Interpolation and The Lagrange Polynomial
Interpolation and The Lagrange Polynomial
Download as pdf or txt
At a glance
Powered by AI
The key takeaways are that polynomials can be used to uniformly approximate continuous functions over intervals, and that the Lagrange interpolation polynomial is commonly used for this purpose.
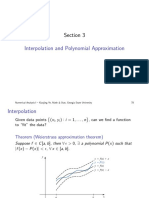
The Weierstrass Approximation Theorem states that any continuous function on a closed interval can be uniformly approximated as closely as desired by polynomials. It is important because it shows the fundamental role of polynomials in approximation.
Karl Weierstrass was an influential German mathematician who helped develop rigorous analysis. He demonstrated functions can be continuous everywhere but nowhere differentiable, and influenced the theory of functions.
You might also like
- Just As I Am (I Come Broken) AbDocument2 pagesJust As I Am (I Come Broken) AbLinda Lutz100% (1)
- CSP 369de MTM 1Document358 pagesCSP 369de MTM 1Irving Martin Beltran Lopez100% (8)
- Incredible God (Chords)Document1 pageIncredible God (Chords)Jesse Wilson100% (3)
- Rhetorical Analysis EssayDocument5 pagesRhetorical Analysis Essayapi-253584128No ratings yet
- Chapter 2 - Laplace Transform PDFDocument34 pagesChapter 2 - Laplace Transform PDFSritaran Balakrishnan100% (1)
- Task 2. English ConversationDocument5 pagesTask 2. English ConversationMarianny GarciaNo ratings yet
- FEM Matlab ProgramDocument4 pagesFEM Matlab ProgramleaNo ratings yet
- 17 Lagrange Interpolation Mathematica ProgramDocument14 pages17 Lagrange Interpolation Mathematica ProgramShashank MishraNo ratings yet
- Numerical AnalysisDocument14 pagesNumerical AnalysisJoshua CookNo ratings yet
- Lab4 - System Modeling 3 - 30-04-2018Document34 pagesLab4 - System Modeling 3 - 30-04-2018Eng. Ibrahim Abdullah AlruhmiNo ratings yet
- Newton's Divided DifferenceDocument25 pagesNewton's Divided DifferencePonnammal KuppusamyNo ratings yet
- mmj1113-Ch02 Nonlinear Equations-Beamer PDFDocument32 pagesmmj1113-Ch02 Nonlinear Equations-Beamer PDFYvonne Zakharov RosenblumNo ratings yet
- Root Locus Method 2Document33 pagesRoot Locus Method 2Umasankar ChilumuriNo ratings yet
- Lagrange InterpolationDocument19 pagesLagrange InterpolationRaja Saad100% (1)
- Intelligent InstrumentationDocument26 pagesIntelligent InstrumentationGoran Miljkovic100% (1)
- Lec 1 Lagrange InterpolationDocument18 pagesLec 1 Lagrange InterpolationMuhammad AliNo ratings yet
- An Enhanced Simulation Model For DC Motor Belt Drive Conveyor System ControlDocument5 pagesAn Enhanced Simulation Model For DC Motor Belt Drive Conveyor System ControlArif AfifNo ratings yet
- Successive OverDocument5 pagesSuccessive OverYohannesNo ratings yet
- RALPH JAN AQUINO Control System SummaryDocument13 pagesRALPH JAN AQUINO Control System SummaryralphNo ratings yet
- 2nd Exam D.E.1 NotesDocument4 pages2nd Exam D.E.1 NotesVince Carlo C GarciaNo ratings yet
- Differential Equations Review MaterialDocument5 pagesDifferential Equations Review MaterialIsmael SalesNo ratings yet
- Differential Calculus Application ProblemsDocument23 pagesDifferential Calculus Application ProblemsJeric PonterasNo ratings yet
- Algorithms For Constrained OptimizationDocument22 pagesAlgorithms For Constrained OptimizationnmooseNo ratings yet
