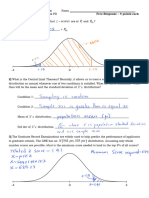
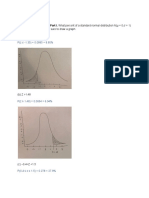
Binomial Distribuiton Assumptions of Binomial Distribuiton
Binomial Distribuiton Assumptions of Binomial Distribuiton
Download as xlsx, pdf, or txt
You might also like
- Statistics Traning ExamDocument10 pagesStatistics Traning Exammohammed saleh100% (1)
- Conditional Probability and TableDocument11 pagesConditional Probability and TableFatah UmasugiNo ratings yet
- Chapter 7 Sampling and Sampling DistributionsDocument24 pagesChapter 7 Sampling and Sampling DistributionsAnonymous yMOMM9bs100% (1)
- Approximating The Shapiro-Wilk W-Test For Non-NormalityDocument3 pagesApproximating The Shapiro-Wilk W-Test For Non-NormalityOsman HamdiNo ratings yet
- Tut1ans PDFDocument3 pagesTut1ans PDFwilliam waltersNo ratings yet
- Analysis of Variance & CorrelationDocument31 pagesAnalysis of Variance & Correlationjohn erispeNo ratings yet
- Ken Black QA ch10Document47 pagesKen Black QA ch10Rushabh VoraNo ratings yet
- Discrete and Continuous Probability Distributions PPT BECDocument68 pagesDiscrete and Continuous Probability Distributions PPT BECJohn Philip ReyesNo ratings yet
- Stat Test 4Document8 pagesStat Test 4supun gamageNo ratings yet
- Assignment Stataic Multimedia UniversityDocument5 pagesAssignment Stataic Multimedia UniversityUmmara RaziNo ratings yet
- 0feaf24f-6a96-4279-97a1-86708e467593 (1)Document7 pages0feaf24f-6a96-4279-97a1-86708e467593 (1)simandharNo ratings yet
- BS Lect 12Document14 pagesBS Lect 12jasonnumahnalkelNo ratings yet
- AP ECON 2500 Session 2Document22 pagesAP ECON 2500 Session 2Thuỳ DungNo ratings yet
- DM QuestionsDocument19 pagesDM Questionseman.safwat2001No ratings yet
- Binomial DistributionDocument22 pagesBinomial DistributionRemelyn AsahidNo ratings yet
- Ist 214-Statictics Ii: Week 4: Binomial Distribution and Poison Distribution, Expected Values and VarianceDocument18 pagesIst 214-Statictics Ii: Week 4: Binomial Distribution and Poison Distribution, Expected Values and Variancemelekkbass10No ratings yet
- STA 13 (hw3)Document8 pagesSTA 13 (hw3)Jelly Jelly JamjamNo ratings yet
- FN 211 Self Test 4: Data Summary, Confidence Intervals, and Hypothesis TestingDocument10 pagesFN 211 Self Test 4: Data Summary, Confidence Intervals, and Hypothesis TestingRaiNz SeasonNo ratings yet
- Practice DOM501 Session 12-13 SolvedDocument4 pagesPractice DOM501 Session 12-13 SolvedashuuuNo ratings yet
- QBM101_chapter5Document65 pagesQBM101_chapter56p7g6yfphfNo ratings yet
- QBM 101 Business Statistics: Department of Business Studies Faculty of Business, Economics & Accounting HE LP UniversityDocument65 pagesQBM 101 Business Statistics: Department of Business Studies Faculty of Business, Economics & Accounting HE LP UniversityVân HảiNo ratings yet
- 1743 Chapter 4 Probability DistributionDocument23 pages1743 Chapter 4 Probability DistributionSho Pin TanNo ratings yet
- Econometrics I Final Examination Summer Term 2013, July 26, 2013Document9 pagesEconometrics I Final Examination Summer Term 2013, July 26, 2013ECON1717No ratings yet
- MS8 IGNOU MBA Assignment 2009Document6 pagesMS8 IGNOU MBA Assignment 2009rakeshpipadaNo ratings yet
- Exercise On T Test and Correlation FinalDocument10 pagesExercise On T Test and Correlation FinalGi NaNo ratings yet
- Solution: Bernoulli Trials & Binomial DistributionsDocument9 pagesSolution: Bernoulli Trials & Binomial DistributionsGladis TorresNo ratings yet
