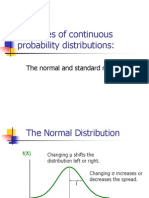
Normal Distribution 2012
Normal Distribution 2012
Download as ppt, pdf, or txt
You might also like
- The Practically Cheating Statistics Handbook, The Sequel! (2nd Edition)From EverandThe Practically Cheating Statistics Handbook, The Sequel! (2nd Edition)Rating: 4.5 out of 5 stars4.5/5 (3)
- Tiny Dungeon 2nd - Treasure DeckDocument104 pagesTiny Dungeon 2nd - Treasure DeckJacobo CisnerosNo ratings yet
- H4 ExpectedValue NormalDistribution SolutionDocument6 pagesH4 ExpectedValue NormalDistribution SolutionHennrocksNo ratings yet
- Emergency PreparednessDocument46 pagesEmergency PreparednessBosh Cosh TrainingsNo ratings yet
- NormalDistribution2012 PDFDocument29 pagesNormalDistribution2012 PDFElisa Dela Reyna BaladadNo ratings yet
- Normal Distribution 2012Document29 pagesNormal Distribution 2012kya karegaNo ratings yet
- Normal Distribution 2012Document29 pagesNormal Distribution 2012Isaac Daplas RosarioNo ratings yet
- Let LetDocument29 pagesLet LetIsaac Daplas RosarioNo ratings yet
- Normal 30Document2 pagesNormal 30Kerdid SimbolonNo ratings yet
- 5 Z&NormalDocument33 pages5 Z&NormalRosemarie GasparNo ratings yet
- Vi. Standard Scores and The Normal DistributionDocument6 pagesVi. Standard Scores and The Normal DistributioncarterreesNo ratings yet
- Normal 30Document2 pagesNormal 30shuddlesNo ratings yet
- Methods GuideDocument16 pagesMethods GuideBrigitta DomokosNo ratings yet
- Z-Scores, The Normal Curve, & Standard Error of The MeanDocument33 pagesZ-Scores, The Normal Curve, & Standard Error of The MeanDåvê D. BãçølōtNo ratings yet
- Saint Joseph College Senior High School Department Tunga-Tunga, Maasin City, Southern Leyte 6600 PhilippinesDocument11 pagesSaint Joseph College Senior High School Department Tunga-Tunga, Maasin City, Southern Leyte 6600 PhilippinesJimkenneth RanesNo ratings yet
- Examples of Continuous Probability Distributions:: The Normal and Standard NormalDocument57 pagesExamples of Continuous Probability Distributions:: The Normal and Standard NormalPawan JajuNo ratings yet
- QTM Cycle 7 Session 4Document79 pagesQTM Cycle 7 Session 4OttilieNo ratings yet
- Week11-Normal Distribution (Ekstra-Week)Document59 pagesWeek11-Normal Distribution (Ekstra-Week)düşünennurNo ratings yet
- Normal CurveDocument37 pagesNormal CurveNeerajNo ratings yet
- Data Types:: Basic StatisticsDocument23 pagesData Types:: Basic StatisticsmaheshsakharpeNo ratings yet
- Normal Distribution StanfordDocument43 pagesNormal Distribution Stanfordapi-204699162100% (1)
- Probability and SamplingDistributionsDocument59 pagesProbability and SamplingDistributionsRmro Chefo LuigiNo ratings yet
- Examples of Continuous Probability Distributions:: The Normal and Standard NormalDocument57 pagesExamples of Continuous Probability Distributions:: The Normal and Standard NormalAkshay VetalNo ratings yet
- Chapter 4: Standardized Scores and The Normal DistributionDocument9 pagesChapter 4: Standardized Scores and The Normal DistributionGunalatcumy KarunanitheNo ratings yet
- Normal Distribution1Document21 pagesNormal Distribution1Rabin BaniyaNo ratings yet
- Standard Scores and The Normal Curve: Report Presentation byDocument38 pagesStandard Scores and The Normal Curve: Report Presentation byEmmanuel AbadNo ratings yet
- Unit 3 Z-Scores, Measuring Performance: Learning OutcomeDocument10 pagesUnit 3 Z-Scores, Measuring Performance: Learning OutcomeCheska AtienzaNo ratings yet
