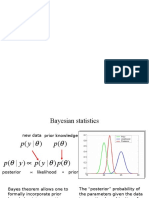
Lecture 3:introduction To Data Analysis and Machine Learning
Lecture 3:introduction To Data Analysis and Machine Learning
Download as pdf or txt
You might also like
- Masters Module HandbookDocument98 pagesMasters Module HandbookRezwan Siddiqui RaihanNo ratings yet
- Basics of Probabilistic/Bayesian Modeling and Parameter EstimationDocument21 pagesBasics of Probabilistic/Bayesian Modeling and Parameter EstimationYash VarunNo ratings yet
- A BAYESIAN APPROACH TO NONPARAMETRIC TEST PROBLEMSDocument16 pagesA BAYESIAN APPROACH TO NONPARAMETRIC TEST PROBLEMSphictionfilmNo ratings yet
- Probabilistic Models For Supervised Learning: Piyush Rai Introduction To Machine Learning (CS771A)Document32 pagesProbabilistic Models For Supervised Learning: Piyush Rai Introduction To Machine Learning (CS771A)satyajitresearchictNo ratings yet
- An Introduction To Objective Bayesian Statistics PDFDocument69 pagesAn Introduction To Objective Bayesian Statistics PDFWaterloo Ferreira da SilvaNo ratings yet
- Chapter 9 Data MiningDocument147 pagesChapter 9 Data MiningYUTRYU8TYURTNo ratings yet
- AUZIPREDocument12 pagesAUZIPRENADASHREE BOSE 2248138No ratings yet
- BR 2Document36 pagesBR 2muralidharanNo ratings yet
- Data Science Cheat SheetDocument10 pagesData Science Cheat SheetZicky Principal RamadhanaNo ratings yet
- Bde Unit 1Document46 pagesBde Unit 1Mielek TathagatNo ratings yet
- Asr 013Document16 pagesAsr 013qiuyihuang1999No ratings yet
- NotesDocument520 pagesNotesdaselknamNo ratings yet
- Most Compact and Complete Data Science Cheat Sheet 1672981093Document10 pagesMost Compact and Complete Data Science Cheat Sheet 1672981093Mahesh KotnisNo ratings yet
- AIC Tutorial - HuDocument19 pagesAIC Tutorial - HujitenparekhNo ratings yet
- Forecasting Time Series With Missing Data Using Holt's ModelDocument9 pagesForecasting Time Series With Missing Data Using Holt's ModelJuan Francisco Durango GrisalesNo ratings yet
- Sparse Principal Component AnalysisDocument23 pagesSparse Principal Component Analysis方鑫然No ratings yet
- Sparse Principal Component AnalysisDocument30 pagesSparse Principal Component AnalysisInSilicoBiology BiologyNo ratings yet
- What Is Data Science? Probability Overview Descriptive StatisticsDocument10 pagesWhat Is Data Science? Probability Overview Descriptive StatisticsMauricioRojasNo ratings yet
- CDA CourseDocument196 pagesCDA CoursekarthyfsuNo ratings yet
- Statistics I: Introduction and Distributions of Sampling StatisticsDocument22 pagesStatistics I: Introduction and Distributions of Sampling Statisticstamer_aciNo ratings yet
- Dempster-Shafer's Basic Probability Assignment Based On Fuzzy Membership FunctionsDocument9 pagesDempster-Shafer's Basic Probability Assignment Based On Fuzzy Membership Functionshenri joel jrNo ratings yet
- Lecture 8: Bayesian Estimation of Parameters in State Space ModelsDocument33 pagesLecture 8: Bayesian Estimation of Parameters in State Space ModelsTrinh VtnNo ratings yet
- Data Analytics Unit 3 NotesDocument28 pagesData Analytics Unit 3 NotesSmash art boy100% (1)
- MCMC Bayes PDFDocument27 pagesMCMC Bayes PDFMichael TadesseNo ratings yet
- Model Fitting and Error Estimation: BSR 1803 Systems Biology: Biomedical ModelingDocument34 pagesModel Fitting and Error Estimation: BSR 1803 Systems Biology: Biomedical ModelingFilipe Gama FreireNo ratings yet
- Machine Learning - Unit 2Document104 pagesMachine Learning - Unit 2sandtNo ratings yet
- Mathematics 05 00005 PDFDocument17 pagesMathematics 05 00005 PDFTaher JelleliNo ratings yet
