LangProp: A code optimization framework using Large Language Models applied to driving
Shu Ishida
Summary: LangProp is a framework that optimizes code with an LLM (Large Language Model) according to a training objective. Code candidates are evaluated on a training dataset, re-ranked by their performances, and updated with an LLM. We applied LangProp to optimize code for a self-driving agent, which outperformed many human-written driving systems in the CARLA benchmark.
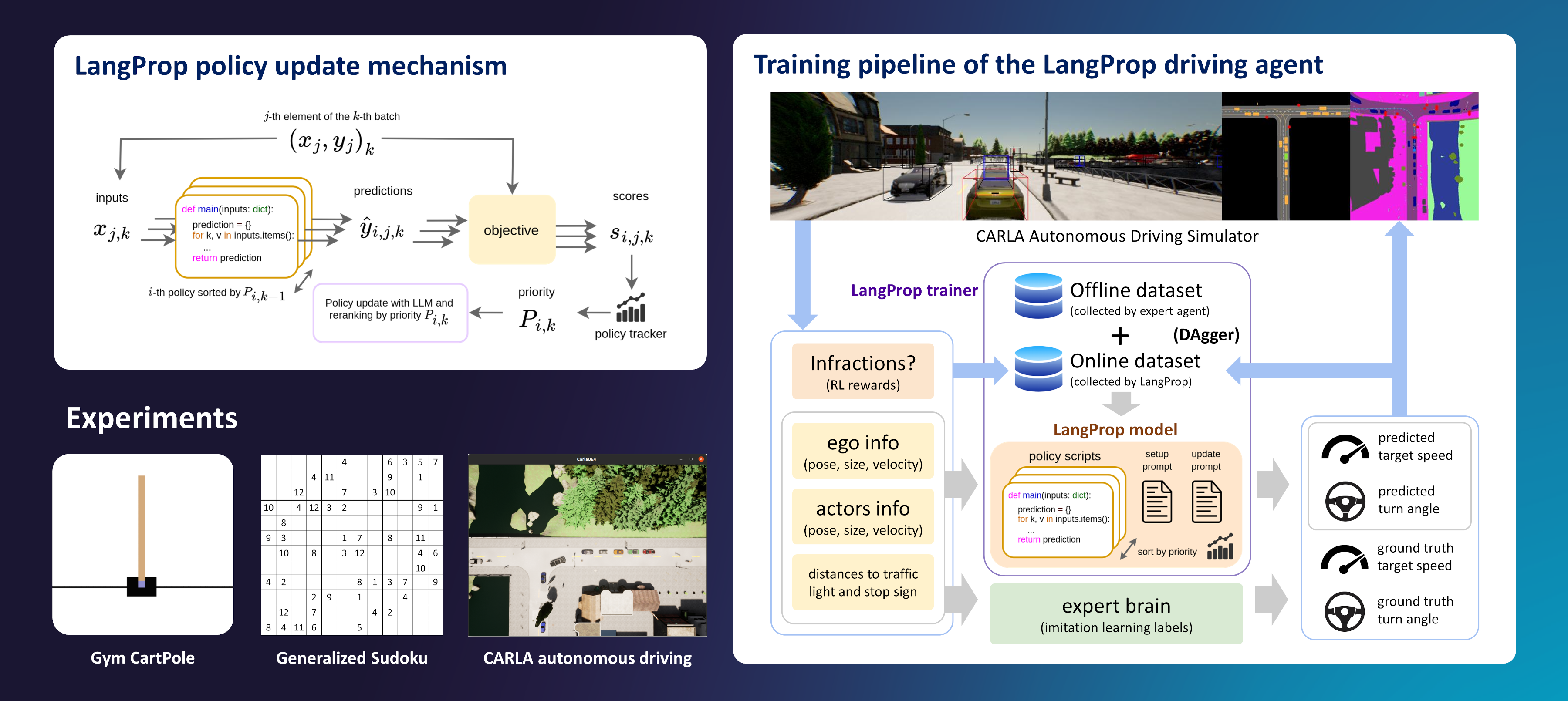
Can we use ChatGPT to drive a car?
You have probably used ChatGPT to write your emails, summarize documents, find out information, or help you debug your code. But can we take a step further and make ChatGPT drive a car?
This was the question we wanted to answer when I started my work placement at Wayve in March last year. Wayve is an autonomous driving startup in London, applying end-to-end learning to the challenging problem of urban driving. At the time, the company was just about to launch its LLM research team, which has since successfully developed LINGO-1 and LINGO-2. AutoGPT had just come out, and Voyager had not come out yet. And yet, the disruption caused by LLMs was palpable. The question was, how can we use this new technology to driving, a domain where language isn’t the main modality?
In this blog post, I would like to give an overview of our paper LangProp, which we presented at the LLM Agents workshop at ICLR (the International Conference on Learning Representations) in May 2024.
Shu Ishida, 29 June 2024
SNeS: Learning Probably Symmetric Neural Surfaces from Incomplete Data
Dylan Campbell
Summary: SNeS is a neural network that reconstructs a mostly-symmetric object using a set of posed images taken from a single side, and renders convincing novel view images of the unseen side.
The Problem
You pass a parked car while driving. What does the side you didn’t see look like? Presumably not a phantasmagoria of impressionist textures and melted geometry, like a mashup of Monet and Dali. Yet this is what state-of-the-art neural rendering models like NeRF [1] and NeuS [2] predict, at best. If a child can accurately visualise the unseen side of a car, how can we get our models to do the same?

