Comph SQL (G9)
Comph SQL (G9)
Download as pdf or txt
You might also like
- DSA456 Midterm Radu PDFDocument10 pagesDSA456 Midterm Radu PDFnavneetkaur12482No ratings yet
- Database Assignment 2 WorksheetDocument3 pagesDatabase Assignment 2 WorksheetMatthew ImpembaNo ratings yet
- AWS Certified Data Analytics - Specialty Exam Guide - v1.0!08!23-2019 - FINALDocument2 pagesAWS Certified Data Analytics - Specialty Exam Guide - v1.0!08!23-2019 - FINALNaga Balaram-pandu0% (1)
- GATE - Ques Set 3Document18 pagesGATE - Ques Set 3rahulyadavsingaporeNo ratings yet
- Assignment 2 DBMS January 2024Document10 pagesAssignment 2 DBMS January 2024no.reply15203No ratings yet
- Assignment 3 NPTEL DBMS January 2024Document10 pagesAssignment 3 NPTEL DBMS January 2024no.reply15203No ratings yet
- SQL IvDocument14 pagesSQL IvKrishnendu RarhiNo ratings yet
- GATE Ques Set 2Document14 pagesGATE Ques Set 2rahulyadavsingaporeNo ratings yet
- dbms (1)Document13 pagesdbms (1)pragya pandeyNo ratings yet
- Week 2 SolutionDocument10 pagesWeek 2 SolutionbalainsaiNo ratings yet
- 2nd UnitDocument4 pages2nd Unitapi-392674726No ratings yet
- 2020A FE AM QuestionDocument29 pages2020A FE AM Questionaungyezaw.devNo ratings yet
- Dbms GateDocument43 pagesDbms GateraniNo ratings yet
- DBMSDPP12 by Vijay Agarwal SirDocument16 pagesDBMSDPP12 by Vijay Agarwal SirAveen RanjanNo ratings yet
- CS XII PB2 Silchar QPDocument10 pagesCS XII PB2 Silchar QPklaus MikaelsonNo ratings yet
- BSCS SolutionDocument5 pagesBSCS SolutionjifferentNo ratings yet
- Cs606 Final Term Quizez and MCQZ Solved With ReferDocument18 pagesCs606 Final Term Quizez and MCQZ Solved With ReferJani JanNo ratings yet
- 2017A FE AM QuestionDocument30 pages2017A FE AM QuestionShah AlamNo ratings yet
- Assignment 3Document11 pagesAssignment 3Shivam GaikwadNo ratings yet
- Database Management System: Assignment 1: August 14, 2018Document10 pagesDatabase Management System: Assignment 1: August 14, 2018Swastik swarup meherNo ratings yet
- April 2005 WithsloutionDocument21 pagesApril 2005 Withsloutionapi-3755462No ratings yet
- Week-2 Assignment-2 DBMS SolnDocument11 pagesWeek-2 Assignment-2 DBMS SolnRoshanNo ratings yet
- Mid Term Practice PaperDocument10 pagesMid Term Practice Papermaterialstudy2400No ratings yet
- Mid ADocument9 pagesMid AKrishnaNo ratings yet
- ∏ (Σ (P×R) ) −∏ (Σ (Q×R) ) 2. Q: R⋈ (Σ (S) ) : Σ (R⋈S) B) Σ (Rlojs) Rloj (Σ (S) ) D) Σ (R) LojsDocument6 pages∏ (Σ (P×R) ) −∏ (Σ (Q×R) ) 2. Q: R⋈ (Σ (S) ) : Σ (R⋈S) B) Σ (Rlojs) Rloj (Σ (S) ) D) Σ (R) LojsKrishnendu RarhiNo ratings yet
- Final ExamDocument16 pagesFinal ExamobsinaafilmakuushNo ratings yet
- Dbms It GateDocument35 pagesDbms It GateMurali Mohan ReddyNo ratings yet
- CS - QP - Xii - T1 - 2023-24 CSDocument8 pagesCS - QP - Xii - T1 - 2023-24 CSjhakas123456No ratings yet
- CMPT-354 D1 Fall 2008 Instructor: Martin Ester TA: Gustavo Frigo Final Exam With SolutionDocument7 pagesCMPT-354 D1 Fall 2008 Instructor: Martin Ester TA: Gustavo Frigo Final Exam With SolutionlcoNo ratings yet
- Quiz-Ans Iitg Ma321Document5 pagesQuiz-Ans Iitg Ma321TusharbhutadNo ratings yet
- DBIFEDocument50 pagesDBIFEHoang Trung Tin (K18 HCM)No ratings yet
- Assignment DBMSDocument7 pagesAssignment DBMShetro2craperNo ratings yet
- Dbms All 8 AssignmentsDocument33 pagesDbms All 8 AssignmentsPrathamesh MoreNo ratings yet
- Cs 60Document80 pagesCs 60Sirsendu RoyNo ratings yet
- Unit Test I - Cs Answer KeyDocument7 pagesUnit Test I - Cs Answer KeyduckymomoNo ratings yet
- Latin Square DesignDocument10 pagesLatin Square DesignJay Ann Pasinao BerryNo ratings yet
