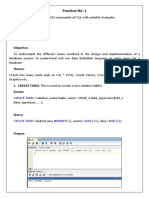
Stata
Stata
Download as docx, pdf, or txt
You might also like
- Stata GuideDocument11 pagesStata GuideTamas BarkoNo ratings yet
- Data Entry Interview QuestionsDocument3 pagesData Entry Interview QuestionsVikas JadhavNo ratings yet
- LDEMO2404 Session1 Dofile - DoDocument4 pagesLDEMO2404 Session1 Dofile - DoCyril VandendorpelNo ratings yet
- Dbms 2 NotesDocument34 pagesDbms 2 Notes22b61a6603No ratings yet
- Tricky SQL Queries For InterviewDocument18 pagesTricky SQL Queries For InterviewRicha kashyap100% (1)
- SAS Library Data Transformations and Data Manipulation in SASDocument31 pagesSAS Library Data Transformations and Data Manipulation in SASShiva KrishnaNo ratings yet
- Surviving Graduate Econometrics With R Difference-In-Differences Estimation - 2 of 8Document7 pagesSurviving Graduate Econometrics With R Difference-In-Differences Estimation - 2 of 8renita1901No ratings yet
- Dbms Manual 2021Document52 pagesDbms Manual 2021Sathish KrishnanNo ratings yet
- 3-Stats UniDocument15 pages3-Stats UniJoshua chirchirNo ratings yet
- CH 02Document36 pagesCH 02Xiaoxu WuNo ratings yet
- The Stata Command All Commands Concerning Fixed and Random EffectDocument10 pagesThe Stata Command All Commands Concerning Fixed and Random EffectMohamed DjellouliNo ratings yet
- National University: 551 M.F. Jhocson ST., Sampaloc, ManilaDocument5 pagesNational University: 551 M.F. Jhocson ST., Sampaloc, ManilaMyka SantosNo ratings yet
- SQL Server 2005 - CoursewareDocument108 pagesSQL Server 2005 - Coursewaremalai642No ratings yet
- DDL Is Data Definition Language Statements. Some ExamplesDocument34 pagesDDL Is Data Definition Language Statements. Some Examplessatya1401No ratings yet
- Oracle Sample - Practice QueriesDocument9 pagesOracle Sample - Practice Querieskullayappa786No ratings yet
- Lab Manuals DDBSDocument67 pagesLab Manuals DDBSzubair100% (1)
- Do - File - Quan Ly Va Lam Sach Du LieuDocument6 pagesDo - File - Quan Ly Va Lam Sach Du Lieutrannhi2806tgNo ratings yet
- Gams Tips and TricksDocument10 pagesGams Tips and TricksTheDarkSoldierCLNo ratings yet
- My SQLDocument44 pagesMy SQLsreelaya100% (1)
- PRACTICAL NOTES STATA (Using Version 8 and 10) Stata Is One of The Sophisticated Statistical Software Used in Data Analysis. It Is More UserDocument30 pagesPRACTICAL NOTES STATA (Using Version 8 and 10) Stata Is One of The Sophisticated Statistical Software Used in Data Analysis. It Is More UserMuwanguzi DavidNo ratings yet
- Many To ManyDocument9 pagesMany To ManyKayalvizhi ElamparithiNo ratings yet
- Informix Show LocksDocument6 pagesInformix Show Locksapi-1850035100% (2)
- Stata ReviewDocument9 pagesStata Reviewlaura.telloNo ratings yet
- Creating New Variables: Generate and ReplaceDocument7 pagesCreating New Variables: Generate and ReplacegaryngaraNo ratings yet
- OOPS FileDocument36 pagesOOPS Filekaranmandrai8643No ratings yet
- Toaz - Info Control Systems Lab 1 PRDocument8 pagesToaz - Info Control Systems Lab 1 PRrhydnar KimNo ratings yet
- Week 1 - Intro To StataDocument35 pagesWeek 1 - Intro To StatatimauditjobppaNo ratings yet
- Assignment: 7: Due: Language Level: Allowed Recursion: Files To Submit: Warmup Exercises: Practise ExercisesDocument6 pagesAssignment: 7: Due: Language Level: Allowed Recursion: Files To Submit: Warmup Exercises: Practise ExercisesYanling LinNo ratings yet
- Chapter 1-7. Looping, Collapsing, and ReshapingDocument29 pagesChapter 1-7. Looping, Collapsing, and ReshapingMithun BhattacharyaNo ratings yet
