1. Introduction
Over the past few years, the number of applications has grown exponentially, and the variety of innovative applications has exploded [
1]. It has become increasingly challenging for computing resources to meet the demands of application devices, which cannot process tasks locally with low latency. The traditional way of offloading tasks in cloud computing suffers from high latency, network congestion, and long transmission distances, which no longer meet the demands of compute-intensive and latency-sensitive tasks [
2]. MEC provides computing power closer to the user by pushing computing resources to the edge of the network, enabling faster and more responsive task processing [
3,
4,
5]. Users can place tasks on edge servers for processing by means of task offloading, thus not only relying on local device computation [
6]. In contrast to traditional cloud computing, MEC is less costly for data transfer and easier for task offloading [
7].
Although MEC is gradually moving in a prominent direction, there are still many challenges. In mobile edge computing scenarios, the dynamic and random tasks to be processed are difficult to predict accurately. There is a need to consider how to offload tasks to MEC edge servers while maintaining system performance benefits [
8]. When performing task offloading, the offloading incurs a series of overheads. The energy consumption and latency in performing task offloading are particularly important. Therefore, we need to find a task-offloading strategy to optimize energy consumption and latency.
In order to find a suitable task-offloading strategy, current research delves deeply and has conducted a large number of studies on computational task-offloading strategies. Typically, this involves solving mixed-integer nonlinear programming (MINLP) problems. Since decoupling these problems is very complex, most studies have focused on how to reduce the complexity of the algorithms, and many heuristic algorithms have been proposed [
9,
10,
11,
12,
13,
14,
15]. However, finding a superior task-offloading strategy through heuristic algorithms requires complex and repetitive iteration. In a realistic scenario, if the parameters change, the MINLP problem needs to be solved all over again, resulting in computational redundancy. Therefore, the costs incurred by using traditional optimization algorithms in MEC environments with frequent dynamic changes are very high. However, the emergence of deep reinforcement learning now provides a state-of-the-art solution to address online computational offloading strategy.
In addition to the need to optimize performance, long-term system stability and staying within the MEC’s energy budget need to be considered. Failure to consider local energy stability and the limited energy budget of the MEC may result in performance degradation of the offloading policy during a long-term task-offloading process, resulting in a reduced ability to make accurate decisions in real time. Yet most DRL-based research approaches nowadays give little consideration to the stability of local system energy consumption in the long term and the impact of energy budget constraints in MEC. There is no overall optimization of the system in the context of a long-term constraint, and most of the studies only introduce events that trigger task failures, such as [
16,
17,
18] by introducing packet loss events.
In this paper, we study the dynamic task-offloading strategy in dynamic multi-user MEC scenarios and propose a strategy to solve task offloading with long-term constraints. The long-term constraints are represented by building multiple queues. And the LMADDPG algorithm is designed using a joint approach to its optimization, which can take full advantage of Lyapunov optimization and DRL. In a dynamic stochastic MEC scenario, an optimal task-offloading policy is found to ensure minimizing the task-offloading cost, which maximizes the user’s QoE. The main contributions are as follows:
We propose a real-time task-offloading problem with long-term local system energy consumption and energy budget constraints for MEC in a dynamic MEC scenario. The objective is to maximize the QoE while ensuring that the constraints can be satisfied in the long run. An optimal task-offloading strategy is found to minimize the weighted sum of delay and energy consumption in an unknown dynamic scenario.
We propose a task-offloading strategy with long-term constraints. The long-term constraint states are represented by creating multiple queues that are jointly optimized with the optimization objective. Unlike other studies that directly add adverse behaviors to the penalty term, we model the problem as a problem with long-term constraints. The problem is decoupled using Lyapunov optimization and transformed into a MINLP problem with a single time slot, thus facilitating the solving of real-time optimization problems.
We describe the problem as an MDP and then design an LMADDPG algorithm based on the union of Lyapunov optimization and deep reinforcement learning, which solves the real-time task-offloading problem by establishing the advantages of deep reinforcement learning.
