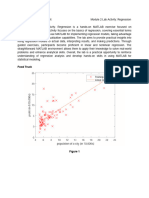
Linear Regression: Machine Learning
Linear Regression: Machine Learning
Download as docx, pdf, or txt
You might also like
- Numerical Methods With MATLAB - Recktenwald PDFDocument85 pagesNumerical Methods With MATLAB - Recktenwald PDFMustafa Yılmaz100% (1)
- Machine Learning Coursera All Exercies PDFDocument117 pagesMachine Learning Coursera All Exercies PDFsudheer1044No ratings yet
- Programming Exercise 1: Linear Regression: Machine LearningDocument15 pagesProgramming Exercise 1: Linear Regression: Machine Learningvaror52751No ratings yet
- Programming Exercise 1: Linear Regression: Machine LearningDocument15 pagesProgramming Exercise 1: Linear Regression: Machine LearningElisabethHanNo ratings yet
- Machine Learning Programming ExerciseDocument118 pagesMachine Learning Programming Exercisexgdsmxy100% (2)
- Linear RegressionDocument14 pagesLinear RegressionSyed Tariq NaqshbandiNo ratings yet
- Ex 1Document15 pagesEx 1Nathan LawlessNo ratings yet
- Programming Exercise 5: Regularized Linear Regression and Bias V.S. VarianceDocument14 pagesProgramming Exercise 5: Regularized Linear Regression and Bias V.S. VarianceleloiboiNo ratings yet
- Ex 1Document15 pagesEx 1Marlos SilvaNo ratings yet
- Linear Regression - Numpy and SklearnDocument7 pagesLinear Regression - Numpy and SklearnArala FolaNo ratings yet
- ML Regression DocumentationDocument7 pagesML Regression Documentationsamuel.yacoubbNo ratings yet
- Gradient Descent and SGDDocument8 pagesGradient Descent and SGDROHIT ARORANo ratings yet
- Ex 5Document14 pagesEx 5api-322416213No ratings yet
- Fisseha Berhane,: Analytical and Numerical Solutions, With R, To Linear Regression ProblemsDocument22 pagesFisseha Berhane,: Analytical and Numerical Solutions, With R, To Linear Regression ProblemsGeorge HamiltonNo ratings yet
- Ex 2 SolutionDocument13 pagesEx 2 SolutionMian AlmasNo ratings yet
- ExerciseDocument15 pagesExerciseNguyen NamNo ratings yet
- Machine Learning Coursera All ExerciesDocument117 pagesMachine Learning Coursera All Exerciesshrikedpill75% (12)
- Ex 3Document12 pagesEx 3api-322416213No ratings yet
- 3 Types of Gradient Descent Algorithms For Small & Large DatasetsDocument9 pages3 Types of Gradient Descent Algorithms For Small & Large Datasetscontactcenter2 LiderNo ratings yet
- PP Introduction To MATLABDocument11 pagesPP Introduction To MATLABAnindya Ayu NovitasariNo ratings yet
- Stanford Machine Learning Exercise 1Document15 pagesStanford Machine Learning Exercise 1MaxNo ratings yet
- Ex 3Document12 pagesEx 3iqfzfbzqfzfqNo ratings yet
- Curve Fitting in MATLAB NotesDocument7 pagesCurve Fitting in MATLAB Notesextramailm2No ratings yet
- Linear Regression: What Is Regression Analysis?Document21 pagesLinear Regression: What Is Regression Analysis?sailusha100% (1)
- A Matlab TutorialDocument39 pagesA Matlab TutorialRitam ChatterjeNo ratings yet
- Question 1 (Linear Regression)Document18 pagesQuestion 1 (Linear Regression)Salton GerardNo ratings yet
- Assignment 1Document4 pagesAssignment 101689373477No ratings yet
- Lecture Notes - Linear RegressionDocument26 pagesLecture Notes - Linear RegressionAmandeep Kaur GahirNo ratings yet
- Linear RegressionDocument46 pagesLinear RegressionRajkiran PatilNo ratings yet
