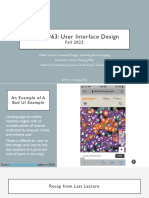
4d WSC Sample
4d WSC Sample
Download as pdf or txt
You might also like
- Dragon Bundle: It's Time To & Make Projects That MatterDocument18 pagesDragon Bundle: It's Time To & Make Projects That MatterRajesh ShindeNo ratings yet
- The Consumer Research ProcessDocument32 pagesThe Consumer Research ProcessvikramsinghcharanNo ratings yet
- Final Project Part One Netflix Ids 404 Lydia HarrisDocument13 pagesFinal Project Part One Netflix Ids 404 Lydia Harrisapi-352111965No ratings yet
- EvaluationtechDocument40 pagesEvaluationtechjNo ratings yet
- MS - BDA Lec - Recommendation Systems IDocument31 pagesMS - BDA Lec - Recommendation Systems IJasura HimeNo ratings yet
- HCI - Evaluation TechniquesDocument43 pagesHCI - Evaluation TechniquesTemsgen BirhanuNo ratings yet
- POLI4023 - Week 19 - BeforeDocument30 pagesPOLI4023 - Week 19 - BeforeFraj A AlshandoliNo ratings yet
- CSE545 sp23 (9) Recommendation Systems 4-10Document72 pagesCSE545 sp23 (9) Recommendation Systems 4-10Selvi KrishNo ratings yet
- Concept Generation: Prof. Rakesh JainDocument21 pagesConcept Generation: Prof. Rakesh JainAviral KediaNo ratings yet
- Overview of Interaction DesignDocument50 pagesOverview of Interaction DesignMedhansh RajdeoNo ratings yet
- Eliciting Requirements Specifying RequirementsDocument90 pagesEliciting Requirements Specifying RequirementsoghaleudoluNo ratings yet
- POLI4023 - Week 19 - AfterDocument29 pagesPOLI4023 - Week 19 - AfterFraj A AlshandoliNo ratings yet
- Introduction to Statistics and Research, MSBA Statistics, 2-6-24 (10 section) copyDocument36 pagesIntroduction to Statistics and Research, MSBA Statistics, 2-6-24 (10 section) copyvarun.seku123No ratings yet
- Chapter-6 Concept GenerationDocument66 pagesChapter-6 Concept GenerationOnur ATASEVEN100% (2)
- Session 1 2Document92 pagesSession 1 2Anuj SharmaNo ratings yet
- 12 Surveys and Questionnaires Revision 2009Document57 pages12 Surveys and Questionnaires Revision 2009Marissa ZabalaNo ratings yet
- Chapter 5Document39 pagesChapter 5Tâm Hồ VănNo ratings yet
- Module5 Recommender Systems PartADocument54 pagesModule5 Recommender Systems PartAAathmika VijayNo ratings yet
- CSIT114-Week 3 - Systems and Business RequirementsDocument56 pagesCSIT114-Week 3 - Systems and Business Requirementsadam hopeNo ratings yet
- PotentialDocument40 pagesPotentialRaj GuptaNo ratings yet
- 4-A PrototypeDocument30 pages4-A Prototypenhith22402No ratings yet
- 2-Recommender Systems - Section B - Annotated PDFDocument44 pages2-Recommender Systems - Section B - Annotated PDFdeepak kumarNo ratings yet
- Music RecommendationDocument113 pagesMusic Recommendationrdd74900100% (1)
- Recommender System - NewDocument49 pagesRecommender System - New245123742004No ratings yet
- PD6Document22 pagesPD6noah11012002No ratings yet
- Unit 7: Evaluation TechniquesDocument41 pagesUnit 7: Evaluation TechniquesKiruthiga DeepikaNo ratings yet
- Part 1 (Chapter 1-4) : Fundamental Components of Interactive SystemDocument46 pagesPart 1 (Chapter 1-4) : Fundamental Components of Interactive SystemM. Talha NadeemNo ratings yet
- Evaluation TechniquesDocument25 pagesEvaluation TechniquesM Husnain ShahidNo ratings yet
- 1 Leaning IntroductionDocument29 pages1 Leaning Introductionlookup.itsNo ratings yet
- SEIP 2021 - Project Workshop - Week 07Document7 pagesSEIP 2021 - Project Workshop - Week 07Little YuheeNo ratings yet
- CB Chapter 2Document30 pagesCB Chapter 2d43843e7e5No ratings yet
- Interaction Design: Natnael GonfaDocument40 pagesInteraction Design: Natnael GonfaMebiratu BeyeneNo ratings yet
- 8455094Document27 pages8455094Orkun oğuzhan AksoyNo ratings yet
- The Process of Interaction DesignDocument29 pagesThe Process of Interaction DesignLe DungNo ratings yet
- E-Assessment & Learning Analytics: 9. Learner Modelling & Recommender SystemsDocument45 pagesE-Assessment & Learning Analytics: 9. Learner Modelling & Recommender Systemsfabian plettNo ratings yet
- Machine and product design_6_elearningDocument40 pagesMachine and product design_6_elearningTran Minh TriNo ratings yet