- Download Study Resources for Essentials of Statistics for Business and Economics 7th Edition Anderson Solutions ManualDocument47 pagesDownload Study Resources for Essentials of Statistics for Business and Economics 7th Edition Anderson Solutions Manualkrisdokayas100% (4)
- Exercise Sheet 2Document4 pagesExercise Sheet 2Florence ManirambonaNo ratings yet
- 2ND LP PreDocument26 pages2ND LP PreAngelu bonaganNo ratings yet
- Lekcija 5 - VjerovatnocaDocument60 pagesLekcija 5 - VjerovatnocaАнђела МијановићNo ratings yet
- Get Statistics for Business and Economics 12th Edition Anderson Solutions Manual Free All Chapters AvailableDocument51 pagesGet Statistics for Business and Economics 12th Edition Anderson Solutions Manual Free All Chapters Availablexabisaopurba100% (3)
- Statistics ProblemDocument8 pagesStatistics ProblemSanjanaDostiKarunggiNo ratings yet
- FIN 2017.s1 ANSWERSDocument2 pagesFIN 2017.s1 ANSWERSfarrellezrabaswaraNo ratings yet
- Random Variable & Probability DistributionDocument48 pagesRandom Variable & Probability DistributionRISHAB NANGIANo ratings yet
- Quantitative Methods For BusinessDocument16 pagesQuantitative Methods For BusinessabhirejanilNo ratings yet
- Exercises 18 Apr - With SolutionsDocument6 pagesExercises 18 Apr - With Solutionsnonloso partedueNo ratings yet
- Assignment 2 AnswersDocument18 pagesAssignment 2 AnswersIvonne NavasNo ratings yet
- Puting AssignmentDocument8 pagesPuting Assignmentcharlay25No ratings yet
- Hypothesis Testing Using Z-Test, T-Test, Linear - Correlation and Regression, and Chi-Square DistributionDocument22 pagesHypothesis Testing Using Z-Test, T-Test, Linear - Correlation and Regression, and Chi-Square DistributionAlleli AspiliNo ratings yet
- Business Statistics ABFinal With AnswerDocument9 pagesBusiness Statistics ABFinal With Answer윤준서No ratings yet
- Let's ApplyDocument5 pagesLet's ApplyJasmin Dianne RodicolNo ratings yet
- Chapter 5Document38 pagesChapter 5Prasath Pillai Raja VikramanNo ratings yet
- Mas291 Ass2 Se1835 He172637 TranngocdoanhDocument15 pagesMas291 Ass2 Se1835 He172637 TranngocdoanhDoanh TranNo ratings yet
- Class X: Bivariate Association & The Chi Square TestDocument27 pagesClass X: Bivariate Association & The Chi Square TestNikita LotwalaNo ratings yet
- Newbold Stat7 Ism 06Document21 pagesNewbold Stat7 Ism 06tawamagconNo ratings yet
- Review Final2021Document18 pagesReview Final2021sports8854346No ratings yet
- U1 4-RVDistributionsDocument36 pagesU1 4-RVDistributionseugene louie ibarraNo ratings yet
- Assignment - Week 10Document6 pagesAssignment - Week 10Nabella Roma DesiNo ratings yet
- A Random Sample of Eight Drivers Insured With A Company and Having Similar Auto Insurance Policies Was SelectedDocument7 pagesA Random Sample of Eight Drivers Insured With A Company and Having Similar Auto Insurance Policies Was SelectedNicole Gayeta100% (1)
- AssignmentDocument4 pagesAssignmentlopenmalinNo ratings yet
- Active Learning Task 8Document7 pagesActive Learning Task 8haptyNo ratings yet
- Assignment 5Document6 pagesAssignment 5sandeep BhanotNo ratings yet
- MATH 230 Probability: Exercise 6: S. Bashir Spring, 2019Document10 pagesMATH 230 Probability: Exercise 6: S. Bashir Spring, 2019Holq PapiNo ratings yet
- Statistics Answers-3Document8 pagesStatistics Answers-3darlingcharming4000No ratings yet
- Eugene Ngoya-Mss 242 AssignmentDocument8 pagesEugene Ngoya-Mss 242 AssignmentEugene NgoyaNo ratings yet
- Logistic RegressionDocument49 pagesLogistic Regressiontamim habybyNo ratings yet
- Lecture 7 ClassificationDocument52 pagesLecture 7 Classificationgeetha.rNo ratings yet