- Sample Exam For ML YSZ Sample For Machine Lerning - CMNKNVMNCS."NMD, MN, MVN, MDNV, MNDV MC, MDN, MDCNVM, NDV, M Ccwdmnbnbew, MwbeDocument4 pagesSample Exam For ML YSZ Sample For Machine Lerning - CMNKNVMNCS."NMD, MN, MVN, MDNV, MNDV MC, MDN, MDCNVM, NDV, M Ccwdmnbnbew, MwbeSalton GerardNo ratings yet
- An Introduction To Gradient Descent and Linear RegressionDocument8 pagesAn Introduction To Gradient Descent and Linear RegressionabolfazlNo ratings yet
- Linear Regression - Jupyter NotebookDocument56 pagesLinear Regression - Jupyter NotebookUjwal Vajranabhaiah100% (3)
- Sample Exam For ML YSZ: Question 1 (Linear Regression)Document4 pagesSample Exam For ML YSZ: Question 1 (Linear Regression)Salton GerardNo ratings yet
- Assignment 1Document3 pagesAssignment 1Abu Fatih100% (1)
- ML Exercise 1Document15 pagesML Exercise 1c_mc2No ratings yet
- Statistical Computing in Matlab: AMS 597 Ling LengDocument23 pagesStatistical Computing in Matlab: AMS 597 Ling LengRenatus KatunduNo ratings yet
- ML Answers UpdatedDocument13 pagesML Answers UpdatedKrishnakant BeheraNo ratings yet
- Data Analysis Using R - 5Document9 pagesData Analysis Using R - 5harshvasudevkoliNo ratings yet
- Ex5 PDFDocument14 pagesEx5 PDFJuan Pablo LorenzoNo ratings yet
- Machine Learning With Python AlgorithmsDocument28 pagesMachine Learning With Python Algorithmslukumon balogunNo ratings yet
- Lab 6Document9 pagesLab 6Muhammad Samay EllahiNo ratings yet
- Linear Regression With Gradient DescentDocument8 pagesLinear Regression With Gradient DescentGautam Kumar100% (1)
- Module 2 Lab Activity - RegressionDocument9 pagesModule 2 Lab Activity - RegressionjulienneulitNo ratings yet
- Homework 2: Lasso Regression: 1.1 Data Set and Programming Problem OverviewDocument11 pagesHomework 2: Lasso Regression: 1.1 Data Set and Programming Problem OverviewMayur AgrawalNo ratings yet
- AI Lec5Document42 pagesAI Lec5Asil Zulfiqar 4459-FBAS/BSCS4/F21No ratings yet
- Numerical Methods With Matlab - ch10 - SolutionDocument8 pagesNumerical Methods With Matlab - ch10 - SolutionDevesh KumarNo ratings yet
- Introduction To Machine Learning Algorithms: Linear RegressionDocument1 pageIntroduction To Machine Learning Algorithms: Linear RegressionRahul ThoratNo ratings yet
- 04 Matlab and Roots IIIDocument18 pages04 Matlab and Roots IIISadaf SalehiNo ratings yet
- Graficar Curvas de Nivel en PythonDocument4 pagesGraficar Curvas de Nivel en PythonDavid Vivas0% (1)
- Line Drawing Algorithm: Mastering Techniques for Precision Image RenderingFrom EverandLine Drawing Algorithm: Mastering Techniques for Precision Image RenderingNo ratings yet
- Bundle Adjustment: Optimizing Visual Data for Precise ReconstructionFrom EverandBundle Adjustment: Optimizing Visual Data for Precise ReconstructionNo ratings yet
- Backpropagation: Fundamentals and Applications for Preparing Data for Training in Deep LearningFrom EverandBackpropagation: Fundamentals and Applications for Preparing Data for Training in Deep LearningNo ratings yet
- A Brief Introduction to MATLAB: Taken From the Book "MATLAB for Beginners: A Gentle Approach"From EverandA Brief Introduction to MATLAB: Taken From the Book "MATLAB for Beginners: A Gentle Approach"Rating: 2.5 out of 5 stars2.5/5 (2)
- Nonlinear Control Feedback Linearization Sliding Mode ControlFrom EverandNonlinear Control Feedback Linearization Sliding Mode ControlNo ratings yet