We testify the LMADDPG algorithm experimentally, proving its ability to find an optimal task-offloading strategy to ensure minimization of cost under long-term constraints, and comparing it with other baseline algorithms.
The rest of the paper is structured as follows:
Section 2 discusses related work.
Section 3 describes the system modeling.
Section 4 describes the problem description and problem transformation process.
Section 5 details the algorithmic design of the LMADDPG algorithm.
Section 6 describes the experimental parameter settings and analyses the experimental simulation results.
Section 7 concludes the paper.
2. Related Work
MEC has strong computing power, which can provide a platform for user devices to support them in offloading tasks to their servers for processing. In terms of server layout, MEC servers are located a short distance from the end devices. More emerging applications can use MEC to process tasks [
19].
Hao et al. [
20] proposed a MURL algorithm to minimize long-term average latency. Wu et al. [
21] proposed a DAR-AC algorithm to optimize computational performance and energy consumption. Zhao et al. [
22] proposed a branch-bounding method to minimize energy consumption. Zhuang et al. [
23] proposed an OTDDPG algorithm to optimize energy consumption and delay. Xiao et al. [
24] performed a modeling transformation of collaborative offloading into a MINLP problem formulated to minimize execution delay. Li et al. [
25] successfully achieved more flexible energy savings in MEC environments by quantifying the correlation between statistical quality of service guarantees and task-offloading policies. Kim et al. [
26] proposed a migration optimization scheme for user mobility by using integer linear programming and heuristic solution algorithms aimed at minimizing service provider costs and user latency. Lim et al. [
27] considered optimizing latency, energy consumption, and the packet loss rate with DRL-OS based on the D3QN algorithm. Cao et al. [
28] proposed the NSGA-II algorithm to solve the problem of minimizing the overall latency and energy consumption, taking into account time-varying networks and limited computational resources in realistic scenarios. The above work provides important reference criteria for the optimization objectives of task-offloading strategies to cope with realistic task offloading in different scenarios.
Wang et al. [
29] investigated server failures, where mobility and power constraints caused tasks running on them to fail as well, and solved the problem by designing a new model. Jiang et al. [
30] considered the case of limited edge server computational power and found a task-offloading strategy to effectively safeguard the QoE of end-users under the condition of limited edge server computational power. The above work has led us to recognize the need to consider the limitations of edge servers, which can cause task execution to fail if the server fails.
As the complexity of offloading tasks gradually increases, deep reinforcement learning (DRL) can be utilized to manage the burgeoning application tasks. In different scenarios, it can be optimized by learning strategies to find an excellent task-offloading strategy. Qiu et al. [
31] proposed a DC-DRL algorithm to solve the problem, which can be trained in two ways: distributed and centralized training. Zou et al. [
32] proposed a dual-offloading framework for realistic application scenarios by designing simulation experiments to simulate realistic task-offloading scenarios for dynamic regional resource scheduling. This is solved using an asynchronous advantageous participant–critic (A3C) algorithm to reduce energy and time costs. Alam et al. [
33] proposed an autonomic management framework by considering the challenges surrounding mobility, heterogeneity, and the geographic distribution of mobile devices, which were eventually solved using DRL. Ren et al. [
34] coordinated the offloading of software through multiple DRL agents on multiple edge nodes, which can deal with dynamic environments and enable the cost of task offloading to be optimized. Cao et al. [
35] used deep reinforcement learning for optimization and a modified algorithm of DDPG for solving.
The aforementioned literature used DRL to solve the task-offloading problem and investigated various optimization objectives. The long-term optimization problem is crucial when solving the task-offloading problem. Some studies have already started to focus on long-term optimization. Some researchers have formulated the problem as an MDP and proposed algorithms to solve it [
36,
37]. In addition, some studies performed the solution by combining Lyapunov optimization with deep reinforcement learning [
38,
39]. However, most studies do not consider the design of representing long-term constraints by constructing multiple queues when using DRL methods to solve the task-offloading problem.
