0% found this document useful (0 votes)
155 viewsEssentials of Linear Regression in Python
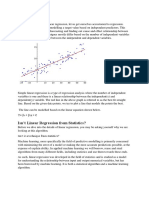
This document provides an overview of linear regression. It defines a regression problem as predicting a continuous output variable from one or more input variables. Linear regression finds a linear function that models the relationship between the input and output variables. It works by minimizing the cost, or error, between the predicted outputs of the linear function and the actual outputs in the training data. Methods like ordinary least squares are commonly used to optimize linear regression by updating the model's parameters (coefficients) through gradient descent to reduce the cost function. While a simple algorithm, linear regression forms the basis for more advanced statistical learning methods.
Uploaded by
Sourav DasCopyright
© © All Rights Reserved
Available Formats
Download as DOCX, PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
155 viewsEssentials of Linear Regression in Python
This document provides an overview of linear regression. It defines a regression problem as predicting a continuous output variable from one or more input variables. Linear regression finds a linear function that models the relationship between the input and output variables. It works by minimizing the cost, or error, between the predicted outputs of the linear function and the actual outputs in the training data. Methods like ordinary least squares are commonly used to optimize linear regression by updating the model's parameters (coefficients) through gradient descent to reduce the cost function. While a simple algorithm, linear regression forms the basis for more advanced statistical learning methods.
Uploaded by
Sourav DasCopyright
© © All Rights Reserved
Available Formats
Download as DOCX, PDF, TXT or read online on Scribd
/ 23