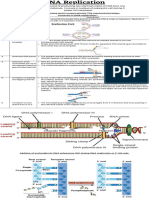
Central Dogma
Central Dogma
Download as pdf or txt
You might also like
- DNA Replication and Protein SynthesisDocument5 pagesDNA Replication and Protein SynthesisFrezelVillaBasiloniaNo ratings yet
- Replikasi DNA Dan Sintesis Protein (Gabungan)Document62 pagesReplikasi DNA Dan Sintesis Protein (Gabungan)adinda tyasprabandariNo ratings yet
- DNA ReplicationDocument28 pagesDNA ReplicationAsim Bin Arshad 58-FBAS/BSBIO/S19100% (1)
- Molecular BiologyDocument2 pagesMolecular BiologyJaymark HisonaNo ratings yet
- Chapter 12 Glencoe Biology Study GuideDocument11 pagesChapter 12 Glencoe Biology Study GuideabdulazizalobaidiNo ratings yet
- DNA Replication IDocument8 pagesDNA Replication IHarish GNo ratings yet
- Compressed Notes Chapter 6: Expression of Biological Information Sb015Document10 pagesCompressed Notes Chapter 6: Expression of Biological Information Sb015SYAZWAN BIN MUSTAFA MoeNo ratings yet
- Chapter 11 OutlineDocument9 pagesChapter 11 Outlinehomaidey23No ratings yet
- DNA Replication and RepairDocument7 pagesDNA Replication and RepairJhun Lerry TayanNo ratings yet
- Central Dogma of BiologyDocument6 pagesCentral Dogma of BiologyJhun Lerry TayanNo ratings yet
- Nucleic Acids NOTESDocument8 pagesNucleic Acids NOTESelaineNo ratings yet
- Biochem QuinDocument4 pagesBiochem QuinKingNo ratings yet
- DNA ReplicationDocument21 pagesDNA ReplicationP Santosh KumarNo ratings yet
- DNA Replication-UGDocument6 pagesDNA Replication-UGAjeesh JosephNo ratings yet
- Central Dogma: Dna ReplicationDocument18 pagesCentral Dogma: Dna ReplicationAkhil KumarNo ratings yet
- Dna ReplicateDocument31 pagesDna ReplicatedevinahNo ratings yet
- Nucleic Acids.Document18 pagesNucleic Acids.kasingabalyaandrewNo ratings yet
- DNA ReplicationDocument5 pagesDNA Replicationreccelle_pre295747No ratings yet
- BG-Lecture 2Document19 pagesBG-Lecture 2NAYYAB SHAHZADNo ratings yet
- Central Dogma of Molecular Biology PDFDocument32 pagesCentral Dogma of Molecular Biology PDFStephy LimboNo ratings yet
- DNA Vs RNA & DNA REPLICATION Vs TRANSCRIPTIONDocument18 pagesDNA Vs RNA & DNA REPLICATION Vs TRANSCRIPTIONSweet PotatoeNo ratings yet
- DNA Replication, The Basis ForDocument23 pagesDNA Replication, The Basis ForDiana M. LlonaNo ratings yet
- DNA ReplicationDocument7 pagesDNA ReplicationMuhammad QayumNo ratings yet
- Dna RepDocument1 pageDna Rep2022495346No ratings yet
- (Lecture 2) GenesDocument39 pages(Lecture 2) GenesKasraSrNo ratings yet
- Presentationprint TempDocument27 pagesPresentationprint TempGandepelli SwetchaNo ratings yet
- Replication of Dna NotesDocument12 pagesReplication of Dna NotesShibani PradhanNo ratings yet
- Replication, Transcription, Translation, Mutation HWDocument20 pagesReplication, Transcription, Translation, Mutation HWtahamidNo ratings yet
- DNA, Replication, Gene Expression and Genetics-1Document62 pagesDNA, Replication, Gene Expression and Genetics-1Manar AnwerNo ratings yet
- Module 2 Heredity - Inheritance and Variation Central DogmaDocument36 pagesModule 2 Heredity - Inheritance and Variation Central Dogmaseph20lupozNo ratings yet