- Bresenham Line Algorithm: Efficient Pixel-Perfect Line Rendering for Computer VisionFrom EverandBresenham Line Algorithm: Efficient Pixel-Perfect Line Rendering for Computer VisionNo ratings yet
- MLOps and Systems - Syllabus and Weekly Schedule - September 2021Document4 pagesMLOps and Systems - Syllabus and Weekly Schedule - September 2021Vivek ThotaNo ratings yet
- Week1 - Introduction To Machine Learning and ToolkitDocument102 pagesWeek1 - Introduction To Machine Learning and ToolkitVivek ThotaNo ratings yet
- 1.0.1.2 Class Activity - Draw Your Concept of The InternetDocument1 page1.0.1.2 Class Activity - Draw Your Concept of The InternetVivek ThotaNo ratings yet
- OpenSAP Ml2 Week 1 InstallationGuide AnacondaDocument6 pagesOpenSAP Ml2 Week 1 InstallationGuide AnacondaVivek ThotaNo ratings yet
- Setup AnacondaDocument1 pageSetup AnacondaVivek ThotaNo ratings yet
- Syllabus and The Details of Examinations For The Award of AMATEUR STATION OPERATOR'S LICENCE (Restricted) and (General)Document5 pagesSyllabus and The Details of Examinations For The Award of AMATEUR STATION OPERATOR'S LICENCE (Restricted) and (General)Vivek ThotaNo ratings yet
- OpenSAP Ml2 Week 1 InstallationGuide AnacondaDocument6 pagesOpenSAP Ml2 Week 1 InstallationGuide AnacondaVivek ThotaNo ratings yet
- General Guide Lines:: Application For Amateur Station Operators Certificate (ASOC) ExaminationDocument7 pagesGeneral Guide Lines:: Application For Amateur Station Operators Certificate (ASOC) ExaminationVivek ThotaNo ratings yet
- NetRiders Brochure APAC 2017 enDocument12 pagesNetRiders Brochure APAC 2017 enVivek ThotaNo ratings yet
- Setup AnacondaDocument1 pageSetup AnacondaVivek ThotaNo ratings yet
- 1.0 Introduction To AndroidDocument37 pages1.0 Introduction To AndroidVivek ThotaNo ratings yet
- Comptia A+ Linux Cheat Sheet: Basic Command SyntaxDocument1 pageComptia A+ Linux Cheat Sheet: Basic Command SyntaxVivek ThotaNo ratings yet
- Day-2 Agenda:-1) Wireless Connectivity BluetoothDocument1 pageDay-2 Agenda:-1) Wireless Connectivity BluetoothVivek ThotaNo ratings yet
- Anyone Over 12 Years Can Be A HAM.: Grade Frequencies Alloted Morse Code (Sending and Receiving)Document2 pagesAnyone Over 12 Years Can Be A HAM.: Grade Frequencies Alloted Morse Code (Sending and Receiving)Vivek ThotaNo ratings yet
- DST& TI ContestDocument8 pagesDST& TI ContestVivek ThotaNo ratings yet
- Chapter 5: Wave Sensing Systems: 2 X Sin Ysin X y e 4 S M M O SDocument55 pagesChapter 5: Wave Sensing Systems: 2 X Sin Ysin X y e 4 S M M O SVivek ThotaNo ratings yet
- Microcontrollers: UNIT-2 Introduction and 8051 Architecture: IntroductionDocument116 pagesMicrocontrollers: UNIT-2 Introduction and 8051 Architecture: IntroductionVivek ThotaNo ratings yet
- TEP Programme BrochureDocument20 pagesTEP Programme BrochureVivek ThotaNo ratings yet
- DE GR14 QPDocument2 pagesDE GR14 QPVivek ThotaNo ratings yet
- Linear Algebra (Mir, 1983)Document393 pagesLinear Algebra (Mir, 1983)georgetacaprarescuNo ratings yet
- Adv Math Lab10Document2 pagesAdv Math Lab10Meriç GäßlerNo ratings yet
- Frank WolfeDocument10 pagesFrank WolfeRodolfo Sergio Cruz FuentesNo ratings yet
- Year 9 May - June 2023 QPDocument20 pagesYear 9 May - June 2023 QPnmorsy91826No ratings yet
- Improved Analytic Solution of Black Hole SuperradianceDocument7 pagesImproved Analytic Solution of Black Hole Superradiancega.simplicio2No ratings yet
