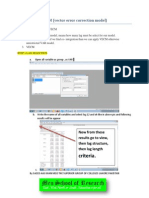
Guided Tour On VAR Innovation Response Analysis
Guided Tour On VAR Innovation Response Analysis
Download as doc, pdf, or txt
You might also like
- Midterm Question - Time Series Analysis - UpdatedDocument3 pagesMidterm Question - Time Series Analysis - UpdatedAakriti JainNo ratings yet
- Dynamic Inefficiency When The Expected Return On Capital Is Greater Than The Growth RateDocument9 pagesDynamic Inefficiency When The Expected Return On Capital Is Greater Than The Growth RateRobertWaldmannNo ratings yet
- yit = β0 + β1xit,1 + β2xit,2 + β3xit,3 + β4xit,4 + uit ,x ,x ,x ,β ,β ,β ,βDocument10 pagesyit = β0 + β1xit,1 + β2xit,2 + β3xit,3 + β4xit,4 + uit ,x ,x ,x ,β ,β ,β ,βSaad MasoodNo ratings yet
- Analysis of German Credit DataDocument24 pagesAnalysis of German Credit Datasavvy_as_98-1100% (1)
- Ae 311 Midterm Exam PartDocument13 pagesAe 311 Midterm Exam PartSamsung AccountNo ratings yet
- AutocorrelationDocument172 pagesAutocorrelationJenab Peteburoh100% (1)
- An Introduction To Bayesian VAR (BVAR) Models R-EconometricsDocument16 pagesAn Introduction To Bayesian VAR (BVAR) Models R-EconometricseruygurNo ratings yet
- Business and Economic Forecasting EMET3007/EMET8012 Problem Set 1Document2 pagesBusiness and Economic Forecasting EMET3007/EMET8012 Problem Set 1Ly SopheaNo ratings yet
- Principles of Econometrics 4e Chapter 2 SolutionDocument33 pagesPrinciples of Econometrics 4e Chapter 2 SolutionHoyin Kwok84% (19)
- VECMDocument9 pagesVECMsaeed meo100% (3)
- Vector Autoregressions: How To Choose The Order of A VARDocument8 pagesVector Autoregressions: How To Choose The Order of A VARv4nhuy3nNo ratings yet
- SVAR Notes: Learn in PersonDocument19 pagesSVAR Notes: Learn in PersonEconometrics FreelancerNo ratings yet
- Structural VAR and Applications: Jean-Paul RenneDocument55 pagesStructural VAR and Applications: Jean-Paul RennerunawayyyNo ratings yet
- About The MS Regression ModelsDocument17 pagesAbout The MS Regression ModelsLars LarsonNo ratings yet
- Application of Smooth Transition Autoregressive (STAR) Models For Exchange RateDocument10 pagesApplication of Smooth Transition Autoregressive (STAR) Models For Exchange Ratedecker4449No ratings yet
- VAR, SVAR and VECMDocument57 pagesVAR, SVAR and VECMjohnpaulcorpus100% (1)
- About The MS Regress PackageDocument28 pagesAbout The MS Regress PackagegliptakNo ratings yet
- Lucas - Econometric Policy Evaluation, A CritiqueDocument28 pagesLucas - Econometric Policy Evaluation, A CritiqueFederico Perez CusseNo ratings yet
- Threshold SlidesDocument6 pagesThreshold SlidesoptoergoNo ratings yet
- Panel DataDocument13 pagesPanel DataAzime Hassen100% (1)
- Cointegration CopenhagenDocument51 pagesCointegration CopenhagenCLIDER100% (1)
- Generalized Method of Moments (GMM) Estimation: OutlineDocument16 pagesGeneralized Method of Moments (GMM) Estimation: OutlineDione BhaskaraNo ratings yet
- The Basic New Keynesian Model: Josef StráskýDocument29 pagesThe Basic New Keynesian Model: Josef StráskýTiago MatosNo ratings yet
- 05 GMM (Annotated)Document106 pages05 GMM (Annotated)Widya RezaNo ratings yet
- DSGE AfricaDocument13 pagesDSGE AfricaWalaa Mahrous100% (1)
- Static Games With Incomplete InformationDocument8 pagesStatic Games With Incomplete InformationHoangluciaNo ratings yet
- Poisson RegressionDocument12 pagesPoisson RegressionRajat GargNo ratings yet
- 01A Introduction To Economic Time SeriesDocument26 pages01A Introduction To Economic Time SeriesFaizus Saquib ChowdhuryNo ratings yet
- MSM Specification: Discrete TimeDocument5 pagesMSM Specification: Discrete TimeNicolas MarionNo ratings yet
- Lecture Series 1 Linear Random and Fixed Effect Models and Their (Less) Recent ExtensionsDocument62 pagesLecture Series 1 Linear Random and Fixed Effect Models and Their (Less) Recent ExtensionsDaniel Bogiatzis GibbonsNo ratings yet
