In Proceedings of 2015 IEEE International Conference on Computer Vision. 972â980 (IEEE, Santiago, 2015).
Du, Q. C. et al. Stereo-matching network for structured light. IEEE Signal Process. Lett. 26, 164â168 (2019).
Yang, G. S. et al. Hierarchical deep stereo matching on high-resolution images. In Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 5510â5519 (IEEE, Long Beach, CA, 2019).
Guo, X. Y. et al. Group-wise correlation stereo network. In Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3273â3282 (IEEE, Long Beach, CA, 2019).
Zhou, C. et al. Unsupervised learning of stereo matching. In Proceedings of 2017 IEEE International Conference on Computer Vision (ICCV). 1576â1584 (IEEE, Venice, 2017).
Kim, S. et al. Unified confidence estimation networks for robust stereo matching. IEEE Trans. Image Process. 28, 1299â1313 (2019).
Pang, J. H. et al. Cascade residual learning: a two-stage convolutional neural network for stereo matching. In Proceedings of 2017 IEEE International Conference on Computer Vision Workshops. 887â895 (IEEE, Venice, 2017).
Khamis, S. et al. StereoNet: guided hierarchical refinement for real-time edge-aware depth prediction. In Proceedings of the 15th European Conference on Computer Vision. 596â613 (Springer, Munich, 2018).
Moo Yi, K. et al. Learning to find good correspondences. In Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2666â2674 (IEEE, Salt Lake City, UT, 2018).
Huang, P. H. et al. DeepMVS: learning multi-view stereopsis. In Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2821â2830 (IEEE, Salt Lake City, UT, 2018).
Yao, Y. et al. Recurrent MVSNet for high-resolution multi-view stereo depth inference. In Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 5520â5529 (IEEE, Long Beach, CA, 2019).
Chabra, R. et al. StereoDRNet: dilated residual stereoNet. In Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 11778â11787 (IEEE, Long Beach, CA, 2019).
Duggal, S. et al. DeepPruner: learning efficient stereo matching via differentiable patchmatch. In Proceedings of 2019 IEEE/CVF International Conference on Computer Vision (ICCV). 4383â4392 (IEEE, Seoul, 2019).
Kim, S. et al. LAF-Net: locally adaptive fusion networks for stereo confidence estimation. In Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 205â214 (IEEE, Long Beach, CA, 2019).
Yee, K. & Chakrabarti, A. Fast deep stereo with 2D convolutional processing of cost signatures. In Proceedings of 2020 IEEE Winter Conference on Applications of Computer Vision. 183â191 (IEEE, Snowmass, CO, 2020).
Tonioni, A. et al. Real-time self-adaptive deep stereo. In Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 195â204 (IEEE, Long Beach, CA, 2019).
Wang, Y. et al. UnoS: unified unsupervised optical-flow and stereo-depth estimation by watching videos. In Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8063â8073 (IEEE, Long Beach, CA, 2019).
Jie, Z. Q. et al. Left-right comparative recurrent model for stereo matching. In Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3838â3846 (IEEE, Salt Lake City, UT, 2018).
Poggi, M. & Mattoccia, S. Learning from scratch a confidence measure. In Proceedings of the British Machine Vision Conference 2016. (BMVC, York, 2016).
Yin, W. et al. High-speed 3D shape measurement with the multi-view system using deep learning. In Proceedings of SPIE 11189, Optical Metrology and Inspection for Industrial Applications VI. 111890B (SPIE, Hangzhou, 2019).
Fanello, S. R. et al. UltraStereo: efficient learning-based matching for active stereo systems. In Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 6535â6544 (IEEE, Honolulu, HI, 2017).
Montrésor, S. et al. Computational de-noising based on deep learning for phase data in digital holographic interferometry. APL Photonics 5, 030802 (2020).
Yan, K. T. et al. Wrapped phase denoising using convolutional neural networks. Opt. Lasers Eng. 128, 105999 (2020).
Yan, K. T. et al. Deep learning-based wrapped phase denoising method for application in digital holographic speckle pattern interferometry. Appl. Sci. 10, 4044 (2020).
Ren, Z. B., Xu, Z. M. & Lam, E. Y. M. End-to-end deep learning framework for digital holographic reconstruction. Adv. Photonics 1, 016004 (2019).
Goodman, J. W. Introduction to Fourier Optics, 3rd edn. (Roberts and Company Publishers, 2005).
Bioucas-Dias, J. et al. Absolute phase estimation: adaptive local denoising and global unwrapping. Appl. Opt. 47, 5358â5369 (2008).
