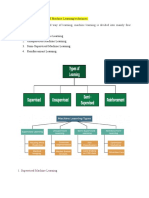
Learning
Learning
Download as pdf or txt
You might also like
- Data Science Project ReportDocument10 pagesData Science Project Reportankitaalai33% (6)
- SCSA3015 Deep Learning Unit 1 Notes PDFDocument30 pagesSCSA3015 Deep Learning Unit 1 Notes PDFpooja vikirthiniNo ratings yet
- (Chapman & Hall - CRC Data Science Series) Brandon M. Greenwell - Tree-Based Methods For Statistical Learning in R - A Practical Introduction With Applications in R-CRC Press (2022)Document405 pages(Chapman & Hall - CRC Data Science Series) Brandon M. Greenwell - Tree-Based Methods For Statistical Learning in R - A Practical Introduction With Applications in R-CRC Press (2022)Lino G. MarujoNo ratings yet
- Internship Report On Machine LearningDocument25 pagesInternship Report On Machine LearningParveen0% (1)
- MarzanoDocument6 pagesMarzanoaqmar77100% (1)
- Ai Unit 4 v2Document17 pagesAi Unit 4 v2Fack WuwuNo ratings yet
- Artificial Intelligence LearningDocument15 pagesArtificial Intelligence LearningSri VardhanNo ratings yet
- AI_Unit-4Document8 pagesAI_Unit-4manishbhardwaj3668No ratings yet
- AI Module 4Document38 pagesAI Module 4FaReeD HamzaNo ratings yet
- General Learning ModelDocument3 pagesGeneral Learning ModelSameer RijalNo ratings yet
- Summer Internship ReportDocument27 pagesSummer Internship ReportSyed ShadNo ratings yet
- Introducti0n (MLT)Document39 pagesIntroducti0n (MLT)Visha VikalNo ratings yet
- Technical Report 2.0Document8 pagesTechnical Report 2.0bhamsuralikhan2019No ratings yet
- Unit 1 NotesDocument29 pagesUnit 1 NotessakthiasphaltalphaNo ratings yet
- Report - Stock Price Prediction DLDocument37 pagesReport - Stock Price Prediction DLnishita KumariNo ratings yet
- ML Doc1Document14 pagesML Doc1vutukuruhaasiniNo ratings yet
- AIML - Practical No.01Document9 pagesAIML - Practical No.01Rohan GhodgeNo ratings yet
- Data Science Solutions IA 2Document16 pagesData Science Solutions IA 2Monesh RallapalliNo ratings yet
- AI Unit 3 Lecture 3Document17 pagesAI Unit 3 Lecture 3Sunil NagarNo ratings yet
- Machine Learning - DataDocument11 pagesMachine Learning - DataAdeeba IramNo ratings yet
- Notes Artificial Intelligence Unit 5Document11 pagesNotes Artificial Intelligence Unit 5Goku KumarNo ratings yet
- Report - Stock Price Prediction DLDocument37 pagesReport - Stock Price Prediction DLnishita KumariNo ratings yet
- unit 4Document20 pagesunit 4Abhishek PathakNo ratings yet
- Learning ScenariosDocument25 pagesLearning ScenariosAnupam BhattaraiNo ratings yet
- Supervised Vs Unsupervised LearningDocument9 pagesSupervised Vs Unsupervised LearningranamzeeshanNo ratings yet
- Supervised Vs Unsupervised LearningDocument9 pagesSupervised Vs Unsupervised Learningdomomwambi100% (1)
- Machine Learning (ML) TechniquesDocument14 pagesMachine Learning (ML) TechniquesMukund TiwariNo ratings yet
- Terms in DSDocument6 pagesTerms in DSLeandro Rocha RímuloNo ratings yet
- Article AReviewOfVariousSemi SuperviseDocument16 pagesArticle AReviewOfVariousSemi SuperviseSatyajit SamalNo ratings yet
- Introduction To Machine Learning Paradigm UpdatedDocument14 pagesIntroduction To Machine Learning Paradigm Updatedyijika6491No ratings yet
- ML U1 2Document4 pagesML U1 2pulkit soniNo ratings yet
- AIML Module - 03 21CS4Document34 pagesAIML Module - 03 21CS4sakshiam12No ratings yet