- Structural VAR Using EviewsDocument8 pagesStructural VAR Using EviewsOladipupo Mayowa PaulNo ratings yet
- Between Within Stata AnalysisDocument3 pagesBetween Within Stata AnalysisMaria PappaNo ratings yet
- Panel VARDocument29 pagesPanel VARsalihuNo ratings yet
- Stata Ts Introduction To Time-Series CommandsDocument6 pagesStata Ts Introduction To Time-Series CommandsngocmimiNo ratings yet
- Goodness of Fit Negative Binomial RDocument3 pagesGoodness of Fit Negative Binomial RTimothyNo ratings yet
- ECONOMETRICDocument50 pagesECONOMETRICjeanpier dcostaNo ratings yet
- Var SvarDocument31 pagesVar SvarEddie Barrionuevo100% (1)
- 004 - Modelling Volatility - Arch and Garch ModelsDocument31 pages004 - Modelling Volatility - Arch and Garch ModelsĐông Đông0% (1)
- Topic 7. VAR ModelsDocument44 pagesTopic 7. VAR ModelsTuấn ĐinhNo ratings yet
- Solutions - PS5 (DAE)Document23 pagesSolutions - PS5 (DAE)icisanmanNo ratings yet
- Generalized Method of Moments Estimation PDFDocument29 pagesGeneralized Method of Moments Estimation PDFraghidkNo ratings yet
- Ch2 SlidesDocument80 pagesCh2 SlidesYiLinLiNo ratings yet
- Var SlidesDocument28 pagesVar SlidespinakimahataNo ratings yet
- Advanced Stata WorkshopDocument59 pagesAdvanced Stata WorkshopHector GarciaNo ratings yet
- 2SLS Klein Macro PDFDocument4 pages2SLS Klein Macro PDFNiken DwiNo ratings yet
- Panel DataDocument9 pagesPanel DataMarkWeberNo ratings yet
- ARCH ModelDocument26 pagesARCH ModelAnish S.MenonNo ratings yet
- GMM StataDocument27 pagesGMM StataMao CardenasNo ratings yet
- Forecasting and VAR Models - PresentationDocument11 pagesForecasting and VAR Models - PresentationFranz EignerNo ratings yet
- Markov Interest Rate Models - Hagan and WoodwardDocument28 pagesMarkov Interest Rate Models - Hagan and WoodwardlucaliberaceNo ratings yet
- GSEMModellingusingStata PDFDocument97 pagesGSEMModellingusingStata PDFmarikum74No ratings yet
- Linear Regression Analysis For STARDEX: Trend CalculationDocument6 pagesLinear Regression Analysis For STARDEX: Trend CalculationSrinivasu UpparapalliNo ratings yet
- ARDL Models-Bounds TestingDocument17 pagesARDL Models-Bounds Testingmzariab88% (8)
- Testing Mediation Using Medsem' Package in StataDocument17 pagesTesting Mediation Using Medsem' Package in StataAftab Tabasam0% (1)
- Heath Jarrow Morton A Interest Rate Model For CVA CalculationsDocument9 pagesHeath Jarrow Morton A Interest Rate Model For CVA CalculationsAlexis MaenhoutNo ratings yet
- Ize y Yeyati (2003) - Financial DollarizationDocument25 pagesIze y Yeyati (2003) - Financial DollarizationEduardo MartinezNo ratings yet
- Introduction To Regression Models For Panel Data Analysis Indiana University Workshop in Methods October 7, 2011 Professor Patricia A. McmanusDocument42 pagesIntroduction To Regression Models For Panel Data Analysis Indiana University Workshop in Methods October 7, 2011 Professor Patricia A. McmanusAnonymous 0sxQqwAIMBNo ratings yet
- TSExamples PDFDocument9 pagesTSExamples PDFKhalilNo ratings yet
- Lec06 - Panel DataDocument160 pagesLec06 - Panel DataTung NguyenNo ratings yet
- Monetary Policy - NotesDocument12 pagesMonetary Policy - NotesPedroNo ratings yet
- Solutions Manual to Accompany Introduction to Quantitative Methods in Business: with Applications Using Microsoft Office ExcelFrom EverandSolutions Manual to Accompany Introduction to Quantitative Methods in Business: with Applications Using Microsoft Office ExcelNo ratings yet
- Dau Tu (Mi)Document32 pagesDau Tu (Mi)runawayyyNo ratings yet
- A "How To" Guide For Stress Testing The ERM WayDocument14 pagesA "How To" Guide For Stress Testing The ERM WayrunawayyyNo ratings yet
- Chapter 15Document29 pagesChapter 15runawayyyNo ratings yet
- Chapter 14Document20 pagesChapter 14runawayyyNo ratings yet
- Chapter 13Document17 pagesChapter 13runawayyyNo ratings yet
- CH 19 Rose8eDocument21 pagesCH 19 Rose8erunawayyyNo ratings yet
- CH 03 Rose8eDocument30 pagesCH 03 Rose8erunawayyyNo ratings yet
