0% found this document useful (0 votes)
56 viewsLinear Regression
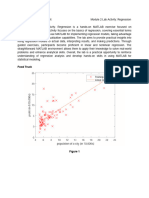
This document provides instructions for completing an assignment on linear regression and optimization functions. It includes downloading starter code files and completing functions for plotting data, computing the cost function, and performing gradient descent to fit a linear regression model to a dataset. The dataset contains population and profit values for various cities. The goal is to predict profits based on population by finding the optimal parameters θ using gradient descent. Functions are provided to plot the data, compute the cost J(θ), and perform gradient descent updates to minimize J(θ) and fit the linear regression line.
Uploaded by
Syed Tariq NaqshbandiCopyright
© © All Rights Reserved
Available Formats
Download as PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
56 viewsLinear Regression
This document provides instructions for completing an assignment on linear regression and optimization functions. It includes downloading starter code files and completing functions for plotting data, computing the cost function, and performing gradient descent to fit a linear regression model to a dataset. The dataset contains population and profit values for various cities. The goal is to predict profits based on population by finding the optimal parameters θ using gradient descent. Functions are provided to plot the data, compute the cost J(θ), and perform gradient descent updates to minimize J(θ) and fit the linear regression line.
Uploaded by
Syed Tariq NaqshbandiCopyright
© © All Rights Reserved
Available Formats
Download as PDF, TXT or read online on Scribd
/ 14