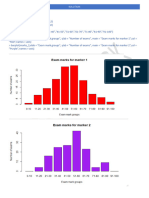
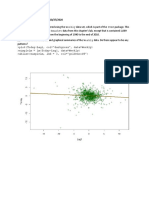
CS1B Actuarial Statistics Solutions
CS1B Actuarial Statistics Solutions
Download as pdf or txt
You might also like
- Tank Dip Test Authorization LetterDocument1 pageTank Dip Test Authorization LetterTMWYN86% (7)
- Labor (A) : Report On: IKEA's Global Sourcing Challenge: Indian Rugs and ChildDocument5 pagesLabor (A) : Report On: IKEA's Global Sourcing Challenge: Indian Rugs and ChildSumit TomarNo ratings yet
- Romer 5e Solutions Manual 06Document26 pagesRomer 5e Solutions Manual 06MatthewNo ratings yet
- Basic Statistics 1Document12 pagesBasic Statistics 1Revathi Jose100% (2)
- SPECIMEN EXAM SOLUTIONS - CS1B - IFoA - 2019 - FinalDocument8 pagesSPECIMEN EXAM SOLUTIONS - CS1B - IFoA - 2019 - FinalKev RazNo ratings yet
- Chapter 5Document22 pagesChapter 5Rajat BansalNo ratings yet
- Assignment R New 1Document26 pagesAssignment R New 1Sohel RanaNo ratings yet
- Group Assignment - Predictive ModellingDocument23 pagesGroup Assignment - Predictive ModellingSimran SahaNo ratings yet
- 04 BasicAnalysesDocument44 pages04 BasicAnalysesCotta LeeNo ratings yet
- Class Test 2 Solution 2019Document3 pagesClass Test 2 Solution 2019Ne PaNo ratings yet
- Q3-Copy1: Pandas PD Numpy NP CSVDocument7 pagesQ3-Copy1: Pandas PD Numpy NP CSVMuhammad Hur RizviNo ratings yet
- Lab file AD pdfDocument25 pagesLab file AD pdfDipayan RakshitNo ratings yet
- Lab file AD pdfDocument25 pagesLab file AD pdfDipayan RakshitNo ratings yet
- CH 8 and 9 SolDocument5 pagesCH 8 and 9 Solyukz241195No ratings yet
- Data Manipulation: Ionut BebuDocument19 pagesData Manipulation: Ionut BebucsedtuhNo ratings yet
- R Intro 2011Document115 pagesR Intro 2011marijkepauwelsNo ratings yet
- Outlier DetectionDocument41 pagesOutlier DetectionTanishi GuptaNo ratings yet
- ASPjskjkjksnkxdqlcwlDocument34 pagesASPjskjkjksnkxdqlcwlSonuBajajNo ratings yet
- Sulvirah-Rahmi UTS KomstatS2Document14 pagesSulvirah-Rahmi UTS KomstatS2viraNo ratings yet
- Homework5Document6 pagesHomework5kc5mv2mhmhNo ratings yet
- Bacs HW4Document14 pagesBacs HW4brian2000890714No ratings yet
- R Lab Hypothesis TestingDocument6 pagesR Lab Hypothesis Testingfarazabdullah3No ratings yet
- 330 Lecture2 2015 PDFDocument24 pages330 Lecture2 2015 PDFAnonymous gUySMcpSqNo ratings yet
- 41 Perusse Alexander Aperusse PDFDocument7 pages41 Perusse Alexander Aperusse PDFAnurita MathurNo ratings yet
- 4027 Assignment Q5Document12 pages4027 Assignment Q5lewis.hastieNo ratings yet
- CodeDocument25 pagesCodeClassy ManNo ratings yet
- Assign3 Sol PDFDocument7 pagesAssign3 Sol PDFvanessalaucodeNo ratings yet
- R Commands GoodDocument2 pagesR Commands Goodshubhang2392No ratings yet
- Ai/Ml Lab-4: Name: Pratik Jadhav PRN: 20190802050Document5 pagesAi/Ml Lab-4: Name: Pratik Jadhav PRN: 20190802050testNo ratings yet
- Predictivemaintenance FaultDetectionDocument12 pagesPredictivemaintenance FaultDetectionMarius BarNo ratings yet
- STATS500 Assignment 1Document3 pagesSTATS500 Assignment 1adi34567No ratings yet