Dylan Campbell, 18 July 2022
CALVIN — a neural network that can learn to plan and navigate unknown environments
Shu Ishida
Summary: CALVIN is a neural network that can plan, explore and navigate in novel 3D environments. It learns tasks such as solving mazes, just by learning from expert demonstrations. Our work builds upon Value Iteration Networks (VIN) [1], a type of recurrent convolutional neural network that builds plans dynamically. While VINs work well in fully-known environments, CALVIN can work even in unknown environments, where the agent has to explore the environment in order to find a target.
The Problem
The problem we address is visual navigation from demonstrations. A robotic agent must learn how to navigate, given a fixed amount of expert trajectories of RGB-D images and the actions taken. While it is easy to plan with a top-down map that defines what are obstacles and targets, it is more challenging if the agent has to learn the nature of obstacles and targets from the RGB-D images.

Another important aspect of navigation is exploration. Our agent starts without any knowledge about the new environment, so it has to build a map of the environment as it navigates, and learn to explore areas that are most likely to lead to the target.

For the agent to be able to navigate in environments it hasn’t been trained on, it has to learn some general knowledge applicable across all environments. In particular, we focus on learning a shared transition model and reward model that best explain expert demonstrations, which can then be applied to new setups.

Shu Ishida, 2 June 2022
Unsupervised Learning of Probably Symmetric Deformable 3D Objects from Images in the Wild
Shangzhe Wu & Christian Rupprecht & Andrea Vedaldi
Summary: We propose a method to learn weakly symmetric deformable 3D object categories from raw single-view images, without ground-truth 3D, multiple views, 2D/3D keypoints, prior shape models or any other supervision.
This work has received the CVPR 2020 Best Paper Award.
