0% found this document useful (0 votes)
140 viewsHttps Raw - Githubusercontent.com Joelgrus Data-Science-From-Scratch Master Code Working With Data
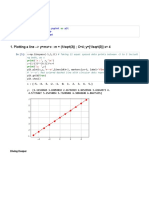
The document contains code for working with data in Python including functions for making histograms, comparing distributions, generating random normal distributions, creating scatter plots, calculating correlations, rescaling data, and performing dimensionality reduction. It includes functions for bucketizing points, making histograms, plotting histograms, generating random normal values, creating scatter plots, calculating correlation matrices, grouping and transforming data, rescaling data, and reducing dimensionality.
Uploaded by
gprasadatvuCopyright
© © All Rights Reserved
Available Formats
Download as PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
140 viewsHttps Raw - Githubusercontent.com Joelgrus Data-Science-From-Scratch Master Code Working With Data
The document contains code for working with data in Python including functions for making histograms, comparing distributions, generating random normal distributions, creating scatter plots, calculating correlations, rescaling data, and performing dimensionality reduction. It includes functions for bucketizing points, making histograms, plotting histograms, generating random normal values, creating scatter plots, calculating correlation matrices, grouping and transforming data, rescaling data, and reducing dimensionality.
Uploaded by
gprasadatvuCopyright
© © All Rights Reserved
Available Formats
Download as PDF, TXT or read online on Scribd
/ 7