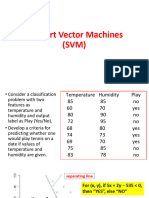
Support Vector Machines
Support Vector Machines
Download as pdf or txt
You might also like
- 6th Central Pay Commission Salary CalculatorDocument15 pages6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- Practice MidtermDocument4 pagesPractice MidtermArka MitraNo ratings yet
- R ProgrammingDocument60 pagesR Programmingzzztimbo100% (8)
- Appunti MLDocument10 pagesAppunti MLvincentNo ratings yet
- MainDocument12 pagesMainAnnayah UsmanNo ratings yet
- Support Vector Machines (SVM) Models in StataDocument19 pagesSupport Vector Machines (SVM) Models in Statajohn3963No ratings yet
- Support Vector Machine in R PaperDocument28 pagesSupport Vector Machine in R PaperzhaozilongNo ratings yet
- SVM TutorialDocument34 pagesSVM Tutoriallalithkumar_93No ratings yet
- Supervised Learning - Support Vector Machines and Feature ReductionDocument11 pagesSupervised Learning - Support Vector Machines and Feature ReductionodsnetNo ratings yet
- Training Data Selection For Support Vector MachineDocument11 pagesTraining Data Selection For Support Vector MachinePrince GurajenaNo ratings yet
- Support Vector MachinesDocument32 pagesSupport Vector MachinesGeorge PaulNo ratings yet
- Chapter 1 - Introduction To Numerical Methods and AnalysisDocument9 pagesChapter 1 - Introduction To Numerical Methods and AnalysisRyan A. RamosNo ratings yet
- Articol Informatica EconomicaDocument10 pagesArticol Informatica EconomicaralucastefaneauaNo ratings yet
- Time Series Forecasting by Using Wavelet Kernel SVMDocument52 pagesTime Series Forecasting by Using Wavelet Kernel SVMAnonymous PsEz5kGVaeNo ratings yet
- Bayesian Methods For Support Vector Machines: Evidence and Predictive Class ProbabilitiesDocument32 pagesBayesian Methods For Support Vector Machines: Evidence and Predictive Class ProbabilitiesAnonymous PKE8zOXNo ratings yet
- Problemset2 PDFDocument4 pagesProblemset2 PDFS MahapatraNo ratings yet
- SVM TutorialDocument34 pagesSVM TutorialKhoa Nguyen DangNo ratings yet
- HW 1Document4 pagesHW 1sagar0596No ratings yet
- Sequential Minimal Optimization: A Fast Algorithm For Training Support Vector MachinesDocument21 pagesSequential Minimal Optimization: A Fast Algorithm For Training Support Vector MachinesLovey SaxenaNo ratings yet
- Pract SVM PDFDocument12 pagesPract SVM PDFYasmine A. SabryNo ratings yet
- MidtermDocument12 pagesMidtermEman AsemNo ratings yet
- Detection of Temporal Bone Abnormalities Using Hybrid Wavelet Support Vector Machine ClassificationDocument6 pagesDetection of Temporal Bone Abnormalities Using Hybrid Wavelet Support Vector Machine ClassificationsaahithyaalagarsamyNo ratings yet
- Introduction To Support Vector Machines: 1 DescriptionDocument15 pagesIntroduction To Support Vector Machines: 1 DescriptionchiemeraNo ratings yet
- Another Introduction SVMDocument4 pagesAnother Introduction SVMisma_shadyNo ratings yet
- SVM in MatlabDocument17 pagesSVM in Matlabtruongvinhlan19895148100% (1)
- SVMDocument21 pagesSVMbudi_ummNo ratings yet
- Midterm Solutions For Machine LearningDocument13 pagesMidterm Solutions For Machine LearningNithinNo ratings yet
- 斯坦福大学机器学习数学基础 57-64Document8 pages斯坦福大学机器学习数学基础 57-642285145156No ratings yet
- Day 1Document41 pagesDay 1sharma.pranshu2388No ratings yet
