
APTrans: Transformer-Based Multilayer Semantic and Locational Feature Integration for Efficient Text Classification

Abstract
:1. Introduction
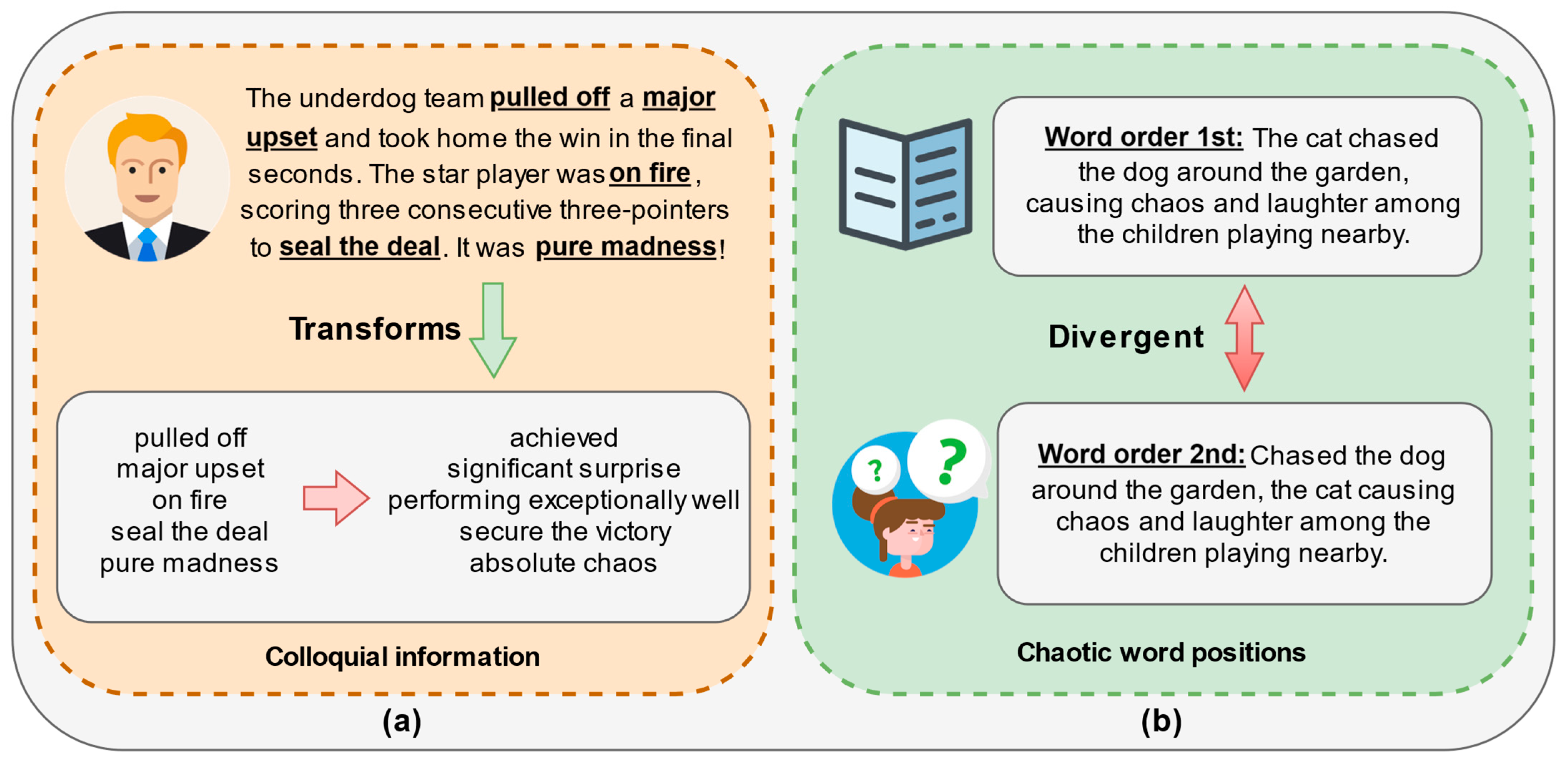
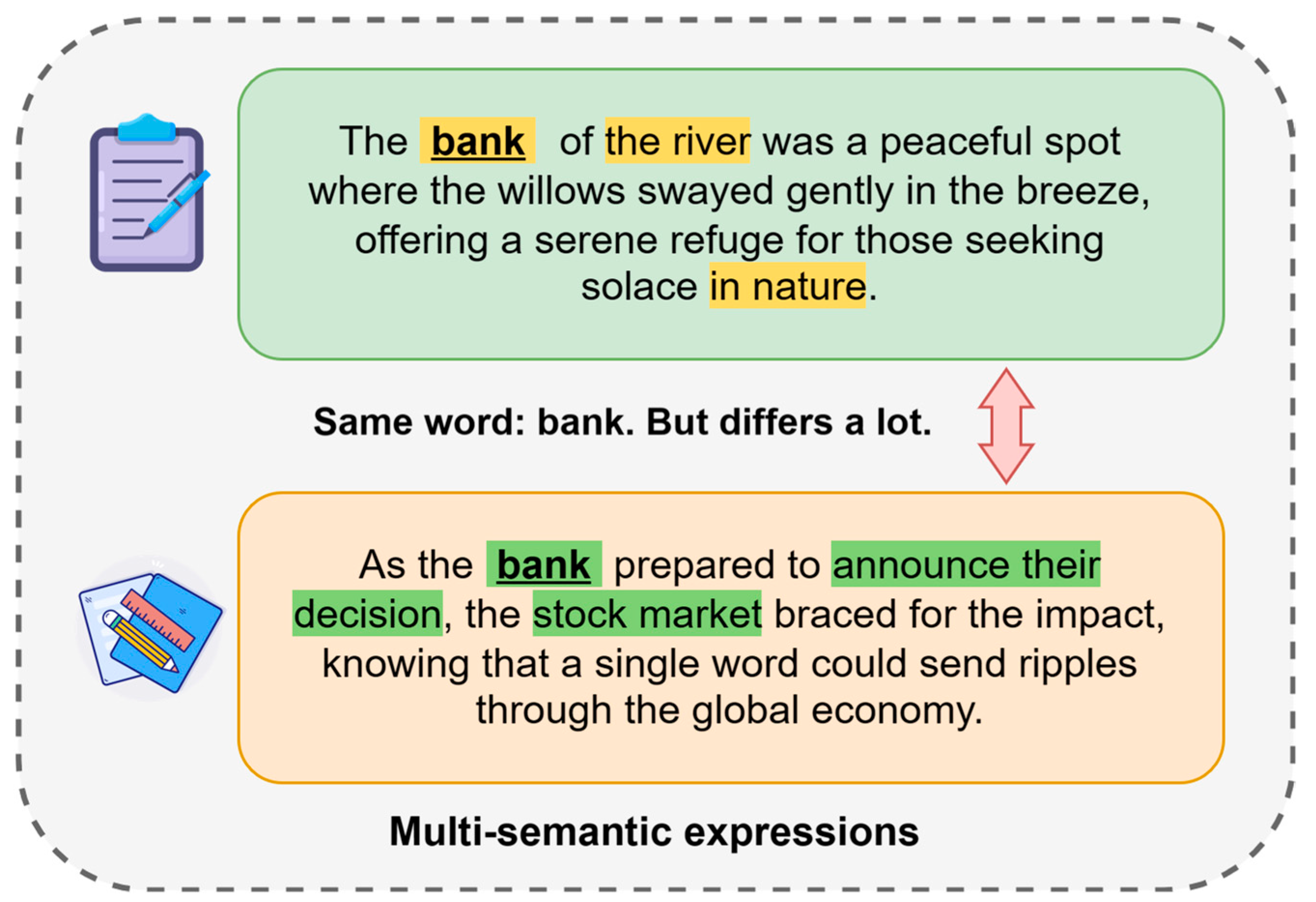
1.1. Challenges
1.2. Observations and Insights
1.3. Contributions
- Three clues are obtained in the survey statements, including core relevance information, semantic location associations, and the mining characteristics of deep and shallow networks for different information. The core correlation information and semantic location associations confirm that the existence of key words in the text and the relative location information have an important impact on the effect of the final classifier. The other remaining clue ensures that we consider the lower layers’ information as important as the high layers’ information during the development of the model. Based on this, we propose a discriminant method, APTrans, for text classification to leverage our findings and address challenging environments.
- We reveal two key insights about sentences, namely, the key information relationship and word group inline relationship. In the proposed hierarchical deeper attention module, we improve the procedural computing mechanism of multi-head attention, enhancing the ability to extract the relationship between words by parallelizing attention computing processing. Moreover, the attention calculation of the text vector output from the backbone network is carried out again to ensure that the model can fully mine the key lexical semantic and location information in the text. The FFCon module transmits information through hierarchical iteration and shrinks text features through MLP, aiming to complete the fusion of multi-level semantic and positional information. Based on this, APTrans is able to solve the challenges caused by colloquial words or multi-semantic texts by mining and integrating the relative position information of texts, so as to achieve better classification results.
- APTrans has been shown to be efficiently applied to text classification in real NLP tasks through a large number of experiments and to perform comparisons on multiple text classification benchmark datasets. In addition, we demonstrate through modular ablation experiments that the two proposed modules, the hierarchical deeper attention module and FFCon module, have an important impact on the overall effect of the model. Furthermore, we conducted visualization experiments to prove that the model effectively leverages locational information for prediction.