- Unit3-Data ScienceDocument37 pagesUnit3-Data ScienceDIVYANSH GAUR (RA2011027010090)No ratings yet
- SAS Project 2 (31.3 Pts. + 4.2 Bonus) Due Dec. 8: 1. Confidence Intervals/Hypothesis TestsDocument21 pagesSAS Project 2 (31.3 Pts. + 4.2 Bonus) Due Dec. 8: 1. Confidence Intervals/Hypothesis TestsAshwani PasrichaNo ratings yet
- Modern Regression Homework 5-1Document8 pagesModern Regression Homework 5-1rowan.christie.21No ratings yet
- MATH 52540 (CHAPTERS 10-12 Worksheet)Document6 pagesMATH 52540 (CHAPTERS 10-12 Worksheet)sarkarigamingytNo ratings yet
- Assignments (Course Requirement) : Misamis University Graduate SchoolDocument7 pagesAssignments (Course Requirement) : Misamis University Graduate SchoolGraciously ElleNo ratings yet
- ChiboubMahmoudYassine 2000252 TP3Document6 pagesChiboubMahmoudYassine 2000252 TP3Mahmoud ChiboubNo ratings yet
- Solutions ModernstatisticsDocument144 pagesSolutions ModernstatisticsdivyanshNo ratings yet
- Quartiles in R PDFDocument4 pagesQuartiles in R PDFwichastaNo ratings yet
- FandI CT3 200709 ReportDocument9 pagesFandI CT3 200709 ReportTuff BubaNo ratings yet
- Supervised Logistic Tutorial Final PDFDocument9 pagesSupervised Logistic Tutorial Final PDFmichaelkotze03No ratings yet
- Industrial Statistics - A Computer Based Approach With PythonDocument140 pagesIndustrial Statistics - A Computer Based Approach With PythonhtapiaqNo ratings yet
- Data Mining Versus Statistical Tools For Value at Risk EstimationDocument9 pagesData Mining Versus Statistical Tools For Value at Risk EstimationroyNo ratings yet
- Final AK (Spring 2024)Document14 pagesFinal AK (Spring 2024)Batchb689No ratings yet
- HW3 張晏壬 R26104047Document11 pagesHW3 張晏壬 R26104047Yen-Jen ChangNo ratings yet
- Relatorio 2Document5 pagesRelatorio 2hpmmarcondesNo ratings yet
- Stat 5700 HW 2Document15 pagesStat 5700 HW 2Alan HollowayNo ratings yet
- Week 2Document7 pagesWeek 2Indri Br SitumorangNo ratings yet
- Lecturenotes14 10Document15 pagesLecturenotes14 10hmolinaqNo ratings yet
- Linear RegressionDocument20 pagesLinear Regressionrakshithsreddy65No ratings yet
- Condition NumberDocument6 pagesCondition NumberPrakharNo ratings yet
- Bacs HW2Document11 pagesBacs HW2brian2000890714No ratings yet
- Lab-6-Binomail and Poisson DistributionDocument13 pagesLab-6-Binomail and Poisson DistributionRakib Khan100% (1)
- 7probability Distributions (Binomial, Poisson and Normal)Document33 pages7probability Distributions (Binomial, Poisson and Normal)lakshita6789No ratings yet
- KVA Anusha - PGP12021 - BADocument8 pagesKVA Anusha - PGP12021 - BAAditi Pareek100% (1)
- Final Exam SBDocument12 pagesFinal Exam SBPhan Đức PhươngNo ratings yet
- Effect SizeDocument9 pagesEffect Sizeapi-362845526No ratings yet
- Mla - 2 (Cia - 1) - 20221013Document14 pagesMla - 2 (Cia - 1) - 20221013JEFFREY WILLIAMS P M 20221013No ratings yet
- AGR003 Laboratory Stats Tester: For AndroidDocument3 pagesAGR003 Laboratory Stats Tester: For AndroidFrederick CabactulanNo ratings yet
