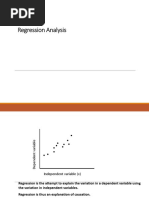
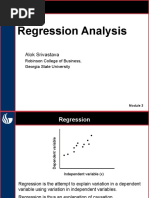
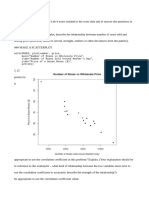
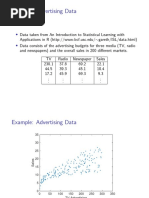
Week 9
Week 9
Download as pdf or txt
You might also like
- Instant Download Essentials of Statistics for the Behavioral Sciences, 9th 9th Edition Frederick J. Gravetter PDF All ChaptersDocument57 pagesInstant Download Essentials of Statistics for the Behavioral Sciences, 9th 9th Edition Frederick J. Gravetter PDF All Chaptershnonabaner3100% (1)
- CH9 and 10. HYPOTHESIS TESTINGDocument7 pagesCH9 and 10. HYPOTHESIS TESTINGHazell DNo ratings yet
- Chapter 16Document6 pagesChapter 16maustroNo ratings yet
- Ehab A. Mahmood 151117Document18 pagesEhab A. Mahmood 151117ehabmahmood3No ratings yet
- Unit 5Document104 pagesUnit 5downloadjain123No ratings yet
- Applied Business Forecasting and Planning: Multiple Regression AnalysisDocument100 pagesApplied Business Forecasting and Planning: Multiple Regression AnalysisRobby PangestuNo ratings yet
- Wooldridge NotesDocument15 pagesWooldridge Notesrajat25690No ratings yet
- Multiple Regression AnalysisDocument8 pagesMultiple Regression AnalysisLeia SeunghoNo ratings yet
- Regression - Definition, Formula, Derivation, Application - EmbibeDocument10 pagesRegression - Definition, Formula, Derivation, Application - EmbibeSrishti ShivangNo ratings yet
- Chapter 17: Autocorrelation (Serial Correlation) : - o o o o - oDocument32 pagesChapter 17: Autocorrelation (Serial Correlation) : - o o o o - ohazar rochmatinNo ratings yet
- SST307 CompleteDocument72 pagesSST307 Completebranmondi8676No ratings yet
- ch11Document55 pagesch11rxn255No ratings yet
- Oversikt ECN402Document40 pagesOversikt ECN402Mathias VindalNo ratings yet
- Ordinary Least SquaresDocument17 pagesOrdinary Least SquaresRa'fat JalladNo ratings yet
- Lecture 2Document17 pagesLecture 2李姿瑩No ratings yet
- Regression ModelDocument26 pagesRegression ModelkhadarcabdiNo ratings yet
- Two-Parameter Rayleigh Distribution: Different Methods of EstimationDocument21 pagesTwo-Parameter Rayleigh Distribution: Different Methods of EstimationdassNo ratings yet
- Lecture 3Document18 pagesLecture 3李姿瑩No ratings yet
- The Multiple Linear Regression Model: Version: 30-10-2023, 16:07Document17 pagesThe Multiple Linear Regression Model: Version: 30-10-2023, 16:07Saptangshu MannaNo ratings yet
- Simple Linear Regression AnalysisDocument5 pagesSimple Linear Regression AnalysisaditidocmocNo ratings yet
- Scatter Plot/Diagram Simple Linear Regression ModelDocument43 pagesScatter Plot/Diagram Simple Linear Regression ModelnooraNo ratings yet
- Regression in Data MiningDocument15 pagesRegression in Data MiningpoonamNo ratings yet
- Regression (Basic Concepts)Document15 pagesRegression (Basic Concepts)LUXMI TRADING COMPANYNo ratings yet
- Emet2007 NotesDocument6 pagesEmet2007 NoteskowletNo ratings yet
- Solving Multicollinearity Problem: Int. J. Contemp. Math. Sciences, Vol. 6, 2011, No. 12, 585 - 600Document16 pagesSolving Multicollinearity Problem: Int. J. Contemp. Math. Sciences, Vol. 6, 2011, No. 12, 585 - 600Tiberiu TincaNo ratings yet
- Module-11.-Lesson-ProperDocument5 pagesModule-11.-Lesson-Properyaway379No ratings yet
- FM Project REPORT - Group3Document24 pagesFM Project REPORT - Group3Jagmohan SainiNo ratings yet
- Ordinary Least SquaresDocument21 pagesOrdinary Least SquaresRahulsinghooooNo ratings yet
- OLS MethodDocument12 pagesOLS MethodaditidocmocNo ratings yet