- 11 Final SolutionsDocument19 pages11 Final Solutionsterrygoh6972100% (1)
- Hw4-Sol KBDocument7 pagesHw4-Sol KBAnonymous LSu67KNo ratings yet
- Statistical Data Analysis-Descriptive and CorrelationalDocument11 pagesStatistical Data Analysis-Descriptive and CorrelationalKang MaeNo ratings yet
- Quantitative Methods For BusinessDocument14 pagesQuantitative Methods For BusinessabhirejanilNo ratings yet
- Trigonometric Ratios to Transformations (Trigonometry) Mathematics E-Book For Public ExamsFrom EverandTrigonometric Ratios to Transformations (Trigonometry) Mathematics E-Book For Public ExamsRating: 5 out of 5 stars5/5 (1)
- Zometric Qtools Features ListDocument1 pageZometric Qtools Features ListRakesh JangraNo ratings yet
- Final Exam in StatsDocument6 pagesFinal Exam in StatsPrincess MirandaNo ratings yet
- Bayesian NetworksDocument24 pagesBayesian NetworksMishaal HajianiNo ratings yet
- Lesson 2: Simple Comparative ExperimentsDocument8 pagesLesson 2: Simple Comparative ExperimentsIrya MalathamayaNo ratings yet
- Section 1: Introducing The Binomial DistributionDocument6 pagesSection 1: Introducing The Binomial DistributionVarul SinhaNo ratings yet
- Chapter 7 TriolaDocument28 pagesChapter 7 TriolaMonita RiskiNo ratings yet
- 2 Testing Hypothesis Levin Rubin Chpt8Document11 pages2 Testing Hypothesis Levin Rubin Chpt8ashokgroy121100% (1)
- Statistics For Business STAT130: Unit 3: Sampling DistributionsDocument24 pagesStatistics For Business STAT130: Unit 3: Sampling DistributionsUsmanNo ratings yet
- STAT001 Module 5 Mean SD of Sampling DistributionDocument32 pagesSTAT001 Module 5 Mean SD of Sampling DistributionJk JeonNo ratings yet
- Jurnal Skripsi Sapto Adi NugrohoDocument35 pagesJurnal Skripsi Sapto Adi NugrohoSusilo SiloNo ratings yet
- Mai 4.10 Binomial DistributionDocument10 pagesMai 4.10 Binomial DistributionPravar TrivediNo ratings yet
- Download Full The Myth of Statistical Inference Michael C Acree PDF All ChaptersDocument50 pagesDownload Full The Myth of Statistical Inference Michael C Acree PDF All Chaptershumpokdenule100% (1)
- PT HypothesisDocument6 pagesPT HypothesisRainzel Faith P. CASTILLONo ratings yet
- Aux Lecture NotesDocument9 pagesAux Lecture NotesJuanQuinteroNo ratings yet
- MpaDocument2 pagesMpaMCPS Operations BranchNo ratings yet
- Math 131Document1 pageMath 131azizaldebasi1No ratings yet
- A First Course in Machine Learning - ErrataDocument2 pagesA First Course in Machine Learning - Erratasynchronicity27No ratings yet
- Choosing A Statistical TestDocument2 pagesChoosing A Statistical TestWifi Sa bahayNo ratings yet
- Stat FitDocument135 pagesStat FitCarlos Angel Vicente RodríguezNo ratings yet
- m248 Block CDocument123 pagesm248 Block CSaad MehmoodNo ratings yet
- Inferential StatisticsDocument29 pagesInferential StatisticsLUMABAD CENYERNNo ratings yet
- MANOVADocument33 pagesMANOVAVishnu Prakash SinghNo ratings yet
- Octagon PT Calendar 2024Document7 pagesOctagon PT Calendar 2024TPM BMPNo ratings yet
- Soil Dynamics and Earthquake Engineering: Shima Taheri, Reza Karami MohammadiDocument20 pagesSoil Dynamics and Earthquake Engineering: Shima Taheri, Reza Karami MohammadiSumit SahaNo ratings yet
- Statistics 1 Discrete Random Variables Past ExaminationDocument24 pagesStatistics 1 Discrete Random Variables Past ExaminationAbid FareedNo ratings yet
- Hasil SpssDocument4 pagesHasil SpssAini Agispa AliNo ratings yet
- Statistics 2012-13Document87 pagesStatistics 2012-13Kamran Khan ShaikhNo ratings yet
- Bivariate Analysis PDFDocument12 pagesBivariate Analysis PDFHygienix FsdNo ratings yet