- Signal Analysis Using MATLABDocument8 pagesSignal Analysis Using MATLABRajiv ShahNo ratings yet
- Matlab Practice TutorialDocument8 pagesMatlab Practice Tutorialchemeleon89No ratings yet
- Final - Exam - SIGNALS AND SYSTEMSDocument3 pagesFinal - Exam - SIGNALS AND SYSTEMSinesNo ratings yet
- Least Square Approximation/Regression: Numerical Methods by Chapra (Chapter 17) Numerical Analysis by Burden (Chapter 8)Document22 pagesLeast Square Approximation/Regression: Numerical Methods by Chapra (Chapter 17) Numerical Analysis by Burden (Chapter 8)Hussain RizviNo ratings yet
- Newton Gauss MethodDocument37 pagesNewton Gauss MethodLucas WeaverNo ratings yet
- Unit-1 Control System Analysis and ComponentsDocument10 pagesUnit-1 Control System Analysis and ComponentsBrooke HollandNo ratings yet
- Topic 8-Mean Square Estimation-Wiener and Kalman FilteringDocument73 pagesTopic 8-Mean Square Estimation-Wiener and Kalman FilteringHamza MahmoodNo ratings yet
- M.tech. (Digital Systems & Signal Processing)Document41 pagesM.tech. (Digital Systems & Signal Processing)Ali MaaroufNo ratings yet
- Chapter 2 FinalDocument83 pagesChapter 2 FinalSana Saleem100% (1)
- 16-Splines and Piecewise InterpolationDocument17 pages16-Splines and Piecewise InterpolationkennethmsorianoNo ratings yet
- 1.ma6459 NM PDFDocument118 pages1.ma6459 NM PDFmmrmathsiubdNo ratings yet
- DigitalSignalProcessing Course McGillDocument6 pagesDigitalSignalProcessing Course McGillSalman NazirNo ratings yet
- Matrices and System of Linear Equations PDFDocument20 pagesMatrices and System of Linear Equations PDFMuhammad IzzuanNo ratings yet
- NotesDocument72 pagesNotesReza ArraffiNo ratings yet
- LabviewDocument25 pagesLabviewGaurav KansekarNo ratings yet
- Differential Equations Midterm 1 v1 SolutionsDocument6 pagesDifferential Equations Midterm 1 v1 SolutionsRodney HughesNo ratings yet
- Datta Meghe College of Engineering, AiroliDocument39 pagesDatta Meghe College of Engineering, AiroliMayuri patilNo ratings yet
- Fourier-Analysis CE273Document41 pagesFourier-Analysis CE273Luyun GE Mark AnjoNo ratings yet
- DSP Lecture NotesDocument24 pagesDSP Lecture Notesvinothvin86No ratings yet
- A.1 Iterative MethodsDocument20 pagesA.1 Iterative MethodsSaad ManzurNo ratings yet
- Segment-6 Discrete Fourier Transform (DFT) & Fast Fourier Transform (FFT)Document32 pagesSegment-6 Discrete Fourier Transform (DFT) & Fast Fourier Transform (FFT)mghabirNo ratings yet
- The Fourier Series and Fourier TransformDocument55 pagesThe Fourier Series and Fourier TransformShiju RamachandranNo ratings yet
- Numerical Solution of Ordinary Differential Equations Part 2 - Nonlinear EquationsDocument38 pagesNumerical Solution of Ordinary Differential Equations Part 2 - Nonlinear EquationsMelih TecerNo ratings yet
- 08.06 Shooting Method For Ordinary Differential EquationsDocument7 pages08.06 Shooting Method For Ordinary Differential EquationsaroobadilawerNo ratings yet
- Numerische Methoden Lecture NotesDocument126 pagesNumerische Methoden Lecture NotesSanjay KumarNo ratings yet
- Probability AssignmentDocument10 pagesProbability Assignmentrabya waheedNo ratings yet
- DSP Chapter 2 Part 1Document45 pagesDSP Chapter 2 Part 1api-26581966100% (1)
- CH 4 Solution of Systems of Non Linear EquationDocument6 pagesCH 4 Solution of Systems of Non Linear EquationAddisu Safo Bosera0% (1)