- ProceedingsDocument13 pagesProceedingsmeatulNo ratings yet
- Principal Component Analysis As A Tool FDocument13 pagesPrincipal Component Analysis As A Tool FMichael StitchNo ratings yet
- PrincipalComponentAnalysisofBinaryData - Applicationstoroll Call AnalysisDocument32 pagesPrincipalComponentAnalysisofBinaryData - Applicationstoroll Call Analysisshree_sahaNo ratings yet
- Introduction Statistics Imperial College LondonDocument474 pagesIntroduction Statistics Imperial College Londoncmtinv50% (2)
- Little Niss Oct1014Document40 pagesLittle Niss Oct1014José SánchezNo ratings yet
- Content PDFDocument61 pagesContent PDFAndika SaputraNo ratings yet
- Bayesian Analysis of Extreme Operational Losses: Chyng-Lan LiangDocument17 pagesBayesian Analysis of Extreme Operational Losses: Chyng-Lan LiangOnkar BagariaNo ratings yet
- Modern Bayesian EconometricsDocument100 pagesModern Bayesian Econometricsseph8765No ratings yet
- Carlo Part 6 - Hierarchical Bayesian Modeling Lecture - Notes - 6Document12 pagesCarlo Part 6 - Hierarchical Bayesian Modeling Lecture - Notes - 6Mark AlexandreNo ratings yet
- Nonlinear Least SQ: Queensland 4001, AustraliaDocument17 pagesNonlinear Least SQ: Queensland 4001, AustraliaAbdul AzizNo ratings yet
- M - F P I: Onetary Iscal Olicy NteractionsDocument21 pagesM - F P I: Onetary Iscal Olicy NteractionsJoab Dan Valdivia CoriaNo ratings yet
- Maximum Likelihood Estimation - StokastikDocument8 pagesMaximum Likelihood Estimation - StokastikKamalakar SreevatasalaNo ratings yet
- James-Stein Type Estimators in Beta Regression Model Simulation and ApplicationDocument20 pagesJames-Stein Type Estimators in Beta Regression Model Simulation and ApplicationFatih KIZILASLANNo ratings yet
- 6 Dimension Reduction TheoryDocument18 pages6 Dimension Reduction TheoryBhaskar MulikNo ratings yet
- Introduction To Bayesian Learning: Aaron Hertzmann University of Toronto SIGGRAPH 2004 TutorialDocument141 pagesIntroduction To Bayesian Learning: Aaron Hertzmann University of Toronto SIGGRAPH 2004 TutorialvivekumNo ratings yet
- Fuzzy 5Document12 pagesFuzzy 5Basma ElNo ratings yet
- Introduction To Bayesian Methods With An ExampleDocument25 pagesIntroduction To Bayesian Methods With An ExampleLucas RobertoNo ratings yet
- Pattern Classification: All Materials in These Slides Were Taken FromDocument18 pagesPattern Classification: All Materials in These Slides Were Taken FromavivroNo ratings yet
- Information TheoryDocument114 pagesInformation TheoryJoshua DuffyNo ratings yet
- The Pad& Method For Computing The Matrix Exponential: North-HollanoDocument20 pagesThe Pad& Method For Computing The Matrix Exponential: North-Hollanopeloduro1010No ratings yet
- A Starting Point Strategy For Nonlinear Interior Methods: Applied Mathematics LettersDocument8 pagesA Starting Point Strategy For Nonlinear Interior Methods: Applied Mathematics LettersValentino LunardiNo ratings yet
- Bayesian Statistics 01Document22 pagesBayesian Statistics 01Kyungsook Park100% (1)
- Goodness of Fit Tests: Do These Data Correspond Reasonably To The Proportions 1:2:1?Document14 pagesGoodness of Fit Tests: Do These Data Correspond Reasonably To The Proportions 1:2:1?MulyadinNo ratings yet
- Objective Bayesian PDFDocument35 pagesObjective Bayesian PDFYuda SaifurrahmanNo ratings yet
- NOISEDocument14 pagesNOISEAli SaadNo ratings yet
- Power Load Forecasting Based On Multi-Task Gaussian ProcessDocument6 pagesPower Load Forecasting Based On Multi-Task Gaussian ProcessKhalid AlHashemiNo ratings yet
- MD Presentation2Document29 pagesMD Presentation2Fathi MusaNo ratings yet
