0% found this document useful (0 votes)
26 viewsLecture Notes 2020
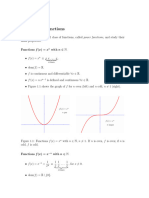
This document provides lecture notes on mathematical foundations of risk management. It reviews key concepts in probability including distributions, densities, tail distributions, and transformations of random variables. Specific distributions covered include exponential, Pareto, normal, and t distributions. Expected value and how it is calculated for different distributions is also reviewed. Examples are provided to demonstrate how to derive the distribution and density of transformed random variables.
Uploaded by
yiyok48477Copyright
© © All Rights Reserved
Available Formats
Download as PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
26 viewsLecture Notes 2020
This document provides lecture notes on mathematical foundations of risk management. It reviews key concepts in probability including distributions, densities, tail distributions, and transformations of random variables. Specific distributions covered include exponential, Pareto, normal, and t distributions. Expected value and how it is calculated for different distributions is also reviewed. Examples are provided to demonstrate how to derive the distribution and density of transformed random variables.
Uploaded by
yiyok48477Copyright
© © All Rights Reserved
Available Formats
Download as PDF, TXT or read online on Scribd
/ 12