- Chapter 1 - Limits and Continuity PDFDocument55 pagesChapter 1 - Limits and Continuity PDFZack MalikNo ratings yet
- Spectrum AnalysisDocument35 pagesSpectrum AnalysisdogueylerNo ratings yet
- Chapter 2 Linear Signal ModelsDocument40 pagesChapter 2 Linear Signal ModelsSisayNo ratings yet
- Feedback and Control Systems: Activity No. 2 - Time Response of Dynamic SystemsDocument15 pagesFeedback and Control Systems: Activity No. 2 - Time Response of Dynamic SystemsYvesExequielPascuaNo ratings yet
- Mathematical Models of Control System: Frequency Domain Analysis System Representation and ImplementationDocument21 pagesMathematical Models of Control System: Frequency Domain Analysis System Representation and ImplementationOgba OkparanyoteNo ratings yet
- 4 Curve Fitting Least Square Regression and InterpolationDocument59 pages4 Curve Fitting Least Square Regression and InterpolationEyu KalebNo ratings yet
- DSP Lab Manual 5 Semester Electronics and Communication EngineeringDocument147 pagesDSP Lab Manual 5 Semester Electronics and Communication Engineeringrupa_123No ratings yet
- NI - PresentationDocument14 pagesNI - PresentationAkash ShettannavarNo ratings yet
- Answer Key Calculus MCQDocument5 pagesAnswer Key Calculus MCQStephen Lloyd GeronaNo ratings yet
- Signals & Systems Course Contents of ElDocument2 pagesSignals & Systems Course Contents of ElNoor SabaNo ratings yet
- Introductory Applications of Partial Differential Equations: With Emphasis on Wave Propagation and DiffusionFrom EverandIntroductory Applications of Partial Differential Equations: With Emphasis on Wave Propagation and DiffusionNo ratings yet
- Numerica Analysis 1Document44 pagesNumerica Analysis 1Kiio MakauNo ratings yet
- NA Ch3 StudentDocument92 pagesNA Ch3 StudentAhiduzzaman AhirNo ratings yet
- Elgenfunction Expansions Associated with Second Order Differential EquationsFrom EverandElgenfunction Expansions Associated with Second Order Differential EquationsNo ratings yet
- Inside Revrerse-Folds To Form The Legs. Repeat Behind. Double Rabbit-Ear To Form The NeckDocument4 pagesInside Revrerse-Folds To Form The Legs. Repeat Behind. Double Rabbit-Ear To Form The NeckEmmanuel Jerome TagaroNo ratings yet
- Protractor Measuring The Angle)Document1 pageProtractor Measuring The Angle)Emmanuel Jerome TagaroNo ratings yet
- Unfold The Bottom Flap On One SideDocument5 pagesUnfold The Bottom Flap On One SideEmmanuel Jerome TagaroNo ratings yet
- Mountain-Fold Bottom Edges Inside. Pull Out Flap in FrontDocument3 pagesMountain-Fold Bottom Edges Inside. Pull Out Flap in FrontEmmanuel Jerome TagaroNo ratings yet
- Valley Fold The Little Tip in The Middle To Meet The Other TipDocument4 pagesValley Fold The Little Tip in The Middle To Meet The Other TipEmmanuel Jerome TagaroNo ratings yet
- Repeat Steps 37 Through 40 On The Other SideDocument3 pagesRepeat Steps 37 Through 40 On The Other SideEmmanuel Jerome TagaroNo ratings yet
- Dragon 5Document3 pagesDragon 5Emmanuel Jerome TagaroNo ratings yet
- Dragon 3Document3 pagesDragon 3Emmanuel Jerome TagaroNo ratings yet
- Dragon 4Document3 pagesDragon 4Emmanuel Jerome TagaroNo ratings yet
- Dragon 2Document4 pagesDragon 2Emmanuel Jerome TagaroNo ratings yet
