0% found this document useful (0 votes)
6 viewsPython 1
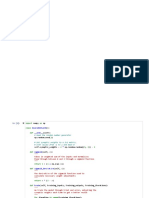
The document contains a Python implementation of a multilayer perceptron (MLP) neural network that uses the sigmoid activation function. It includes methods for forward propagation, backward propagation, and training the model on XOR logic gate data. The model is trained for 10,000 epochs and outputs predictions based on the input data.
Uploaded by
MOHAMMED BOUKANTARCopyright
© © All Rights Reserved
Available Formats
Download as DOCX, PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
6 viewsPython 1
The document contains a Python implementation of a multilayer perceptron (MLP) neural network that uses the sigmoid activation function. It includes methods for forward propagation, backward propagation, and training the model on XOR logic gate data. The model is trained for 10,000 epochs and outputs predictions based on the input data.
Uploaded by
MOHAMMED BOUKANTARCopyright
© © All Rights Reserved
Available Formats
Download as DOCX, PDF, TXT or read online on Scribd
/ 2