0% found this document useful (0 votes)
428 viewsMultivariate Normal Distribution
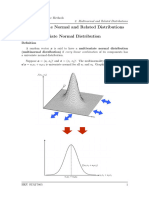
The document discusses the multivariate normal distribution. Some key points:
1) A random vector x is said to have a multivariate normal distribution if every linear combination of its components has a univariate normal distribution.
2) The distribution can be written as x ~ N(μ, Σ), where μ is the mean vector and Σ is the covariance matrix.
3) When the covariance matrix Σ is positive definite, the distribution has a density function involving the determinant and inverse of Σ. When Σ is singular, the distribution does not have a standard density function.
Uploaded by
ccffffCopyright
© © All Rights Reserved
Available Formats
Download as PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
428 viewsMultivariate Normal Distribution
The document discusses the multivariate normal distribution. Some key points:
1) A random vector x is said to have a multivariate normal distribution if every linear combination of its components has a univariate normal distribution.
2) The distribution can be written as x ~ N(μ, Σ), where μ is the mean vector and Σ is the covariance matrix.
3) When the covariance matrix Σ is positive definite, the distribution has a density function involving the determinant and inverse of Σ. When Σ is singular, the distribution does not have a standard density function.
Uploaded by
ccffffCopyright
© © All Rights Reserved
Available Formats
Download as PDF, TXT or read online on Scribd
/ 9