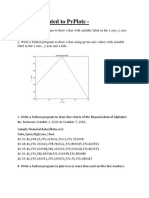
R Lab File Deepak
R Lab File Deepak
Download as docx, pdf, or txt
You might also like
- Challenges and Scope of Data Science ProjectDocument21 pagesChallenges and Scope of Data Science ProjectMihir PesswaniNo ratings yet
- 2048 Game On Python Project SynopsisDocument4 pages2048 Game On Python Project SynopsisRhody FlashNo ratings yet
- RSTUDIODocument44 pagesRSTUDIOsamarth agarwalNo ratings yet
- Cailin Chen Question 9: (10 Points)Document5 pagesCailin Chen Question 9: (10 Points)Manuel BoahenNo ratings yet
- 4-5. Problems On Risk & ReturnDocument1 page4-5. Problems On Risk & ReturnPRANAV BHARARANo ratings yet
- Ameet Sao Research PDFDocument6 pagesAmeet Sao Research PDFReshma RameshNo ratings yet
- Macro Economics For Business DecisionsDocument86 pagesMacro Economics For Business DecisionsViraja GuruNo ratings yet
- Classical CryptoDocument16 pagesClassical CryptoMusic LandNo ratings yet
- A434234317 16857 30 2018 GraphsDocument51 pagesA434234317 16857 30 2018 GraphsSai TejaNo ratings yet
- I M Com QT Final On16march2016Document166 pagesI M Com QT Final On16march2016Khandaker Sakib Farhad0% (1)
- Project Report: Data Analysis System For Behavioural Biometric Authentication (Keystroke Dynamics)Document46 pagesProject Report: Data Analysis System For Behavioural Biometric Authentication (Keystroke Dynamics)Evin JoyNo ratings yet
- Mid - Real World Case Scenario #2Document4 pagesMid - Real World Case Scenario #2Eliezer RabaNo ratings yet
- Graphs, Hashing, Sorting, Files: Definitions: Graph, Vertices, EdgesDocument24 pagesGraphs, Hashing, Sorting, Files: Definitions: Graph, Vertices, EdgesMohan BiradarNo ratings yet
- R Notes-Unit-3Document65 pagesR Notes-Unit-3Anitej ANo ratings yet
- Unit 3 - Data VisualizationDocument64 pagesUnit 3 - Data VisualizationVivuEtukuruNo ratings yet
- R-Programming NotesDocument33 pagesR-Programming Notesnivn26393100% (1)
- Stock Valuation ProblemsDocument1 pageStock Valuation ProblemsPRANAV BHARARANo ratings yet
- Venn Diagrams: Database PrinciplesDocument13 pagesVenn Diagrams: Database PrincipleslucdahNo ratings yet
- Big Data and Data ScienceDocument6 pagesBig Data and Data ScienceAishwarya JagtapNo ratings yet
- Financial Analytics 4Document9 pagesFinancial Analytics 4Ram patharvatNo ratings yet
- Lecture NotesDocument82 pagesLecture NotesSarah Edwards100% (1)
- Indusind Bank PresentionDocument12 pagesIndusind Bank PresentionSaurav SharanNo ratings yet
- Question and Answers For PyplotsDocument11 pagesQuestion and Answers For PyplotsPrakhar KumarNo ratings yet
- R Studio ProjectDocument8 pagesR Studio ProjectShreya NandanNo ratings yet
- R LnaguagerDocument38 pagesR LnaguagerdwrreNo ratings yet
- Capstone Project Power BIDocument8 pagesCapstone Project Power BIKshitij PlNo ratings yet
- Unit 5 - Testing of Hypothesis - SLMDocument46 pagesUnit 5 - Testing of Hypothesis - SLMVineet SharmaNo ratings yet
- Discriminant Analysis Chapter-SevenDocument7 pagesDiscriminant Analysis Chapter-SevenSoloymanNo ratings yet
- St. Paul University Philippines Graduate School: A Course Presentation in StatisticsDocument103 pagesSt. Paul University Philippines Graduate School: A Course Presentation in StatisticsRoselle Mae BinolocNo ratings yet
