The document discusses the problem of backtesting in empirical finance research. Some key points:
1) Most backtests published in leading finance journals are incorrect because they do not properly account for multiple testing, which inflates false positive rates. This undermines a large portion of empirical work over the past 70 years.
2) Common errors in backtesting include look-ahead bias, unrealistic transaction costs, failure to consider capacity and slippage, and importantly, not correcting for multiple testing which leads to overfitting.
3) While some solutions exist when the algorithmic strategy has an algebraic representation, general solutions are needed when no such representation exists. The document proposes two such general solutions: a closed-form solution using
The document discusses the problem of backtesting in empirical finance research. Some key points:
1) Most backtests published in leading finance journals are incorrect because they do not properly account for multiple testing, which inflates false positive rates. This undermines a large portion of empirical work over the past 70 years.
2) Common errors in backtesting include look-ahead bias, unrealistic transaction costs, failure to consider capacity and slippage, and importantly, not correcting for multiple testing which leads to overfitting.
3) While some solutions exist when the algorithmic strategy has an algebraic representation, general solutions are needed when no such representation exists. The document proposes two such general solutions: a closed-form solution using
The document discusses the problem of backtesting in empirical finance research. Some key points:
1) Most backtests published in leading finance journals are incorrect because they do not properly account for multiple testing, which inflates false positive rates. This undermines a large portion of empirical work over the past 70 years.
2) Common errors in backtesting include look-ahead bias, unrealistic transaction costs, failure to consider capacity and slippage, and importantly, not correcting for multiple testing which leads to overfitting.
3) While some solutions exist when the algorithmic strategy has an algebraic representation, general solutions are needed when no such representation exists. The document proposes two such general solutions: a closed-form solution using
The document discusses the problem of backtesting in empirical finance research. Some key points:
1) Most backtests published in leading finance journals are incorrect because they do not properly account for multiple testing, which inflates false positive rates. This undermines a large portion of empirical work over the past 70 years.
2) Common errors in backtesting include look-ahead bias, unrealistic transaction costs, failure to consider capacity and slippage, and importantly, not correcting for multiple testing which leads to overfitting.
3) While some solutions exist when the algorithmic strategy has an algebraic representation, general solutions are needed when no such representation exists. The document proposes two such general solutions: a closed-form solution using
Lawrence Berkeley National Laboratory Computational Research Division
Key Points Empirical Finance is in crisis: Our most important discovery tool is historical simulation. And yet, most backtests published in the leading Financial journals are wrong.
The problem is well known to professional organizations of
Statisticians and Mathematicians, who have publicly criticized the misuse of mathematical tools among Finance researchers. In particular, reported results are not corrected for multiple testing. To this day, standard Econometrics textbooks appear to be oblivious to the issue of multiple testing. The President-Elect of the American Finance Association has stated that most claimed research findings in financial economics are likely false.
This may invalidate a large portion of the empirical work done
over the past 70 years. We present practical solutions to this problem. 2
SECTION I The General Backtesting Problem
The Goal of Backtesting
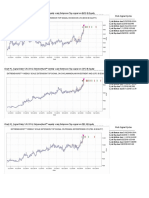
A backtest is a statistical test to evaluate the accuracy of a predictive model using available historical time series. For example, a backtest may compute the series of profits and losses that an investment strategy would have generated, should that algorithm had been run over a past time period. On the right, example of a backtested strategy. The green line plots the performance of a tradable security, while the blue line plots the performance achieved by buying and selling that security. Sharpe ratio is 1.77, with 46.21 trades per year. Note the low correlation between the strategys returns and the securitys. 4
Common Backtesting Errors
Backfill bias, survivorship bias [relatively easy to avoid]: Using an index composed on a later date, or excluding names dropped later.
Non-trailing, look-ahead bias [relatively easy to avoid]:
E.g., trading at close using signal extracted from closing prices.
Unrepresentative time period [relatively easy to avoid].
Optimistic transaction costs [somewhat involved]. Capacity and slippage [somewhat involved]: The test ignores market impact, or assumes infinite liquidity. The test assumes that no informational leakage takes place.
Performance inflation [difficult to avoid]:
Non-normality, serial dependence, outliers, etc.
Multiple Testing [hard to avoid]:
The reported false positive rate is lower than the actual.
Multiple Testing is the 800lb. Gorilla in this slide.
Some Myths on Prevention of False Discoveries
Myth #1: p-values give the probability that a finding is the result of random chance. FALSE: p-values are a statement about hypothetical study replications using imaginary well-behaved data. Myth #2: Holding-out part of the sample for cross-validation prevents false discoveries. FALSE: Hold-out, walk-forward, etc. does not control for the number of trials, thus it is equally exposed to selection bias. Myth #3: Simpler models on longer series are more likely to be correct. FALSE: The Backtest Overfitting Simulation Tool is an extremely simple model, and yet it will deliver a winning strategy on random series of any length. Journal XYZ has `selected this paper for you (p-value<0.05)!