- 5th Sem ReportDocument29 pages5th Sem ReportRohan RathodNo ratings yet
- Ai Unit5 LearningDocument62 pagesAi Unit5 Learning1DA19CS111 PrajathNo ratings yet
- 6CS4 AI Unit-4 @zammersDocument129 pages6CS4 AI Unit-4 @zammersgagaco5776No ratings yet
- AI Unit 4Document20 pagesAI Unit 4AKSHIT JAINNo ratings yet
- 12 LearningDocument22 pages12 Learningnamanmaurya000No ratings yet
- ML Unit-1 NotesDocument23 pagesML Unit-1 NotesVenkata NareshNo ratings yet
- 6CS4 AI Unit-4Document129 pages6CS4 AI Unit-4Nikhil KumarNo ratings yet
- Marzano's New Taxonomy: The Three Systems and Knowledge Self-SystemDocument5 pagesMarzano's New Taxonomy: The Three Systems and Knowledge Self-SystemPaola ZerezasNo ratings yet
- Turner, Ryan - Python Machine Learning - The Ultimate Beginner's Guide To Learn Python Machine Learning Step by Step Using Scikit-Learn and Tensorflow (2019)Document144 pagesTurner, Ryan - Python Machine Learning - The Ultimate Beginner's Guide To Learn Python Machine Learning Step by Step Using Scikit-Learn and Tensorflow (2019)Daniel GNo ratings yet
- What Is Machine Learning-UNIT IIIDocument12 pagesWhat Is Machine Learning-UNIT IIImanglamdubey2011No ratings yet
- Training Report On Machine LearningDocument27 pagesTraining Report On Machine LearningBhavesh yadavNo ratings yet
- Supervised and Deep LearningDocument83 pagesSupervised and Deep LearninglegendfortuneubgNo ratings yet
- Unit No: 1 Introduction To Machine Learning (3170724) : Department of CEDocument28 pagesUnit No: 1 Introduction To Machine Learning (3170724) : Department of CEfoodiebuddy999No ratings yet
- Learning Scenarios Supervised Learning Unsupervised Learning Unit 1 Part BDocument25 pagesLearning Scenarios Supervised Learning Unsupervised Learning Unit 1 Part BAnkur ChoudharyNo ratings yet
- Machine Learning and Eural EtworkDocument21 pagesMachine Learning and Eural EtworkRedmond R. Shamshiri100% (1)
- 4 Lesson 01Document5 pages4 Lesson 01mec17b209No ratings yet
- ML 3170724 Unit-1Document27 pagesML 3170724 Unit-1Hetvy JadejaNo ratings yet
- Ybi Python Final Internship ReportDocument29 pagesYbi Python Final Internship ReportRishu Cs 32100% (6)
- ML Unit 1 NotesDocument134 pagesML Unit 1 NotesAnkit MauryaNo ratings yet
- Unit-1-Introduction (Fundamentals of ML & AI) January 29, 2024Document80 pagesUnit-1-Introduction (Fundamentals of ML & AI) January 29, 2024Arin DanielNo ratings yet
- Module 03Document54 pagesModule 03Pushpak ChakrabortyNo ratings yet
- AIML Module - 03Document34 pagesAIML Module - 03bashantr29No ratings yet
- L01 - Introduction-to-MLDocument10 pagesL01 - Introduction-to-MLsayali sonavaneNo ratings yet
- Lecture - 32 - 33Document65 pagesLecture - 32 - 33spandansahil15No ratings yet
- ASSIGNMENT 1 Mavhine LearningDocument8 pagesASSIGNMENT 1 Mavhine LearningThe RockyFFNo ratings yet
- Machine LearningDocument6 pagesMachine LearningJudah PraiseNo ratings yet
- MLT Unit 1Document15 pagesMLT Unit 1sahil.utube2003No ratings yet
- MACHINE LEARNING FOR BEGINNERS: A Practical Guide to Understanding and Applying Machine Learning Concepts (2023 Beginner Crash Course)From EverandMACHINE LEARNING FOR BEGINNERS: A Practical Guide to Understanding and Applying Machine Learning Concepts (2023 Beginner Crash Course)No ratings yet
