Compression: Author: Paul Penfield, Jr. 2004 Massachusetts Institute of Technology Url: Start: Back: Next
Compression: Author: Paul Penfield, Jr. 2004 Massachusetts Institute of Technology Url: Start: Back: Next
Download as pdf or txt
You might also like
- NG - Argument Reduction For Huge Arguments: Good To The Last BitDocument8 pagesNG - Argument Reduction For Huge Arguments: Good To The Last BitDerek O'ConnorNo ratings yet
- Tornado Codes and Luby Transform Codes PDFDocument12 pagesTornado Codes and Luby Transform Codes PDFpathmakerpkNo ratings yet
- Convolution CodesDocument14 pagesConvolution CodeskrishnaNo ratings yet
- Matlab PDFDocument2 pagesMatlab PDFpathmakerpkNo ratings yet
- Channel Coding: Version 2 ECE IIT, KharagpurDocument8 pagesChannel Coding: Version 2 ECE IIT, KharagpurHarshaNo ratings yet
- OFDM Simulation EE810Document18 pagesOFDM Simulation EE810Ashique Mahmood100% (1)
- Jpeg PDFDocument9 pagesJpeg PDFAvinashKumarNo ratings yet
- HasanDocument8 pagesHasansumeiranNo ratings yet
- Software-Defined Radio Lab 2: Data Modulation and TransmissionDocument8 pagesSoftware-Defined Radio Lab 2: Data Modulation and TransmissionpaulCGNo ratings yet
- VLSI ImageCompression EncryptionReadDocument5 pagesVLSI ImageCompression EncryptionReadqsashutoshNo ratings yet
- Paper - 2011 - A Simplified Successive-Cancellation Decoder For Polar Codes - Amin Alamdar-YazdiDocument3 pagesPaper - 2011 - A Simplified Successive-Cancellation Decoder For Polar Codes - Amin Alamdar-Yazdirobertmotaoliveira73No ratings yet
- Chapter 8-b Lossy Compression AlgorithmsDocument18 pagesChapter 8-b Lossy Compression AlgorithmsfarshoukhNo ratings yet
- Codes Decoding: Design and Analysis: Feng Lu Chuan Heng Foh, Jianfei Cai and Liang-Tien ChiaDocument5 pagesCodes Decoding: Design and Analysis: Feng Lu Chuan Heng Foh, Jianfei Cai and Liang-Tien ChiaViet Tuan NguyenNo ratings yet
- Chapter 8 MmediaDocument18 pagesChapter 8 MmediaAbraham AbaynehNo ratings yet
- MIT6 050JS08 Chapter3Document16 pagesMIT6 050JS08 Chapter3Phong ĐinhNo ratings yet
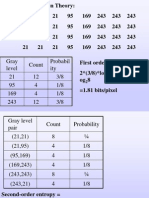
- Gray Level Count Probabil Ity 21 12 3/8 95 4 1/8 169 4 1/8 243 12 3/8Document51 pagesGray Level Count Probabil Ity 21 12 3/8 95 4 1/8 169 4 1/8 243 12 3/8kamnakhannaNo ratings yet
- LT Erasure CodesDocument10 pagesLT Erasure CodesCosmo SeedsNo ratings yet
- Img CompressionDocument15 pagesImg CompressionchinthaladhanalaxmiNo ratings yet
- LDPC - Low Density Parity Check CodesDocument6 pagesLDPC - Low Density Parity Check CodespandyakaviNo ratings yet
- 3.multimedia Compression AlgorithmsDocument23 pages3.multimedia Compression Algorithmsaishu sillNo ratings yet
- An Introduction To JPEG Compression Using Matlab: Arno Swart 28th October 2003Document5 pagesAn Introduction To JPEG Compression Using Matlab: Arno Swart 28th October 2003Arini PartiwiNo ratings yet
- DSP Lab ManualDocument22 pagesDSP Lab ManualAishwarya GNo ratings yet
- New SlideDocument41 pagesNew SlideShekhar chanderNo ratings yet
- Ee4140 Comp Assg1 Sep 2024 v2Document2 pagesEe4140 Comp Assg1 Sep 2024 v2Fardeen RazifNo ratings yet
- Development of Wimax Physical Layer Building BlocksDocument5 pagesDevelopment of Wimax Physical Layer Building BlocksSandeep Kaur BhullarNo ratings yet
- Rawan Ashraf 2019 - 13921 Comm. Lab5Document17 pagesRawan Ashraf 2019 - 13921 Comm. Lab5Rawan Ashraf Mohamed SolimanNo ratings yet
- Source and Channel Encoder and Decoder Modeling: S-72.333 Postgraduate Course in Radiocommunications Fall 2000Document17 pagesSource and Channel Encoder and Decoder Modeling: S-72.333 Postgraduate Course in Radiocommunications Fall 2000Adarsh AnchiNo ratings yet
- Illuminating The Structure Code and Decoder Parallel Concatenated Recursive Systematic CodesDocument6 pagesIlluminating The Structure Code and Decoder Parallel Concatenated Recursive Systematic Codessinne4No ratings yet
- Modulation Doping For Iterative Demapping of Bit-Interleaved Coded ModulationDocument3 pagesModulation Doping For Iterative Demapping of Bit-Interleaved Coded ModulationabdulsahibNo ratings yet
