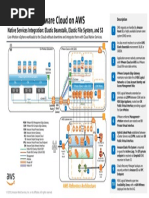
Durability & Availability: Durability Can Be Described As The Probability That You Will Eventually Be
Durability & Availability: Durability Can Be Described As The Probability That You Will Eventually Be
Download as docx, pdf, or txt
You might also like
- Cloud Web ApplicationDocument10 pagesCloud Web ApplicationBharat PremNo ratings yet
- Lab Assignment 2-CSET 463Document20 pagesLab Assignment 2-CSET 4632412arjitchauhanNo ratings yet
- Module 1 - Activity 1 - Install and Configure The AWS CLIDocument9 pagesModule 1 - Activity 1 - Install and Configure The AWS CLIJulio RosalesNo ratings yet
- Saa c01Document186 pagesSaa c01ArifNo ratings yet
- Transcript: Kouame Romeo Kouadio 1. Vmware Learning Zone Basic SubscriptionDocument13 pagesTranscript: Kouame Romeo Kouadio 1. Vmware Learning Zone Basic SubscriptionRomeo0% (1)
- Special Economic Zones in The OIC-Region PDFDocument194 pagesSpecial Economic Zones in The OIC-Region PDFFreedom FreedomNo ratings yet
- AWS Cloud Automation: Harnessing Terraform For AWS Infrastructure As CodeFrom EverandAWS Cloud Automation: Harnessing Terraform For AWS Infrastructure As CodeNo ratings yet
- AWS Fully Loaded: Mastering Amazon Web Services for Complete Cloud SolutionsFrom EverandAWS Fully Loaded: Mastering Amazon Web Services for Complete Cloud SolutionsNo ratings yet
- General S3 FAQsDocument45 pagesGeneral S3 FAQsshailesh.dyadeNo ratings yet
- Solving The Five Most Common VMware Virtual Machine Issues FINALDocument20 pagesSolving The Five Most Common VMware Virtual Machine Issues FINALHingu BhargavNo ratings yet
- AWS S3 QuizetDocument51 pagesAWS S3 QuizetchandraNo ratings yet
- Installing Vmware Esx and Esxi: Module Number 13-1Document16 pagesInstalling Vmware Esx and Esxi: Module Number 13-1سعود المعشريNo ratings yet
- AWS Certified Solutions Architect Associate Practice Test 01Document88 pagesAWS Certified Solutions Architect Associate Practice Test 01mpramod16No ratings yet
- AWS - Interview Questions For BeginnersDocument14 pagesAWS - Interview Questions For Beginnersnirajaadithya.dasireddiNo ratings yet
- AWS Certified Solutions Architect Associate Practice Test 03Document72 pagesAWS Certified Solutions Architect Associate Practice Test 03mpramod16No ratings yet
- Cloud ComputingDocument22 pagesCloud Computingmdarmaanmalik0078600No ratings yet
- AWS Certified Solutions Architect Associate Practice Test 02Document75 pagesAWS Certified Solutions Architect Associate Practice Test 02mpramod16No ratings yet
- Amazon ElastiCache - Digital Cloud Training (2019!05!25 07-29-21)Document7 pagesAmazon ElastiCache - Digital Cloud Training (2019!05!25 07-29-21)rahulpatil9559No ratings yet
- The Vcp5-Dcv Blueprint - : Study GuideDocument138 pagesThe Vcp5-Dcv Blueprint - : Study Guidedacan1No ratings yet
- saa3_wk7Document117 pagessaa3_wk7welehe9538No ratings yet
- VcenterServer Installation ManualDocument6 pagesVcenterServer Installation Manualhamidsa81No ratings yet
- AWS IAM VPC and EC2 Interview QuestionsDocument17 pagesAWS IAM VPC and EC2 Interview QuestionsRohit KulkarniNo ratings yet
- Docker Usage and Cheat SheetDocument6 pagesDocker Usage and Cheat SheetBachu Saee RamNo ratings yet
- Amazon - Pass4sure - Aws Certified Solutions Architect - Associate 2018.v2019-02-12.by - Mia.84q PDFDocument3 pagesAmazon - Pass4sure - Aws Certified Solutions Architect - Associate 2018.v2019-02-12.by - Mia.84q PDFmehanakjafhhaifhiassf100% (1)
- 04 1) +EC2+instance+LabDocument45 pages04 1) +EC2+instance+LabBuddiNo ratings yet
- Aws Unilever FinalDocument17 pagesAws Unilever FinalPradeesh S AINo ratings yet
- 1) AWS Things To KnowDocument14 pages1) AWS Things To KnowMike DanielNo ratings yet
- Ec2 InstancesDocument38 pagesEc2 Instancesjyotiraditya0709.be21No ratings yet
- Architecting On AWSDocument3 pagesArchitecting On AWSMartin CarrozzoNo ratings yet