- Matlab-STATISTICAL MODELS AND METHODS FOR FINANCIAL MARKETSDocument13 pagesMatlab-STATISTICAL MODELS AND METHODS FOR FINANCIAL MARKETSGonzalo SaavedraNo ratings yet
- Fitting The Nelson-Siegel-Svensson Model With Differential EvolutionDocument10 pagesFitting The Nelson-Siegel-Svensson Model With Differential Evolutionhappy_24471No ratings yet
- Assignment Extreme Value TheoryDocument11 pagesAssignment Extreme Value Theoryg-74296469No ratings yet
- MSCRWEE Master of Science (Renewable Energy and Environment)Document3 pagesMSCRWEE Master of Science (Renewable Energy and Environment)Vasudev PurNo ratings yet
- EY Artificial Intelligence Esg Stakes Discussion PaperDocument34 pagesEY Artificial Intelligence Esg Stakes Discussion PaperVasudev PurNo ratings yet
- How Leaders Should React When Someone Disappoints HBRDocument5 pagesHow Leaders Should React When Someone Disappoints HBRVasudev PurNo ratings yet
- BCG The-Roadmap-To-A-Green-TransformationDocument7 pagesBCG The-Roadmap-To-A-Green-TransformationVasudev PurNo ratings yet
- Staking Out Climate RiskDocument9 pagesStaking Out Climate RiskVasudev PurNo ratings yet
- ESG - Biodiversity - Senior - EY - LinkedInDocument3 pagesESG - Biodiversity - Senior - EY - LinkedInVasudev PurNo ratings yet
- How To Make Better Decisions With Less Data HBRDocument7 pagesHow To Make Better Decisions With Less Data HBRVasudev PurNo ratings yet
- Lca Environmental Footprinting Xivia Danisco ESG WhitepaperDocument12 pagesLca Environmental Footprinting Xivia Danisco ESG WhitepaperVasudev PurNo ratings yet
- GHG013 enDocument3 pagesGHG013 enVasudev PurNo ratings yet
- ASTM Sustainable Manufacturing Standards Implementation Support 2Document2 pagesASTM Sustainable Manufacturing Standards Implementation Support 2Vasudev PurNo ratings yet
- JEE Advanced Eligibility Criteria 2024 - Age Limit, Qualify Marks, No of Attempts - Aakash Byjus - AESLDocument11 pagesJEE Advanced Eligibility Criteria 2024 - Age Limit, Qualify Marks, No of Attempts - Aakash Byjus - AESLVasudev PurNo ratings yet
- Lca Critical Review Navigating Process ESG WhitepaperDocument8 pagesLca Critical Review Navigating Process ESG WhitepaperVasudev PurNo ratings yet
- Institute of Actuaries of India: ExaminationsDocument9 pagesInstitute of Actuaries of India: ExaminationsVasudev PurNo ratings yet
- JEE Main Cutoff 2024 - Qualifying Cut Off For NITs, IIITs, GFTIsDocument1 pageJEE Main Cutoff 2024 - Qualifying Cut Off For NITs, IIITs, GFTIsVasudev PurNo ratings yet
- CFTC Risk DisclosureDocument32 pagesCFTC Risk DisclosureVasudev PurNo ratings yet
- Institute of Actuaries of India: December 2022 ExaminationDocument8 pagesInstitute of Actuaries of India: December 2022 ExaminationVasudev PurNo ratings yet
- Institute of Actuaries of India: ExaminationsDocument6 pagesInstitute of Actuaries of India: ExaminationsVasudev PurNo ratings yet
- Cpim BSP PDFDocument4 pagesCpim BSP PDFVasudev PurNo ratings yet
- CB1 Business FinanceDocument7 pagesCB1 Business FinanceVasudev PurNo ratings yet