- ExcelData2 FilterPivotDocument9 pagesExcelData2 FilterPivotJMFMNo ratings yet
- Ess Spreadsheet Features: Operators and Functions Changing Cell StyleDocument22 pagesEss Spreadsheet Features: Operators and Functions Changing Cell StyleElvir OmanovićNo ratings yet
- Statistical Modeling Using R - Lab ManualDocument23 pagesStatistical Modeling Using R - Lab ManualGagana ReddyNo ratings yet
- Eviews: 29. Juni 2010Document20 pagesEviews: 29. Juni 2010Nicoleta TudoracheNo ratings yet
- DBMS Manual-1Document39 pagesDBMS Manual-1Divya DharshiniNo ratings yet
- CMSC 15100Document66 pagesCMSC 15100pie1213No ratings yet
- Proc SQLDocument7 pagesProc SQLhima100% (1)
- Introduction To Stata and Data ManagementDocument30 pagesIntroduction To Stata and Data ManagementHulle TNo ratings yet
- Chavan - Sakshi - 201EE116 - Labreport - 2 PDFDocument2 pagesChavan - Sakshi - 201EE116 - Labreport - 2 PDFSakshi ChavanNo ratings yet
- Control Systems Lab 1Document8 pagesControl Systems Lab 1Patrick GoNo ratings yet
- Bitmap Indexes: Table 11-6. A Representation of How Oracle Would Store The Bitmp IndexDocument8 pagesBitmap Indexes: Table 11-6. A Representation of How Oracle Would Store The Bitmp Indexamit_dbaNo ratings yet
- Lecture Notes 11Document41 pagesLecture Notes 11SayanNo ratings yet
- Homework Index: To See If The Questions Have Been Changed, or If You Are Required To Use Different Data or ExamplesDocument86 pagesHomework Index: To See If The Questions Have Been Changed, or If You Are Required To Use Different Data or ExamplesasNo ratings yet
- MakeDocument4 pagesMaketamzid11No ratings yet
- Lab01 Note SASDocument5 pagesLab01 Note SASsdcphdworkNo ratings yet
- 12 Mysql Qs NotesDocument18 pages12 Mysql Qs Notessubhash varghese50% (2)
- Star Query Versus Star Transformation Query: Which To Choose?Document8 pagesStar Query Versus Star Transformation Query: Which To Choose?baraagoNo ratings yet
- Aae 550 Multidisciplinary Design Optimization FALL 2011 Homework Assignment #3 DUE NOVEMBER 30, 2011Document9 pagesAae 550 Multidisciplinary Design Optimization FALL 2011 Homework Assignment #3 DUE NOVEMBER 30, 2011rmalone67No ratings yet
- C++ Proposed Exercises (Chapter 7: The C++ Programing Language, Fourth Edition)Document7 pagesC++ Proposed Exercises (Chapter 7: The C++ Programing Language, Fourth Edition)Mauricio BedoyaNo ratings yet
- DBMS ManualDocument96 pagesDBMS ManualSushmith ShettigarNo ratings yet
- StataguideDocument17 pagesStataguidejihanazizah036No ratings yet
- PivotDocument2 pagesPivotNarcizo NorzagarayNo ratings yet
- Package Montecarlo': R Topics DocumentedDocument9 pagesPackage Montecarlo': R Topics DocumentedDavid HumphreyNo ratings yet
- Lab Activity 1 Engineering Control SystemsDocument8 pagesLab Activity 1 Engineering Control SystemsKENNETH LIGUTOMNo ratings yet
- MCS 025 (11 12)Document34 pagesMCS 025 (11 12)Ajai Issac ArisserilNo ratings yet
- DBMSDocument49 pagesDBMSbhoomika311.dNo ratings yet
- Advance Database Administration Practicles by Om WamanDocument44 pagesAdvance Database Administration Practicles by Om WamanOm wamanNo ratings yet
- Exportar de Stata A ExcelDocument2 pagesExportar de Stata A ExcelJavier Burbano ValenciaNo ratings yet
- Code FightDocument10 pagesCode FightManeesh DarisiNo ratings yet
- STATA Codes - BasicDocument8 pagesSTATA Codes - Basic蕭得軒No ratings yet