[Paper · Project Page · Code]
Demo
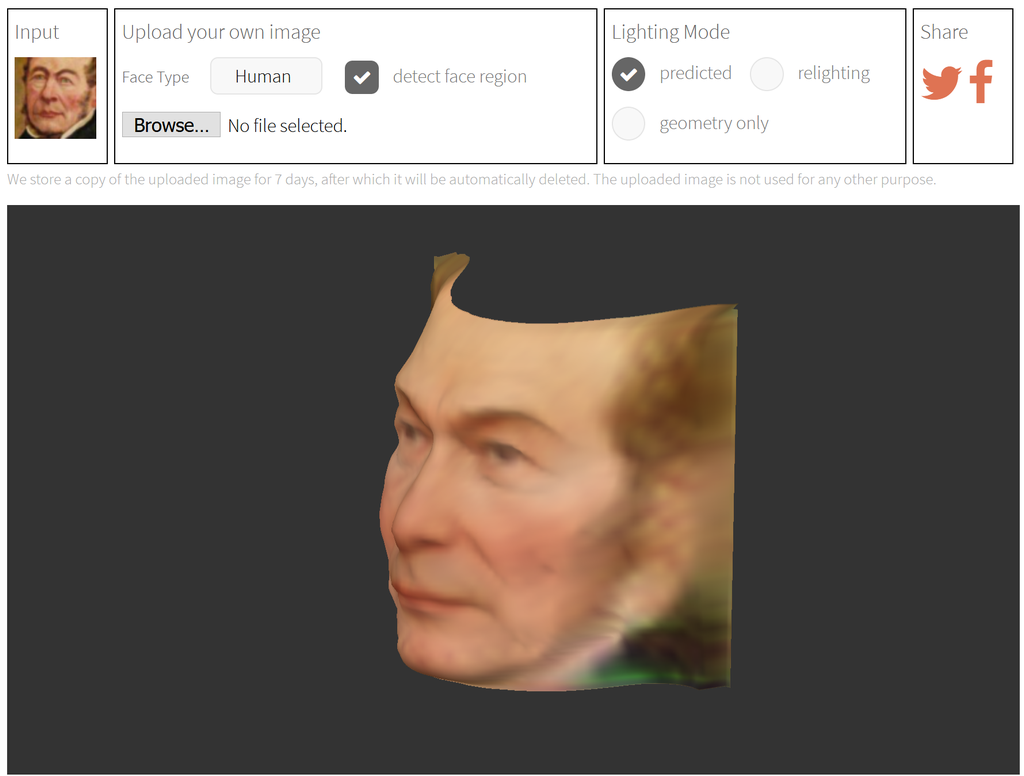
Shangzhe Wu & Christian Rupprecht & Andrea Vedaldi, 26 February 2020
Self-Labelling via simultaneous clustering and representation learning
Yuki M Asano & Christian Rupprecht
Summary: We have developed a self-supervised learning formulation that simultaneously learns feature representations and useful dataset labels by optimizing the common cross-entropy loss for features and labels, while maximizing information. This method can be used to generate labels for an any image dataset.
Learning from unlabelled data can dramatically reduce the cost of deploying algorithms to new applications, thus amplifying the impact of machine learning in the real world. Self-supervision is an increasingly popular framework for learning without labels. The idea is to define pretext learning tasks can be constructed from raw data alone, but that still result in neural networks that transfer well to useful applications. Much of the research in self-supervision has focused on designing new pre-text tasks. However, given supervised data such as ImageNet, the standard classification objective of minimizing the cross-entropy loss still results in better pre-training than any of such methods (for a certain amount of data and model complexity). This suggest that the task of classification may be sufficient for pre-training networks, provided that suitable data labels are available. In this paper, we develop a method to obtain the labels automatically by designing a self-labelling algorithm.
Yuki M Asano & Christian Rupprecht, 14 February 2020
ShapeStacks: Giving Robots a Physical Intuition
Oliver Groth
Summary: Physical intuition is a human super-power. It enables our superior object manipulation skills which we apply in countless scenarios - from playing with toys to using tools. The ShapeStacks project aims to equip robots with a similar intuition by providing a virtual playground in which robots can acquire physical experiences.