The Backtest Overfitting Simulation Tool
An optimized investment strategy (in
blue) making steady profit while the underlying trading instrument (in green) gyrates in price. It is trivial to make Financial discoveries if enough variations are tried.
The same investment strategy performs
poorly on a different sample of the same trading instrument.
Please visit http://datagrid.lbl.gov/backtest/index.php or www.tenure-maker.org
7
Special Solutions When the algorithmic strategy has an algebraic representation, statistical methods can be used. Familywise Error Rate (FWER): Probability of even one false discovery. Hochberg and Tamhane [1987]. False Discovery Rate (FDR): Probability of a set proportion of false discoveries. Benjamini and Hochberg [1995]. Some econometric applications of FWER & FDR: Distribution of the maximal 2: Foster, Smith and Whaley [1997]. Data snooping: Harvey and Y. Liu [2014], White [2000]. Italian mathematician Carlo Bonferroni was the first (c.1936) to realize that p-values may understate the probability of a false positive. The key objective of the above procedures is to correct the effects of multipletesting on p-values. Surprisingly, 79 years later, most papers in Finance still do not correct for multiple testing, a phenomenon known as p-hacking. Most other academic fields have been addressing this issue for decades Why?
General Solutions When the algorithmic strategy does not rely on an algebraic representation, no p-values can be corrected. Two alternatives: Closed-form solution: Evaluate if the objective function (e.g., Sharpe ratio) is significantly higher than its expected maximum value after N trials. Bailey and Lpez de Prado [2014] Non-Parametric solution: Given N alternative configurations, determine if the optimal configuration in-sample consistently outperforms the median of configurations out-of-sample. Bailey, Borwein, Lpez de Prado and Zhu [2014] Harvey and Liu [2014] IMPORTANT: When someone comes to you with a machine learning strategy, always ask if s/he has controlled for the number of trials. If the answer is NO, run away as fast as you can. It does not matter if s/he has applied X-validation, hold-out, etc. When uncorrected by the number of trials, results will always be useless. 9
SECTION II General Closed-form Solution
Backtest Overfitting 7
Expected Maximum Sharpe Ratio as the number of independent trials N grows, for = 0 and 1,4 .
Expected Maximum Sharpe Ratio
1 Z 1 1
E max V 0 0
100
200
300
400
500
600
Number of Trials (N)
Variance=1
Variance=4
1 1 + Z 1 1 1
700
800
900
1000
Data Dredging: Searching for empirical findings regardless of their theoretical basis is likely to magnify the problem, as V will increase when unrestrained by theory.
This is a consequence of pure random behavior. We will observe better candidates even if there is no investment skill associated with this strategy class ( = 0). 11
The Deflated Sharpe Ratio (1/2)
The Deflated Sharpe Ratio computes the probability that the Sharpe Ratio (SR) is statistically significant, after controlling for the inflationary effect of multiple trials, data dredging, non-normal returns and shorter sample lengths.
0 =
4 1 2 1 3 + 4
where 0 =
DSR packs more information than SR, and it is expressed in
probabilistic terms. 12
The Deflated Sharpe Ratio (2/2)
The standard SR is computed as a function of two estimates: Mean of returns Standard deviation of returns.
DSR deflates SR by taking into consideration five additional
variables (it packs more information): The non-Normality of the returns 3 , 4 The length of the returns series The amount of data dredging The number of independent trials involved in the selection of the investment strategy Deflation will take place when the track record contains bad attributes. However, strategies with positive skewness or negative excess kurtosis may indeed see their DSR boosted, as SR was failing to reward those good attributes. 13
Numerical Example (1/2)
An analyst uncovers a daily strategy with annualized SR=2.5, after 1 running N=100 independent trials, where = , T=1250, 2 3 = 3 and 4 = 10. QUESTION: Is this a legitimate discovery, at a 95% conf.? ANSWER: No. There is only a 90% probability that the true Sharpe ratio is above zero. 0 =
1 2250
1 1 1
1 100
+ 1 1
1 1 100
0.1132
2.5 0.1132 250
1249
2.5 101 1 3 + 4 250
2.5 2 250
= 0.9004.
14
Numerical Example (2/2)
1
1.8
0.99
1.6
0.98
1.4
0.97
1.2
0.96
0.95
0.8
0.94
0.6
0.93
0.4
0.92
0.2
0.91
0.9
10
20
30
40
50
60
70
# Independent Trials (N)
SR0 (annualized)
80
90
100
Should the strategist have
made his discovery after running only N=46, then 0.9505. DSR
SR0, annualized
Non-Normality also played a
role in discarding this investment offer: For 3 = 0, 4 = 3, then = 0.9505 after N=88 independent trials.