2. Related Work
2.1. Problem Formulation
2.2. Model Based on Traditional Methods
2.3. T-PTLM Technology
2.4. Summary of Previous Work
3. Proposed Method
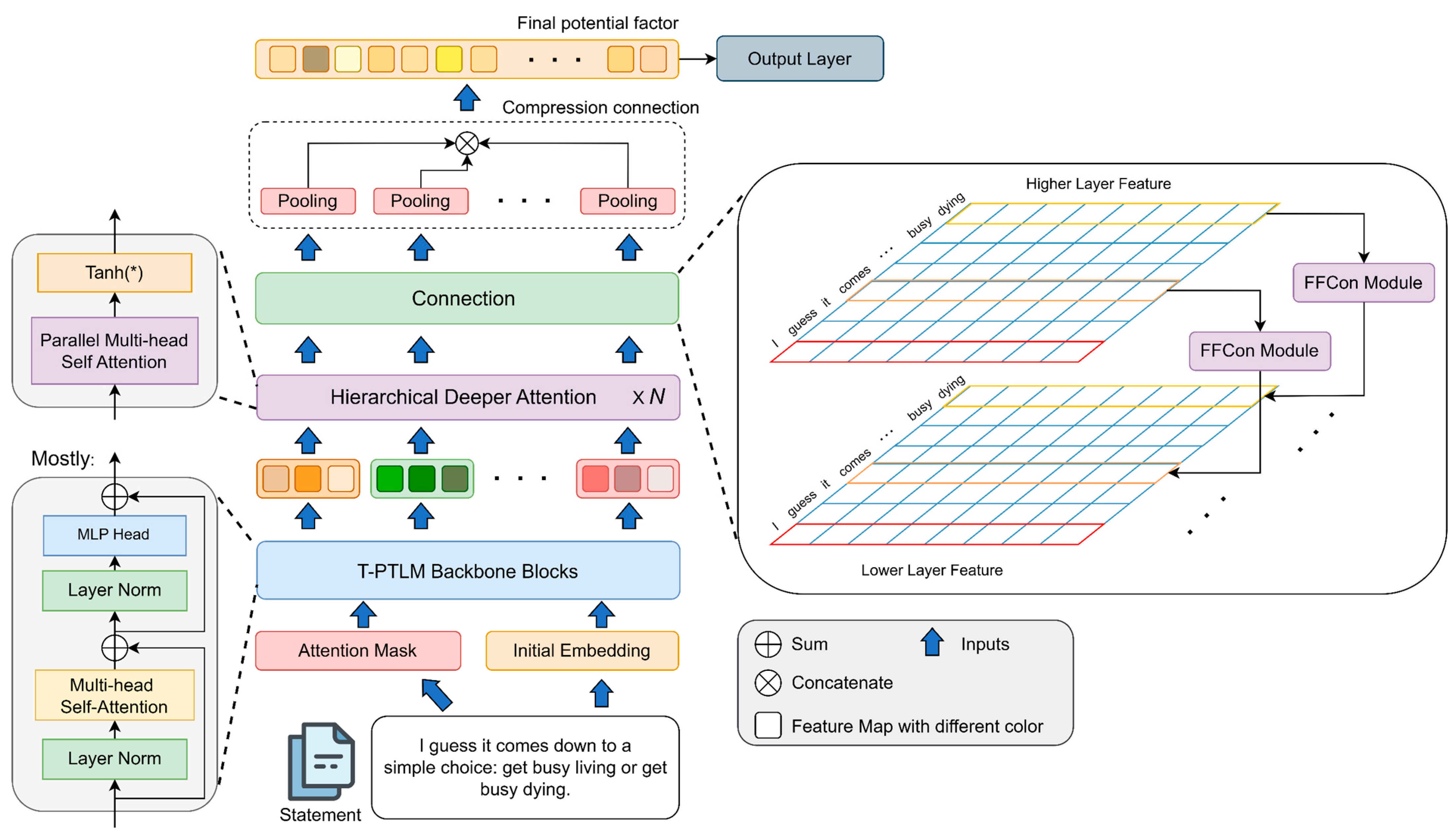
3.1. Architecture Overview
3.2. Feature Mapping Module
3.3. Hierarchical Deeper Attention Module
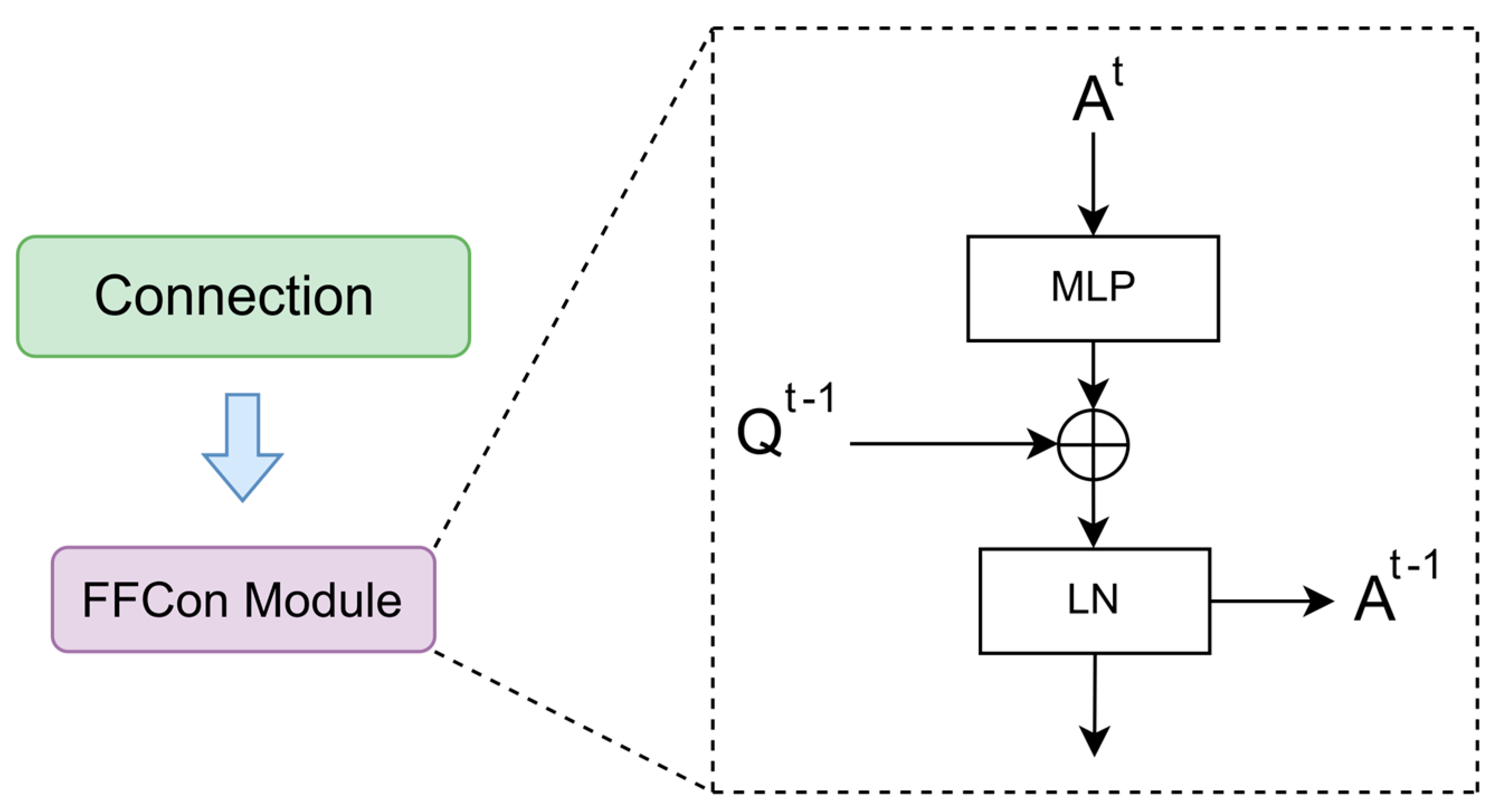
3.4. FFCon Module
3.5. Compression Connection Module
4. Experimental Results
4.1. General Setting
4.1.1. Datasets
4.1.2. Evaluation Metrics
4.1.3. Compared Methods
4.2. Implementation Details
4.3. Experiment Results and Analysis
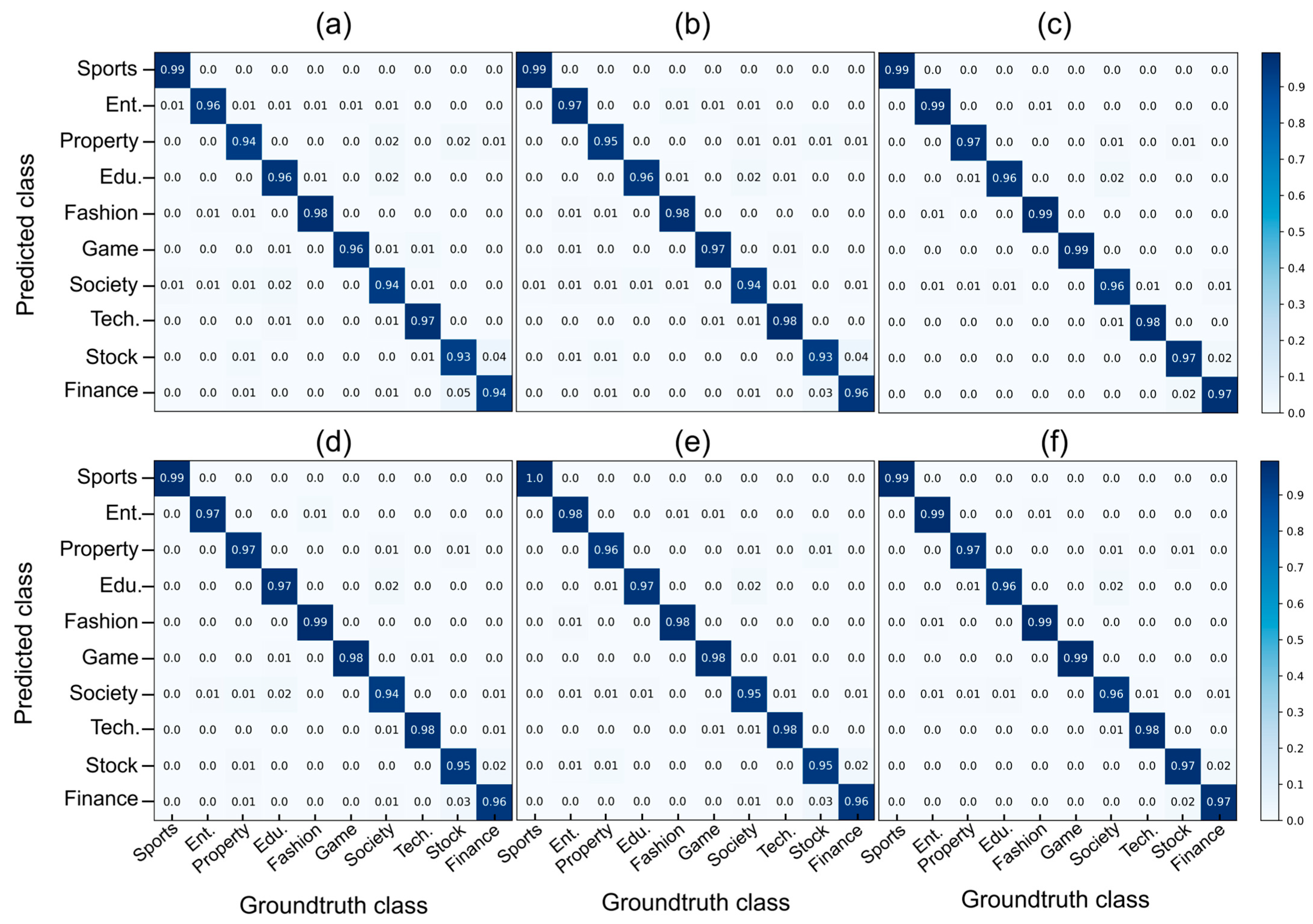
4.3.1. Results on the THUCNews Dataset
4.3.2. Results on the AG News Dataset
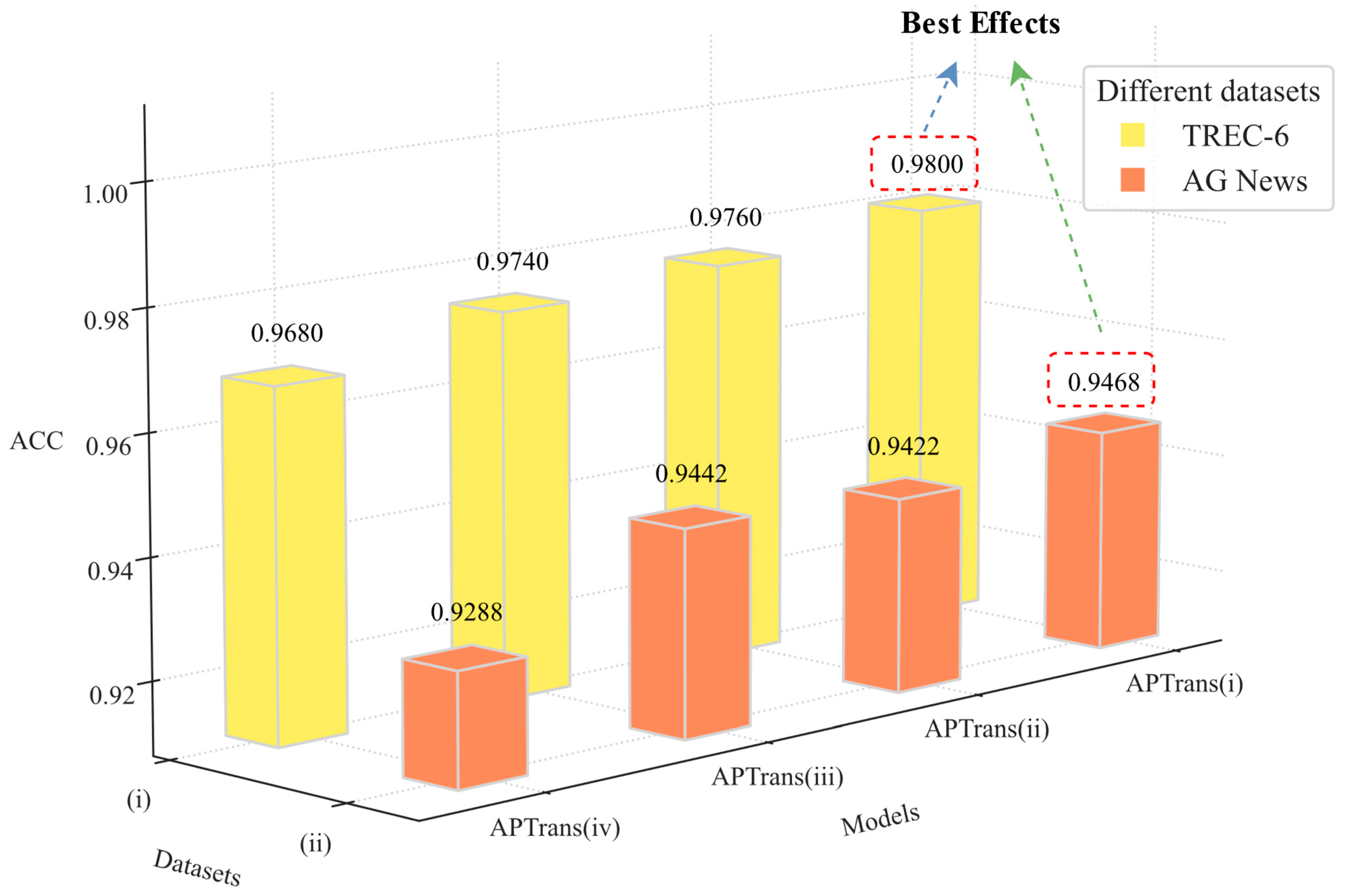
4.3.3. Results on the TREC-6 Dataset
4.3.4. Ablation Study
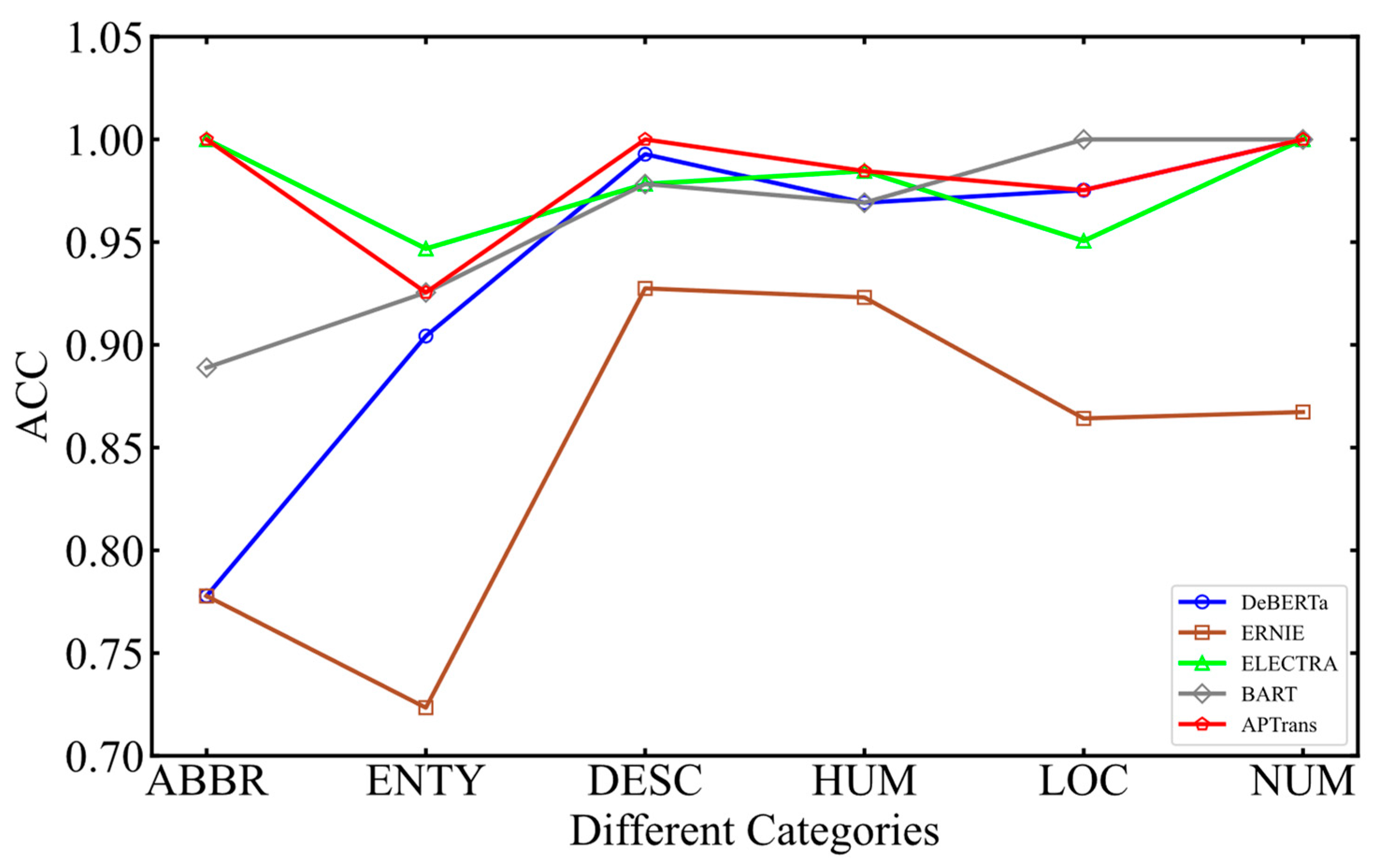
4.3.5. Confusion Matrix and Analysis
4.3.6. Expansion Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Stroudsburg, PA, USA, 2014; pp. 1746–1751. [Google Scholar]
- Johnson, R.; Zhang, T. Deep Pyramid Convolutional Neural Networks for Text Categorization. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 562–570. [Google Scholar]
- Le, H.T.; Cerisara, C.; Denis, A. Do Convolutional Networks Need to Be Deep for Text Classification? In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Pota, M.; Esposito, M.; De Pietro, G.; Fujita, H. Best Practices of Convolutional Neural Networks for Question Classification. Appl. Sci. 2020, 10, 4710. [Google Scholar] [CrossRef]