- Course Content - Advance Excel & Macros PDFDocument7 pagesCourse Content - Advance Excel & Macros PDFUdayNo ratings yet
- Python FlaskDocument11 pagesPython FlaskPoonam AgrawalNo ratings yet
- Artificial Neural Networks Kluniversity Course HandoutDocument18 pagesArtificial Neural Networks Kluniversity Course HandoutHarish ParuchuriNo ratings yet
- Relational ModelDocument20 pagesRelational ModelMag CreationNo ratings yet
- 4.1 Point and Interval EstimationDocument30 pages4.1 Point and Interval EstimationShamuel AlasNo ratings yet
- Probability and StatisticsDocument34 pagesProbability and StatisticsMuhammad AbdullahNo ratings yet
- Assignment-Based Subjective Questions/AnswersDocument3 pagesAssignment-Based Subjective Questions/AnswersrahulNo ratings yet
- Unit 6 GRAPHDocument75 pagesUnit 6 GRAPHDivya ReddyNo ratings yet
- 4.1.gaming TheoryDocument59 pages4.1.gaming Theoryusnish banerjeeNo ratings yet
- Data Science Interview QuestionsDocument31 pagesData Science Interview QuestionsAlok ThakurNo ratings yet
- Research Paperon HRAnalyticsDocument12 pagesResearch Paperon HRAnalyticsMrunalini KhandareNo ratings yet
- Module 1-1Document38 pagesModule 1-1Aakash RajputNo ratings yet
- Unit 1 Programming in C and Primitive Data TypesDocument26 pagesUnit 1 Programming in C and Primitive Data Typesjhaa98676No ratings yet
- Relational NotationDocument3 pagesRelational NotationTweetrudi WhyteNo ratings yet
- PROJECT REPORT Regression Analysis SPECU PDFDocument8 pagesPROJECT REPORT Regression Analysis SPECU PDFVICKY GAURAVNo ratings yet
- Introduction To AI IBM (COURSERA)Document2 pagesIntroduction To AI IBM (COURSERA)Ritika MondalNo ratings yet
- Assignment I Data AnalyticsDocument3 pagesAssignment I Data Analyticsnalluri_08No ratings yet
- Final Project - Regression ModelsDocument35 pagesFinal Project - Regression ModelsCaio Henrique Konyosi Miyashiro100% (1)
- Crime Prediction in Nigeria's Higer InstitutionsDocument13 pagesCrime Prediction in Nigeria's Higer InstitutionsBenjamin BalaNo ratings yet
- Frugal Testing AssignmentDocument5 pagesFrugal Testing Assignmentnavjot singhNo ratings yet
- 1st Unit NotesDocument22 pages1st Unit NotesJazzNo ratings yet
- Data Science NotesDocument36 pagesData Science Notesmdluffyyy300No ratings yet
- Series1 SolDocument6 pagesSeries1 SolPoonam RavNo ratings yet
- Qa PDFDocument30 pagesQa PDFJoshna SambaNo ratings yet
- Module - 4 Bayeian LearningDocument44 pagesModule - 4 Bayeian LearningAkhila RNo ratings yet
- Business Anaytics Unit 1Document37 pagesBusiness Anaytics Unit 1K.V.T SNo ratings yet
- Ss Project With PythonDocument9 pagesSs Project With PythonBhola KambleNo ratings yet
- Data Mining - IMT Nagpur-ManishDocument82 pagesData Mining - IMT Nagpur-ManishSumeet GuptaNo ratings yet
- Dealing With Missing Data in Python PandasDocument14 pagesDealing With Missing Data in Python PandasSello100% (1)
- Chapter 3Document31 pagesChapter 3AntoNo ratings yet
- Day 2 TaskDocument4 pagesDay 2 TaskYaathriganNo ratings yet
- DS3000 End User Demo GuideDocument47 pagesDS3000 End User Demo GuideSenthilkumar MuthusamyNo ratings yet
- Threat Protection - Windows 10Document3,502 pagesThreat Protection - Windows 10tetkaCNo ratings yet