Kreis, T. M., Adams, M. & Jüeptner, W. P. O. Methods of digital holography: a comparison. In Proceedings of SPIE 3098, Optical Inspection and Micromeasurements II. 224â233 (SPIE, Munich, 1997).
Ren, Z. B., Xu, Z. M. & Lam, E. Y. Learning-based nonparametric autofocusing for digital holography. Optica 5, 337â344 (2018).
Lee, J. et al. Autofocusing using deep learning in off-axis digital holography. in Digital Holography and Three-Dimensional Imaging (ed. Yoshio, H. et al.) 2018. Dth1C.4 (Optical Society of America, 2018).
Shimobaba, T., Kakue, T. & Ito, T. Convolutional neural network-based regression for depth prediction in digital holography. In Proceedings of the IEEE 27th International Symposium on Industrial Electronics (ISIE). 1323â1326 (IEEE, Cairns, QLD, 2018).
Jaferzadeh, K. et al. No-search focus prediction at the single cell level in digital holographic imaging with deep convolutional neural network. Biomed. Opt. Express 10, 4276â4289 (2019).
Pitkäaho, T., Manninen, A. & Naughton, T. J. Focus prediction in digital holographic microscopy using deep convolutional neural networks. Appl. Opt. 58, A202âA208 (2019).
Nguyen, T. et al. Automatic phase aberration compensation for digital holographic microscopy based on deep learning background detection. Opt. Express 25, 15043â15057 (2017).
Nguyen, T. et al. Accurate quantitative phase digital holographic microscopy with single-and multiple-wavelength telecentric and nontelecentric configurations. Appl. Opt. 55, 5666â5683 (2016).
Lv, S. Z. et al. Projector distortion correction in 3D shape measurement using a structured-light system by deep neural networks. Opt. Lett. 45, 204â207 (2020).
Aguénounon, E. et al. Real-time, wide-field and high-quality single snapshot imaging of optical properties with profile correction using deep learning. Biomed. Opt. Express 11, 5701â5716 (2020).
Li, Z. W. et al. Complex object 3D measurement based on phase-shifting and a neural network. Opt. Commun. 282, 2699â2706 (2009).
Ouellet, J. N. & Hebert, P. A simple operator for very precise estimation of ellipses. In Proceedings of the 4th Canadian Conference on Computer and Robot Vision (CRVâ07). 21â28 (IEEE, Montreal, QC, 2007).
Li, Z. W. et al. Accurate calibration method for a structured light system. Optical Eng. 47, 053604 (2008).
Nguyen, H., Wang, Y. Z. & Wang, Z. Y. Single-shot 3D shape reconstruction using structured light and deep convolutional neural networks. Sensors 20, 3718 (2020).
Van der Jeught, S. & Dirckx, J. J. J. Deep neural networks for single shot structured light profilometry. Opt. Express 27, 17091â17101 (2019).
Van Der Jeught, S., Muyshondt, P. G. G. & Lobato, I. Optimized loss function in deep learning profilometry for improved prediction performance. J. Phys.: Photonics 3, 024014 (2021).
Machineni, R. C. et al. End-to-end deep learning-based fringe projection framework for 3D profiling of objects. Computer Vis. Image Underst. 199, 103023 (2020).
Zheng, Y. et al. Fringe projection profilometry by conducting deep learning from its digital twin. Opt. Express 28, 36568â36583 (2020).
Wang, F. Z., Wang, C. X. & Guan, Q. Z. Single-shot fringe projection profilometry based on deep learning and computer graphics. Opt. Express 29, 8024â8040 (2021).
Mayer, N. et al. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. 4040â4048 (IEEE, Las Vegas, NV, 2016).
Menze, M. & Geiger, A. Object scene flow for autonomous vehicles. In Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. 3061â3070 (IEEE, Boston, MA, 2015).
Kendall, A. et al. End-to-end learning of geometry and context for deep stereo regression. In Proceedings of 2017 IEEE International Conference on Computer Vision (ICCV). 66â75 (IEEE, Venice, 2017).
Chang, J. R. & Chen, Y. S. Pyramid stereo matching network. In Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5410â5418 (IEEE, Salt Lake City, UT, 2018).
Zhang, F. H. et al. GA-Net: guided aggregation net for end-to-end stereo matching. In Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 185â194 (IEEE, Long Beach, CA, 2019).
Yin, W. et al. Single-shot 3D shape measurement using an end-to-end stereo matching network for speckle projection profilometry. Opt. Express 29, 13388â13407 (2021).
Nguyen, H. et al. Three-dimensional shape reconstruction from single-shot speckle image using deep convolutional neural networks. Opt. Lasers Eng. 143, 106639 (2021).