- Signal and Systems: Ab Vaqar (COMPANY NAME) (Company Address)Document72 pagesSignal and Systems: Ab Vaqar (COMPANY NAME) (Company Address)Abdul RehmanNo ratings yet
- Advanced SAS Interview Questions You'll Most Likely Be AskedFrom EverandAdvanced SAS Interview Questions You'll Most Likely Be AskedNo ratings yet
- ICT ContactCenterServices 9 Q3 LAS1 FINALDocument8 pagesICT ContactCenterServices 9 Q3 LAS1 FINALRousell AndradaNo ratings yet
- Varilight Catalogue PDFDocument58 pagesVarilight Catalogue PDFRavi AlagumalaiNo ratings yet
- Panasonic DP-8020e Service HandbookDocument352 pagesPanasonic DP-8020e Service Handbookgenemanlapaz100% (1)
- Aertrim™ System For Benchmark Boilers: Technical Data SheetDocument2 pagesAertrim™ System For Benchmark Boilers: Technical Data SheetNdia2007No ratings yet
- Primavera P6 Vs MSPDocument7 pagesPrimavera P6 Vs MSPKaran AvadNo ratings yet
- Sonika ResumeDocument2 pagesSonika ResumeAnshu SinghNo ratings yet
- K80mccpower Take in Take OffDocument259 pagesK80mccpower Take in Take OffNihal NaralkarNo ratings yet
- UPS Installation Procedure 2Document5 pagesUPS Installation Procedure 2vimal alaberahNo ratings yet
- US660H (ASIA) - Datasheet (Low) - LG Commercial TV - 200522Document5 pagesUS660H (ASIA) - Datasheet (Low) - LG Commercial TV - 200522Birthley RagasaNo ratings yet
- GMSKDocument18 pagesGMSKHamza MalikNo ratings yet
- JVC Sr-Dvm70ag Sr-Dvm70eu DVD HDD Mini-Dv Recorder FullDocument118 pagesJVC Sr-Dvm70ag Sr-Dvm70eu DVD HDD Mini-Dv Recorder FullSteve WalschotNo ratings yet
- Pcbasket 23Document10 pagesPcbasket 23Ian FallerNo ratings yet
- Bandi KishoreDocument95 pagesBandi KishoreSagarChedeNo ratings yet
- Available Courses For Ethiopian Students Who Wants To Study in EuropeDocument6 pagesAvailable Courses For Ethiopian Students Who Wants To Study in Europegetahun esubalewNo ratings yet
- 725 Electrical SchematicDocument11 pages725 Electrical SchematicKhaled Naseem Abu-Sabha0% (1)
- CCNA Boot Camp Post TestDocument4 pagesCCNA Boot Camp Post TestEric ResuelloNo ratings yet
- CloudComputing Model Answer Key 2024Document1 pageCloudComputing Model Answer Key 2024venkatesh.mNo ratings yet
- HRQ Discriptions 2915 What Is Retransmission, ARQ and HARQ?: Statistics CategoriesDocument14 pagesHRQ Discriptions 2915 What Is Retransmission, ARQ and HARQ?: Statistics CategoriesDavid MdevaNo ratings yet
- IPv6@ESTG-Leiria IPv6Wireless Relatorio FinalDocument94 pagesIPv6@ESTG-Leiria IPv6Wireless Relatorio FinalAndré MadeiraNo ratings yet
- Rakesh Resume 3.2yrsDocument1 pageRakesh Resume 3.2yrsBEST OF BESTNo ratings yet
- SSM II Inglés Sem 16Document8 pagesSSM II Inglés Sem 16Kevin GamesNo ratings yet
- ACKNOWLEDGEMENTDocument4 pagesACKNOWLEDGEMENTSowmya KamatamNo ratings yet
- What Is Big Data ?: University Year: 2019 - 2020Document30 pagesWhat Is Big Data ?: University Year: 2019 - 2020Samar JelassiNo ratings yet
- Eko 10 PDFDocument6 pagesEko 10 PDFJavier Martínez75% (4)
- Castro Franklin ResumeDocument2 pagesCastro Franklin ResumeFrank CastroNo ratings yet
- Final Report of Andode Tuma Power and TelecommunicationDocument38 pagesFinal Report of Andode Tuma Power and TelecommunicationSintayehu TerefeNo ratings yet
- CFD in Launch Vehicle ApplicationsDocument6 pagesCFD in Launch Vehicle ApplicationsaeroalanNo ratings yet
- Ic Engines Laboratory ManualDocument35 pagesIc Engines Laboratory ManualYuvaraj Yuvi0% (1)
- 023 - Cutting Edge COBOL OfferingsDocument36 pages023 - Cutting Edge COBOL Offeringsshinu_diyNo ratings yet