- Tut3 QuestionsDocument2 pagesTut3 QuestionsAmir SharifiNo ratings yet
- Midterm 2010 FDocument15 pagesMidterm 2010 FMuhammad MurtazaNo ratings yet
- Homework 2: SVM, Kernel Methods, Ensemble Learning, Learning TheoryDocument12 pagesHomework 2: SVM, Kernel Methods, Ensemble Learning, Learning TheoryAli AhmadNo ratings yet
- Solu 10Document43 pagesSolu 10c_noneNo ratings yet
- CS 229, Public Course Problem Set #4: Unsupervised Learning and Re-Inforcement LearningDocument5 pagesCS 229, Public Course Problem Set #4: Unsupervised Learning and Re-Inforcement Learningsuhar adiNo ratings yet
- ML Support Vector Machines 2Document22 pagesML Support Vector Machines 223mb0072No ratings yet
- Support Vector Machine Classification Algorithm and Its ApplicationDocument8 pagesSupport Vector Machine Classification Algorithm and Its Application0191720003 ELIAS ANTONIO BELLO LEON ESTUDIANTE ACTIVONo ratings yet
- 10 1134@S0005117915090052Document16 pages10 1134@S0005117915090052Riccardo FerreroNo ratings yet
- Lec3-The Kernel TrickDocument4 pagesLec3-The Kernel TrickShankaranarayanan GopalNo ratings yet
- Matrix Computations, Marko HuhtanenDocument63 pagesMatrix Computations, Marko HuhtanenHoussam MenhourNo ratings yet
- DSCI 303: Machine Learning For Data Science Fall 2020Document5 pagesDSCI 303: Machine Learning For Data Science Fall 2020Anonymous StudentNo ratings yet
- DOS - ReportDocument25 pagesDOS - ReportSagar SimhaNo ratings yet
- Report 1Document6 pagesReport 1api-3861670No ratings yet
- Survit Sra Efficient Primal SVMDocument8 pagesSurvit Sra Efficient Primal SVMDipesh MakwanaNo ratings yet
- Support Vector Machines: Jeff WuDocument35 pagesSupport Vector Machines: Jeff WunombreNo ratings yet
- 1.1 ID5059 1.2 Tom Kelsey - Jan 2021: February 15, 2021Document43 pages1.1 ID5059 1.2 Tom Kelsey - Jan 2021: February 15, 2021Tev WallaceNo ratings yet
- An Idiot Guide To SVMDocument25 pagesAn Idiot Guide To SVMLjiljana Đurić-DelićNo ratings yet
- Iv. Single Layer Structures: 4.1. PerceptronsDocument26 pagesIv. Single Layer Structures: 4.1. PerceptronsYunus KoçNo ratings yet
- HW2 MTH452/552Document7 pagesHW2 MTH452/552Jhovanny AlexanderNo ratings yet
- Kobe University Repository: KernelDocument7 pagesKobe University Repository: KernelTrần Ngọc LâmNo ratings yet
- A Deterministic Strongly Polynomial Algorithm For Matrix Scaling and Approximate PermanentsDocument23 pagesA Deterministic Strongly Polynomial Algorithm For Matrix Scaling and Approximate PermanentsShubhamParasharNo ratings yet
- LIBSVM A Library For Support Vector MachinesDocument25 pagesLIBSVM A Library For Support Vector Machinesmhv_gameNo ratings yet
- Support Vector Machines: Review and Applications in Civil: October 2011Document15 pagesSupport Vector Machines: Review and Applications in Civil: October 2011linoficNo ratings yet
- E Cient Sparse Approximation of Support Vector Machines Solving A Kernel LassoDocument9 pagesE Cient Sparse Approximation of Support Vector Machines Solving A Kernel LassoRaja Ben CharradaNo ratings yet
- K-SVM: An Effective SVM Algorithm Based On K-Means ClusteringDocument8 pagesK-SVM: An Effective SVM Algorithm Based On K-Means ClusteringSalmaElfellahNo ratings yet
- Lecture Slides-Week12Document41 pagesLecture Slides-Week12moazzam kiani100% (1)
