0% found this document useful (0 votes)
9 viewsRM Assignment 2
1. The document provides examples and explanations for statistical concepts including central limit theorem, z-tests, t-tests, and confidence intervals.
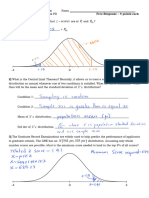
2. For a one-tailed z-test example, the document tests if the mean weight of water bottles is greater than 10kg. For two tailed t-test examples, it tests if a material's mean strength is equal to a target value, and if the mean blood sodium concentration of patients is within the total population range.
3. The document calculates a 95% confidence interval for the mean blood sodium concentration using a t-distribution, given a sample size of 18 patients.
Uploaded by
7 EduCopyright
© © All Rights Reserved
Available Formats
Download as DOCX, PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
9 viewsRM Assignment 2
1. The document provides examples and explanations for statistical concepts including central limit theorem, z-tests, t-tests, and confidence intervals.
2. For a one-tailed z-test example, the document tests if the mean weight of water bottles is greater than 10kg. For two tailed t-test examples, it tests if a material's mean strength is equal to a target value, and if the mean blood sodium concentration of patients is within the total population range.
3. The document calculates a 95% confidence interval for the mean blood sodium concentration using a t-distribution, given a sample size of 18 patients.
Uploaded by
7 EduCopyright
© © All Rights Reserved
Available Formats
Download as DOCX, PDF, TXT or read online on Scribd
/ 9