DSR
It is critical for investors to account for both sources of
performance inflation jointly, as DSR does. 15
SECTION III General Non-Parametric Solution
A formal definition of Backtest Overfitting
QUESTION: What is the probability that an optimal strategy is overfit? DEFINITION 1 (Overfitting): Let be the strategy with optimal performance IS, i.e. , = 1, , . Denote the performance OOS of . Let be the median performance of all strategies OOS. Then, we say that a strategy selection process overfits if for a strategy with the highest rank IS, < In the above definition we refer to overfitting in relation to the strategy selection process (e.g., backtesting), not a strategys model calibration (e.g., a regression). 17
A formal definition of PBO
DEFINITION 2 (Probability of Backtest Overfitting): Let be the strategy with optimal performance IS. Because strategy is not necessarily optimal OOS, there is a non-null probability that < . We define the probability that the selected strategy is overfit as < In other words, we say that a strategy selection process overfits if the expected performance of the strategies selected IS is less than the median performance OOS of all strategies. In that situation, the strategy selection process becomes in fact detrimental, and selection bias takes place. 18
Combinatorially-Symmetric Cross-Validation (1/4)
1. Form a matrix M by collecting the performance series from the N trials. 2. Partition M across rows, into an even number S of disjoint submatrices of equal dimensions. Each of these submatrices ,
with s=1,,S, is of order .
3. Form all combinations of , taken in groups of size . This
2 gives a total number of combinations
= ==
2 2 2
1 2 =0
19
Combinatorially-Symmetric Cross-Validation (2/4)
4. For each combination , a. Form the training set J, by joining the 2 submatrices that
constitute c. J is a matrix of order
= . 2
b. Form the testing set , as the complement of J in M. In other
words, is the 2 matrix formed by all rows of M that are not
part of J. c. Form a vector R of performance statistics of order N, where the nth item of R reports the performance associated with the n-th column of J (the training set). d. Determine the element such that , = 1, , . In other words, = arg max .
20
Combinatorially-Symmetric Cross-Validation (3/4)
4. ( continuation.) e. Form a vector of performance statistics of order N, where the nth item of reports the performance associated with the n-th column of (the testing set). f.
Determine the relative rank of within . We will denote this
relative rank as , where 0,1 . This is the relative rank of the OOS performance associated with the trial chosen IS. If the strategy optimization procedure is not overfitting, we should observe that systematically outperforms OOS, just as outperformed R.
g. We define the logit = ln 1 . This presents the property that
= 0 when coincides with the median of .
21
Combinatorially-Symmetric Cross-Validation (4/4)
IS A A A B B C
OOS B C D C D D
C B B A A A
D D C D C B
This figure schematically represents how the combinations in are
used to produce training and testing sets, where S=4. Each arrow is associated with a logit, . 5. Compute the distribution of ranks OOS by collecting all the logits , for . is then the relative frequency at which
occurred across all , with = 1.
22
SECTION IV Backtesting as an Industry-Only Research Tool
Is Empirical Finance a Pathological Science?
Academic view: Like physical objects, Markets follow fundamental principles that can be empirically studied. Reality: Investing differs from Physics in several aspects: There are no laboratories: We cannot reproduce experiments under controlled conditions. [Hint: Calling something a lab does not make it a lab] Effects are not immutable: Competition arbitrages effects away as soon as published or maybe they never existed in the first place?? Arbitrage leads to low signal-to-noise, resulting in the proliferation of false positives. We will never know if Mr. Sarao caused the Flash Crash. Unlike in physics, we cannot repeat the events of that day in absence of Mr. Saraos spoofing... We can only backtest, however most published backtests are flawed. In the words of Prof. Campbell Harvey (President-Elect of the American Finance Association) most claimed research findings in financial economics are likely false.
24
Why Academics Should Not Publish Backtests
As an Academic tool, backtesting has limited power.
The reason is, there is no central repository of all trials. Without this information, selection bias inevitably takes place. Discovery claims cannot be challenged because There arent independent, unused datasets. Even if there are such datasets, nobody keeps track of the number of trials. Again effects are not immutable, e.g. Goodharts Law.
If Physics worked like Finance, we would all be
levitating since 1687. As soon as Newton would have published his Principia, things would have begun to float around us, and nobody would have been able to verify his equations through experimentation. [On the right, Father Merrin helping Sir Issac bring Gravity back, so that Newtons law can be tested...]