- 6 BIO462 Chapter 6Document21 pages6 BIO462 Chapter 6Syafiqah SuhaimiNo ratings yet
- Semi-Conservative DNA ReplicationDocument12 pagesSemi-Conservative DNA ReplicationDibyakNo ratings yet
- Tutorial Case 2 Learning GoalsDocument6 pagesTutorial Case 2 Learning GoalsseppaendekerkNo ratings yet
- Protein Synthesis NotesDocument6 pagesProtein Synthesis NotesRokunuz Jahan RudroNo ratings yet
- Genes and Protein SynthesisDocument7 pagesGenes and Protein SynthesisbrayonosoroNo ratings yet
- DNA ReplicationDocument5 pagesDNA ReplicationNikki SStarkNo ratings yet
- Dna & RnaDocument8 pagesDna & Rnamariam.1119028No ratings yet
- ScienceDocument7 pagesScienceRonald Alexandrei TropelNo ratings yet
- Lecture 2Document48 pagesLecture 2KrishNo ratings yet
- Nucleic Acids (HL)Document23 pagesNucleic Acids (HL)Boris-Jeremie-Latyr GueyeNo ratings yet
- Dnareplication2 170410185549Document20 pagesDnareplication2 170410185549sajawalrehman687No ratings yet
- Genetic Research PaperDocument10 pagesGenetic Research PaperDev raj regmiNo ratings yet
- Dna ReplicationDocument21 pagesDna ReplicationGhost IraQNo ratings yet
- Structure of DNA Science Presentation in Light Blue Green Lined Style 20240314 1Document26 pagesStructure of DNA Science Presentation in Light Blue Green Lined Style 20240314 1leighariazbongsNo ratings yet
- Nucleic Acids and Their FunctionsDocument2 pagesNucleic Acids and Their FunctionsgreengreenplanksNo ratings yet
- Biochem Group ProjDocument21 pagesBiochem Group ProjYves Christian PineNo ratings yet
- Nucleic Acids ChemistryDocument68 pagesNucleic Acids ChemistryAlok DhelditNo ratings yet
- CH 16 and 17 Worksheet-1Document3 pagesCH 16 and 17 Worksheet-1Dani Jo OwensNo ratings yet
- BT 101 KS MidsemDocument1 pageBT 101 KS MidsemthedogbirdsNo ratings yet
- MBC 331 NOTE 1Document13 pagesMBC 331 NOTE 1NwankwoNo ratings yet
- Class 12 DnareplicaDocument5 pagesClass 12 Dnareplicakrishgaming1311No ratings yet
- DNA Replication: Molecular Biology DNA Living Organisms Biological InheritanceDocument2 pagesDNA Replication: Molecular Biology DNA Living Organisms Biological InheritancePretty UNo ratings yet
- 2 - Nucleic Acid Replication, Transcription & Translation - ModuleDocument15 pages2 - Nucleic Acid Replication, Transcription & Translation - ModuleMichaella CabanaNo ratings yet
- BCH 305 (Chemistry & Metabolism of Nucleic Acids)Document30 pagesBCH 305 (Chemistry & Metabolism of Nucleic Acids)ihebunnaogochukwu24No ratings yet
- REPLICATIONDocument9 pagesREPLICATIONdineshNo ratings yet
- Replication PDFDocument12 pagesReplication PDFYi LingNo ratings yet
- Dna Replication and Protein SynthesisDocument12 pagesDna Replication and Protein Synthesisromelreston04No ratings yet
- Biology Notes DddxfymcfmcghDocument7 pagesBiology Notes Dddxfymcfmcghthirumalaivasan GNo ratings yet
- Chaper-01 Biology Faderal BoardDocument46 pagesChaper-01 Biology Faderal BoardHifza BalouchNo ratings yet
- Fyfe Et Al. (2014) Interference Between Concurrent Resistance and Endurance Exercise - Molecular Bases and The Role of Individual Training Variables PDFDocument23 pagesFyfe Et Al. (2014) Interference Between Concurrent Resistance and Endurance Exercise - Molecular Bases and The Role of Individual Training Variables PDFkévinNo ratings yet