- CET Vol69Document6 pagesCET Vol69minh leNo ratings yet
- Numerical Methods and Software For Sensitivity Analysis of Differential-Algebraic SystemsDocument23 pagesNumerical Methods and Software For Sensitivity Analysis of Differential-Algebraic SystemsFCNo ratings yet
- An Introduction To Bayesian Statistics and MCMC MethodsDocument69 pagesAn Introduction To Bayesian Statistics and MCMC MethodsIssaka MAIGANo ratings yet
- Ae5b PDFDocument17 pagesAe5b PDFNader FaroukNo ratings yet
- Yoke Calibration ProcedureDocument1 pageYoke Calibration ProcedureArjun Rawat100% (3)
- Shape FuncDocument33 pagesShape FuncSAMNo ratings yet
- ARITHMETIC ProgressionDocument4 pagesARITHMETIC ProgressionSANDEEP SINGHNo ratings yet
- Assignment Problem - PPTX - CompressedDocument30 pagesAssignment Problem - PPTX - Compressedaaravkalia54No ratings yet
- Finite Element Simulation of Solidification ProblemsDocument32 pagesFinite Element Simulation of Solidification ProblemsNicolas FernandezNo ratings yet
- Answer For Assignment8Document10 pagesAnswer For Assignment8xinzhiNo ratings yet
- Statistical Analysis For ResearchDocument5 pagesStatistical Analysis For ResearchRabbi HasanNo ratings yet
- MAT 1327 Lecture 1 FilledDocument5 pagesMAT 1327 Lecture 1 FilledianNo ratings yet
- Lectures On Lipschitz AnalysisDocument77 pagesLectures On Lipschitz Analysistoby0630No ratings yet
- On Problem Identification and HypothesisDocument57 pagesOn Problem Identification and HypothesisKusum Bajaj75% (8)
- Constant Strain Triangle (CST)Document32 pagesConstant Strain Triangle (CST)Mostafa AdilNo ratings yet
- Lect2 AgmDocument63 pagesLect2 AgmShu Shujaat LinNo ratings yet
- HypothesisDocument61 pagesHypothesisRajesh Dwivedi100% (1)
- Dempsey - Comeau - Anxiety 2017Document31 pagesDempsey - Comeau - Anxiety 2017Mario Alberto QuintanarNo ratings yet
- Chapter 8 SolutionDocument10 pagesChapter 8 Solution王奕凡No ratings yet
- Solutions Manual: From: Solutions Books Date: Fri, 10 Feb 2012 11:53:24 0800 (PST)Document12 pagesSolutions Manual: From: Solutions Books Date: Fri, 10 Feb 2012 11:53:24 0800 (PST)Usman Sabir8% (13)
- Mark Vincent Navarro - AssignmentDocument11 pagesMark Vincent Navarro - AssignmentMARK VINCENT NAVARRONo ratings yet
- ASP Guideline - ME05Document19 pagesASP Guideline - ME05Shan rNo ratings yet
- Chapter 10 SolutionsDocument11 pagesChapter 10 SolutionsNgọc YếnNo ratings yet
- Lab No 3Document4 pagesLab No 3Farhan Khan NiaZiNo ratings yet
- 2-0-Solution To Differential EquationsDocument5 pages2-0-Solution To Differential EquationsGedeon BetosNo ratings yet
- (Dimensions of Philosophy Series) Coleman, Jules L. - Murphy, Jeffrey G - Philosophy of Law - An Introduction To Jurisprudence-Westview Press (1990)Document257 pages(Dimensions of Philosophy Series) Coleman, Jules L. - Murphy, Jeffrey G - Philosophy of Law - An Introduction To Jurisprudence-Westview Press (1990)BD KNOWLEDGE HOUSENo ratings yet
- UAL BRIEF 5 Unit 8Document5 pagesUAL BRIEF 5 Unit 8miskinmusic123No ratings yet
- Continuous Random VariableDocument31 pagesContinuous Random VariableDipak Kumar PatelNo ratings yet
- Semester Courses of M.A/M.Sc. (Mathematics)Document38 pagesSemester Courses of M.A/M.Sc. (Mathematics)Abhay Pratap SharmaNo ratings yet
- Stefanica 2019 - VolatilityDocument29 pagesStefanica 2019 - VolatilitypukkapadNo ratings yet
- Introductory Mathematics-Part ADocument77 pagesIntroductory Mathematics-Part AVlad ChalapcoNo ratings yet
- MCR3U-Unit 1 AssignmentDocument3 pagesMCR3U-Unit 1 AssignmentKhaled NajjarNo ratings yet