- HCI-lecture Chp9 (Evaluation Techniques)Document60 pagesHCI-lecture Chp9 (Evaluation Techniques)Waqas TanoliNo ratings yet
- Recommender LectureDocument29 pagesRecommender LectureArockiaruby RubyNo ratings yet
- Slides Lecture 2 RecSysDocument86 pagesSlides Lecture 2 RecSyssummerorvectorNo ratings yet
- Previous LectureDocument43 pagesPrevious LecturemuneebNo ratings yet
- RO47002 - Course IntroductionDocument48 pagesRO47002 - Course IntroductionHaia Al SharifNo ratings yet
- CulbertDocument19 pagesCulbertBad BoyNo ratings yet
- Requirement ElicitationDocument57 pagesRequirement ElicitationKHUSHI MAHESHWARINo ratings yet
- Data Mining Week 1 2Document117 pagesData Mining Week 1 2nadeemajeedchNo ratings yet
- Chapter 4 Research - Design AbDocument40 pagesChapter 4 Research - Design AbGatluak Thalow KuethNo ratings yet
- Shad Valley MUN: Introduction To Product Design and DevelopmentDocument20 pagesShad Valley MUN: Introduction To Product Design and DevelopmentzetseatNo ratings yet
- 12. Recommendation SystemDocument62 pages12. Recommendation Systemnguyenducanhtuan22092004No ratings yet
- NeedfindingDocument37 pagesNeedfindingDenis SuljakovicNo ratings yet
- III-IT-Data Mining Unit 1-Session 2-Part1Document17 pagesIII-IT-Data Mining Unit 1-Session 2-Part1Saranya KalimuthuNo ratings yet
- Human Computer Interaction Unit Iii: BY C.Vinoth (Adhoc) Dept CSE GcesDocument40 pagesHuman Computer Interaction Unit Iii: BY C.Vinoth (Adhoc) Dept CSE GcesVinoth ChandrasekaranNo ratings yet
- 4-NPD - The UB Design ApproachDocument9 pages4-NPD - The UB Design ApproachLeon BrridgesNo ratings yet
- 20S1 Seminar 05 StudentVersionDocument80 pages20S1 Seminar 05 StudentVersiondave.grahammmNo ratings yet
- UCD Sketching Prototyping-01Document26 pagesUCD Sketching Prototyping-01sahibNo ratings yet
- CS305: HCI in SW Development: Software Process and User-Centered DesignDocument62 pagesCS305: HCI in SW Development: Software Process and User-Centered DesignMebiratu BeyeneNo ratings yet
- Chapter 03 5eDocument51 pagesChapter 03 5ewatcherdannyNo ratings yet
- 02-User Analysis - Task AnalysisDocument59 pages02-User Analysis - Task AnalysisYap Hoong chunNo ratings yet
- The Process of Interaction DesignDocument106 pagesThe Process of Interaction DesignEmran AljarrahNo ratings yet
- Application of or in AgricultureDocument48 pagesApplication of or in AgricultureFrew Tadesse FreNo ratings yet
- Mlfa Autumn 22 Lec 01Document43 pagesMlfa Autumn 22 Lec 01Abhro DharNo ratings yet
- A Guide to Assessing Needs: Essential Tools for Collecting Information, Making Decisions, and Achieving Development ResultsFrom EverandA Guide to Assessing Needs: Essential Tools for Collecting Information, Making Decisions, and Achieving Development ResultsRating: 3 out of 5 stars3/5 (2)
- The Handbook of Online Marketing Research: Knowing Your Customer Using the NetFrom EverandThe Handbook of Online Marketing Research: Knowing Your Customer Using the NetRating: 2 out of 5 stars2/5 (1)
- Choose Change HealthcareDocument17 pagesChoose Change HealthcarekpsaripalliNo ratings yet
- Serious Games in Healthcare PDFDocument12 pagesSerious Games in Healthcare PDFkpsaripalliNo ratings yet
- Alert-Driven E-Service Management: Dickson K.W. Chiu, Benny W. C. Kwok, Ray L. S. Wong, S.C. Cheung, Eleanna KafezaDocument10 pagesAlert-Driven E-Service Management: Dickson K.W. Chiu, Benny W. C. Kwok, Ray L. S. Wong, S.C. Cheung, Eleanna KafezakpsaripalliNo ratings yet
- Nagarjuna LanguageDocument17 pagesNagarjuna LanguagekpsaripalliNo ratings yet
- Unnadi Nalubadi Sadvidya, Sri RamanaDocument84 pagesUnnadi Nalubadi Sadvidya, Sri Ramanakpsaripalli100% (3)
- SAP Data Masking ToolsDocument6 pagesSAP Data Masking ToolskpsaripalliNo ratings yet
- 4 - 09-19-2024 - 16-50-45 - NEW BTech (CSE (AI & ML), B.Tech. (AI & ML), B.Tech. CSE (AI) and B.Tech. (AI) 3rd & 4th Years From The Session 2024-25Document59 pages4 - 09-19-2024 - 16-50-45 - NEW BTech (CSE (AI & ML), B.Tech. (AI & ML), B.Tech. CSE (AI) and B.Tech. (AI) 3rd & 4th Years From The Session 2024-25mehori7294No ratings yet