- Aws CsaDocument83 pagesAws Csararawet685No ratings yet
- AWS SQL Server LincensingDocument37 pagesAWS SQL Server Lincensingnearurheart1No ratings yet
- OCI Cust Onboarding Session Activity GuideDocument74 pagesOCI Cust Onboarding Session Activity Guidesrak478502No ratings yet
- AWS - IAM QuizletDocument32 pagesAWS - IAM QuizletchandraNo ratings yet
- Service Offerings: AWS Price Calculator Azure CalculatorDocument3 pagesService Offerings: AWS Price Calculator Azure CalculatorSachin YadavNo ratings yet
- Amazon Web ServicesDocument2 pagesAmazon Web Servicesrob_howard_12No ratings yet
- Introduction To AWS IAMDocument5 pagesIntroduction To AWS IAMSrinivasanNo ratings yet
- AWS Solution Architect Associate Agenda PDFDocument6 pagesAWS Solution Architect Associate Agenda PDFSamaram SamNo ratings yet
- All Netapp Cifs 2Document96 pagesAll Netapp Cifs 2Purushothama GnNo ratings yet
- AWS Solutions Architect Project 1 SolutionDocument8 pagesAWS Solutions Architect Project 1 SolutionNaseeerulla KhanNo ratings yet
- Route 53 NotesDocument6 pagesRoute 53 Notesnaresh sahuNo ratings yet
- Aws Saa McqsDocument24 pagesAws Saa McqsHarleen KaurNo ratings yet
- Shell ProgrammingDocument29 pagesShell ProgrammingHaritha NaraNo ratings yet
- AWS IAM NotesDocument12 pagesAWS IAM NotessivakumarNo ratings yet
- Ramaiah Chinna SwamyDocument5 pagesRamaiah Chinna SwamySyed AbrarNo ratings yet
- Amazon Cloudfront Overview: Tal Saraf General Manager Amazon Cloudfront and Route 53Document40 pagesAmazon Cloudfront Overview: Tal Saraf General Manager Amazon Cloudfront and Route 53செந்தில் குமார்No ratings yet
- EC2 Forensics & Incident ResponseDocument6 pagesEC2 Forensics & Incident Responsechristopher.d.domanNo ratings yet
- VMware QAsDocument18 pagesVMware QAsgdhivakarNo ratings yet
- Troubleshoot Windows Ad Auth PDFDocument39 pagesTroubleshoot Windows Ad Auth PDFJoseph SamuelNo ratings yet
- Aws Reference Architecture Oracle Rac On Vmware Cloud PDFDocument1 pageAws Reference Architecture Oracle Rac On Vmware Cloud PDFsundeep_dubeyNo ratings yet
- AWS SME QuestionsDocument8 pagesAWS SME Questionssaif sadiqNo ratings yet
- VMware Fusion Network Settings - Part 1Document7 pagesVMware Fusion Network Settings - Part 1MC. Rene Solis R.100% (3)
- Cognixia 360° MASTERS TRAINING PROGRAM IN AWSDocument25 pagesCognixia 360° MASTERS TRAINING PROGRAM IN AWSshivNo ratings yet
- AWS SAA-C03Document272 pagesAWS SAA-C03wei chenNo ratings yet
- VM Series Deployment PDFDocument606 pagesVM Series Deployment PDFSushant ManwatkarNo ratings yet
- Virtual Private Cloud (Amazon VPC) : Naresh I Technologies Amazon Web Services Avinash Reddy TDocument33 pagesVirtual Private Cloud (Amazon VPC) : Naresh I Technologies Amazon Web Services Avinash Reddy Tma3gr8No ratings yet
- Synchronization Service Manager - Azure ADDocument4 pagesSynchronization Service Manager - Azure ADAbhijeet KumarNo ratings yet
- Aindump2go Saa-C03 Vce 2023-Jun-20 by Timothy 236q VceDocument13 pagesAindump2go Saa-C03 Vce 2023-Jun-20 by Timothy 236q Vceomar meroNo ratings yet
- 9.amazon Elastic File System (EFS) PDFDocument12 pages9.amazon Elastic File System (EFS) PDFbiswajit patrasecNo ratings yet
- Active Directory 101 Install and Configure AD Domain ServicesDocument31 pagesActive Directory 101 Install and Configure AD Domain ServicesLuis Reyes ZelayaNo ratings yet
- AWS Cloud Solutions Architecht Associate Exam PrepDocument4 pagesAWS Cloud Solutions Architecht Associate Exam PrepmehanakjafhhaifhiassfNo ratings yet
- Amazon - Lead2pass - Aws Certified Solutions Architect - Associate.v2019-02-12.by - Zoe.493qDocument4 pagesAmazon - Lead2pass - Aws Certified Solutions Architect - Associate.v2019-02-12.by - Zoe.493qmehanakjafhhaifhiassfNo ratings yet
- 1418Document19 pages1418mehanakjafhhaifhiassfNo ratings yet
- CV KRNDocument8 pagesCV KRNmehanakjafhhaifhiassfNo ratings yet