- Continuous Probability Z-ScoreDocument51 pagesContinuous Probability Z-ScoreKhalil UllahNo ratings yet
- Ambo University Waliso Campus: Statistics For MGT I: Normal Distributions (Continuous Probability Distributions)Document121 pagesAmbo University Waliso Campus: Statistics For MGT I: Normal Distributions (Continuous Probability Distributions)keransotadeseNo ratings yet
- ACCTY 312 - Lesson 3Document7 pagesACCTY 312 - Lesson 3shsNo ratings yet
- Probability Distributions: Probability: With Random Sampling or ADocument40 pagesProbability Distributions: Probability: With Random Sampling or ABhargav MendaparaNo ratings yet
- Jurnal StatistikDocument7 pagesJurnal StatistikAry PratiwiNo ratings yet
- Chapter 6Document30 pagesChapter 6Mohd Nazri OthmanNo ratings yet
- Continuous Probability Distribution PDFDocument47 pagesContinuous Probability Distribution PDFDipika PandaNo ratings yet
- Examples of Continuous Probability Distributions:: The Normal and Standard NormalDocument57 pagesExamples of Continuous Probability Distributions:: The Normal and Standard NormalkethavarapuramjiNo ratings yet
- NormalWS1 PDFDocument4 pagesNormalWS1 PDFRizza Jane BautistaNo ratings yet
- Chapter 6 DPDDocument47 pagesChapter 6 DPDismamnNo ratings yet
- Lecture 6Document28 pagesLecture 6Angel Borbon GabaldonNo ratings yet
- Tugas Kuliah Statistika SESI 4Document4 pagesTugas Kuliah Statistika SESI 4CEOAmsyaNo ratings yet
- Tugas Kuliah StatistikaDocument4 pagesTugas Kuliah StatistikaCEOAmsyaNo ratings yet
- m2 2 Variation Z ScoresDocument18 pagesm2 2 Variation Z ScoresRey Marion CabagNo ratings yet
- 026 Exercise03-DistributionsDocument3 pages026 Exercise03-Distributionsashishamitav123No ratings yet
- Chapter6 StatsDocument4 pagesChapter6 StatsPoonam NaiduNo ratings yet
- Normal DistributionDocument4 pagesNormal DistributionAlyssa Marie L. Palamiano100% (1)
- Normal Curve Standard Normal CurveDocument33 pagesNormal Curve Standard Normal CurveJahanvi AundhiyaNo ratings yet
- Lesson 9 Normal DistributionDocument8 pagesLesson 9 Normal DistributionAshley ColinaNo ratings yet
- Normal DistributionDocument29 pagesNormal DistributionMohamed Abd El-MoniemNo ratings yet
- Stats Lecture 06. Normal Distribution DataDocument46 pagesStats Lecture 06. Normal Distribution DataShair Muhammad hazaraNo ratings yet
- Statistics Class Work # 2-1Document8 pagesStatistics Class Work # 2-1dc.yinhelenNo ratings yet
- Random Variable & Probability DistributionDocument48 pagesRandom Variable & Probability DistributionRISHAB NANGIANo ratings yet
- Assignment Inferential Statistics 1Document5 pagesAssignment Inferential Statistics 1maudy octhalia d4 kepNo ratings yet
- Tatang A Gumanti 2010: Pengenalan Alat-Alat Uji Statistik Dalam Penelitian SosialDocument15 pagesTatang A Gumanti 2010: Pengenalan Alat-Alat Uji Statistik Dalam Penelitian SosialPrima JoeNo ratings yet
- BS-chapter3-2021-Z - Score or STD ScoreDocument17 pagesBS-chapter3-2021-Z - Score or STD ScorefarwaNo ratings yet
- Lecture 2 EPS 550 SP 2010Document30 pagesLecture 2 EPS 550 SP 2010Leslie SmithNo ratings yet
- IISER BiostatDocument87 pagesIISER BiostatPrithibi Bodle GacheNo ratings yet
- AssignmentDocument12 pagesAssignmentminakshi kamdiNo ratings yet
- Standard Deviation & The Normal ModelDocument12 pagesStandard Deviation & The Normal ModelEloisa ReyesNo ratings yet
- Estimasi StatistikDocument28 pagesEstimasi StatistikSiti Maisyarah SmashblastNo ratings yet
- Summary Chapter 6Document9 pagesSummary Chapter 6Kartika PutriNo ratings yet