- Sem 5 Put 2022-23Document8 pagesSem 5 Put 2022-23Jatin ChoudharyNo ratings yet
- Data Structures With C Jan 2014Document1 pageData Structures With C Jan 2014Prasad C MNo ratings yet
- InfyTQ Daily Test Questions On 19th Feb 2020Document14 pagesInfyTQ Daily Test Questions On 19th Feb 2020Phani PNo ratings yet
- 12th - QPAPER - Half Yearly 2023Document9 pages12th - QPAPER - Half Yearly 2023Deepti SharmaNo ratings yet
- Enrollment NoDocument5 pagesEnrollment Nosanjit kumarNo ratings yet
- Xii Comp Sci Pb-1 Qp-1 Hr 2024-25Document7 pagesXii Comp Sci Pb-1 Qp-1 Hr 2024-25royalmax.official19No ratings yet
- Assignment Week 1Document10 pagesAssignment Week 1DiamondNo ratings yet
- Question Bank - NewDocument20 pagesQuestion Bank - Newsri sai xeroxNo ratings yet
- 9.Compt Sc Ms Class Xii Isg Cpbe 2023Document25 pages9.Compt Sc Ms Class Xii Isg Cpbe 2023bvcbsecslabNo ratings yet
- Questions Set - 2Document8 pagesQuestions Set - 2Shobhit TiwariNo ratings yet
- Final ExaminationDocument3 pagesFinal ExaminationLinah RoseNo ratings yet
- Ex Nested ResamplingDocument4 pagesEx Nested Resamplingtoluei.s29No ratings yet
- IT3020 - Database SystemsDocument6 pagesIT3020 - Database Systemsjathurshanm3No ratings yet
- Assignment 1 DBMS JUL 2022Document11 pagesAssignment 1 DBMS JUL 2022somesh b.m.100% (1)
- CNS 2102 - Data Structures and Algorithms - July 2022Document5 pagesCNS 2102 - Data Structures and Algorithms - July 2022lisa.sayiNo ratings yet
- 2017S FE AM QuestionDocument28 pages2017S FE AM Questionfqnguyen8No ratings yet
- Python CodesDocument13 pagesPython Codes618Vishwajit PawarNo ratings yet
- Question 1. (8 Points) (A) Draw The Binary Search Tree That Is Created If The FollowingDocument12 pagesQuestion 1. (8 Points) (A) Draw The Binary Search Tree That Is Created If The FollowingInocent NdazaNo ratings yet
- BCADocument76 pagesBCAArvinder SinghNo ratings yet
- 06CS842 May - June 2010Document2 pages06CS842 May - June 2010Kali GunjanNo ratings yet
- 4431 Question PaperDocument2 pages4431 Question Papertanakaladharmesh68No ratings yet
- 194 Sorting in Linear Time: 8.2 Counting SortDocument3 pages194 Sorting in Linear Time: 8.2 Counting SortLizbeth AzNo ratings yet
- QP_univ_DS-set1Document6 pagesQP_univ_DS-set1Monica Bhavani MNo ratings yet
- Dbms S9Document7 pagesDbms S9Avinash SinghNo ratings yet
- Second Examination: Name: Netid: Lab Section (Day/Time)Document14 pagesSecond Examination: Name: Netid: Lab Section (Day/Time)sandbox7117No ratings yet
- Notes 220517 200054 2eaDocument16 pagesNotes 220517 200054 2eagjajNo ratings yet
- Transaction, Concurrency, RecoveryDocument7 pagesTransaction, Concurrency, RecoverygjajNo ratings yet
- CST308 - KQB KtuQbankDocument13 pagesCST308 - KQB KtuQbankgjajNo ratings yet
- CSL332 - KQB KtuQbankDocument6 pagesCSL332 - KQB KtuQbankgjajNo ratings yet
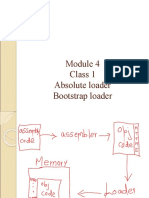
- Class 1 Absolute Loader Bootstrap LoaderDocument18 pagesClass 1 Absolute Loader Bootstrap LoadergjajNo ratings yet
- Module 3 - Complete ChapterDocument78 pagesModule 3 - Complete ChaptergjajNo ratings yet
- Mod 3 Class 4 - Machine Independent Assembler Features (Part 1)Document23 pagesMod 3 Class 4 - Machine Independent Assembler Features (Part 1)gjajNo ratings yet
- Mod 3 Class 1 - Machine Dependent Assembler Features (Part 1)Document12 pagesMod 3 Class 1 - Machine Dependent Assembler Features (Part 1)gjajNo ratings yet
- Macro Processor: (Type Text)Document25 pagesMacro Processor: (Type Text)gjajNo ratings yet
- Mod 3 Control Section and Program Linking: Chap 2Document20 pagesMod 3 Control Section and Program Linking: Chap 2gjajNo ratings yet