- Lec 1-2 Notes Introduction To Machine LearningDocument7 pagesLec 1-2 Notes Introduction To Machine Learningchudailbhoot790No ratings yet
- SynopsisDocument31 pagesSynopsisFUN FACTZNo ratings yet
- An Improved Collaborative Movie Recommendation System Using Computational Intelligence-2Document9 pagesAn Improved Collaborative Movie Recommendation System Using Computational Intelligence-2jalatfNo ratings yet
- What Is Product AnalyticsDocument13 pagesWhat Is Product Analyticsjahanviaggarwal06No ratings yet
- Project+Template 2Document10 pagesProject+Template 2m.3mokhtar3No ratings yet
- Reverse Engineering The YouTube Algorithm PT 2Document6 pagesReverse Engineering The YouTube Algorithm PT 2agnihoonNo ratings yet
- Handbook Recommender Systems For LearningDocument31 pagesHandbook Recommender Systems For LearningtmpvmaNo ratings yet
- Tourism TicsDocument355 pagesTourism TicsVasiliniuc IonutNo ratings yet
- Chapter 8. IS and Artificial Intelligence TechnologiesDocument18 pagesChapter 8. IS and Artificial Intelligence TechnologiesKamran ArmaniNo ratings yet
- The Future of Artificial IntelligenceDocument2 pagesThe Future of Artificial IntelligenceAreeha ZahidNo ratings yet
- Application of Business Analytics in Various IndustriesDocument3 pagesApplication of Business Analytics in Various IndustriesAlyNo ratings yet
- Miniproject ThirukumaranDocument38 pagesMiniproject ThirukumaranqwdqwdqNo ratings yet
- Epaper - The Personalized Mobile Newspaper: Bracha Shapira, Peretz Shoval, Joachim Meyer, Noam Tractinsky, Dudu MimranDocument7 pagesEpaper - The Personalized Mobile Newspaper: Bracha Shapira, Peretz Shoval, Joachim Meyer, Noam Tractinsky, Dudu MimranpandijaiNo ratings yet
- Ten Financial Applications of Machine Learning: Marcos López de PradoDocument20 pagesTen Financial Applications of Machine Learning: Marcos López de PradoAndrew FuNo ratings yet
- Solution MethodologyDocument3 pagesSolution Methodologysanjib biswasNo ratings yet
- E Health and Fitness Recommendation System Using Machine LearningDocument8 pagesE Health and Fitness Recommendation System Using Machine Learningsunil computerNo ratings yet
- Expert Systems With Applications - Volume 149, 1 July 2020, 113301Document11 pagesExpert Systems With Applications - Volume 149, 1 July 2020, 113301meseret systemNo ratings yet
- The Effects Cognitive Approach of Personality Expression: Results in The LiteratureDocument5 pagesThe Effects Cognitive Approach of Personality Expression: Results in The LiteratureMajoysa MagpileNo ratings yet
- Leveraging Artificial Intelligence For Community-Centric Information Services in Public LibrariesDocument2 pagesLeveraging Artificial Intelligence For Community-Centric Information Services in Public LibrariesNo ThanksNo ratings yet
- Netflix - EcommerceDocument17 pagesNetflix - Ecommerceitaloyz87No ratings yet
- Semantic Web Recommender SystemsDocument12 pagesSemantic Web Recommender Systemsynmanju4usNo ratings yet
- Arun KumarDocument7 pagesArun Kumarrishabkumar25798No ratings yet
- Main Steps For Doing Data Mining Project Using Weka: February 2016Document20 pagesMain Steps For Doing Data Mining Project Using Weka: February 2016kavi testNo ratings yet
- 2021-Evaluation of Recent Advances in Recommender Systems On Arabic ContentDocument20 pages2021-Evaluation of Recent Advances in Recommender Systems On Arabic ContentRehab Ahmed Mohamed FaroukNo ratings yet
- Artificial Intelligence - MGR UniversityDocument41 pagesArtificial Intelligence - MGR UniversityBlessyNo ratings yet
- Student Performance Analysis: A Systematic ResearchDocument9 pagesStudent Performance Analysis: A Systematic ResearchInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Complete Download Predictive Analytics with Microsoft Azure Machine Learning Barga PDF All ChaptersDocument62 pagesComplete Download Predictive Analytics with Microsoft Azure Machine Learning Barga PDF All Chapterspeyodeo50% (2)