Unlike previous studies, this paper builds on existing research and investigates the problem of the dynamic task-offloading strategy with long-term constraints for multi-user MEC dynamic scenarios. In a scenario with a dynamically changing system environment, the performance constraint—where the long-term system energy consumption is stable and does not exceed the long-term MEC energy budget—is considered, which is described as an optimization problem with long-term constraints. A task-offloading strategy with long-term constraints is proposed to co-optimize with the optimization objective by constructing multiple queues to represent the long-term constraint states. The optimization problem with long-term constrained task offloading is constructed as a MINLP problem. The MINLP problem is decoupled by using Lyapunov optimization. On this basis, the problem is described as a MDP. A LMADDPG algorithm is proposed for the solution. The algorithm represents the long-term constraints in the form of multiple queues and makes use of Lyapunov for optimization, which ensures that the long-term constraints find an optimal task-offloading policy to ensure that the task-offloading cost is minimized.
3. System Model
3.1. System Overview
As
Figure 1 shows, in this paper, a scenario with multiple edge servers (ESs) and multiple types of user equipment (UE) is considered, and each user has its energy consumption queue and MEC energy queue. Each edge server has limited resources, and each user needs to execute multiple tasks, which are processed by task offloading, where an edge server is selected to offload part of the tasks and leave some to be executed locally.
Let denote the set of user devices, for each user device , computational tasks will be executed at each time slot. And these tasks need to be handed off to the edge server by way of offloading, or they can be executed on local devices. The task queue has a queuing form, which needs to queue until the end of the previous tasks before the subsequent tasks can be executed, and the latest processing end time of the whole task is its execution time. The set of edge servers is , . In a continuous time, the edge server assists the user device in computing for a duration, T, set to a number of consecutive time slots, which we define as time slots , where is considered a time slot.
The aim of this paper is to consider the optimization of task-offloading costs under the constraints of guaranteeing long-term task energy stability, not exceeding the MEC energy budget. The optimal user QoE can be achieved by determining the best offloading strategy for each time slot. Therefore, the impact of task offloading to the ES for execution or local execution on the QoE needs to be considered.
3.2. Task Transfer and Computational Model
It is assumed that the wireless access system of the edge servers uses orthogonal frequency division multiple access (OFDMA). The network deployment uses the same common bandwidth B. indicates the uplink transmission rate and indicates the downlink transmission rate. The offloading method uses partial offloading, where the user device selects only one edge server at a time for offloading. represents the local computational capacity for the ith UE (user equipment), and represents the computational capacity for the jth ES. represents the offload ratio of user i for the jth edge server, and represents the task data size. represents the CPU cycles required to execute the task, , where represents the number of CPU cycles required to process 1 bit of data. Task processing methods include local execution and offloading to ES for execution.
- (1)
Local execution
The local computational delay
is as follows:
The local energy consumption
is as follows:
where
denotes the energy consumption coefficient.
- (2)
Offloading execution
The transmission delay
is as follows:
Using Shannon’s formula for uplink and downlink, respectively,
and
are denoted as follows:
where
represent the transmission power of the UE and ES, respectively.
are the channel gains of the uplink and downlink, respectively, and
is the noise power.
The edge server computational delay
is as follows:
The edge offloading delay
is as follows:
The transmission energy consumption
is as follows:
where
and
represent the transmission power of the UE and ES, respectively.
The edge server computing energy consumption
is as follows:
The edge server energy consumption
is as follows:
3.3. Queue Model
3.3.1. Energy Queue
To ensure long-term system energy consumption stabilization, we introduce
N energy consumption queues
for each UE. We set
. The queue is dynamically updated as follows:
where
is the energy consumption of the ith UE, and
is the energy consumption threshold of the ith UE. When the energy consumption queue does not show an infinite increasing trend, i.e., the UE’s energy consumption
is less than or equal to the energy consumption threshold
can be satisfied.