- UWBin Fading ChannelsDocument10 pagesUWBin Fading Channelsneek4uNo ratings yet
- Comparison of Convolutional Codes With Block CodesDocument5 pagesComparison of Convolutional Codes With Block CodesEminent AymeeNo ratings yet
- Sequential Decoding by Stack AlgorithmDocument9 pagesSequential Decoding by Stack AlgorithmRam Chandram100% (1)
- Convolutional CodeDocument15 pagesConvolutional CodeDhivya LakshmiNo ratings yet
- A L D I S HW/SW C - D: Shun-Wen ChengDocument6 pagesA L D I S HW/SW C - D: Shun-Wen Chengmorvarid7980No ratings yet
- System Design Considerations For The Use Turbo Codes in Aeronautical Satellite CommuncationsDocument8 pagesSystem Design Considerations For The Use Turbo Codes in Aeronautical Satellite CommuncationsanchisanNo ratings yet
- Spreading Codes in Cdma Detection: Eastern Mediterranean University July 2003Document24 pagesSpreading Codes in Cdma Detection: Eastern Mediterranean University July 2003Alex BadeaNo ratings yet
- Performance Evaluation For Convolutional Codes Using Viterbi DecodingDocument6 pagesPerformance Evaluation For Convolutional Codes Using Viterbi Decodingbluemoon1172No ratings yet
- Convolution Codes: 1.0 PrologueDocument26 pagesConvolution Codes: 1.0 PrologueGourgobinda Satyabrata AcharyaNo ratings yet
- Error Control Coding3Document24 pagesError Control Coding3DuongMinhSOnNo ratings yet
- Viterbi DecodingDocument4 pagesViterbi DecodingGaurav NavalNo ratings yet
- Efficient Implementation of Low Power 2-D DCT ArchitectureDocument6 pagesEfficient Implementation of Low Power 2-D DCT ArchitectureIJMERNo ratings yet
- 3D Turbo CodesDocument13 pages3D Turbo Codestvrpolicemobilemissing0No ratings yet
- JPEGDocument29 pagesJPEGRakesh InaniNo ratings yet
- Convolutional Codes Turbo Codes LDPC CodesDocument49 pagesConvolutional Codes Turbo Codes LDPC CodesveerutheprinceNo ratings yet
- Low-Complexity Low-Latency Architecture For Identical of Data Encoded With Hard Systematic Error-Correcting CodesDocument104 pagesLow-Complexity Low-Latency Architecture For Identical of Data Encoded With Hard Systematic Error-Correcting CodesJaya SwaroopNo ratings yet
- DSP Lab Manual-Msc2Document103 pagesDSP Lab Manual-Msc2AswathyPrasadNo ratings yet
- Comparative Study of Turbo Codes in AWGN Channel Using MAP and SOVA DecodingDocument14 pagesComparative Study of Turbo Codes in AWGN Channel Using MAP and SOVA Decodingyemineniraj33No ratings yet
- ViterbiDocument14 pagesViterbicalvinhsuNo ratings yet
- Amil NIS: Department of Radioelectronics Faculty of Electrical Engineering Czech Tech. University in PragueDocument30 pagesAmil NIS: Department of Radioelectronics Faculty of Electrical Engineering Czech Tech. University in PragueAr FatimzahraNo ratings yet
- Digital 3Document81 pagesDigital 3Mohamed TarkasNo ratings yet
- Lets Discuss (How, What and Why) : 16 QAM Simulation in MATLABDocument7 pagesLets Discuss (How, What and Why) : 16 QAM Simulation in MATLABpreetik917No ratings yet
- TG10 2Document5 pagesTG10 2m0hmdNo ratings yet
- JPEG Compression: CSC361/661 Spring 2002 Burg/WongDocument16 pagesJPEG Compression: CSC361/661 Spring 2002 Burg/Wongmahajan777No ratings yet
- Experimental Verification of Linear Block Codes and Hamming Codes Using Matlab CodingDocument17 pagesExperimental Verification of Linear Block Codes and Hamming Codes Using Matlab CodingBhavani KandruNo ratings yet
- Compression IIDocument51 pagesCompression IIJagadeesh NaniNo ratings yet
- Channel Coding Techniques in TetraDocument12 pagesChannel Coding Techniques in TetraAdnan Shehzad100% (1)
- The Elements of Computing Systems, second edition: Building a Modern Computer from First PrinciplesFrom EverandThe Elements of Computing Systems, second edition: Building a Modern Computer from First PrinciplesNo ratings yet
- Line Drawing Algorithm: Mastering Techniques for Precision Image RenderingFrom EverandLine Drawing Algorithm: Mastering Techniques for Precision Image RenderingNo ratings yet
- Hidden Line Removal: Unveiling the Invisible: Secrets of Computer VisionFrom EverandHidden Line Removal: Unveiling the Invisible: Secrets of Computer VisionNo ratings yet