- CoverLetter LalithaRamakrishnan Java 5yrs ExpDocument1 pageCoverLetter LalithaRamakrishnan Java 5yrs ExpmehanakjafhhaifhiassfNo ratings yet
- Linux-Commands and NIFI TemplateDocument110 pagesLinux-Commands and NIFI Templatemehanakjafhhaifhiassf0% (1)
- A Snapshot of CaseyDocument2 pagesA Snapshot of CaseymehanakjafhhaifhiassfNo ratings yet
- 30 Oil Less Cooking RecipesDocument21 pages30 Oil Less Cooking RecipesmehanakjafhhaifhiassfNo ratings yet
- Java Interview MapDocument1 pageJava Interview MapmehanakjafhhaifhiassfNo ratings yet
- The Ultimate Guide To Job Interview Answers1Document92 pagesThe Ultimate Guide To Job Interview Answers1Oana Si Cristi Mocanu89% (9)
- Wca Regulations and GuidelinesDocument25 pagesWca Regulations and GuidelinesEmanuel AravenaNo ratings yet
- MT600 ManualDocument60 pagesMT600 ManualnattornmNo ratings yet
- BIG-IP LTM Architecture and High AvailabilityDocument19 pagesBIG-IP LTM Architecture and High Availabilityanh0050% (2)
- PRMO L6 - Properties of GCD, LCMDocument48 pagesPRMO L6 - Properties of GCD, LCMŁØNɆ ⱲØŁꞘNo ratings yet
- Grundfos Isolutions: We Bring More Than PumpsDocument31 pagesGrundfos Isolutions: We Bring More Than PumpsTasawwur TahirNo ratings yet
- Must Read ITT QuestionsDocument62 pagesMust Read ITT QuestionsMadhan LakshmiNarayanan100% (2)
- COLIPA Good - Manufacturing - Practices-Guidelines - For - The - Manufacturer - of - Cosmetic - Products PDFDocument21 pagesCOLIPA Good - Manufacturing - Practices-Guidelines - For - The - Manufacturer - of - Cosmetic - Products PDFDevi Sri. DNo ratings yet
- Cylinder Design Standards WSNZDocument5 pagesCylinder Design Standards WSNZjamilNo ratings yet
- ANALYSIS Aerodynamics ParagliderDocument8 pagesANALYSIS Aerodynamics Paraglidermlproject42No ratings yet
- P-N-P Alloy - Junction Germanium Power Transistors: High Power Conversion - High Current Switching AudioDocument4 pagesP-N-P Alloy - Junction Germanium Power Transistors: High Power Conversion - High Current Switching Audio王宗超No ratings yet
- Solid Waste ManagementDocument17 pagesSolid Waste ManagementMuthamsetty Shyam SundarNo ratings yet
- Training Report 1Document27 pagesTraining Report 1SHANKAR PRINTINGNo ratings yet
- 3C03 Quality Check 201707008Document4 pages3C03 Quality Check 201707008ruhichavan15No ratings yet
- Adobe TutorialDocument37 pagesAdobe Tutorialv69silva100% (1)
- PROJECT SYNOPSIS Team Android-1Document11 pagesPROJECT SYNOPSIS Team Android-1Nisha PanditaNo ratings yet
- 100 Keraflex Maxi Uk NoRestrictionDocument4 pages100 Keraflex Maxi Uk NoRestrictionFloorkitNo ratings yet
- Guia Rapida - Mammomat InspirationDocument26 pagesGuia Rapida - Mammomat InspirationISABEL URBANO100% (2)
- Whirlpool Awsx 63213Document33 pagesWhirlpool Awsx 63213Iulian LupseNo ratings yet
- Bioorganic Chem Arm HandbookDocument192 pagesBioorganic Chem Arm HandbookVardan TorosyanNo ratings yet
- Kathrein 80010622V01Document2 pagesKathrein 80010622V01Miguel Andres Vanegas G100% (2)
- Acct Statement XX8988 01102021Document1 pageAcct Statement XX8988 01102021punit GroverNo ratings yet
- School Calendar and End of School Year Rites - SY 2022-2023Document20 pagesSchool Calendar and End of School Year Rites - SY 2022-2023tojhie 07No ratings yet
- Hardware Information Guide: Emc Vnxe Series Vnxe3200Document65 pagesHardware Information Guide: Emc Vnxe Series Vnxe3200Anonymous n4NOOONo ratings yet
- NX Import Pax FilesDocument4 pagesNX Import Pax FilesmusebladeNo ratings yet
- 2 Wheeler Spare Parts Master IndiaDocument130 pages2 Wheeler Spare Parts Master IndiaHarsh Goyal100% (3)
- A380 Pilots GuideDocument26 pagesA380 Pilots GuideJoseph Michael Leal100% (1)
- Nuctech WooKong HDocument2 pagesNuctech WooKong HJonathan ChikNo ratings yet
- Case 1 Murphy Brother FurnitureDocument2 pagesCase 1 Murphy Brother FurnitureSuvrata SarmaNo ratings yet
- Networkx ReferenceDocument524 pagesNetworkx ReferenceSanthoshPatil0% (1)