- Ethem Murat Arsava (Eds.) - Nutrition in Neurologic Disorders - A Practical Guide (2017, Springer International Publishing)Document209 pagesEthem Murat Arsava (Eds.) - Nutrition in Neurologic Disorders - A Practical Guide (2017, Springer International Publishing)riddhiNo ratings yet
- Animal Physiology PDFDocument111 pagesAnimal Physiology PDFShahnawaz MustafaNo ratings yet
- Poly (A) Tail Regulation in The Nucleus, Thesis, 2022Document205 pagesPoly (A) Tail Regulation in The Nucleus, Thesis, 2022atpowrNo ratings yet
- Cell DivisionDocument28 pagesCell Divisionstan.suineg100% (1)
- Cell PartsDocument28 pagesCell PartsArim ArimNo ratings yet
- Odd OxiDocument10 pagesOdd OxiKarl Torres Uganiza RmtNo ratings yet
- Exercise 5Document5 pagesExercise 5holie madroneroNo ratings yet
- Bio Adv CC CH 03 - Cell Biology - Answer Keys (10.03.15)Document29 pagesBio Adv CC CH 03 - Cell Biology - Answer Keys (10.03.15)Margie OpayNo ratings yet
- June 2017 QP - Paper 1 Edexcel Biology (B) AS-levelDocument28 pagesJune 2017 QP - Paper 1 Edexcel Biology (B) AS-levelbgtes123No ratings yet
- DLL Do SCI g10 Q3 Week6 22 23Document8 pagesDLL Do SCI g10 Q3 Week6 22 23NURSHAHADAH ISMAELNo ratings yet
- Cell Structure 3Document30 pagesCell Structure 3Rohan PaneruNo ratings yet
- Capillary Electrophoresis Method Change - 08 - 08Document2 pagesCapillary Electrophoresis Method Change - 08 - 08Samar SharafNo ratings yet
- Course Outline Nutritional Biochemistry HNDDocument2 pagesCourse Outline Nutritional Biochemistry HNDMujtabaNo ratings yet
- Fibronectin: Fibronectin Is A High-MolecularDocument22 pagesFibronectin: Fibronectin Is A High-Molecularfelipe smithNo ratings yet
- Amino Acids Metabolism, Functions, and NutritionDocument17 pagesAmino Acids Metabolism, Functions, and NutritionJulio de Sousa100% (1)
- Genome Organization - 2020Document26 pagesGenome Organization - 2020Bagus Arya MahartaNo ratings yet
- CRISPR Regulators of Cancer Cell PhagocytosisDocument32 pagesCRISPR Regulators of Cancer Cell Phagocytosiskatie weiNo ratings yet
- Photosynthesis: STEP Grade 9Document14 pagesPhotosynthesis: STEP Grade 9Lo ViNo ratings yet
- Fred Review 16Document8 pagesFred Review 16Justin HsuNo ratings yet
- Cell ComponentsDocument17 pagesCell ComponentsAlla Mae CastroNo ratings yet
- Sapphire Baculovirus DNADocument2 pagesSapphire Baculovirus DNAAlleleBiotechNo ratings yet
- Primer Design 2013 PDFDocument58 pagesPrimer Design 2013 PDFMaila EscuderoNo ratings yet
- 1876 Robert KochDocument6 pages1876 Robert KochSarah PavuNo ratings yet
- Mardinoglu 2014Document14 pagesMardinoglu 2014Julia SCNo ratings yet
- Singkatan Arti Atau Kepanjangan DI LABORATORIUMDocument6 pagesSingkatan Arti Atau Kepanjangan DI LABORATORIUMDIANNo ratings yet
- Entry Level Genetics Notes.Document3 pagesEntry Level Genetics Notes.Joy SmokeNo ratings yet
- PharmacogeneticsDocument30 pagesPharmacogeneticsShailendra Sk100% (3)
- Kami Export - Pogil DNA Vs RNADocument3 pagesKami Export - Pogil DNA Vs RNAEva EllisNo ratings yet