- Deva 1Document12 pagesDeva 1Jasmin StanislausNo ratings yet
- GCSE Maths Revision: Cheeky Revision ShortcutsFrom EverandGCSE Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (2)
- SSC CGL Preparatory Guide -Mathematics (Part 2)From EverandSSC CGL Preparatory Guide -Mathematics (Part 2)Rating: 4 out of 5 stars4/5 (1)
- Protein Structure and FunctionDocument30 pagesProtein Structure and Functionمحمد جانNo ratings yet
- EDC-DTS-MV016 - Stay Wire and AccessoriesDocument27 pagesEDC-DTS-MV016 - Stay Wire and AccessoriesJoe bilouteNo ratings yet
- Discrete Element Modelling: Trouble-Shooting and Optimisation Tool For Chute DesignDocument27 pagesDiscrete Element Modelling: Trouble-Shooting and Optimisation Tool For Chute Designvenkatryedulla100% (1)
- Adsorbents: Carbon Molecular SieveDocument1 pageAdsorbents: Carbon Molecular SievemayankNo ratings yet
- Japanese Dessert Recipes Gordon RockDocument62 pagesJapanese Dessert Recipes Gordon RockBorat Kaza100% (3)
- 120 (Book 1) 2016Document236 pages120 (Book 1) 2016Jerico Kier YesyesNo ratings yet
- தடம் TEST BATCH 2023 - E.M.Document11 pagesதடம் TEST BATCH 2023 - E.M.Shiva GangaNo ratings yet
- Laporan Stock On Hand Nasional 21-10-2021Document1,464 pagesLaporan Stock On Hand Nasional 21-10-2021HilmiANSNo ratings yet
- English As A Second Language: Paper 1: Reading and WritingDocument24 pagesEnglish As A Second Language: Paper 1: Reading and WritingΒασιλεία ΕυαγγέλουNo ratings yet
- Garcia Et Al 2019Document13 pagesGarcia Et Al 2019Christian Borja TacuriNo ratings yet
- Intro. To HumanitiesDocument15 pagesIntro. To HumanitiesEdlyn ResuelloNo ratings yet
- Chapter 5. Upthrust in Fluids, Archimedes' Principle and FloatationDocument30 pagesChapter 5. Upthrust in Fluids, Archimedes' Principle and FloatationRabindra DashNo ratings yet
- Ethylene Glycol&EO UllmannDocument41 pagesEthylene Glycol&EO UllmannCristina NegreaNo ratings yet
- Materi Song KirimDocument4 pagesMateri Song Kirimrane ajaNo ratings yet
- Atom Sunflower Warmer Operation ManualDocument64 pagesAtom Sunflower Warmer Operation ManualGunma AkagiNo ratings yet
- Average Number of Each SpeciesDocument5 pagesAverage Number of Each SpeciesShantonu Rahman Shanto 1731521No ratings yet
- 961 Annex B Form 1b Sample Harmonized WorkplanDocument2 pages961 Annex B Form 1b Sample Harmonized WorkplanRandell ManjarresNo ratings yet
- Surge Voltage ProtectionDocument22 pagesSurge Voltage Protectionrajpre1213No ratings yet
- War and Defence VocabularyDocument3 pagesWar and Defence VocabularyDhiman NathNo ratings yet
- NCLEX Practice Exam For Pediatric Nursing 2 - RNpediaDocument14 pagesNCLEX Practice Exam For Pediatric Nursing 2 - RNpediaLot Rosit100% (1)
- Puzzles and GamesDocument22 pagesPuzzles and Gamessarwarpashamd786No ratings yet
- Chapter 8Document40 pagesChapter 8s211151339No ratings yet
- Malaysia Airlines Flight 370Document3 pagesMalaysia Airlines Flight 370dinosaur x-drakeNo ratings yet
- CBSE Class 5 EVS Worksheet Safety and First Aid: Get Free Worksheets OnDocument5 pagesCBSE Class 5 EVS Worksheet Safety and First Aid: Get Free Worksheets Onbittuchintu50% (2)
- Find My Favorite AnimalsDocument16 pagesFind My Favorite AnimalsCecilia DaoNo ratings yet
- Solid - Liquid ExtractionDocument20 pagesSolid - Liquid ExtractionFikriyatul KhaeriyahNo ratings yet
- Rose Geranium in Sesame Oil NasalDocument3 pagesRose Geranium in Sesame Oil NasalHolly JonesNo ratings yet
- Motion Loads Pal ADocument11 pagesMotion Loads Pal ABoris Stheven Sullcahuaman JaureguiNo ratings yet