Knöbelreiter, P. et al. End-to-end training of hybrid CNN-CRF models for stereo. In Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 1456â1465 (IEEE, Honolulu, HI, 2017).
Ummenhofer, B. et al. DeMoN: depth and motion network for learning monocular stereo. In Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. 5622â5631 (IEEE, Honolulu, HI, 2017).
Yao, Y. et al. MVSNet: depth inference for unstructured multi-view stereo. In Proceedings of the 15th European Conference on Computer Vision. 785â801 (Springer, Munich, 2018).
Liang, Z. F. et al. Learning for disparity estimation through feature constancy. In Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2811â2820 (IEEE, Salt Lake City, UT, 2018).
Yang, G. R. et al. SegStereo: exploiting semantic information for disparity estimation. In Proceedings of the 15th European Conference on Computer Vision (ECCV). 660â676 (Springer, Munich, 2018).
Song, X. et al. EdgeStereo: a context integrated residual pyramid network for stereo matching. In Proceedings of the 14th Asian Conference on Computer Vision. 20â35 (Springer, Perth, 2018).
Yu, L. D. et al. Deep stereo matching with explicit cost aggregation sub-architecture. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence. (AAAI, New Orleans, LA, 2018).
Fanello, S. R. et al. HyperDepth: learning depth from structured light without matching. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 5441â5450 (IEEE, Las Vegas, NV, 2016).
Tulyakov, S., Ivanov, A. & Fleuret, F. Practical deep stereo (PDS): toward applications-friendly deep stereo matching. In Proceedings of the 32nd International Conference on Neural Information Processing Systems. 5871â5881 (ACM, Montréal, 2018).
Nie, G. Y. et al. Multi-level context ultra-aggregation for stereo matching. In Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 3278â3286 (IEEE, Long Beach, CA, 2019).
Zhong, Y. R., Li, H. D. & Dai, Y. C. Open-world stereo video matching with deep RNN. In Proceedings of the 15th European Conference on Computer Vision (ECCV). 101â116 (Springer, Munich, 2018).
Tonioni, A. et al. Unsupervised adaptation for deep stereo. In Proceedings of 2017 IEEE International Conference on Computer Vision (ICCV). 1614â1622 (IEEE, Venice, 2017).
Tonioni, A. et al. Unsupervised domain adaptation for depth prediction from images. IEEE Trans. Pattern Anal. Mach. Intell. 42, 2396â2409 (2020).
Chen, X. Y. Non-destructive three-dimensional measurement of hand vein based on self-supervised network. Measurement 173, 108621 (2020).
Zhang, Y. D. et al. ActiveStereoNet: end-to-end self-supervised learning for active stereo systems. In Proceedings of the 15th European Conference on Computer Vision (ECCV). 802â819 (Springer, Munich, 2018).
Tonioni, A. et al. Learning to Adapt for Stereo. In Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 9653â9662 (IEEE, Long Beach, CA, 2019).
Boukhtache, S. et al. When deep learning meets digital image correlation. Opt. Lasers Eng. 136, 106308 (2021).
Min, H. G. et al. Strain measurement during tensile testing using deep learning-based digital image correlation. Meas. Sci. Technol. 31, 015014 (2020).
Rezaie, A. et al. Comparison of crack segmentation using digital image correlation measurements and deep learning. Constr. Build. Mater. 261, 120474 (2020).
Son, K., Liu, M. Y. & Taguchi, Y. Learning to remove multipath distortions in time-of-flight range images for a robotic arm setup. In Proceedings of 2016 IEEE International Conference on Robotics and Automation (ICRA). 3390â3397 (IEEE, Stockholm, 2016).
Marco, J. et al. DeepToF: off-the-shelf real-time correction of multipath interference in time-of-flight imaging. ACM Trans. Graph. 36, 219 (2017).
Song, S. & Shim, H. Depth reconstruction of translucent objects from a single time-of-flight camera using deep residual networks. In Proceedings of the 14th Asian Conference on Computer Vision. 641â657 (Springer, Perth, 2018).
Su, S. C. et al. Deep end-to-end time-of-flight imaging. In Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6383â6392 (IEEE, Salt Lake City, UT, 2018).
Chen, Y. et al. A learning method to optimize depth accuracy and frame rate for Time of Flight camera. IOP Conf. Ser.: Mater. Sci. Eng. 563, 042067 (2019).
Chen, Y. et al. Very power efficient neural time-of-flight. In Proceedings of 2020 IEEE Winter Conference on Applications of Computer Vision. 2246â2255 (IEEE, Snowmass, CO, 2020).