- Liu, P.; Qiu, X.; Huang, X. Recurrent Neural Network for Text Classification with Multi-Task Learning. In Proceedings of the 25th International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 2873–2879. [Google Scholar]
- Tai, K.S.; Socher, R.; Manning, C.D. Improved Semantic Representations from Tree-Structured Long Short-Term Memory Networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised Classification with Graph Convolutional Networks. In Proceedings of the 5th International Conference on Learning Representations(ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic Routing between Capsules. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. In Proceedings of the 8th International Conference on Learning Representations(ICLR), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Liu, H.; Zhang, C.; Deng, Y.; Xie, B.; Liu, T.; Zhang, Z.; Li, Y. TransIFC: Invariant Cues-aware Feature Concentration Learning for Efficient Fine-grained Bird Image Classification. IEEE Trans. Multimed. 2023. [Google Scholar] [CrossRef]
- Liu, T.; Liu, H.; Yang, B.; Zhang, Z. LDCNet: Limb Direction Cues-aware Network for Flexible Human Pose Estimation in Industrial Behavioral Biometrics Systems. IEEE Trans. Ind. Inf. 2024. [Google Scholar] [CrossRef]
- Liu, H.; Liu, T.; Chen, Y.; Zhang, Z.; Li, Y. EHPE: Skeleton Cues-based Gaussian Coordinate Encoding for Efficient Human Pose Estimation. IEEE Trans. Multimed. 2024, 124–138. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, C.; Deng, Y.; Liu, T.; Zhang, Z.; Li, Y. Orientation Cues-Aware Facial Relationship Representation for Head Pose Estimation via Transformer. IEEE Trans. Image Process. 2023, 32, 6289–6302. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. In Proceedings of the 28th Annual Conference on Neural Information Processing Systems, Quebec, QC, Canada, 8–13 December 2014. [Google Scholar]
- Zhou, Y.; Xu, B.; Xu, J.; Yang, L.; Li, C.; Xu, B. Compositional Recurrent Neural Networks for Chinese Short Text Classification. In Proceedings of the 2016 IEEE/WIC/ACM International Conference on Web Intelligence (WI), Omaha, NE, USA, 13–16 October 2016; pp. 137–144. [Google Scholar]
- She, X.; Zhang, D. Text Classification Based on Hybrid CNN-LSTM Hybrid Model. In Proceedings of the 11th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 8–9 December 2018. [Google Scholar]
- Khan, L.; Amjad, A.; Afaq, K.M.; Chang, H.-T. Deep Sentiment Analysis Using CNN-LSTM Architecture of English and Roman Urdu Text Shared in Social Media. Appl. Sci. 2022, 12, 2694. [Google Scholar] [CrossRef]
- Gao, Z.; Li, Z.; Luo, J.; Li, X. Short Text Aspect-Based Sentiment Analysis Based on CNN + BiGRU. Appl. Sci. 2022, 12, 2707. [Google Scholar] [CrossRef]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical Attention Networks for Document Classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–16 June 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 1480–1489. [Google Scholar]