- Regression and Multiple Regression AnalysisDocument21 pagesRegression and Multiple Regression AnalysisRaghu Nayak100% (1)
- Multiple Regression Analysis 1Document57 pagesMultiple Regression Analysis 1Jacqueline CarbonelNo ratings yet
- Lecture3 221109 035214Document87 pagesLecture3 221109 035214indrahermawanNo ratings yet
- Exp 1 121a1047 Lavanya Kurup MLDocument11 pagesExp 1 121a1047 Lavanya Kurup MLPunya NairNo ratings yet
- Chapter 1Document17 pagesChapter 1Getasew AsmareNo ratings yet
- Lesson 2: Multiple Linear Regression Model (I) : E L F V A L U A T I O N X E R C I S E SDocument14 pagesLesson 2: Multiple Linear Regression Model (I) : E L F V A L U A T I O N X E R C I S E SMauricio Ortiz OsorioNo ratings yet
- Topic:-Regression: Name: - Teotia Nidhi Class: - M.SC BiotechnologyDocument10 pagesTopic:-Regression: Name: - Teotia Nidhi Class: - M.SC Biotechnologynidhi teotiaNo ratings yet
- Lecturer 4 Regression AnalysisDocument29 pagesLecturer 4 Regression AnalysisShahzad Khan100% (1)
- Unit 5Document10 pagesUnit 5Uttareshwar SontakkeNo ratings yet
- Least Squares.: Herv e AbdiDocument4 pagesLeast Squares.: Herv e Abdinuocmatvinhcuu2510No ratings yet
- 325unit 1 Simple Regression AnalysisDocument10 pages325unit 1 Simple Regression AnalysisutsavNo ratings yet
- Data Analytics Unit 3 NotesDocument28 pagesData Analytics Unit 3 NotesSmash art boy100% (2)
- L1 QM07 High Yield NotesDocument4 pagesL1 QM07 High Yield NotesaesopNo ratings yet
- Chap 2Document9 pagesChap 2MingdreamerNo ratings yet
- Linear Regression Analysis: Module - IvDocument10 pagesLinear Regression Analysis: Module - IvupenderNo ratings yet
- RegressionDocument15 pagesRegressionhamdoniNo ratings yet
- Regression Analysis: Alok SrivastavaDocument16 pagesRegression Analysis: Alok SrivastavagopiNo ratings yet
- Chapter 4Document68 pagesChapter 4Nhatty WeroNo ratings yet
- Datamining Lecture6Document41 pagesDatamining Lecture6Vi LeNo ratings yet
- Chapter Three MultipleDocument15 pagesChapter Three MultipleabdihalimNo ratings yet
- Regression and CorrelationDocument9 pagesRegression and CorrelationVivay Salazar100% (1)
- Measurement Error ModelsDocument79 pagesMeasurement Error ModelsTandis AsadiNo ratings yet
- Part A Assignment - No - 4Document14 pagesPart A Assignment - No - 4Krushna ShindeNo ratings yet
- Binomial Probability DistributionDocument31 pagesBinomial Probability DistributionLORAINE OBLIPIAS100% (1)
- The Binomial Probability Distribution and Related TopicsDocument31 pagesThe Binomial Probability Distribution and Related TopicsLORAINE OBLIPIASNo ratings yet
- Chapter 3 - Classical Simple Linear RegressionDocument52 pagesChapter 3 - Classical Simple Linear RegressionSolomonSakalaNo ratings yet
- Week 2 and Week 3Document14 pagesWeek 2 and Week 3g-sk5103tmp05No ratings yet
- MultivariableRegression 4Document98 pagesMultivariableRegression 4Alada manaNo ratings yet
- CHP 3 Notes, GujaratiDocument4 pagesCHP 3 Notes, GujaratiDiwakar ChakrabortyNo ratings yet
- Types of StatisticsDocument7 pagesTypes of StatisticsTahirNo ratings yet
- Topic:-Regression: Name: - Teotia Nidhi Class: - M.SC BiotechnologyDocument11 pagesTopic:-Regression: Name: - Teotia Nidhi Class: - M.SC Biotechnologynidhi teotiaNo ratings yet
- Student Solutions Manual to Accompany Economic Dynamics in Discrete Time, second editionFrom EverandStudent Solutions Manual to Accompany Economic Dynamics in Discrete Time, second editionRating: 4.5 out of 5 stars4.5/5 (2)
