0% found this document useful (0 votes)
97 viewsAssignment Solution 074
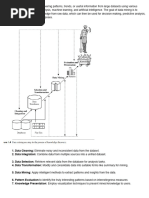
The document discusses data mining techniques for analyzing an applicant dataset from a financial services company. It describes the company's agent recruitment process and goal of predicting which applicants will become successful agents. The data contains applicant and manager attributes. Data cleaning steps are outlined, such as handling missing values through imputation or binning, and dealing with noisy data through binning, clustering, or regression. Data integration is also mentioned.
Uploaded by
Atharv SharmaCopyright
© © All Rights Reserved
Available Formats
Download as DOCX, PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
97 viewsAssignment Solution 074
The document discusses data mining techniques for analyzing an applicant dataset from a financial services company. It describes the company's agent recruitment process and goal of predicting which applicants will become successful agents. The data contains applicant and manager attributes. Data cleaning steps are outlined, such as handling missing values through imputation or binning, and dealing with noisy data through binning, clustering, or regression. Data integration is also mentioned.
Uploaded by
Atharv SharmaCopyright
© © All Rights Reserved
Available Formats
Download as DOCX, PDF, TXT or read online on Scribd
/ 8