3.3.2. MEC Energy Queue
To ensure that the MEC energy budget is not exceeded when offloading for long-term tasks, we introduce
N MEC energy queues
. Each UE has a MEC energy queue, and the UEs incur different MEC energy consumption values under different offloading policies. We set
. The queue is dynamically updated as follows:
where
is the energy consumed on the edge server and
is the average energy budget. When the
ith user uses too much energy at the edge server, the MEC energy queue at time slot
will expand and, thus, the queue can be used to measure the energy constraint of the MEC.
4. Problem Description and Transformation
The task-offloading cost is defined as
, which is the weighted sum of task latency and user energy consumption, as follows:
where
denote the respective corresponding weights.
The aim of this paper is to consider the optimization of task-offloading costs under the constraints of guaranteeing long-term task energy stability, not exceeding the MEC energy budget. The optimal user QoE can be achieved by determining the best offloading strategy for each time slot. Task-offloading optimization with long-term constraints needs to be considered. Thus, the problem form is expressed as follows:
where
denotes the energy constraint of the local energy queue and
denotes the energy constraint of the MEC energy queue.
Making optimal task-offloading decisions under a long-term constraint is very difficult due to environment and task unknowns.
Lyapunov Optimization
The MINLP optimization problem is decoupled into a single time-slot deterministic problem through Lyapunov optimization, as the optimization objective, as well as the constraints of
, have both long-term optimizations. In order to have control over the system energy queue and the MEC energy queue, we define
, where
, and
,
. According to the Lyapunov optimization theory, the Lyapunov function
, is denoted as follows:
The change in value will be referred to as the Lyapunov drift function
, denoted as follows:
Due to ; therefore, can be derived from .
Theorem 1. Given the dynamic relationship of the queues in the system, when , and there exist constants , we can obtain an upper bound on the Lyapunov drift as follows: Proof of Theorem 1. Using
, for the energy consumption queue, squaring Equation (
11), we have the following:
The drift function is as follows:
This can be obtained by substituting Equation (
18) into Equation (
19), as follows:
where
is a constant,
, holds for all
since all
.
For the MEC energy queue, we square Equation (
12) as follows:
The drift function of the MEC energy queue is calculated as follows:
This can be obtained by substituting Equation (
21) into Equation (
22):
where
is a constant,
, holds for all
since all
.
Summarizing Equations (
20) and (
23) yields the following:
where
. □
This is optimized to ensure long-term task energy consumption stability without exceeding the constraints of the MEC energy budget. This is achieved using the Lyapunov drift plus penalty, minimizing its upper bound. The expression is given as follows:
where
V is a hyperparameter and
; the first term is the Lyapunov drift function containing the energy consumption queue and the MEC energy queue, and the second term
is the penalty term. The optimal QoE is found by minimizing the upper bound. According to Theorem 1, Equation (
24) can be obtained by substituting into Equation (25):
Therefore, the long-term optimization problem
is decoupled into a single time-slot MINLP subproblem, transforming the
problem into the following:
When all problems are solved, the problem can be solved. Decisions within the current time slot are based on the current state without regard to the historical state.
5. Deep Reinforcement Learning-Based Solutions
5.1. Markov Decision Process
In the environment designed in this paper, the UE is viewed as the DRL-Agent. In the face of dynamically changing MEC environments, it is often difficult to go to the state transfer probability matrix P. Thus, it is not possible to rely on the full quaternion , which contains state, action, reward, and state transfer probability, to characterize the MDP. Therefore, in this paper, we turn to the use of the ternary , which contains state, action, and reward, without considering state transfer probability.