- Student's Solutions Manual and Supplementary Materials for Econometric Analysis of Cross Section and Panel Data, second editionFrom EverandStudent's Solutions Manual and Supplementary Materials for Econometric Analysis of Cross Section and Panel Data, second editionNo ratings yet
- Repeated Measures ANOVA and Two-Factor (Factorial) ANOVADocument32 pagesRepeated Measures ANOVA and Two-Factor (Factorial) ANOVASrinivasagopalanNo ratings yet
- G11 ModulesDocument32 pagesG11 ModuleshonetosuccessNo ratings yet
- Lab 4Document5 pagesLab 4cracking khalifNo ratings yet
- Vikram Mullachery Aniruddh Khera Amir Husain: Bayesian Neural NetworksDocument16 pagesVikram Mullachery Aniruddh Khera Amir Husain: Bayesian Neural NetworksTamás MákosNo ratings yet
- CS1B Actuarial Statistics SolutionsDocument13 pagesCS1B Actuarial Statistics SolutionsVasudev PurNo ratings yet
- Ws 103822Document34 pagesWs 103822Felipe Pablo Velasquez GuerinoNo ratings yet
- Notes On ARIMA: ND RDDocument4 pagesNotes On ARIMA: ND RDSri NeogiNo ratings yet
- Two Way ANOVA 4 UploadedDocument75 pagesTwo Way ANOVA 4 UploadedOzell SandersNo ratings yet
- Post HocDocument5 pagesPost HocTracy NadineNo ratings yet
- Final Performance Task in Statistics AND ProbabilityDocument10 pagesFinal Performance Task in Statistics AND ProbabilityjeanNo ratings yet
- Evans Analytics1e PPT 10Document61 pagesEvans Analytics1e PPT 10Etibar AshirovNo ratings yet
- Linear Regression 1Document10 pagesLinear Regression 1CharanKanwal VirkNo ratings yet
- Assignment 1Document2 pagesAssignment 1SwapnilNo ratings yet
- Diamonds: Analyze Diamonds by Their Cut, Color, Clarity, Price, and Other AttributesDocument14 pagesDiamonds: Analyze Diamonds by Their Cut, Color, Clarity, Price, and Other Attributesneer2898No ratings yet
- ch1 The Nature of Regression AnalysisDocument12 pagesch1 The Nature of Regression AnalysisyukeNo ratings yet
- Practice of Introductory Time Series With RDocument22 pagesPractice of Introductory Time Series With Rapi-285777244No ratings yet
- Regr06linregressionquiz2ans 1Document2 pagesRegr06linregressionquiz2ans 1api-250286128No ratings yet
- Ken Black QA 5th Chapter 11 SolutionDocument30 pagesKen Black QA 5th Chapter 11 SolutionRushabh VoraNo ratings yet
- STAT 2006 Chapter 2 - 2022Document83 pagesSTAT 2006 Chapter 2 - 2022Hiu Yin YuenNo ratings yet
- MAST20005 Statistics Assignment 2Document9 pagesMAST20005 Statistics Assignment 2Anonymous na314kKjOANo ratings yet
- Stats Extra CreditDocument5 pagesStats Extra CreditNawaraj Pokhrel100% (3)
- Further Issues With The Classical Linear Regression Model: Introductory Econometrics For Finance' © Chris Brooks 2002 1Document74 pagesFurther Issues With The Classical Linear Regression Model: Introductory Econometrics For Finance' © Chris Brooks 2002 1Pawan PreetNo ratings yet
- Hypothesis Testing: By: Janice Galus CordovaDocument22 pagesHypothesis Testing: By: Janice Galus CordovaJaniceGalusCordova75% (4)
- CHP 13 ARMADocument23 pagesCHP 13 ARMASayed AamirNo ratings yet
- BNAD 277 Tableau AssignmentDocument1 pageBNAD 277 Tableau AssignmentMadison C BarnettNo ratings yet
- Solution - Test 2Document6 pagesSolution - Test 2Duyên Phạm ThùyNo ratings yet
- Anova Chi Square TestDocument53 pagesAnova Chi Square TestAira Jean MangusinNo ratings yet
- Assignment2 Dhairya - ShahDocument7 pagesAssignment2 Dhairya - ShahAvani PatilNo ratings yet