- Institute of Actuaries of India: December 2022 ExaminationDocument9 pagesInstitute of Actuaries of India: December 2022 ExaminationVasudev PurNo ratings yet
- Cpim BSCM PDFDocument5 pagesCpim BSCM PDFVasudev PurNo ratings yet
- Listening P2Document4 pagesListening P2humanistadesmotivadoNo ratings yet
- Beta, CAPM, RF CalculationsDocument8 pagesBeta, CAPM, RF CalculationsPradeesh MenomadathilNo ratings yet
- HOSMER - Chapter 1 Version 2Document3 pagesHOSMER - Chapter 1 Version 2einstein995No ratings yet
- HDFC Health Prime Staff - BrochureDocument6 pagesHDFC Health Prime Staff - BrochureswastikjadavpurNo ratings yet
- Chap 17Document66 pagesChap 1775ndy5b4jsNo ratings yet
- ESP Cable Catalogue 2023.03.28Document15 pagesESP Cable Catalogue 2023.03.28Ricardo CastilloNo ratings yet
- Alphaex Capital Candlestick Pattern Cheat Sheet InfographDocument1 pageAlphaex Capital Candlestick Pattern Cheat Sheet InfographFnudarman Fnudarman100% (1)
- 9335 (Eng)Document322 pages9335 (Eng)home80101No ratings yet
- Anthony AbrahamDocument2 pagesAnthony AbrahamMichael IdowuNo ratings yet
- Quotation - Ceiling Arch - DavidDocument4 pagesQuotation - Ceiling Arch - DavidJohnSerranoNo ratings yet
- Ejercicios MPS (English)Document5 pagesEjercicios MPS (English)Jason Jules Rahul Pierre SevinNo ratings yet
- Peza PDFDocument14 pagesPeza PDFdexterbautistadecember161985No ratings yet
- Sales Quote 2022-VFS-DahuaDocument1 pageSales Quote 2022-VFS-DahuaCornelius KevinNo ratings yet
- Rosewood Hotels Case Study - MM v2Document7 pagesRosewood Hotels Case Study - MM v2Nemish KuvadiaNo ratings yet
- Official Documents Millionaire TrackDocument7 pagesOfficial Documents Millionaire Trackpriyacutex8No ratings yet
- Quadratic EquationsDocument21 pagesQuadratic EquationsBarickASNo ratings yet
- Econ - Article1Document3 pagesEcon - Article1Nicah AcojonNo ratings yet
- Population Variance Is KnownDocument12 pagesPopulation Variance Is KnownMilkysidec RelatorNo ratings yet
- List of E-Books On Economics: S.No TitleDocument7 pagesList of E-Books On Economics: S.No TitleTarleen SinghNo ratings yet
- China'S Economic Growth: Towards Sustainable Economic Development and Social JusticeDocument210 pagesChina'S Economic Growth: Towards Sustainable Economic Development and Social JusticeApoorwa Srivastava100% (1)
- Bent Chair OutdoorsDocument43 pagesBent Chair OutdoorsIshika PunaniNo ratings yet
- Affidavit of Loss of Receipt RDDocument4 pagesAffidavit of Loss of Receipt RDWendell MaunahanNo ratings yet
- Cost of ProductionDocument11 pagesCost of ProductionGia BảoNo ratings yet
- Refinery List PenjualanDocument5 pagesRefinery List PenjualanFendy ShirahNo ratings yet
- University of Mumbai Project On Investment Banking Bachelor of CommerceDocument6 pagesUniversity of Mumbai Project On Investment Banking Bachelor of CommerceParag MoreNo ratings yet
- Merritt Morning Market 3893 - Nov 8Document2 pagesMerritt Morning Market 3893 - Nov 8Kim LeclairNo ratings yet
- Ficha Tecnica FlujometroDocument2 pagesFicha Tecnica FlujometroTatiana Mejías SeguraNo ratings yet