Most of us have probably played a game of Jenga before, dealt with stacks of dirty dishes in their kitchen or used a hammer to hit a nail into a piece of wood. The inherent complexity of these simple everyday tasks becomes immediately clear when we try to build a machine which is capable of doing the same thing. Robots are essentially computers integrating sensing, locomotion and manipulation. And like all computers, they are first and foremost fast and exact calculators. Yet, despite their number-crunching powers (which allows them to perform complex physical and geometric calculations in split-seconds) they still largely struggle with basic object manipulation. Humans on the other hand, possess only a tiny fraction of the arithmetic exactitude of a computer, but are still capable of “computing” accurate movements of their limbs (e.g. swinging a hammer on a nail’s head) and estimates of the physical states of the objects around them (e.g. judging the stability of a stack of dishes).
Oliver Groth, 15 January 2019
VGG Image Annotator
Abhishek Dutta
Summary: VGG Image Annotator (VIA) is a manual image annotation tool which is so easy to use that you can be up and running with this application in less than a minute. VIA runs in most modern web browsers and does not require any installations. The whole application is so small -- less than 400 KB -- that it can be easily shared over email. This image annotation tool is not only useful for Computer Vision research but also is being used in other disciplines like Humanities, History, Zoology, etc and has been used more than 230K times since it was released in April 2017. This blog post highlights the main features of VIA, discusses its impact and finally describes the open source ecosystem that thrives around the VIA project.
Introduction
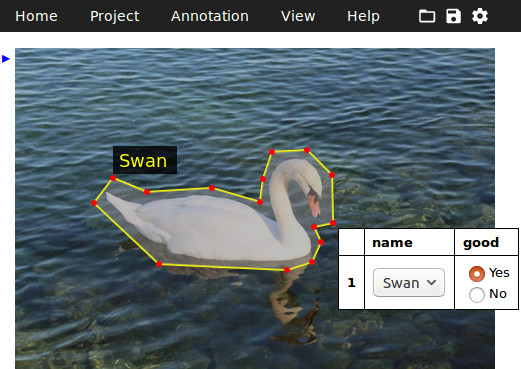 An example of manual image annotation done using VGG Image Annotator (VIA)
An example of manual image annotation done using VGG Image Annotator (VIA)
Manual image annotation is the process of defining regions in an image and describing those regions using text metadata. These regions can have arbitrary shape and is mostly drawn by human operators. We have developed an open source software, called VGG Image Annotator (VIA), that allows manual annotation of images. One of the most important features of VIA is that it does not require any installations and a new user can quickly get started with using this software. Furthermore, since this is an open source project, users can – and many have chosen to do so – update the source code to suit their specific needs. Here is a list of some important features of VIA:
Abhishek Dutta, 17 October 2018
Comparator Networks
Weidi Xie
Summary: We propose a deep neural network (Comparator Networks) for set-wise verification, e.g. to decide if two sets of images are of the same category or not.
Motivation
Verification is often central for lots of real-world applications, e.g. biometrics, security, retrieval, and tracking. As a generalization of conventional image-to-image verification, here we consider the set-to-set case, where each set may contain an arbitrary number of face images, e.g. individual images, or frame sequences in a video. To aggregate information from multiple images, the most straightforward way would be to use the mean to represent the whole set.

However, this procedure of first generating a single vector per face, and then simply averaging them, misses out on potentially using more available information in four ways:
Weidi Xie, 5 October 2018
Seeing Voices and Hearing Faces
Arsha Nagrani
Summary: We explore the relationship between audio and video for cross-modal learning, by focusing on videos of people speaking.
 McClane talking to Powell on the phone in 'DieHard'
McClane talking to Powell on the phone in 'DieHard'
How similar are human faces and voices? Can you recognise someone’s face if you have only heard their voice? Or recognise their voice if you have only seen their face? As humans, we may ‘see voices’ or ‘hear faces’ by forming mental pictures of what a person looks like after only hearing their voice, or vice versa.
If you’ve seen the film “Die Hard”, you may remember the scene where John McClane (Bruce Willis) emerges from the building towards the end of the film and is instantly able to recognise the cop (Sgt. Al Powell) who he has only spoken to by radio throughout the film, but never seen.
While you might believe this intuitively, human psychologists such as Kamachi et al. have actually studied this phenomenon by asking participants to perform a binary forced matching task. They were asked to listen to a human voice and then select a matching face of the same identity from two face images presented later.
Arsha Nagrani, 28 September 2018
Mapping environments with deep networks
João F. Henriques
Summary: We teach a deep neural network to create an internal map of its environment from video, and to use it for self-localization. We tested it on both toy/game data, and images from a real robot. There are some interesting technical bits on how this is achieved too.
Hi, and welcome to the first installment of the VGG blog! In this space we’ll share some of the (hopefully) exciting discoveries that we make in our lab, and things that we find interesting at the intersection of computer vision and deep learning. Tune in from time to time (or use our RSS feed) for a new dose of casual research discussions.
My name is João, and I’ve been working on teaching neural networks to perform simultaneous localization and mapping (SLAM) from videos. On the surface this may seem relatively niche – why build maps? And how is this different from the well-established, classical SLAM systems? The reason is that I see mapping as the first step towards much bigger things.

In computer vision we’re used to making predictions from images or videos – detections, segmentations, even depth. But if we want to eventually have autonomous agents moving around and doing useful things for us, they’re going to need a stable model of the world, one that goes beyond the current view. One example of this is object permanence – knowing that an object continues to exist and may be in the same place even when it is out of view. That “place” should be relative to a rock-solid World-centric origin, instead of an ever-changing Camera-centric origin. This sort of knowledge allows you to make larger and more complicated plans than is possible when considering only the current view, such as remembering that you have the ingredients for a delicious sandwich in the kitchen and planning what to do with them.