(1) State space: Reinforcement learning involves the use of one’s own powerful learning ability to improve one’s decision-making by learning the information stored in the experienced replay buffer, which updates the strategy based on its improved decision-making. Therefore, defining an appropriate state space is crucial for overall performance improvement. In defining the state space, the complete environment needs to be added to it. For user device
i, define the state space as follows:
where
represent the computational resources of UE and ES, respectively.
(2) Action space: When the DRL-Agent acquires state
, it selects an action from the action space that determines the target server
and the offload ratio
for offloading tasks. This strategy aims to achieve a balanced allocation of tasks by processing some of them locally and offloading others to edge servers. For the user device
i, define the action as follows:
(3) Reward function: The aim of this paper is to consider the optimization of task-offloading costs under the constraints of guaranteeing long-term task energy stability, not exceeding the MEC energy budget. However, the aim of reinforcement learning is to obtain the highest reward value, and the task-offloading cost is inversely proportional to the reward value. Therefore, the reward function for time slot
t is as follows:
5.2. DRL-Based Algorithm Design
5.2.1. Deep Reinforcement Learning Algorithms
Traditional reinforcement learning algorithms typically use a Q-value table to select out the best action. However, as the complexity of the problem changes, it eventually makes the size of the Q-value table explode, resulting in a significant increase in storage and computational cost and, thus, is no longer advantageous in high-dimensional spaces. However, Deep Q-Network (DQN) introduces a neural network to approximate the Q-function, thus avoiding the need to directly store Q-values and being able to handle more complex problems. However, a single Q-learning or DQN cannot be used to implement complex interactions between multiple ‘intelligences’. In this case, the use of the multi-agent deep deterministic policy gradient (MADDPG) algorithm offers significant advantages. The MADDPG algorithm facilitates co-learning among ‘intelligences’ and enhances overall performance through policy sharing, making it more effective in addressing multi-intelligence collaborative decision-making problems.
The MADDPG algorithm achieves better performance by utilizing deep learning and policy gradient methods that allow multiple ‘intelligences’ to learn and make decisions collaboratively in the environment. Its distributed learning feature makes the algorithm scalable and adaptable to large-scale multi-intelligent body systems. The algorithm uses the structure of the two networks joined so that the algorithm can be used in a dynamically changing environment, and can autonomously learn an advantageous strategy, through the learning of the strategy constantly updated and adjusted, in the face of dynamic tasks and different scenarios can be reasonably adjusted to the optimal strategy. In addition, the algorithm can further optimize and adjust the optimal strategy through the interaction between multiple ‘intelligences’, so that each intelligence can fully improve its own decision-making level.
5.2.2. Actor–Critic Network
The actor–network will maximize the reward value accumulated over time by receiving states as inputs and then outputting actions, and it learns the best action to choose in each state by continuously adjusting the network parameters. This network contains an evaluation network , and a target network , where denote the respective parameters of the two networks. The critic–network is used to evaluate the action’s output by the actor–network and provide feedback to improve the strategy. The network receives states and actions as its inputs and outputs the payoff values of the selected actions. The critic–network then provides feedback to the actor–network by accurately estimating these values so that the actor–network can use the feedback to optimize its strategy. The network also includes an evaluation network and a target network , where denote the parameters of each of the two networks.The updating of the network parameters between the two networks is done by gradient descent.
5.2.3. LMADDPG Algorithm Design
Each user device is individually defined as an intelligence, and each intelligence has two queues each, i.e., the system energy queue and the MEC energy queue, which are used to represent the long-term constraints. The use of the actor–critic network in this algorithm is used for learning to optimize the task-offloading decision. In order to reduce the data relevance of the input experience during the training process and to improve the data utilization, the LMADDPG algorithm employs an experience replay mechanism, which improves the performance of the algorithm by creating an experience replay buffer
D. During training, samples are randomly selected from the experience replay buffer
D. Each data sample includes information about the state, action, reward, and next state. It is assumed that
Z data, each denoted as
, are randomly drawn from
D for each training session.The corresponding loss values are computed using these randomly drawn data, and the computed loss values are used to update the parameters of the network. The critic–network at each intelligence interacts with each other through the ‘intelligences’ to update the network parameters by minimizing the computed loss function. Define the objective value as follows:
where
is the discount factor.