25
What Mathematicians Have To Say
Running multiple tests on the same data set at the same stage of an analysis increases the chance of obtaining at least one invalid result. Selecting the one "significant" result from a multiplicity of parallel tests poses a grave risk of an incorrect conclusion. Failure to disclose the full extent of tests and their results in such a case would be highly misleading. American Statistical Society. Ethical Guideline #A.8 Renowned Prof. Martin Fleischmann, FRS, was forced to retract his 1989 claim of achieving cold fusion at room temperature. While retractions are common in the Sciences, they are extremely rare in Finance, as claims are hard to challenge (except in cases of fraud or gross negligence). For all we know, Empirical Finance may be, to a large extent, a collection of cold fusion claims.
26
Backtesting as an Industry-Only Research Tool
Paradoxically, some of the best hedge funds are math-driven: Financial firms can conduct research in terms analogous to Scientific laboratories. E.g., deploy an execution algorithm and experiment with alternative configurations (market interaction). Financial firms can control for the increased probability of false positives that results from multiple testing. Their research protocols can legally enforce the accounting of the results from all trials carried out by employees. In the Industry, out-of-sample testing is the peer-review. If you dont make money, you are out of business. Corollary: Backtest carefully or die. Financial firms do not necessarily report their empirical discoveries, thus discovered effects are more likely to persist. Unless this state of affairs changes, true discoveries in Empirical Finance are more likely to come from the Industry than Academia. Read the Journal of Portfolio Management and other Academic journals with strong Industry involvement. 27
THANKS FOR YOUR ATTENTION!
28
SECTION V The stuff nobody reads
Bibliography
Bailey, D., J. Borwein, M. Lpez de Prado and J. Zhu (2015): The Probability of Backtest Overfitting. Journal of Computational Finance, forthcoming. Available at: http://ssrn.com/abstract=2326253 Bailey, D., J. Borwein, M. Lpez de Prado and J. Zhu (2014): Pseudo-Mathematics and Financial Charlatanism: The Effects of Backtest Overfitting on Out-Of-Sample Performance. Notices of the American Mathematical Society, 61(5), May. Available at: http://ssrn.com/abstract=2308659 Bailey, D. and M. Lpez de Prado (2012): The Sharpe Ratio Efficient Frontier. Journal of Risk, 15(2), Winter. Available at http://ssrn.com/abstract=1821643 Bailey, D. and M. Lpez de Prado (2015): Stop-Outs Under Serial Correlation and 'The Triple Penance Rule, Journal of Risk, forthcoming. Available at http://ssrn.com/abstract=2201302 Carr, P. and M. Lpez de Prado (2014): Determining Optimal Trading Rules Without Backtesting, Working paper. Available at http://arxiv.org/abs/1408.1159 Lpez de Prado, M. (2015): Quantitative Meta-Strategies, Practical Applications (IIJ), 2(3), Spring. Available at http://ssrn.com/abstract=2547325 30
Bio Marcos Lpez de Prado is Senior Managing Director at Guggenheim Partners. He is also a Research Fellow at Lawrence Berkeley National Laboratory's Computational Research Division (U.S. Department of Energys Office of Science), where he conducts unclassified research in the mathematics of largescale financial problems and supercomputing. Before that, Marcos was Head of Quantitative Trading & Research at Hess Energy Trading Company (the trading arm of Hess Corporation, a Fortune 100 company) and Head of Global Quantitative Research at Tudor Investment Corporation. In addition to his 17 years of trading and investment management experience at some of the largest corporations, he has received several academic appointments, including Postdoctoral Research Fellow of RCC-Harvard University and Visiting Scholar at Cornell University. Marcos earned a Ph.D. in Financial Economics (2003), a second Ph.D. in Mathematical Finance (2011) from Complutense University, is a recipient of the National Award for Excellence in Academic Performance by the Government of Spain (National Valedictorian, 1998) among other awards, and was admitted into American Mensa with a perfect test score. Marcos serves on the Editorial Board of the Journal of Portfolio Management (IIJ) and the Journal of Investment Strategies (Risk). He has collaborated with ~30 leading academics, resulting in some of the most read papers in Finance (SSRN), four international patent applications on High Frequency Trading, three textbooks, numerous publications in the top Mathematical Finance journals, etc. Marcos has an Erds #2 and an Einstein #4 according to the American Mathematical Society. 31
Disclaimer The views expressed in this document are the authors and do not necessarily reflect those of the organizations he is affiliated with. No investment decision or particular course of action is recommended by this presentation. All Rights Reserved.
32
Notice: The research contained in this presentation is the result of a continuing collaboration with David H. Bailey, Berkeley Lab Jon M. Borwein, FRSC, AAAS Peter P. Carr, Morgan Stanley, NYU Jim (Qiji) Zhu, WMU The full paper is available at: http://ssrn.com/abstract=2547325 For additional details, please visit: http://ssrn.com/author=434076 www.QuantResearch.info