Santo, H. et al. Deep photometric stereo network. In Proceedings of 2017 IEEE International Conference on Computer Vision Workshops. 501â509 (IEEE, Venice, 2017).
Ikehata, S. CNN-PS: CNN-based photometric stereo for general non-convex surfaces. In Proceedings of the 15th European Conference on Computer Vision (ECCV). 3â19 (Springer, Munich, 2018).
Taniai, T. & Maehara, T. Neural inverse rendering for general reflectance photometric stereo. In Proceedings of the 35th International Conference on Machine Learning. 4864â4873 (PMLR, Stockholm, 2018).
Xu, Z. X. et al. Deep image-based relighting from optimal sparse samples. ACM Trans. Graph. 37, 126 (2018).
Li, J. X. et al. Learning to minify photometric stereo. In Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7560â7568 (IEEE, Long Beach, CA, 2019).
Chen, G. Y. et al. Self-calibrating deep photometric stereo networks. In Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8731â8739 (IEEE, Long Beach, CA, 2019).
Sang, L., Haefner, B. & Cremers, D. Inferring super-resolution depth from a moving light-source enhanced RGB-D sensor: a variational approach. In Proceedings of 2020 IEEE Winter Conference on Applications of Computer Vision. 1â10 (IEEE, Snowmass, CO, 2020).
Nishizaki, Y. et al. Deep learning wavefront sensing. Opt. Express 27, 240â251 (2019).
Hu, L. J. et al. Learning-based Shack-Hartmann wavefront sensor for high-order aberration detection. Opt. Express 27, 33504â33517 (2019).
DuBose, T. B., Gardner, D. F. & Watnik, A. T. Intensity-enhanced deep network wavefront reconstruction in ShackâHartmann sensors. Opt. Lett. 45, 1699â1702 (2020).
Hu, L. J. et al. Deep learning assisted ShackâHartmann wavefront sensor for direct wavefront detection. Opt. Lett. 45, 3741â3744 (2020).
Rodin, I. A. et al. Recognition of wavefront aberrations types corresponding to single Zernike functions from the pattern of the point spread function in the focal plane using neural networks. Computer Opt. 44, 923â930 (2020).
Moran, O. et al. Deep, complex, invertible networks for inversion of transmission effects in multimode optical fibres. In Proceedings of the 32nd International Conference on Neural Information Processing Systems. 3284â3295 (ACM, Montréal, 2018).
Borhani, N. et al. Learning to see through multimode fibers. Optica 5, 960â966 (2018).
Fan, P. F., Zhao, T. R. & Su, L. Deep learning the high variability and randomness inside multimode fibers. Opt. Express 27, 20241â20258 (2019).
Caramazza, P. et al. Transmission of natural scene images through a multimode fibre. Nat. Commun. 10, 2029 (2019).
Fan, P. F. et al. Speckle reconstruction with corruption through multimode fibers using deep learning. In Proceedings of 2020 Conference on Lasers and Electro-Optics (CLEO). 1â2 (IEEE, San Jose, CA, 2020).
Sun, C. et al. Revisiting unreasonable effectiveness of data in deep learning era. In Proceedings of 2017 IEEE International Conference on Computer Vision. 843â852 (IEEE, Venice, 2017).
Pan, S. J. & Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 22, 1345â1359 (2010).
Sung, F. et al. Learning to compare: relation network for few-shot learning. In Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1199â1208 (IEEE, Salt Lake City, UT, 2018).
Goh, G. B. et al. Using rule-based labels for weak supervised learning: a ChemNet for transferable chemical property prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 302â310 (ACM, London, 2018).
Hutter, F., Kotthoff, L. & Vanschoren, J. Automated Machine Learning: Methods, Systems, Challenges (Springer, 2019).
Neyshabur, B. et al. Exploring generalization in deep learning. In Proceedings of the 31st International Conference on Neural Information Processing Systems. 5949â5958 (ACM, Long Beach, CA, 2017).
Ledig, C. et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. 105â114 (IEEE, Honolulu, HI, 2017).
Qian, J. M. et al. High-resolution real-time 360° 3D surface defect inspection with fringe projection profilometry. Opt. Lasers Eng. 137, 106382 (2021).
Jing, L. L. & Tian, Y. L. Self-supervised visual feature learning with deep neural networks: a survey. IEEE Trans. Pattern Anal. Mach. Intell. 43, 4037â4058 (2021).
Baker, B. et al. Designing neural network architectures using reinforcement learning. In Proceedings of the 5th International Conference on Learning Representations. (OpenReview, Toulon, 2017).