- DocumentDocument78 pagesDocumentgjajNo ratings yet
- Answer All Questions, Each Carries 3 Marks.: Reg No.: - NameDocument2 pagesAnswer All Questions, Each Carries 3 Marks.: Reg No.: - NamegjajNo ratings yet
- Macro Processors: System SoftwareDocument12 pagesMacro Processors: System SoftwaregjajNo ratings yet
- Machine Independent Macro Processor FeaturesDocument15 pagesMachine Independent Macro Processor FeaturesgjajNo ratings yet
- Lab 1-LinuxDocument17 pagesLab 1-LinuxanubhavNo ratings yet
- 20761B 02Document28 pages20761B 02Abdul-alim Bhnsawy100% (1)
- Neo 4 JDocument19 pagesNeo 4 JAhmed FouzanNo ratings yet
- RSBSS153 - Adjacencies Having High HO Failure Ratio-NOKBSCDocument16 pagesRSBSS153 - Adjacencies Having High HO Failure Ratio-NOKBSChuseyinNo ratings yet
- Beginner's Crash Course To Elastic Stack - Part 1. 1 Intro To Elasticsearch and KibanaDocument59 pagesBeginner's Crash Course To Elastic Stack - Part 1. 1 Intro To Elasticsearch and KibanaboyeNo ratings yet
- PHP Tutorial Step by StepDocument6 pagesPHP Tutorial Step by Stepbekabeki829No ratings yet
- CDISC 123 SasDocument12 pagesCDISC 123 SasKatti VenkataramanaNo ratings yet
- Silabus PII Short Course Intro To Big Data in 2 HoursDocument3 pagesSilabus PII Short Course Intro To Big Data in 2 HoursIskarimah YolanisaNo ratings yet
- OLAP Data MiningDocument44 pagesOLAP Data Miningvarshaarya22222No ratings yet
- Linux Cheat Sheet PDFDocument1 pageLinux Cheat Sheet PDFArief PrihantoroNo ratings yet
- DBase AdminDocument2 pagesDBase AdminEvans TingaNo ratings yet
- Lecture 5 NormalizationDocument12 pagesLecture 5 NormalizationMohamed MagedNo ratings yet
- Vtu 5TH Sem Cse DBMS NotesDocument54 pagesVtu 5TH Sem Cse DBMS NotesNeha Chinni100% (1)
- HANA Disks Data Overview 1.00.120+Document5 pagesHANA Disks Data Overview 1.00.120+Rafael Gonzalez HernándezNo ratings yet
- phpFastCache V2Document7 pagesphpFastCache V2DaisilySamuelNo ratings yet
- Music Retrieval A Tutorial and ReviewDocument92 pagesMusic Retrieval A Tutorial and ReviewAlejandro SepaNo ratings yet
- Addition and Multiplication of Huge Numbers Using Doubly Linked List - C ++Document5 pagesAddition and Multiplication of Huge Numbers Using Doubly Linked List - C ++Akshara P SNo ratings yet
- 11g Location of AlertDocument18 pages11g Location of AlertShailendra KherdeNo ratings yet
- Data Mining PrimerDocument15 pagesData Mining PrimerapoorvgadwalNo ratings yet
- AIX-To-Linux Quick Start ComparisonDocument7 pagesAIX-To-Linux Quick Start ComparisonSaroj KumarNo ratings yet
- How To Configure RMAN To Work With NETbackupDocument7 pagesHow To Configure RMAN To Work With NETbackupNJ SinghNo ratings yet
- Pivot TableDocument13 pagesPivot TableDivjot BatraNo ratings yet
- 2SGBD Practice 1Document2 pages2SGBD Practice 1Matisse prtNo ratings yet
- Database Assignment-Ll Dream Home Database System Faisal Abbas BSCM-F19-404Document5 pagesDatabase Assignment-Ll Dream Home Database System Faisal Abbas BSCM-F19-404FAISAL ABBASNo ratings yet
- Practice Lecture 1 - October 8 2009 View-Based Data Integration (Relational Data Model)Document4 pagesPractice Lecture 1 - October 8 2009 View-Based Data Integration (Relational Data Model)Sazid Ahmed NassirNo ratings yet
- Delphi To InterBase in 15 M...Document42 pagesDelphi To InterBase in 15 M...faropeNo ratings yet
- Architecture in Object Oriented Databases.: Sunanda LuthraDocument12 pagesArchitecture in Object Oriented Databases.: Sunanda LuthraTHAMZHILTHEDALNo ratings yet
- BIG DATA 1 UnitDocument17 pagesBIG DATA 1 UnitIshika Singh100% (1)