- Monte Carlo AdvDocument44 pagesMonte Carlo AdvrunawayyyNo ratings yet
- Monte Carlo Simple UpdateDocument23 pagesMonte Carlo Simple UpdaterunawayyyNo ratings yet
- US Financial CrisisDocument28 pagesUS Financial CrisisrunawayyyNo ratings yet
- Time Series: Scholarship StatisticsDocument6 pagesTime Series: Scholarship StatisticsJeffNo ratings yet
- 6) BIOSTATISTICsDocument99 pages6) BIOSTATISTICsMadhulikaNo ratings yet
- Fin534 Ci Oct22Document4 pagesFin534 Ci Oct22SITI NUR FARAHANA MAZLANNo ratings yet
- Math 250 Elements of Statistics / Tutorialoutlet Dot ComDocument4 pagesMath 250 Elements of Statistics / Tutorialoutlet Dot Comalbert0077No ratings yet
- Supervised Learning in R ClassificationDocument7 pagesSupervised Learning in R ClassificationOctavio FloresNo ratings yet
- 1Document4 pages1نور الفاتحةNo ratings yet
- Supervised Learning: Hadrien LacroixDocument85 pagesSupervised Learning: Hadrien LacroixRoberto MacielNo ratings yet
- Methods For Identifying Out of Trends in Ongoing StabilityDocument10 pagesMethods For Identifying Out of Trends in Ongoing StabilityPiruzi MaghlakelidzeNo ratings yet
- LESSON 1 Prob Stat 4th QuarterDocument26 pagesLESSON 1 Prob Stat 4th QuarterKishma ItoNo ratings yet
- Paired-Samples T-Test Using SPSSDocument31 pagesPaired-Samples T-Test Using SPSSVenice izza VenancioNo ratings yet
- Wingspan Length of Ateneo Undergraduate StudentsDocument4 pagesWingspan Length of Ateneo Undergraduate StudentsJV GamoNo ratings yet
- Bessel's CorrectionDocument8 pagesBessel's CorrectionCarlos Cuevas LópezNo ratings yet
- Stat2 2023 Syllabus B v1.0 Weeks 5-6-7Document41 pagesStat2 2023 Syllabus B v1.0 Weeks 5-6-7Andrei PopaNo ratings yet
- Risk and Return A - SolutionsDocument3 pagesRisk and Return A - SolutionsmilotikyuNo ratings yet
- Item Analysis 2018 - 2019Document8 pagesItem Analysis 2018 - 2019Bill VillonNo ratings yet
- Sta101 - Project: Professor: Vinay VachharajaniDocument14 pagesSta101 - Project: Professor: Vinay VachharajaniKING RAMBONo ratings yet
- Download Solution manual for Introduction to Econometrics 3rd edition by James H Stock Mark W Watson James H Stock Mark W Watson ebook All Chapters PDFDocument40 pagesDownload Solution manual for Introduction to Econometrics 3rd edition by James H Stock Mark W Watson James H Stock Mark W Watson ebook All Chapters PDFlabesshollkfNo ratings yet
- Test Bank For Statistics For Business and Economics 12th Edition AndersonDocument25 pagesTest Bank For Statistics For Business and Economics 12th Edition Andersona516275311No ratings yet
- Spearman'S Rank Correlation Coefficient: Miguel Angelo Oboza ConcioDocument25 pagesSpearman'S Rank Correlation Coefficient: Miguel Angelo Oboza ConcioJohn Marvin CanariaNo ratings yet
- AssignmentDocument2 pagesAssignmentRuchiNo ratings yet
- Safety Climate Factors, Group Differences and Safety Behaviour in Road ConstructionDocument32 pagesSafety Climate Factors, Group Differences and Safety Behaviour in Road ConstructionOlivia ScullyNo ratings yet
- STATA - Logit-Probit-Tobit - IInd Sem 23-24Document84 pagesSTATA - Logit-Probit-Tobit - IInd Sem 23-24f20212579No ratings yet
- CA35P Business Data AnalyticsDocument4 pagesCA35P Business Data Analyticsmosotirobert30No ratings yet
- G023: Econometrics: J Er Ome AddaDocument154 pagesG023: Econometrics: J Er Ome AddaLilia XaNo ratings yet
- Instant Access to Statistics: Unlocking the Power of Data, 2nd Edition (eBook PDF) ebook Full ChaptersDocument41 pagesInstant Access to Statistics: Unlocking the Power of Data, 2nd Edition (eBook PDF) ebook Full Chaptersmyiamyubit100% (2)
- Quantitative MethodsDocument9 pagesQuantitative Methodsumushtaq005No ratings yet
- Descriptive Statistics Using Microsoft ExcelDocument5 pagesDescriptive Statistics Using Microsoft ExcelVasant bhoknalNo ratings yet
- Leslie Salt Property Project ReportDocument10 pagesLeslie Salt Property Project ReportAgnish KarNo ratings yet