The loss function its expression is as follows:
To update the actor–network using the policy gradient, the actor–network is used to compute the action in the current state, and then the gradient of the action value function computed by the critic–network is used to update the actor–network parameters with the following formula:
Use the soft update strategy to update the target actor–network and target critic–network parameters:
The reward function is optimized using Lyapunov optimization based on the multiple queues created. Each intelligent body obtains the reward value by executing an action after acquiring the environment information and accumulates experience data using the experience playback mechanism. Each intelligent body updates its policy network with the accumulated data, using a deep deterministic policy gradient approach to optimize its policy to maximize the expected cumulative reward. The queue information is updated at each training time slot. When updating the policy network, the intelligence also uses the target policy network to stabilize the training process by updating the parameters of the target network through a soft update approach. During the training process, the ‘intelligences’ learn from each other and optimize their respective strategies through collaboration and competition to achieve the global optimal solution. In this way, the LMADDPG algorithm enables multiple ‘intelligences’ to learn to work together effectively in a collaborative environment to achieve finding an optimal task-offloading decision under the performance constraint of stable long-term system energy consumption and not exceeding the long-term MEC energy budget. The overall execution process is shown in Algorithm 1.
| Algorithm 1 LMADDPG task-offloading algorithm |
- 1:
Initialization: Initialize the parameters of each agent’s actor and critic evaluations and target networks. Initialize the replay buffer D, learning rate, the discount factor, the maximum learning epoch, steps. - 2:
for
to
M
do - 3:
Initialize a random process N for action exploration - 4:
Initialize , - 5:
for to T do - 6:
For each agent i, select action , based on the current observed state: - 7:
Execute actions , obtain the reward based on Lyapunov drift-plus-penalty function, and the subsequent new state - 8:
For each agent i, input the new state to agent i - 9:
Store the agent’s information into the experience replay buffer D as a tuple of four elements - 10:
- 11:
for Each agent to N do - 12:
Sample a random mini-batch of Z samples from the replay buffer D - 13:
- 14:
Update the critic–network according to the following loss function: - 15:
Update the actor–network using the sampled gradient based on Equation ( 36) - 16:
Update using Equation ( 11) - 17:
Update using Equation ( 12) - 18:
end for - 19:
Update target network parameters for each agent with: - 20:
end for - 21:
end for
|
5.2.4. Algorithm Complexity Analysis
In the LMADDPG algorithm, each intelligent body uses the actor–critic network architecture. The number of ‘intelligences’ is N. denotes the number of network layers of actor–network and denotes the number of network layers of critic–network. denotes the dimensions of inputs and outputs of the layer of actor–network and denotes the dimensions of inputs and outputs of the layer respectively. Therefore, the algorithm complexity of LMADDPG can be calculated as .