- Multi-Class Classification Using Support Vector Machines in Binary Tree ArchitectureDocument6 pagesMulti-Class Classification Using Support Vector Machines in Binary Tree ArchitecturegoremadNo ratings yet
- Student's Solutions Manual and Supplementary Materials for Econometric Analysis of Cross Section and Panel Data, second editionFrom EverandStudent's Solutions Manual and Supplementary Materials for Econometric Analysis of Cross Section and Panel Data, second editionNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and ApplicationsFrom EverandGreen's Function Estimates for Lattice Schrödinger Operators and ApplicationsNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- Gauss Nodes Revolution: Numerical Integration Theory Radically Simplified And GeneralisedFrom EverandGauss Nodes Revolution: Numerical Integration Theory Radically Simplified And GeneralisedNo ratings yet
- A Brief Introduction to MATLAB: Taken From the Book "MATLAB for Beginners: A Gentle Approach"From EverandA Brief Introduction to MATLAB: Taken From the Book "MATLAB for Beginners: A Gentle Approach"Rating: 2.5 out of 5 stars2.5/5 (2)
- AI Machine LearningDocument2 pagesAI Machine LearningzzztimboNo ratings yet
- A Comparison of Approaches To Large-Scale Data AnalysisDocument14 pagesA Comparison of Approaches To Large-Scale Data AnalysisVarad MeruNo ratings yet
- 4 LermanDocument2 pages4 LermanzzztimboNo ratings yet
- Google and The MindDocument8 pagesGoogle and The Mindzzztimbo100% (1)
- That Couldnt Happen To UsDocument19 pagesThat Couldnt Happen To UszzztimboNo ratings yet
- Seam ReferenceDocument320 pagesSeam Referencezzztimbo100% (10)
- Swopper ManualDocument16 pagesSwopper Manualzzztimbo100% (1)
- The $25,000,000,000 Eigenvector The Linear Algebra Behind GoogleDocument11 pagesThe $25,000,000,000 Eigenvector The Linear Algebra Behind GoogleSureshbrtNo ratings yet
- Linda Implementations in Java For Concurrent Systems: G. C. Wells, A. G. Chalmers and P. G. ClaytonDocument19 pagesLinda Implementations in Java For Concurrent Systems: G. C. Wells, A. G. Chalmers and P. G. ClaytonzzztimboNo ratings yet
- Academic Calendar 2007-2009: June 2007Document10 pagesAcademic Calendar 2007-2009: June 2007zzztimbo100% (1)
- AIprogDocument120 pagesAIprogproductionsupervisorNo ratings yet
- ADSegment IPSec W2KDocument80 pagesADSegment IPSec W2Kzzztimbo100% (1)
- To Go MenuDocument3 pagesTo Go Menuzzztimbo100% (2)
- Dynamo: Amazon's Highly Available Key-Value StoreDocument16 pagesDynamo: Amazon's Highly Available Key-Value StoreJeff PrattNo ratings yet
- The Ultimate Money MachineDocument9 pagesThe Ultimate Money Machinezzztimbo100% (3)
- Data RDocument3 pagesData RzzztimboNo ratings yet
- Google'S Mapreduce Programming Model - Revisited: Ralf L AmmelDocument42 pagesGoogle'S Mapreduce Programming Model - Revisited: Ralf L AmmelzzztimboNo ratings yet
- Automatic Meaning Discovery Using GoogleDocument31 pagesAutomatic Meaning Discovery Using GooglezzztimboNo ratings yet
- Jmeter Distributed Testing Step by StepDocument4 pagesJmeter Distributed Testing Step by StepShunSetiyabudiNo ratings yet
- Knoblock00 DebDocument10 pagesKnoblock00 DebzzztimboNo ratings yet
- MapReduce: Simplified Data Processing On Large ClustersDocument13 pagesMapReduce: Simplified Data Processing On Large Clusterszzztimbo100% (1)