- CytometerDocument4 pagesCytometerDJNo ratings yet
- Maxava MaxView Lite Guide1Document64 pagesMaxava MaxView Lite Guide1Anonymous d4Z4KSzRnxNo ratings yet
- Arduino Guide Using MPU-6050 and nRF24L01: Digital Human Research CenterDocument29 pagesArduino Guide Using MPU-6050 and nRF24L01: Digital Human Research CenterusmanNo ratings yet
- UsbFix ReportDocument2 pagesUsbFix Reportamira TAHRAOUINo ratings yet
- The Complete Collection of Instructions That Are Understood by A CPU Is Called Instruction Set. - It Has Its Own Formats and ElementsDocument17 pagesThe Complete Collection of Instructions That Are Understood by A CPU Is Called Instruction Set. - It Has Its Own Formats and ElementsGebrie BeleteNo ratings yet
- Part 1-Tutorial 1-AnswersDocument15 pagesPart 1-Tutorial 1-AnswersXot OngNo ratings yet
- Exception Handling in PythonDocument12 pagesException Handling in PythonSwayam ShrikondwarNo ratings yet
- Android Studio Flashlight App BasicDocument12 pagesAndroid Studio Flashlight App BasicPhilip100% (1)
- Introduction To Database Management SystemDocument26 pagesIntroduction To Database Management SystemDharshanNo ratings yet
- CookiessssDocument28 pagesCookiessssCasianNo ratings yet
- Configuring EPL Services On An Ethernet Switching BoardDocument10 pagesConfiguring EPL Services On An Ethernet Switching BoardSery ArthurNo ratings yet
- Kendriya Vidyalaya Vikaspuri (1 Shift) : Submitted By: Ravi Kumar SharmaDocument44 pagesKendriya Vidyalaya Vikaspuri (1 Shift) : Submitted By: Ravi Kumar SharmaANSHNo ratings yet
- Rugged, Ultra Low Power I.Mx6 Sbc/ComDocument2 pagesRugged, Ultra Low Power I.Mx6 Sbc/ComTaruna FandanuNo ratings yet
- SM C900F Direy 6 - AsdqqDocument14 pagesSM C900F Direy 6 - Asdqqlaaalof9113No ratings yet
- Python by Example Book 2 (Data Manipulation and Analysis)Document105 pagesPython by Example Book 2 (Data Manipulation and Analysis)Aamir MehmoodNo ratings yet
- Bhuvnesh Resum-1Document3 pagesBhuvnesh Resum-1Prashant KumarNo ratings yet
- Flash MemoryDocument68 pagesFlash Memoryshiva100% (1)
- 342.01 Win10 Win8 Win7 Winvista Desktop Release NotesDocument47 pages342.01 Win10 Win8 Win7 Winvista Desktop Release NotesShafin JahinNo ratings yet
- GA-EP45T-UD3LR: User's ManualDocument112 pagesGA-EP45T-UD3LR: User's Manualroni albuquerqueNo ratings yet
- 02 Java Syntax and Class ReviewDocument38 pages02 Java Syntax and Class ReviewSanthanalakshmi SelvakumarNo ratings yet
- Excel - Can Advanced Filter Criteria Be in The VBA Rather Than A Range? - Stack OverflowDocument1 pageExcel - Can Advanced Filter Criteria Be in The VBA Rather Than A Range? - Stack OverflowvaskoreNo ratings yet
- Connections For Supported MMDVM BoardsDocument1 pageConnections For Supported MMDVM BoardsFABIANNo ratings yet
- Lab 2: Notepad Application: M.Sc. Bui Tan LocDocument8 pagesLab 2: Notepad Application: M.Sc. Bui Tan LocPhat QuyNo ratings yet
- Om2007 MP MSMQ 5.0Document37 pagesOm2007 MP MSMQ 5.0OscarGomezNo ratings yet
- Mac ForensicsDocument72 pagesMac ForensicsScridbDaveNo ratings yet
- Purchase Order Lines - 638029674650719856Document9 pagesPurchase Order Lines - 638029674650719856Anoop PurohitNo ratings yet