7. Conclusions
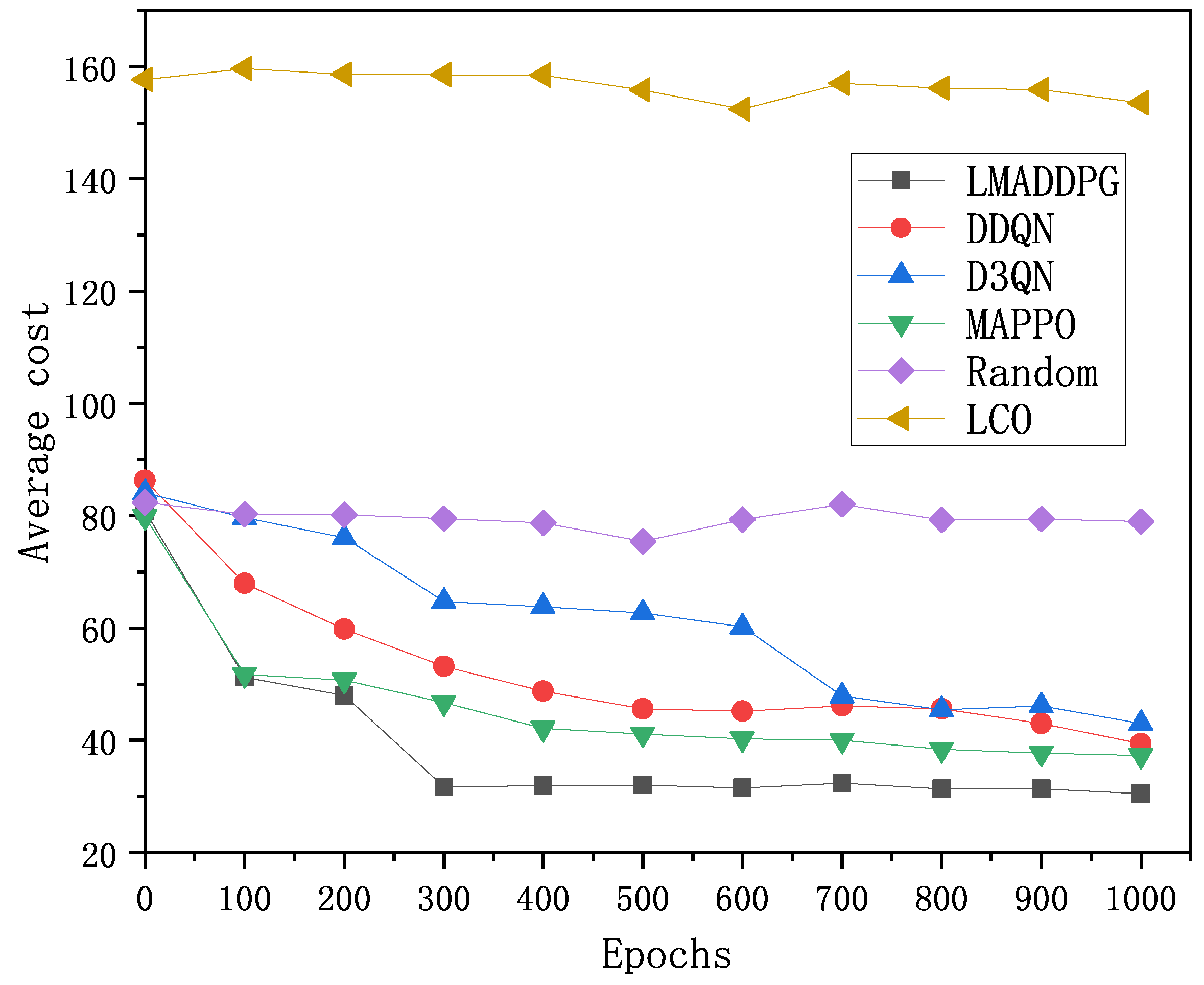
In this paper, we propose a multi-queue-based real-time task-offloading strategy for deep reinforcement learning. We establish multiple queues to represent the long-term constraint states and co-optimize with the optimization objective. The optimization problem with long-term constraints is decoupled into subproblems to be solved in a single time slot using Lyapunov optimization, which describes the problem as an MDP. We propose a DRL-based LMADDPG algorithm to solve the task-offloading decision problem. During the training process, all the ‘intelligences’ share a unified strategy network in order to utilize the experience of all the ‘intelligences’ during the training process. However, in the execution phase, each intelligence independently executes its own policy to interact with the environment. Finally, an optimal task-offloading strategy is found, which can effectively maintain long-term system energy consumption and MEC energy stability. The simulation results prove the effectiveness of the improved algorithm and it is more advantageous in comparison with other baseline algorithms.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}