- Least Squares Full ResumeDocument15 pagesLeast Squares Full ResumeseñalesuisNo ratings yet
- 7th Maths SOS May New AlterDocument6 pages7th Maths SOS May New Alternomiyaqoob5No ratings yet
- 11 Sem 1 Trial 2023Document2 pages11 Sem 1 Trial 2023Hadi ShaifulNo ratings yet
- Third Quarter ActivityDocument39 pagesThird Quarter Activityeunica_dolojanNo ratings yet
- BE - 3110014 - Mathematics 1 - Tutorial - 2023 - 24Document19 pagesBE - 3110014 - Mathematics 1 - Tutorial - 2023 - 24Herin Soni100% (1)
- Canadian Senior Mathematics Contest: The Centre For Education in Mathematics and Computing Cemc - Uwaterloo.caDocument6 pagesCanadian Senior Mathematics Contest: The Centre For Education in Mathematics and Computing Cemc - Uwaterloo.caSwati NigaamNo ratings yet
- IMC Number TheoryDocument3 pagesIMC Number TheoryAbir MohammedNo ratings yet
- (Doi 10.1017/9781139856485.004) Nualart, David Nualart, Eulalia - Introduction To Malliavin Calculus - Derivative and Divergence Operators PDFDocument13 pages(Doi 10.1017/9781139856485.004) Nualart, David Nualart, Eulalia - Introduction To Malliavin Calculus - Derivative and Divergence Operators PDFGabriele ScarlattiNo ratings yet
- Solution of Exercises of 7.5 and 7.6Document6 pagesSolution of Exercises of 7.5 and 7.6Mayank BhartiNo ratings yet
- Using Bezier Curves For Geometric Transformations: MSM Creative Component Catherine Kaspar Fall 2009Document40 pagesUsing Bezier Curves For Geometric Transformations: MSM Creative Component Catherine Kaspar Fall 2009Abdelkarim AdnaneNo ratings yet
- Chapter 3. ODEDocument66 pagesChapter 3. ODEJoke ChanNo ratings yet
- Bessel's EquationDocument27 pagesBessel's EquationVelzaeroNo ratings yet
- Points of Intersection (P.O.I.) - Graphing Method: (Use Slope and Y-Intercept)Document4 pagesPoints of Intersection (P.O.I.) - Graphing Method: (Use Slope and Y-Intercept)Varun KumarNo ratings yet
- Classroom Notes: Pursuit Curves in The Complex PlaneDocument9 pagesClassroom Notes: Pursuit Curves in The Complex PlaneJohn GillNo ratings yet
- PMO National 2018 For IMO PDFDocument8 pagesPMO National 2018 For IMO PDFCedrixe MadridNo ratings yet
- Introduction To VectorsDocument130 pagesIntroduction To VectorsLee MwadimeNo ratings yet
- Grade 9 Quiz Term 3Document2 pagesGrade 9 Quiz Term 3muhammad shoaibNo ratings yet
- B. 14.1 AB WKSHT HW Also Add Your Turn Problems P 440 To This For HWDocument2 pagesB. 14.1 AB WKSHT HW Also Add Your Turn Problems P 440 To This For HWShaira ClamorNo ratings yet
- Parareal Algorithm: Ma. Cristina BargoDocument43 pagesParareal Algorithm: Ma. Cristina BargoTina BargoNo ratings yet
- HC Sba 2020 Unit 2 Test 1Document2 pagesHC Sba 2020 Unit 2 Test 1kkkkllllNo ratings yet
- AIMO 2017 Trial G8 PaperDocument6 pagesAIMO 2017 Trial G8 PaperHary PurbowoNo ratings yet
- Lesson Plan Sem 3Document35 pagesLesson Plan Sem 3narayananx5No ratings yet
- FD Methods For Parabolic Pdes: 10:12:57, Subject To The Cambridge Core Terms of UseDocument30 pagesFD Methods For Parabolic Pdes: 10:12:57, Subject To The Cambridge Core Terms of Useverstapenm76No ratings yet
- Cyclic Convolution PDFDocument64 pagesCyclic Convolution PDFGopalakrishnanNo ratings yet
- Order of Complexity AnalysisDocument9 pagesOrder of Complexity AnalysisMusic LifeNo ratings yet