- Zhou, Y.; Li, C.; Xu, B.; Xu, J.; Cao, J.; Xu, B. Hierarchical Hybrid Attention Networks for Chinese Conversation Topic Classification. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, USA, 4–9 December 2017. [Google Scholar]
- Jang, B.; Kim, M.; Harerimana, G.; Kang, S.-U.; Kim, J.W. Bi-LSTM Model to Increase Accuracy in Text Classification: Combining Word2vec CNN and Attention Mechanism. Appl. Sci. 2020, 10, 5841. [Google Scholar] [CrossRef]
- Zheng, W.; Liu, X.; Yin, L. Sentence Representation Method Based on Multi-Layer Semantic Network. Appl. Sci. 2021, 11, 1316. [Google Scholar] [CrossRef]
- Chen, Z.; Li, J.; Liu, H.; Wang, X.; Wang, H.; Zheng, Q. Learning Multi-Scale Features for Speech Emotion Recognition with Connection Attention Mechanism. Expert Syst. Appl. 2023, 214, 118943. [Google Scholar] [CrossRef]
- Yao, L.; Mao, C.; Luo, Y. Graph Convolutional Networks for Text Classification. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence and 31st Innovative Applications of Artificial Intelligence Conference and 9th AAAI Symposium on Educational Advances in Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Zhou, D.; Yu, H.; Yu, J.; Zhao, S.; Xu, W.; Li, Q.; Cai, F. MFDS-STGCN: Predicting the Behaviors of College Students With Fine-Grained Spatial-Temporal Activities Data. IEEE Trans. Emerg. Top. Comput. 2024, 12, 254–265. [Google Scholar] [CrossRef]
- Linmei, H.; Yang, T.; Shi, C.; Ji, H.; Li, X. Heterogeneous Graph Attention Networks for Semi-Supervised Short Text Classification. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 4820–4829. [Google Scholar]
- Yang, M.; Zhao, W.; Chen, L.; Qu, Q.; Zhao, Z.; Shen, Y. Investigating the transferring capability of capsule networks for text classification. Neural Netw. 2019, 118, 247–261. [Google Scholar] [CrossRef] [PubMed]
- Kalyan, K.S.; Rajasekharan, A.; Sangeetha, S. AMMU: A Survey of Transformer-Based Biomedical Pretrained Language Models. J. Biomed. Inform. 2022, 126, 103982. [Google Scholar] [CrossRef] [PubMed]
- Peters, M.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 1–6 June 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 2227–2237. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. Available online: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 22 March 2024).
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-Train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing. ACM Comput. Surv. 2023, 55, 1–35. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models Are Unsupervised Multitask Learners. Available online: https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf (accessed on 22 March 2024).