- PythonDocument65 pagesPythonAnilNo ratings yet
- AI UNIT - 5 NotesDocument10 pagesAI UNIT - 5 Notesneelu guptaNo ratings yet
- 11 W11NSE6220 - Fall 2023 - ZengDocument43 pages11 W11NSE6220 - Fall 2023 - Zengrahul101056No ratings yet
- Analytix Labs Data Science CourseDocument18 pagesAnalytix Labs Data Science CourseHonest Business Services100% (1)
- Machine Learing AlgorithmsDocument13 pagesMachine Learing AlgorithmsNexgen TechnologyNo ratings yet
- Thesis PresentationDocument35 pagesThesis PresentationShaaf AmjadNo ratings yet
- Week 5 - Decision TreesDocument42 pagesWeek 5 - Decision TreesDoğukanNo ratings yet
- Fulldoc - Dsec Mca - Crime PredictionDocument56 pagesFulldoc - Dsec Mca - Crime PredictionDSEC-MCANo ratings yet
- DM - 01 - 02 - Data Mining Functionalities PDFDocument63 pagesDM - 01 - 02 - Data Mining Functionalities PDFshouryaraj batraNo ratings yet
- ML Sheet01 Handout PDFDocument3 pagesML Sheet01 Handout PDFOishikNo ratings yet
- MLT Unit-3 Important QuestionsDocument8 pagesMLT Unit-3 Important QuestionsJitendra KumarNo ratings yet
- IT446 Test BankDocument57 pagesIT446 Test BankZaina BarhamNo ratings yet
- Classification: Basic Concepts and Decision TreesDocument56 pagesClassification: Basic Concepts and Decision TreesMd Shazman AnwarNo ratings yet
- IJRPR6647Document4 pagesIJRPR6647Anas AhmadNo ratings yet
- 01 Ml-Overview SlidesDocument58 pages01 Ml-Overview Slidesashishamitav123No ratings yet
- Machine-Learning Research: Four Current DirectionsDocument40 pagesMachine-Learning Research: Four Current DirectionsAndreas KarasNo ratings yet
- ML Assignment 2Document25 pagesML Assignment 2Abs WpsNo ratings yet
- Free Download Data Science Curriculum - Innomatics Research Labs Hyderabad, IndiaDocument14 pagesFree Download Data Science Curriculum - Innomatics Research Labs Hyderabad, IndiaAkash InnomaticsNo ratings yet
- Anurag Nayak ReportDocument36 pagesAnurag Nayak Reporthimanshubehera73No ratings yet
- Using Data Mining To Predict Student PerformanceDocument12 pagesUsing Data Mining To Predict Student PerformanceLuis PinedaNo ratings yet
- Apl I Kasi Data MiningDocument44 pagesApl I Kasi Data MiningJack CodeNo ratings yet
- Pore Pressure Prediction by Machine Learning TechniquesDocument15 pagesPore Pressure Prediction by Machine Learning TechniqueshadermanNo ratings yet
- Data Mining - Output: Knowledge RepresentationDocument30 pagesData Mining - Output: Knowledge RepresentationA.J KhanNo ratings yet
- A Customer Profiling Methodology For Churn Prediction - Hadden - Thesis - 2008 PDFDocument313 pagesA Customer Profiling Methodology For Churn Prediction - Hadden - Thesis - 2008 PDFcatalin_ilie_5100% (1)
- Applications of TOP 10 AlgorithmsDocument16 pagesApplications of TOP 10 AlgorithmssharathNo ratings yet
- Computers and Structures: Jalal Kiani, Charles Camp, Shahram PezeshkDocument15 pagesComputers and Structures: Jalal Kiani, Charles Camp, Shahram Pezeshkhamid ghorbaniNo ratings yet
- Machine Learning With Decision Trees and Random Forest ?Document31 pagesMachine Learning With Decision Trees and Random Forest ?HARSH KUMARNo ratings yet
- Synthpop: Bespoke Creation of Synthetic Data in R: Beata Nowok Gillian M Raab Chris DibbenDocument26 pagesSynthpop: Bespoke Creation of Synthetic Data in R: Beata Nowok Gillian M Raab Chris Dibbenh1ghw1nd1No ratings yet