- White Side Up. Pre-Fold Diagonals. Valley-Fold The Top Corner To The Center and UnfoldDocument3 pagesWhite Side Up. Pre-Fold Diagonals. Valley-Fold The Top Corner To The Center and UnfoldEmmanuel Jerome TagaroNo ratings yet
- Kathy Curnow PDFDocument8 pagesKathy Curnow PDFEmmanuel Jerome TagaroNo ratings yet
- Modeling of Mechanical VibrationDocument31 pagesModeling of Mechanical VibrationEmmanuel Jerome TagaroNo ratings yet
- Development of The SonnetDocument2 pagesDevelopment of The SonnetFahiem Chaucer75% (4)
- Captain Canot : Brantz MayerDocument252 pagesCaptain Canot : Brantz MayerGutenberg.orgNo ratings yet
- Creativity WorkshopDocument42 pagesCreativity WorkshopRamyaa RameshNo ratings yet
- Engleski Riječi PDFDocument5 pagesEngleski Riječi PDFMajaNo ratings yet
- A483 (A) 786 2024Document2 pagesA483 (A) 786 2024Sagar SNo ratings yet
- Differences in Tear Secretion Before and After Phacoemulsification Surgery Using Schirmer I TestsDocument4 pagesDifferences in Tear Secretion Before and After Phacoemulsification Surgery Using Schirmer I TestsKris AdinataNo ratings yet
- LibreOffice Calc Guide 2Document20 pagesLibreOffice Calc Guide 2Violeta XevinNo ratings yet
- GS HS Math 2012 ParticipantDocument224 pagesGS HS Math 2012 Participanthairey947594No ratings yet
- PatanjaliDocument2 pagesPatanjaliAbhishek KumarNo ratings yet
- GCSE English Literature Poems at A Potato DiggingDocument2 pagesGCSE English Literature Poems at A Potato DiggingSahib MatharuNo ratings yet
- Brief Report On Ibadan City Wide Crusade Held at Amphi Theatre AdamasingbaDocument4 pagesBrief Report On Ibadan City Wide Crusade Held at Amphi Theatre AdamasingbaOlusanya Tolulope OlufemiNo ratings yet
- Ayurveda and The Mind The Healing of Consciousness David Frawley.12821 - 2prefaceDocument6 pagesAyurveda and The Mind The Healing of Consciousness David Frawley.12821 - 2prefaceJayvin PandeeyaNo ratings yet
- Papa PublicDocument22 pagesPapa PublicKenneth LeeNo ratings yet
- Recollection For ParentsDocument33 pagesRecollection For ParentsMCCEI RAD100% (8)
- Paper V - PDF FinalDocument13 pagesPaper V - PDF Finalalex jonesNo ratings yet
- Programme GuideDocument56 pagesProgramme GuidecarolynNo ratings yet
- Tablas Cinéticas PDFDocument466 pagesTablas Cinéticas PDFSergioNo ratings yet
- Assignment Research and StatisticsDocument24 pagesAssignment Research and StatisticsJailani KunNo ratings yet
- Multi Variable Optimization: Min F (X, X, X, - X)Document69 pagesMulti Variable Optimization: Min F (X, X, X, - X)Mohsin ModiNo ratings yet
- Card Game: Must and Mustn't by Jill Hadfield: Teacher'S NotesDocument3 pagesCard Game: Must and Mustn't by Jill Hadfield: Teacher'S NotesBettina Borg CardonaNo ratings yet
- Performing An Automated InstallationDocument24 pagesPerforming An Automated InstallationDaniel SouzaNo ratings yet
- Marriage As KPDocument4 pagesMarriage As KPSunil RupaniNo ratings yet
- Lemar Hema Exam Lemar Hema ExamDocument10 pagesLemar Hema Exam Lemar Hema ExamJaycee ArgaNo ratings yet
- Robin DiAngelo's 'White Fragility' Ignores The Differences Within WhitenessDocument4 pagesRobin DiAngelo's 'White Fragility' Ignores The Differences Within WhitenessgaryrobertNo ratings yet
- Grade 10 Math Performance Task Practice Test Scoring Guide Lights Candles ActionDocument20 pagesGrade 10 Math Performance Task Practice Test Scoring Guide Lights Candles ActionMaychelle TañezaNo ratings yet