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Bashynska, I.; Sarafanov, M.; Manikaeva, O. Research and Development of a Modern Deep Learning Model for Emotional Analysis Management of Text Data. Appl. Sci. 2024, 14, 1952. [Google Scholar] [CrossRef]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.; Salakhutdinov, R. Transformer-XL: Attentive Language Models beyond a Fixed-Length Context. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 2978–2988. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; Liu, Q., Schlangen, D., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 38–45. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Misra, D. Mish: A Self Regularized Non-Monotonic Activation Function. In Proceedings of the 31st British Machine Vision Virtual Conference(BMVC), Manchester, UK, 7–11 September 2020. [Google Scholar]
- Li, J.; Sun, M. Scalable Term Selection for Text Categorization. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), Prague, Czech Republic, 28–30 June 2007; Association for Computational Linguistics: Stroudsburg, PA, USA, 2007. [Google Scholar]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level convolutional networks for text classification. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 1, pp. 649–657. [Google Scholar]
- Li, X.; Roth, D. Learning Question Classifiers: The Role of Semantic Information. Nat. Lang. Eng. 2006, 12, 229–249. [Google Scholar] [CrossRef]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-Training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 7871–7880. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. In Proceedings of the 8th International Conference on Learning Representations(ICLR), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Zhang, Z.; Han, X.; Liu, Z.; Jiang, X.; Sun, M.; Liu, Q. ERNIE: Enhanced Language Representation with Informative Entities. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 1441–1451. [Google Scholar]
- Clark, K.; Luong, M.-T.; Le, Q.V. ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. In Proceedings of the 8th International Conference on Learning Representations(ICLR), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Song, K.; Tan, X.; Qin, T.; Lu, J.; Liu, T.-Y. MPNet: Masked and Permuted Pre-Training for Language Understanding. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; pp. 16857–16867. [Google Scholar]
- Cui, Y.; Che, W.; Liu, T.; Qin, B.; Wang, S.; Hu, G. Revisiting Pre-Trained Models for Chinese Natural Language Processing. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 657–668. [Google Scholar]
- Zaheer, M.; Guruganesh, G.; Dubey, A.; Ainslie, J.; Alberti, C.; Ontanon, S.; Pham, P.; Ravula, A.; Wang, Q.; Yang, L.; et al. Big Bird: Transformers for Longer Sequences. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; pp. 17283–17297. [Google Scholar]
- He, P.; Liu, X.; Gao, J.; Chen, W. DeBERTa: Decoding-enhanced BERT with Disentangled Attention. In Proceedings of the 9th International Conference on Learning Representations(ICLR), Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Hua, J.; Sun, D.; Hu, Y.; Wang, J.; Feng, S.; Wang, Z. Heterogeneous Graph-Convolution-Network-Based Short-Text Classification. Appl. Sci. 2024, 14, 2279. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Pad Size | Dev Acc (%) | Test Acc (%) |
|---|---|---|---|
| BigBird [52] | 512 | 96.85 | 95.73 |
| ALBERT [47] | 96.95 | 96.64 | |
| DeBERTa [53] | 97.15 | 96.33 | |
| ELECTRA [49] | 97.45 | 97.32 | |
| GPT-2 [36] | 97.80 | 97.51 | |
| BART [46] | 97.85 | 97.10 | |
| RoBERTa [11] | 98.00 | 97.11 | |
| BERT [10] | 98.30 | 97.67 | |
| ERNIE [48] | 98.30 | 97.15 | |
| XLNet [12] | 98.45 | 97.67 | |
| APTrans (ours) | 98.55 | 97.89 |
| Methods | Pad Size | Acc (%) |
|---|---|---|
| SHGCN [54] | None | 88.38 |
| ERNIE [48] | 512 | 90.79 |
| DeBERTa [53] | 91.38 | |
| ALBERT [47] | 93.13 | |
| MPNet [50] | 93.22 | |
| GPT-2 [36] | 94.20 | |
| ELECTRA [49] | 94.28 | |
| RoBERTa [11] | 94.42 | |
| XLNet [12] | 94.51 | |
| BERT [10] | 94.57 | |
| APTrans (ours) | 94.68 |
| Methods | Pad Size | Acc (%) |
|---|---|---|
| ERNIE [48] | 128 | 86.20 |
| ALBERT [47] | 95.80 | |
| GPT-2 [36] | 96.40 | |
| DeBERTa [53] | 96.80 | |
| BERT [10] | 97.00 | |
| RoBERTa [11] | 97.20 | |
| ELECTRA [49] | 97.40 | |
| BART [46] | 97.40 | |
| APTrans (ours) | 98.00 |
| Methods | Pad Size | Acc (%) |
|---|---|---|
| BigBird [52] | 128 | 77.34 |
| DeBERTa [53] | 73.69 | |
| ALBERT [47] | 73.70 | |
| ELECTRA [49] | 80.47 | |
| GPT-2 [36] | 82.02 | |
| XLNet [12] | 82.03 | |
| RoBERTa [11] | 83.06 | |
| BART [46] | 83.07 | |
| ERNIE [48] | 83.07 | |
| APTrans (ours) | 83.33 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, G.; Chen, Z.; Liu, H.; Liu, T.; Wang, B. APTrans: Transformer-Based Multilayer Semantic and Locational Feature Integration for Efficient Text Classification. Appl. Sci. 2024, 14, 4863. https://doi.org/10.3390/app14114863
Ji G, Chen Z, Liu H, Liu T, Wang B. APTrans: Transformer-Based Multilayer Semantic and Locational Feature Integration for Efficient Text Classification. Applied Sciences. 2024; 14(11):4863. https://doi.org/10.3390/app14114863
Chicago/Turabian StyleJi, Gaoyang, Zengzhao Chen, Hai Liu, Tingting Liu, and Bing Wang. 2024. "APTrans: Transformer-Based Multilayer Semantic and Locational Feature Integration for Efficient Text Classification" Applied Sciences 14, no. 11: 4863. https://doi.org/10.3390/app14114863