Bisong, E. Google AutoML: cloud vision. In Building Machine Learning and Deep Learning Models on Google Cloud Platform: A Comprehensive Guide for Beginners (ed. Bisong, E.) 581â598 (Springer, 2019).
Barnes, J. Microsoft Azure Essentials Azure Machine Learning (Microsoft Press, 2015)
Feurer, M. et al. Efficient and robust automated machine learning. In Proceedings of the 28th International Conference on Neural Information Processing Systems. 2755â2763 (ACM, Montreal, 2015).
Wang, F. et al. Phase imaging with an untrained neural network. Light.: Sci. Appl. 9, 77 (2020).
Abdar, M. et al. A review of uncertainty quantification in deep learning: techniques, applications and challenges. Inf. Fusion 76, 243â297 (2021).
Korattikara, A. et al. Bayesian dark knowledge. In Proceedings of the 28th International Conference on Neural Information Processing Systems. (ACM, Montreal, 2015).
Shekhovtsov, A. & Flach, B. Feed-forward propagation in probabilistic neural networks with categorical and max layers. In Proceedings of the 7th International Conference on Learning Representations. (OpenReview, New Orleans, LA, 2019).
Feng, S. J. et al. Deep-learning-based fringe-pattern analysis with uncertainty estimation. Optica 8, 1507â1510 (2021).
Chakrabarti, A. Learning sensor multiplexing design through back-propagation. In Proceedings of the 30th International Conference on Neural Information Processing Systems. 3089â3097 (ACM, Barcelona, 2016).
Horstmeyer, R. et al. Convolutional neural networks that teach microscopes how to image. Preprint at https://arxiv.org/abs/1709.07223 (2017).
Kellman, M. R. et al. Physics-based learned design: optimized coded-illumination for quantitative phase imaging. IEEE Trans. Comput. Imaging 5, 344â353 (2019).
Muthumbi, A. et al. Learned sensing: jointly optimized microscope hardware for accurate image classification. Biomed. Opt. Express 10, 6351â6369 (2019).
Kim, Y. et al. Evaluation for snowfall depth forecasting using neural network and multiple regression models. J. Korean Soc. Hazard Mitig. 13, 269â280 (2013).
Geiger, A. et al. Vision meets robotics: the KITTI dataset. Int. J. Robot. Res. 32, 1231â1237 (2013).
Hirschmuller, H. & Scharstein, D. Evaluation of cost functions for stereo matching. In Proceedings of 2007 IEEE Conference on Computer Vision and Pattern Recognition. 1â8 (IEEE, Minneapolis, MN, 2007).
Acknowledgements
This work was supported by National Natural Science Foundation of China (U21B2033, 62075096, 62005121), Leading Technology of Jiangsu Basic Research Plan (BK20192003), â333 Engineeringâ Research Project of Jiangsu Province (BRA2016407), Jiangsu Provincial âOne belt and one roadâ innovation cooperation project (BZ2020007), Fundamental Research Funds for the Central Universities (30921011208, 30919011222, 30920032101), and Open Research Fund of Jiangsu Key Laboratory of Spectral Imaging & Intelligent Sense (JSGP202105).
Author information
Authors and Affiliations
Contributions
C.Z.: conceptualization, writingâoriginal draft, data curation, visualization, supervision, project administration, and funding acquisition. J.Q.: investigation, writingâreview, visualization, and editing. S.F.: writingâreview and editing. W.Y.: writingâreview and editing. Y.L.: writingâreview, visualization, and editing. P.F.: writingâreview and editing. J.H.: writingâreview and editing. K.Q.: writingâreview and editing. Q.C.: resources, supervision, project administration, and funding acquisition.
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Smart Computational Imaging (SCI) Laboratory: https://scilaboratory.com/
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the articleâs Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the articleâs Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zuo, C., Qian, J., Feng, S. et al. Deep learning in optical metrology: a review. Light Sci Appl 11, 39 (2022). https://doi.org/10.1038/s41377-022-00714-x
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41377-022-00714-x
This article is cited by
-
Deep-learning-enabled temporally super-resolved multiplexed fringe projection profilometry: high-speed kHz 3D imaging with low-speed camera
PhotoniX (2024)
-
Fast topographic optical imaging using encoded search focal scan
Nature Communications (2024)
-
LGIT: localâglobal interaction transformer for low-light image denoising
Scientific Reports (2024)
-
Deep learning sheds new light on non-orthogonal optical multiplexing
Light: Science & Applications (2024)
-
AI-driven projection tomography with multicore fibre-optic cell rotation
Nature Communications (2024)
